从0到N建立高性价比的大数据平台(转载)
声明:本文为作者在CSDN技术公开课的分享原创整理,未经许可,禁止转载。
作者:郭炜,易观CTO,毕业于北京大学,曾任联想大数据总监、万达电商数据部总经理,曾在中金、IBM、Teradata公司担任大数据方向重要岗位。在智能硬件以及大数据分析领域具有丰富的理论和实践经验。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
分享内容简介
今天和大家分享的内容主要就是怎么样从0到N来建一个大数据平台。其实,每一个大数据平台都不是凭空而起的,每个企业刚刚开始数据分析的时候,也不是上来就是一个大数据开源平台Hadoop、Spark这样一个存储的。今天分享的内容,其实是根据企业发展的不同阶段,针对业务的需求来选择不同的大数据架构,配置不同规模的数据处理人员,根据企业不同的时间点,帮助企业从0到N,建立高性价比的大数据平台。
从0到N——数据大时代的划分
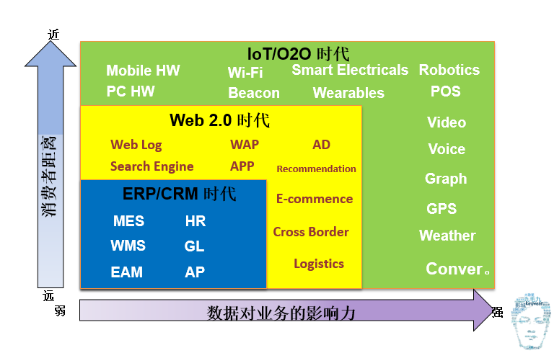
第一个先说从0到N大数据的时代划分,其实大数据时代不是现在才开始的,它早在以前就开始了,只不过那时候不叫大数据,在最开始的时候叫数据仓库。十年前,它在做企业内部的ERP、CRM的相对的一些集成。然后把里面做一些BI的分析报表,做一些数据挖掘。那个时候最著名的例子应该是啤酒和尿片的故事,就是关联数据挖掘能分析出来,周末男人经常去买尿片和啤酒故事。到后来互联网的出现大数据进入了Web2.0时代。在过去大家只是拿到一些用户结构化的交易信息和用户的联系信息,现在可以获得每一个人上网的点击流的信息,根据你的点击的情况做一些推荐。包括一些现在的猜你喜欢和搜索引擎排名,这些都是在Web2.0时候基于你在点击流的大数据的检索和大数据的一些处理。第三个阶段,现在我们所处的阶段,我认为就是IoT O2O时代,现在大家一讲到大数据,其实不仅仅包括了上网的行为日志,还包括像现在智能Wi-Fi与智能POS(感知在线下,一个在逛商场的时候,你在哪里停留了,停了多久,进了哪家店,吃了什么东西,唱了什么歌,看了什么电影这样的数据)把这些东西全部能收上来。还包括像现在的一些可穿戴的设备,去检测你的健康信息,也包括图象的识别、录像的分析,这些都是在现在这个时代大数据囊括的内容。
大家能感觉到,随着大数据时代的发展,从1.0,2.0到现在3.0,它离消费者的距离是越来越近了,过去原来都是高高在上,数据结果都是在相关的企业决策者的眼里,而现在其实我们都可以把它穿戴在身上,从手机上就能看到一些相关的数据的分析和相关的结果,整个数据对业务的影响力也是由弱慢慢变强,现在基本上如果一个企业没有一个数据决策,这个企业很难去运转。
从0到N——大数据时代企业划分
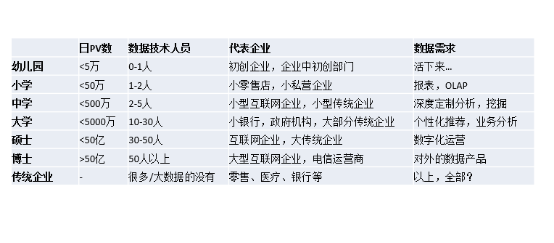
说过大数据时代的划分,下面来给大家介绍下我定义的大数据时代的企业划分,这里面我做了一个小的比喻,我根据一个企业的数量量,然后根据它的技术人员的分布,我去把它分成幼儿园、小学、中学、大学、硕士、博士等等。最后单独拿一个模板给传统企业。这里面的提到的PV数,如果你不是互联网的企业也没关系,你可以用你的企业每天日增的数据的处理条数,因为数据量其实决定了企业的技术框架复杂度和你的处理的人员多少。这里分别划分了几种:五万、五十万、五百万、五千万、五十亿条,大于五十亿条。数据技术人员的多少跟每一个企业发展阶段都是有直接关系的,具体情况参见上图,不再赘述。单独把传统企业拎出来,因为它稍微特殊,除了数据量的量级之外,传统行业的技术人员做大数据的人一般都比较匮乏,现在像零售、医疗、银行等等其实都是这个状态,而它的数据需求特别多,既需要OLAP,又要做挖掘,还要做个性推荐,对数据还有做一些数据产品,想法非常多,我们到后面也讨论一下,传统企业做大数据的时候要注意什么。
这个是我对不同数据阶段的划分,下面逐步介绍不同阶段适合的框架。
大学之前的基本框架

先说说大学之前的框架,就是所有的这些数据处理的基本框架,在大学之前其实无外乎分为以下几个模块:数据处理调度模块,数据展示工具,结构化数据存储(非结构化处理后放入结构化存储)。非结构化数据也可以用第三方的一些免费的分析工具,具体每个阶段略有不同。
先说说大学之前的框架,就是所有的这些数据处理的基本框架,在大学之前其实无外乎分为以下几个模块:数据处理调度模块,数据展示工具,结构化数据存储(非结构化处理后放入结构化存储)。非结构化数据也可以用第三方的一些免费的分析工具,具体每个阶段略有不同。

