python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了?
浏览器请求数据方式:浏览器向服务器的api(例如这样的字符串:http://api.qingyunke.com/api.php?key=free&appid=0&msg=关键词)发送请求,服务器返回json,然后解析该json,就得到请求数据了
同理:用Python向api发送请求,获得json,解析json,得到数据
即关键在于得到api
api获取:
1.用浏览器打开目标网页eg:https://www.zhihu.com/topic/19561718/top-answers
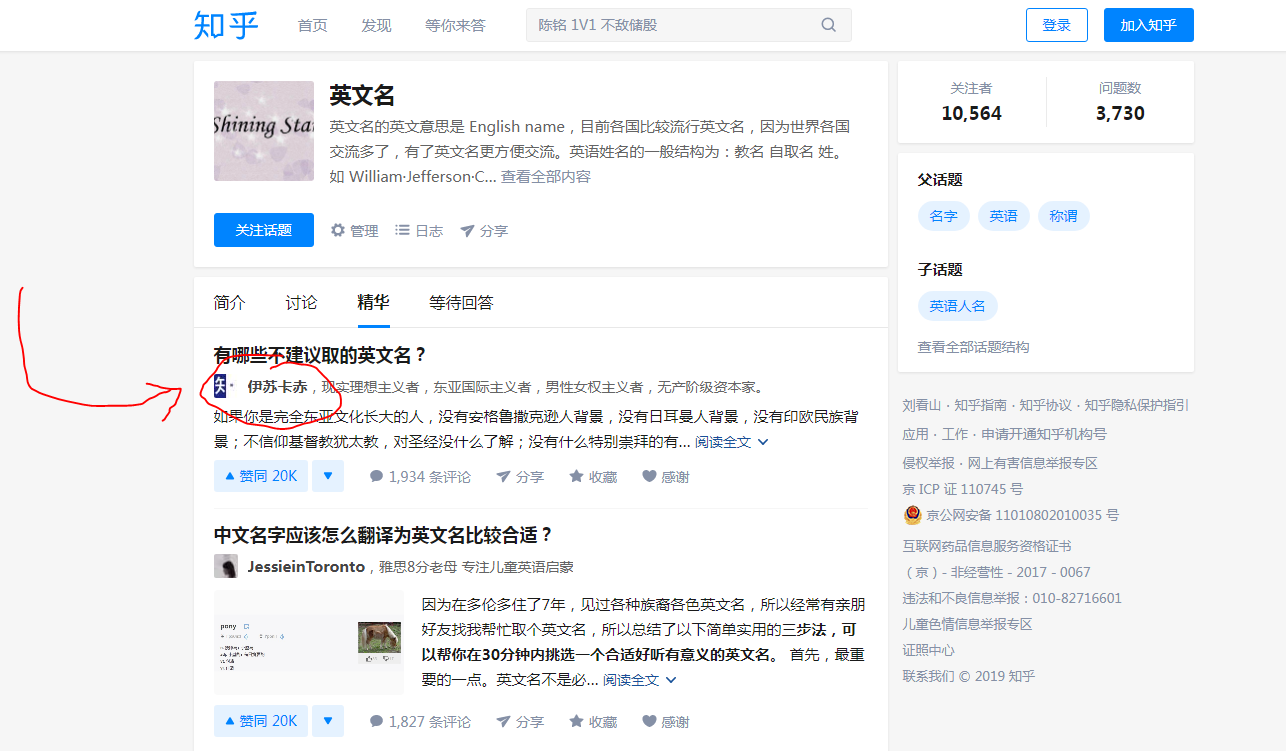
将鼠标放在上图图示位置,将显示该用户的一些信息,这些信息就是动态加载出来的。当鼠标放在该位置时,浏览器向服务器api发出请求,得到json,再解析便得到下图所示数据

在该网页反键选择检查源代码,按图示点开选项:
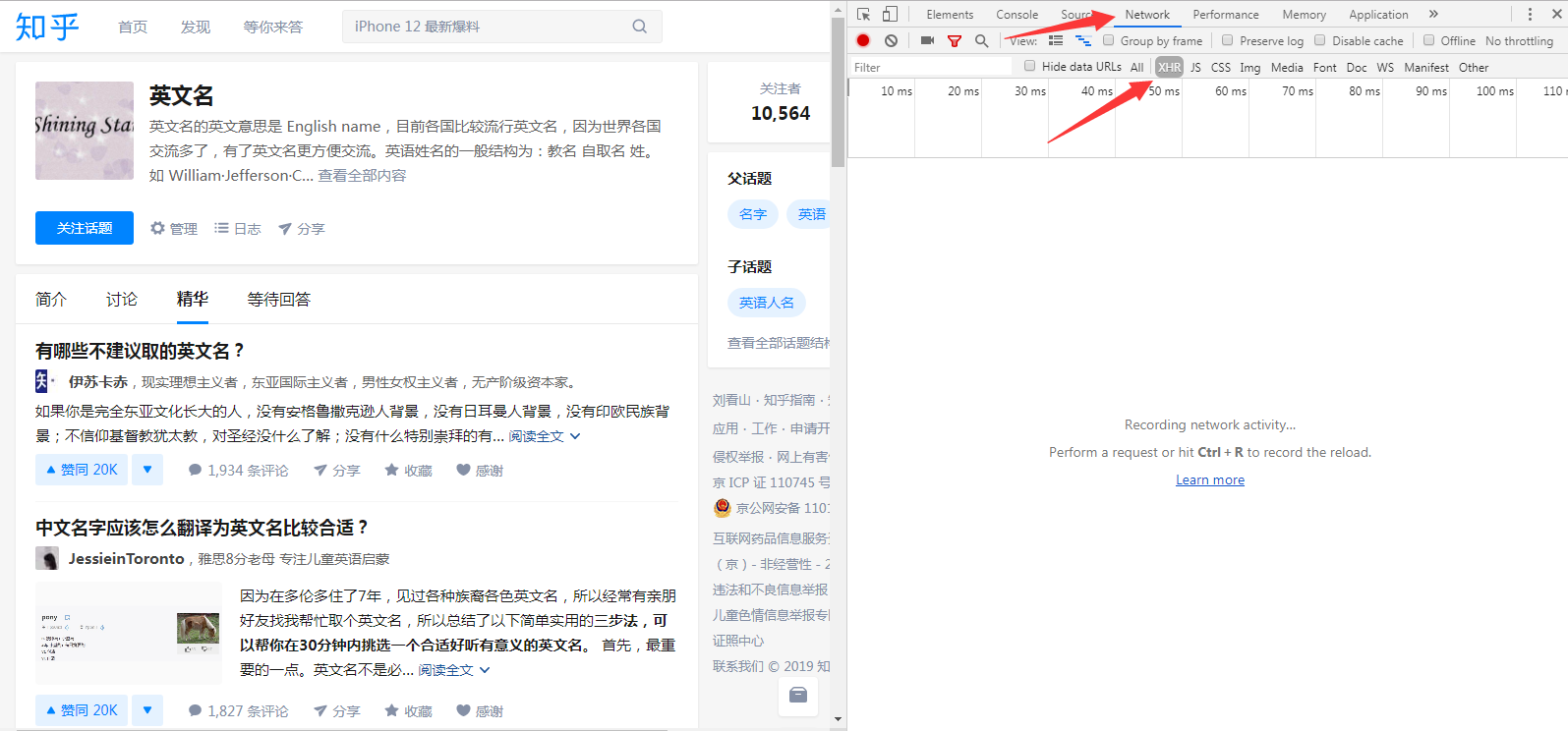
然后将鼠标移动到网页界面用户上(箭头位置),会发现右边多出两个请求信息,如图:
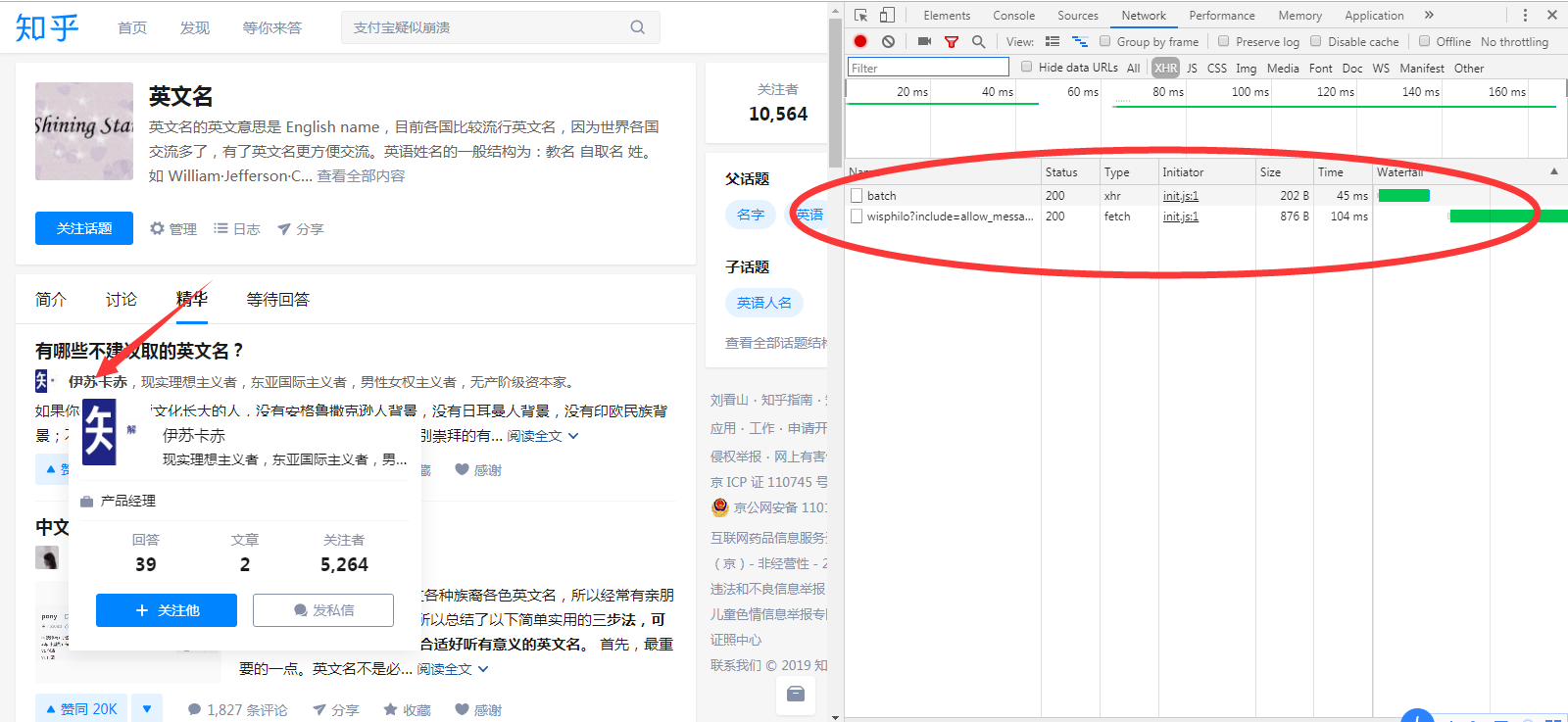
点击下面一个,红色方框内的链接,就是要找的api接口