先讲讲幼儿园阶段,此时数据专职人员几乎没有,主要都是结构化的数据。结构化数据在这个量级的时候每天五万条,用Mysql即可存储,数据处理调度的时候,不用专门复杂的ETL工具,用Shell+JAVA处理即可(此时企业也没有专职数据处理人员)。展示工具在这个阶段的时候,不用买什么工具,这里我强烈推荐Excel,待会我给大家讲讲为什么推荐它。对于非结构化数据,这个量级有很多第三方的免费工具,如果需要可以挑选一个使用。
幼儿园基本框架

Excel是小数据量最好分析工具
- 所见即所得。
- 产品使用方便,人员易上手
- 支持各种定制化展示
- 支持简单的数据挖掘
- 业务部门容易使用 无招胜有招 多少金融模型来自于Excel
为什么推崇Excel?到目前为止,个人一直认为Excel是小数据量的最好的分析工具,没有之一。第一,所见即所得,所有的数据处理和数据挖掘工具没有一个就像Excel一样,简单拖拖拽拽即可实现,旋转透视表、关联分析挖掘、或者回归分析完全就在一个界面上就能处理好,没有一个工具能比得上它。第二点是使用方便,人员易上手,对业务人员不用做什么培训,用Excel业务人员就能做出各种各样的分析报表,非常高效。第三,支持各种个性化的展示。如右图,在页面上面能画出来比较炫酷的这些图,Excel基本都支持,包括支持地图上展示热区图等,具体的方法,大家自行谷歌一下。第四,支持简单的数据挖掘。Excel支持大部分的基本数据挖掘算法,比如关联分析,决策树分类等,方法大家自行谷歌。 Excel我认为在数据量级不超过十万条的时候是最好的分析工具。所以用Mysql把这个数据做一下汇总,Excel直接展示,这也是在幼儿园阶段对你来讲最好的一个分析框架了。有些人会说用Excel不是大数据,但是到现在为止,很多数据分析师还在用Excel,个人认为无招胜有招,不在乎工具是怎么样,而是在乎你背后分析思路和分析的经验是如何。大家知道现在很多大家都说金融股票分析什么这些都非常高深,用各种量化模型,但是大家知道,很多金融模型都是来自Excel的,对于最基本的分析工具Excel,我向大家强烈推荐一下,无论哪个阶段一定要深学活用。
第三方分析——易观方舟帮助你分析页面流量
- 支持网页和APP
- SDK只有66k
- 省去了各种数据加工的麻烦
- 基本指标一应俱全
- 目前开放的基本功能,永久免费
- 功能不断在迭代
对于在这个阶段,互联网非结构化分析有很多像友盟和方舟这样的免费分析工具。我在易观就简单说易观的方舟,通过易观的业界最小的SDK(Android只有66K)就可以看到各种基本的分析指标,存储和处理都不用操心了。基本的这些指标一应俱全,而且永久免费,指标数据可以下载回本地,如果需要明细数据回传服务也可以单聊。这个阶段,最重要的是把企业把业务流程打通,先活下来,这是在幼儿园这个阶段。

集美貌与智慧一身的“SQL Server”
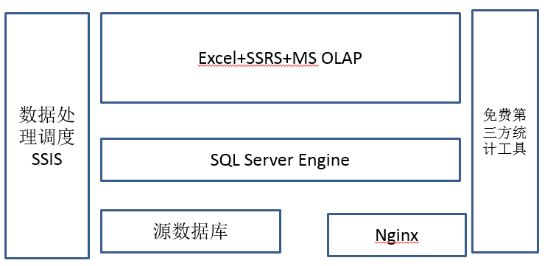
为什么是SQL Server?
- 一个软件覆盖了这个阶段数据处理的所有功能
- 支持各种数据源的集成
- 支持ETL调度
- 支持报表展示
- 支持OLAP
- 数据量在几亿条之内(每天50万,一年1.5亿),查询效
率OK,如果扩展cluster,支持更好。 小数据分析神器Excel,完美结合,扩展了数据挖掘,展
现等功能缺点:数据量大以后,效率跟不上
在小学阶段的企业基本上有一点数据了,每天大概有五十万条这样的数据,有一些数据的处理专职人员了,1到2个人。需要有ETL工具和一定数据量级的数据存储。这个时候,向小企业隆重推荐一个继承解决方案就是SQL Server。提到SQL Server其实也有很多人在鄙视,听上去一点都不高大上,怎么能叫大数据?但其实大家知道吗?无论是现在已经火的京东,还是现在的美团,刚刚起步的时候都曾经经过SQL Server做数据分析的阶段。我把SQL Server叫做“集美貌与智慧于一身”,为什么这么说?其实SQL Server其实是它目前唯一一款软件,覆盖了这个阶段数据处理分析的所有功能,支持各种数据源的支撑。因为企业在这个数据量级的时候,源数据库有多个异构数据库和异构数据来源,需要一个比较强大的ETL工具做集中数据存储。在这个阶段,可以利用SQL Server自身集成带的一个东西叫SSIS,SSIS组件是一个简化版的ETL处理工具,你购买了SQL Server,你不用再需要购买一个ETL工具。此外,SQL Server还集成SSRS,它是一个网页报表系统,这个东西本身还支持OLAP引擎,你不需要再单独买一套报表的展现工具,对于这个阶段的企业来讲,大部分需求也足够使用。第四个是OLAP引擎,就是上钻下钻旋转这些OLAP特性SQL Server全都支持,而且在数据量级在几亿条以内,数据查询效率OK。当然,如果企业比较富裕,你去购买Cognos、Tablau这样的产品的话,支持会更好一些。最关键的,完美结合刚才提到的小数据分析神器Excel。Excel直接连上SqlServer,那基本上就如虎添翼,原来Excel只能十万条,SQL Server扩展到一亿条。当然此时第三方的工具还可以继续用,你用的像方舟这些继续可以使。那方舟里面,但这个阶段除了刚才说PV、UV,现在可能就是分析一下这个页面路径了,就是这些人通过什么样的路径点击进来,到你那触达你的最终的购买路线的,这些人究竟它的转化率怎么样。包括一些留存分析,就是哪些用户是老用户,这些用户留存情况怎么样,是什么活动促销进来的等等。这个问题是在这个阶段肯定有的,但是用的工具不一定是易观的方舟也有其他的工具。

传统数据仓库+日志分析工具
日增500万,年度过5亿以内,2-4个人,暂时还没有人力搭建hadoop。
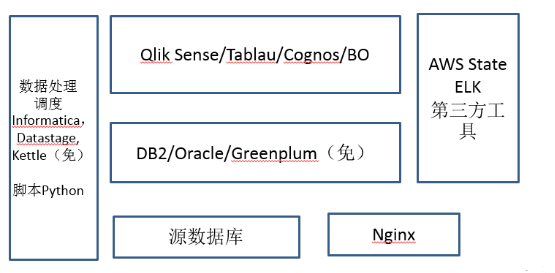
刚才讲到了幼儿园小学,现在上中学了。为什此时我还在推荐商业组件而不是开源组件,是因为在此时,大部分企业还是以满足企业内部需求为主,建立分析平台的时间和效率往往比建立高大上的平台有效切实的多,同时建立相关团队也需要时间,使用商业组件可以提高整体的效率。在中学的时候,每日日增数据量基本上是五百万量级,一般是小型的这些互联网企业,或者小的传统企业,此时,数据专职人员就有2到5个人了,这个数据量可能像一年下来可能要过十亿条了,单机的SQL Server支持可能会有一些吃力。目前这个阶段,我个人的建议还是你不要上Hapdoop这样大的平台,建立Hapdoop平台一定要10人以上的团队规模,这个其实是一个坎儿,在这个时间不要着急搭这种复杂的Hapdoop平台,但是对于您目前的企业数据量来讲,你需要一些专业的数据处理工具和展示工具了,就是你的小的企业可能刚才我说的SqlServer这个解决方案,已经不适合你了。那一般现在都有哪些?像数据处理调度的时候,因为刚才我提到说,SqlServer它自己集成,但是目前处理到SSIS,肯定是不能够完全满足你的要求了,于是就有比较专业的数据处理工具,有两个比较商业上过去用的非常有名的,一个叫Informatica,另一个Datastage,这两个其实都能满足大部分的企业的数据处理的调度的需求,现在大部分银行也在用。当然今天我们追求性价比,所以我给大家介绍常用开源的工具,叫做Kettle,目前大部分中小公司Kettle用的其实还是最多的,因为它的功能比Informatica、Datastage相比肯定要弱一些,但是比SSIS来讲还是要更强一些,而且现在Kettle还支持了Hadoop、Spark等等任务调度和监控,还是扩展性在这个阶段挺强的工具。
数据存储在这里也有一个升级,原先的存储在这个数据量级每年在15-20亿条,此时需要更大型的数据存储,比如说DB2、Oracle,这两个都是商业的,就是现在目前也是过去在商业数据仓库验证比较好的。我们追求性价比,也可以用去年开源的Greenplum。GP其实在大数据行业里面还挺有名的,去年年底实现开源免费使用。GP是在上百亿数据量级里面,唯一一个MPP架构且开源的数据存储平台,它的处理效率和DB2、Oracle一点不落后。在展示方面,随着业务量的增加,需求越来越多,也需要一些单独的查询展示工具。在这个环境下,数据量有一定数据量级了,但你的人不多,做自己的一些查询工具可能还不行,你方式是买一些商用的工具来去做一个过渡,所以我在这里推荐几个现在比较火的。Qlik Sense/Tablau这两个我用过都还不错,属于新一代的展现工具,当然还有老牌的Cognos和BO等表现都中规中矩,建议展示工具和业务需求部门一起评审,选一个合适的即可。选择合适的展示工具可以节约建立大数据平台的大量时间。
开源的ELK——简易日志分析平台
ELK
- Logstash
- ElasticsSearch
- Kabana
优点
- 搭建简易
- 迅速满足日志分析需求
- 自身具有多种展示方式
缺点
- 功能单一,只针对日志
- 扩展性不强
在中小学的时候,非结构化数据可以通过程序转换为结构化数据再存入传统结构化数据数据库的同时使用第三方免费工具来分析处理。在这个数据量级的时候,你会发现很多临时性的新需求,第三方免费的这些工具不够用,这时候ELK就派上用场了,ELK,就是Logstash、ElasticsSearch、Kabana缩写。在这个时间点,其实如果你想要自己一些自主的,这种非结构化的日志类的分析,可以使用ELK分析。
在这个时候如果你的公司还没有使用Python处理数据的话,一定要求你的技术人员开始使用Python,前面其实都没有单独对数据处理的语言对大家做限制,特别人比较少的时候,在这个时间点,一定需要让你的人员从JAVA转到Python去。Python有几个这样的好处,第一数据处理简洁明快,比Java针对数据开发效率高很多。过去有一个语言叫做Perl,现在Python已经取代了Perl的地位,成为一个数据处理的一个必会的语言。第二个好处是Python各种数据源和各种环境都支持,它的延展性特别高。第三个是Python支持各种数据挖掘的算法库,基本上各种在Python的这种库是最多的,甚至比JAVA还多。第四个是支持各种流式计算系统的框架,就是你将来学了Python以后,你可以顺利地从中学上大学。所以在这个阶段,我建议每一个企业在这个时候,去把Python脚本用起来。
第三方免费分析——易观方舟的用户画像
- 人口属性:设备群体特征
- 使用类型:都是使用什么类型的应用
- 使用类型时段:什么时间使用什么类型的APP
- 使用关联分析:从哪里来,到哪里去
- 用户偏好:用户标签
当然,在这个阶段,第三方的数据平台依然可以帮你做一些事情,比如说方舟的用户画像。因为这些功能的背后需要有大量的数据和大量的数据分析算法,来帮助你的企业告诉你,你的客户它的设备群体是什么样的,他们是在使用什么样类型的应用,这些应用在什么时间段怎么使用。也能告诉你做一些关联分析,就是你这个客户在使用应用之前,他从哪里来到哪里去,还给你很多的一些用户标签。这些其实是你在用ELK,这些统计的东西都是没有的,目前这个功能也是免费对外开放的,大家欢迎去使一下。

开源平台的引入与数据治理的加强
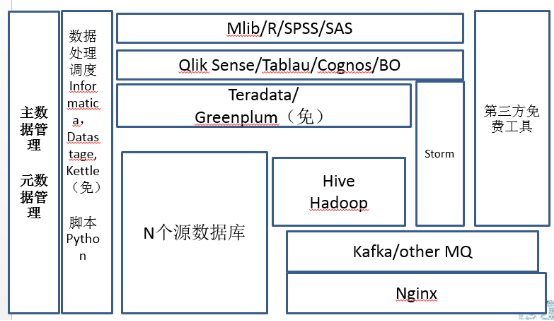
上完中学以后就要上大学了,包括小银行、政府机构、大部分传统机构,这个里面它要求的东西就更多了。上大学以后,系统的结构一下就变复杂了,为什么?除了非结构化数据的处理之外,在这个时候有两个非技术模块很重要,一个叫做主数据管理,一个叫做元数据管理,所有在这个阶段的企业都做了类似这样的项目。主数据是什么?在企业里面,各种各样的系统里面都有各种各样的数据,对于某些特殊的数据的标准数据就是主数据。举个例子,客户信息。你可能有CRM里面有,ERP里面有,可能生产调度系统里面有,可能销售的APP里面也有,你的网站上面也有。对于每一个客户来讲,谁作为唯一确定的数据做黄金拷贝?这就是主数据管理的意义,你一定把主数据存储独立存储,业务流程发生变更的时候,哪个系统有权限去改主数据,是非常重要的,否则最后客户的电话号码天天变来变去,你也不知道它哪个是最终有的有效数据。所以在这个时间点你一定要做一个主数据的管理。第二个元数据,元数据的管理,到这个阶段以后,表、存储特别多了,这些数据怎么能有效的管理。例如,元数据当中的血缘分析,就是你这个表它的数据从哪里来,到哪里去,这个数据怎么最后变成了指标展现出来,指标发生数据问题的时候,哪些数据处理过程可能存在一些故障可能,这些东西其实是在这个阶段做的。
在这个阶段开始要做真的开源平台的引入了,开源平台的引入和数据治理的加强,导致你的人员迅速地扩张。第一个这里面引入了Hadoop,Hadoop我目前建议你还是先用Hive先用用,逐步转为Map Reduce非结构化处理,通过Kafka,接入Storm也可以使用实时地流式计算,通过Storm直接反馈到前端的展现工具。在这个数据量级的时候,每天五千万条左右的结构化数据的处理量,可以使用开源的Greenplum或者商业化的Teradata。Teradata目前还是在MPP架构业界最快的,但是卖的也是最贵的。展现工具,企业依然可以去买第三方工具,自己不用去开发。此时的企业,数据挖掘的需求越来越多,使用数据挖掘工具的时候,原来做的一些简单的像Excel这样的工具已经无法满足个性化推荐、协同过滤这些算法了。挖掘工具可以在R SPSS、SAS、或Mlib库选一个。Mlib是Spark中的数据挖掘库,功能强大,处理速度快。不过此时我还不建议企业着急上Spark,因为大部分这些企业大数据投入还是有限的,Spark的使用会给人员带来新的需求。如果人员有限,那么可以选择商业的数据挖掘工具,如果人力比较富裕,可以使用开源的R结合python相关挖掘的类库,能解决企业大部分的挖掘和推荐需求。这个时间点上有一个特点就是在大部分的这个企业处理的时候,大部分数据还是将非结构化数据处理之后,变为结构化数据再做相关处理,哪怕经过了MapReduce,经过挖掘在线模型,最终的数据还会回到这种结构化的数据库里面再去使用。或者有小部分地流式实时数据处理来做展示。绝大部分数据存储还不是放在Hive和Hapdoop里面的,你的大部分的数据其实还是在结构化的数据里面。因为你的人员在这个阶段,其实还是结构化数据处理人员比非结构化数据处理人员多,你的业务需求也是结构化数据需求最多。
中流砥柱——Kafka/HDFS/Hadoop/Hive
最皮实的组合
- 鲁棒性
- 硬件兼容性
- 数据处理稳定性
每个系统大数据存储,都绕不开
缺点:慢!
分开来讲,Kafka/HDFS/Mapreduce/Hive,我把它叫做最皮实的大数据组合,原因有几个:第一就是稳定,无论你现在用的是Cloudera 还是Hortonworks,其实让你的开发人员去安装一套,安装配置的时候可能中间有一些坑,但是你只要把它安上去转起来一次以后,那后面基本上它的大部分问题几乎就没有了。不会像其他平台,在运行时有时候会有一些诡异的问题。它的兼容性也比较强,就是无论好硬件差硬件,它都能跑起来。数据处理的稳定性,数据处理是非常稳定的,你不用担心数据量徒增会出什么问题。所以现在目前为止,每一个大数据的存储都绕不开这个组合。缺点也很明显,就是慢。这个东西它是不会内存爆掉,不会死机, 但是它转起来真的很慢,你想让它跑快起来,这个事其实挺难的,因为这个整个结构其实就不是那样的结构,经常你查一个SQL下去,你看着它先做map,然后再做reduce可能半个小时过去了。
贵族的开源——Greenplum
- MPP架构,查询速度很快!
- 大数据量SQL查询,除了Teradata,商业化使用最多
稳定性强
GPDB目前使用最多,HAWQ支持HDFS是未来
缺点:吃硬件,万兆、多SAS盘、服务器很贵…
刚才我提到了Greenplum, Greenplum这家公司其实也是一家老牌公司了,它其实现在有两个开源的版本,一个以GPDB为核心,一个以HAWK位核心。GPDB是现在目前使用最多一个查询的引擎,广泛应用于银行、电信等等很多的领域里面,其实都是用了GPDB的SQL的查询比较多。HAWK是新版的GP存储引擎,现在支持HDFS,简单来讲它是底下存储换为HDFS,它本身的查询计划和优化还是用的GP的这一套东西,所以它的速度基本上和GPDB是相同的,只不过现在刚刚推出来,还需要一些时间验证和推广。但是整个趋势来看HAWK是未来,因为它支持的HDFS,对于数据的导入导出,磁盘的冗余替换都是非常有利的。易观作为GP开源以后第一个使用开源版本存储处理大量数据的企业(日处理量在100亿条左右),我们也遇到了一些坑。但是给我们带来的优势是查询速度非常快,同样的结构化数据的查询,不夸张的讲Hive需要1小时,GP 1分钟就可以算出来。目前来讲GP其实商业化用的是最多的,稳定性也是非常强,在大数据的类SQL这个领域里还是比较好用的。当然,它也有缺点,就是非常吃硬件。普通的开源软件我叫做屌丝开源,一般对硬件要求不高,而GP我管它叫贵族开源,它对网络和磁盘的IO要求极为苛刻,一旦你的网络和你的磁盘IO没有配置均衡有效的时候,它会经常出现一些诡异的问题。所以基本的配置,单光口万兆是最最基本的,没有这个硬件投入你就不要想用GP了,一般它推荐的是双万兆卡,就是一定要有光交机,两个万兆给它,每一个机器的磁盘很多的SAS盘。所以,它要求的硬件,包括整个的服务器,那你服务器本身主板其实这些要求全都规格都上去了。但是企业结构化数据到一定数据量级的时候,还是可以选它的,个人认为它还是比较靠谱的。
易观方舟的转化分析与应用评级
看自己产品转化
- 营销活动是否高转化为下单支付?
- 行业平均转化率如何?
- 什么渠道用户分享与传播多?
看行业均值、TOP10
- 市场是否已被领头羊蚕食?
- 长尾几无生存空间?
看自己评级
- 易观给你的第三方的评估
当然在这个阶段,第三方的平台依然可以给你一些帮助。例如,帮助你看你企业从广告到浏览到下单,转化率是如何的?行业均值差多远?这些易观都一些分行业的分析模板,只需要你简单的做一些数据嵌入即可。能看看行业趋势是怎么样,你自己看看这个行业的TOP10是怎么样。你的市场已经被领头羊吃掉了,或者你自己生存空间怎么样。再看看你在这个行业里排行如何?有没有一些新的缺口?另外易观给你做一个第三方的评估评级,给你的投资看下你的用户的价值有多大。这些基本功能都是永久免费的,而将来基于这些基本功能的扩展分析是要收费的。

那刚才讲完大学了,现在开始上研究生了,研究生每天的数据条数少于五十亿,那现在到了这个量级的时候,基本上专职人员是30到50人了,这个时候关键词就是一个字,开源。为什么?在这个量级的时候,如果你不去用一些开源的一些工具投入已经超过了你对于人员雇佣的投入费用。那对于这个阶段来讲,除了Hadoop系列,会引入Spark、麒麟、Presto、Druid这样的数据处理和存储平台。研发工具基本上原来的商业工具肯定是无法满足需求了,可以引用百度的E-Chart或者D3。他们之间各有千秋,但是我是支持国产的开源的,所以我选了echarts。
数据量增加、实时计算的引入导致全面开源化
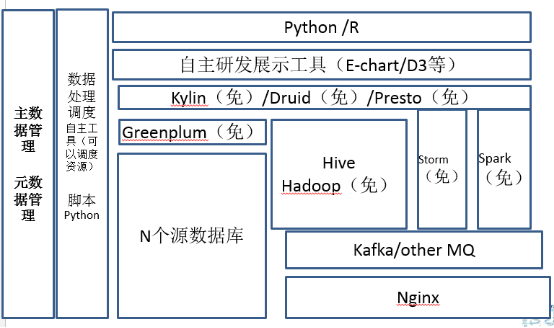
内存计算的翘楚——Spark
- 目前最火的大数据开源项目
- 华人贡献占52%
- 大数据下数据挖掘必选项SparkR
- 即使使用磁盘,执行效率优于Hive几倍
研究生大数据必修课
- 缺点:如果达到很高效,硬件要支持
- 数据量比较大,节点比较多,对Scala要求比较高
先说Spark,目前最火的大数据开源项目。它的开源的火爆程度目前超过了Hadoop一倍可能还得多,而且华人在里面贡献的人名数超过50%以上。在这个数据量级,会有大量的数据挖掘模型和处理的需求,而Spark对于迭代式的数据挖掘,特别大数据量的处理的时候。同时,它的内存计算及相关框架效率是Hadoop运行效率的几倍,所以在研究生阶段,大数据必修课就是Spark。但缺点也挺明显,就是如果你想达到它的高效,因为它就是内存的计算,硬件整体环境需要支持。就是也许你现在不用万兆,那你也得用双网卡或者四网卡捆绑,你的网络IO得有保证,你的内存和CPU得能上来,这两个是你在Spark的时候必用的。另外,大家知道Spark是用scala做的,你对scala的要求就比较高了,因为你结点多的时候,这点或者那点总有点小问题,所以研发的技术人员必须得对scala比较熟悉,可以简单调试相关的问题。相对于Hadoop,Spark稳定性还在逐步加强,它在流程里会有一些小的bug出来,因为它虽然很火,但是它还会有各种各样的小问题,需要你去修修补补的。所以这个是你在研究生的时候你再去学。
OLAP的利器——Kylin
- 解决了大数据多维度查询速度慢,多维查询数据返回丌及时的问题
- 开源MOLAP利器
- Apache金牌项目
- 源自Ebay内部大数据
- 利用Hbase,加速可以加速Hbase
中国人自己的开源项目!
- 缺点:预计算时间比较长
麒麟源自于e-Bay,现在它单独从e-Bay独立出来了,那它是Apache的金牌开源项目。麒麟是开源的MOlap的利器,解决了大数据多维查询速度慢,多维查询的反馈不及时的问题。目前麒麟底层主要是利用Hbase去做存储和查询,所以你要去想加快麒麟的速度的话,可以用增强磁盘和网络I/O的方式处理。麒麟目前国内很多大牌的地方也都用过了,包括像腾讯,美团都有使用,现在有很多经过实际的一些经验,它是OK的。最重要的一点,它是中国自己开源的项目,中国人自己的,所以大家一定要支持它。但是麒麟也有它的缺点了,就是它的预加载时间比较长,因为它是用空间换时间的。在大数据架构里,展示的时候如果想看到数据怎么上钻下钻,然后做一些查询,麒麟作为国产的开源的这样一个软件,我觉得还是强烈推荐的,这个大家可以去使用。
OLAP的生力军——Druid
- 解决单表大数据查询问题
- 支持实时增量的聚合
- 不支持查明细
正准POC,不乱评价
开源负责人是华人
- 缺点:未知,正在准备试用
Druid是最近比较火爆的查询平台,最近群里也一直在讨论,我正在做POC,暂时还不评论。试用以后再给大家做一个反馈。
内部SQL查询工具——Presto
- Facebook开源内存SQL查询
- 可以跨mysql,Hadoop, cassandra查询
- 查询效率进高于Hive
SQL支持比较好
缺点:内存吃的很厉害,而且大查询出现诡异的异常
- 目前易观用作内部查询使用
Presto其实Facebook开源的,是一个内存式计算的框架,它比较牛的地方,它是一个能够跨Mysql跨Hadoop,跨cassandra的查询。支持跨库查询,可能主数据在Mysql,行为明细在Hive,用户标签在cassandra,一个语句可以解决所有问题。这件事情还是很牛逼的,但是现在它要支持很多新的数据库的Adapter,但是据说新的adapter要收费,查询效率也高于原生的Hive。我们原先也用 presto,美团也在使用。但是Presto的缺点也挺明显,就是如果你数量不大的时候,原来我们拿presto串到整个数据处理流程也很好。但缺点也很明显,Presto内存吃的很厉害,如果数据量级比较大的的查询(超过20亿左右,根据集群大小不同),就会出现很诡异的异常,而且每次异常的点都不一样。所以在这个情况下,就是我们现在易观拿它做内部查询使用,就是你不能把它串到数据处理流程里。

对开源平台的修改、对硬件的定制要求
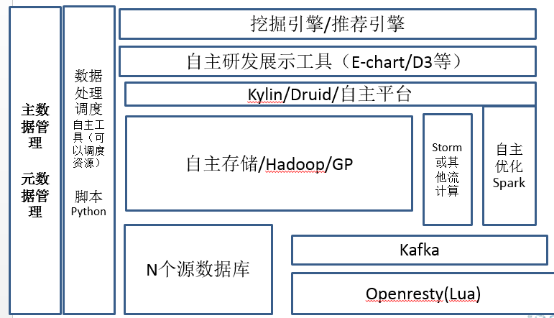
到博士生了,更多的技术人员集中到算法层面,例如像知识库或者知识图谱的建立,或者在线推荐引擎和搜索优化这样。大数据平台方面,其实每个不同的这个地方,其实都不太一样。这个阶段每个公司都是自主的一些存储了,包括ETL的工具。在这个阶段原先免费开源的ETL调度工具都不行了,这个工具需要结合任务去动态调整资源,像易观自己做的EAMP,或者我在万达时候e-horse,除了你调度ETL流程之外,因为你的数据量很多了,它得能够去调动你的Hadoop的这些资源并处理一些特殊的业务情况。大数据存储的时候在此时各显神通,这个时候真的没有一个统一地说完整的解决方案。这里稍微提一点优化,就是需要将大数据分段处理了。因为这么大量的数据,如果直接扔到后台集群,集群压力会超大,性价比也不是最高。所以在这里举例,在互联网数据接收的时候,就开始做数据处理。例如,利用Lua在openresty去处理脏数据,分段优化整体的大数据处理流程。在这个阶段,基本上所有的这些博士生的企业,都有修改开源平台的能力,你的团队得能去修理开源的平台解决相关的问题。
性价比最高的定制化硬件
大数据集群要什么?不同场景不同
批量计算——高性价比的I/O,网络I/O,磁盘I/O
- 磁盘I/O,SSD?量大了用不起。
- 多磁盘,组Raid
- 网络I/O,光纤万兆?性价比丌吅适
- 多网卡捆绑,4块放一起
实时计算——网络 I/O,CPU
- 大内存
- 万兆
- 高CPU
- 磁盘?SSD,必须的
同时,你要对硬件做一些定制,就是如果你真的想做性价比最高,原来成型的这些机器不太好使了,其实有很多东西你得去配置什么要下一些功夫。大数据集群需要什么?就是不同场景,不太一样。批量计算,批量计算像Hadoop或者presto主要是高性价比的IO,指的是网络的IO,磁盘的IO。如果真的想框架不变,速度提升优化50%、70%,你想通过优化Hadoop这些优化,我觉得基本不太可能,你直接升SSD硬盘才是解决方案。如果性价比比较高的方案,优选的就是磁盘特别多的机器,在这个时候你去买更多的盘,比如说你的机器支持16块盘,把这16块盘,如果HDFS倍数是3的话,你组三个Raid,去处理,比你用8块盘的机器用罗裸快得多。磁盘IO这件事是我觉得第一个优化的。
第二个网络IO,网络IO,我们要高性价比,网络IO万兆当然是最好了但是性价比其实不合适,其实现在很多的这种多网卡捆绑的方案了,就是你买四块网卡,费点交换机,你把四块卡绑一起,其实它这个速度,虽然不是×4,但是基本上×2×3还可以。所以在这个时候也是一个廉价的解决方案,所以你的Hadoop集群在配的时候,你就用这种多磁盘,多网卡,CPU要不要高?其实我觉得不用。就是大部分的Hadoop出现的问题都不用在CPU上,都是在磁盘和网络IO上面的,就是你在这两个IO上面提上去,你的查询效率会高很多,而且也不用花太多钱。
对于时时计算来讲,这个事其实如果你真的想做得比较好,那么主要是网络IO和CPU,内存一定要大,你的网络,我觉得像GP、Spark这些你要想把它转得非常好,速度非常快,那你还是上万兆吧。如果你要想便宜的话,你就用四块网卡去捆绑,CPU,因为这个时候其实它是内存之间的交互,CPU如果不够高,那你最后CPU就有瓶颈,磁盘直接上SSD即可,现在目前其实你要想定制比较性价比高的这些硬件,其实主要还是回到它原来处理平台的时候,需要IO,需要CPU还是需要网络,从这几个角度来看,不同场景其实还是不太一样的。
当然,其实刚才讲了一堆开源的工具,我们也在做一些有趣的测试,就是拿我们现在易观处理完的,比如说一天大概五十亿条的数据,拿这个数据做一下评测,在不同场景下,每个查询效果怎么样,这个事其实我们现在正在做POC,做完以后,下次分享的时候,也跟大家去聊一聊。
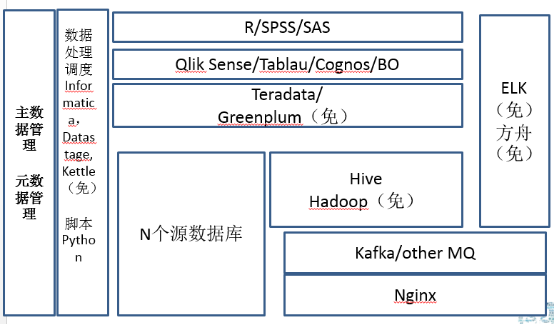
刚才也说了各个不同的,从幼儿园到博士生,其实跨度还是挺大的,讲的从一开始的Mysql到最后整个完整的一个大数据平台。传统企业比较特殊,就是它大部分数据都是结构化数据,技术人员基本上不是特别多,要么就是外包,要么是自己内部人员。但大数据的这些算法和大数据的非结构化的处理比较少。我这里面关键词其实就是建议传统企业还是先建一个数据仓库,然后把少量的非结构化的处理放到结构化里面。
传统企业模板
大数据云化的观点
大数据云化是趋势
小公司,全面云化,借劣第三方云化解决方案,端到端解决问题
- 核心数据选一家大的(阿里、腾讯、Ucloud等)
- 周边方案丌一定只一家(多选几家功能触达为主)
大公司,大数据混吅云是当前的最佳实践
- 大数据集群自主
- 相关组件不产品云化
最后说说,大数据和云化的问题。各家云都上了各种大数据组件,这个东西可不可用?好不好用?该不该用?我的观点是这样的,就是大数据是云化是未来的趋势。目前在国内,如果你是小公司,那你就全面云化吧,那借助第三方的云化的解决方案,端到端解决问题,比如阿里、腾讯、Ucloud等等这个就不列了,这个感兴趣大家可以看易观的分析报告。周边端到端的数据分析服务云就不一定选一家,哪家能用它的一个优化的方案来解决你用哪家,对于移动互联网来讲,你可以选易观,当然你也可以加上其他的友商,在这个阶段对于中小公司来讲,这就可以了。对于大公司来讲,目前现在最佳的方案是混合云,最终落到还是一个混合云的方案。是为什么?就刚才提到,大数据集群从性价比来讲,从稳定性来讲,公有云都还有一段路要走。大数据集群可以在自己的私有云里面,那么你的相关的这些产品可以放到公共云上。
2016年8月12日-13日,由CSDN重磅打造的互联网应用架构实战峰会、运维技术与实战峰会将在成都举行,目前18位讲师和议题已全部确认。两场峰会大牛讲师来自阿里、腾讯、百度、京东、小米、乐视、聚美优品、YY互娱、华为、360等知名互联网公司,一线深度的实践,共同探讨高可用/高并发/高性能系统架构设计、电商架构、分布式架构、运维工具研发与实践、运维自动化系统的构建、DevOps、云上的运维案例分析、虚拟化技术、应用性能检测与管理、游戏行业的运维实践等,将和与会嘉宾共同探讨「构建更安全、更高性能、更稳定的架构和运维体系」等领域的话题与技术。【八折优惠中,点击这里抢票,欲购从速。】
从0到N建立高性价比的大数据平台(转载)的更多相关文章
- Web网站架构演变—高并发、大数据
转 Web网站架构演变—高并发.大数据 2018年07月25日 17:27:22 gis_morningsun 阅读数:599 前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系 ...
- Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案 随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! ...
- CDH构建大数据平台-Kerberos高可用部署【完结篇】
CDH构建大数据平台-Kerberos高可用部署[完结篇] 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装Kerberos相关的软件包并同步配置文件 1>.实验环境 ...
- CentOS7部署CDH6.0.1大数据平台
Cloudera’s Distribution Including Apache Hadoop,简称“CDH”,基于Web的用户界面,支持大多数Hadoop组件,包括HDFS.MapReduce.Hi ...
- LVS解决高并发,大数据量
http://www.360doc.com/content/14/0726/00/11962419_397102114.shtml LVS的全称Linux vitual system,是由目前阿里巴巴 ...
- 最新版大数据平台安装部署指南,HDP-2.6.5.0,ambari-2.6.2.0
一.服务器环境配置 1 系统要求 名称 地址 操作系统 root密码 Master1 10.1.0.30 Centos 7.7 Root@bidsum1 Master2 10.1.0.105 Cent ...
- 最全Java架构师130面试题:微服务、高并发、大数据、缓存等中间件
一.数据结构与算法基础 · 说一下几种常见的排序算法和分别的复杂度. · 用Java写一个冒泡排序算法 · 描述一下链式存储结构. · 如何遍历一棵二叉树? · 倒排一个LinkedList. · 用 ...
- 利用先电云iaas平台搭建apache官方大数据平台(ambari2.7+hdp3.0)
一.ambari架构解析 二.基础环境配置 以两台节点为例来组件Hadoop分布式集群,这里采用的系统版本为Centos7 1511,如下表所示: 主机名 内存 硬盘 IP地址 角色 master 8 ...
- HDFS+ClickHouse+Spark:从0到1实现一款轻量级大数据分析系统
在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析.版本迭代效果分析.运营活动效果分析等.这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足.本 ...
随机推荐
- 初学者用pycharm创建一个django项目和一个app时需要注意的事项
如何新建一个djiango项目: 1.在pycharm中点击File,选择new project,点击djiango,在右面的Location中将untitile改为你的项目名,其余部分注意见下图: ...
- 24 枚举Enum类
引用声明:部分内容来自文章:http://c.biancheng.net/view/1100.html 枚举Enum类是java.lang下的一个类. 枚举的命名规范 枚举名:大驼峰 枚举值:全大写, ...
- centos7简单部署rancher
rancher官网文档地址 https://www.cnrancher.com/docs/rancher/v2.x/cn/overview/ 准备机器 两台虚拟机 192.168.56.100 192 ...
- Docker学习笔记(一)—— 概述
1. Docker是个什么玩意 说Docker是什么之前,先来看一看Docker为什么会出现.我们知道,在学习过程中我们需要频繁地安装配置一些软件,不管是在Windows下还是在Linux,这些东西的 ...
- JDK提供的原子类和AbstractQueuedSynchronizer(AQS)
大致分成: 1.原子更新基本类型 2.原子更新数组 3.原子更新抽象类型 4.原子更新字段 import java.util.concurrent.atomic.AtomicInteger; impo ...
- Javap与JVM指令
一.javap命令简述 javap是jdk自带的反解析工具.它的作用就是根据class字节码文件,反解析出当前类对应的code区(汇编指令).本地变量表.异常表和代码行偏移量映射表.常量池等等信息.当 ...
- Hadoop常用命令及范例
hadoop中的zookeeper,hdfs,以及hive,hbase都是hadoop的组件,要学会熟练掌握相关的命令及其使用规则,下面就是一些常用命令及对hbase和hive的操作语句,同时也列出了 ...
- The server quit without updating PID file
[root@fjgh ~]# service mysqld start Starting MySQL... ERROR! The server quit without updating PID fi ...
- 小程序canvas绘制倒计时
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ 如果解决不了,可以在文末进群交流. 效果展示: //广告倒计时 advTimeCountDown:function(advTime ...
- Struts框架笔记03_OGNL表达式与值栈
目录 1. OGNL 1.1 OGNL概述 1.1 什么是OGNL 1.1.2 OGNL的优势 1.1.2 OGNL使用的要素 1.2 OGNL的Java环境入门[了解] 1.2.1 访问对象的方法 ...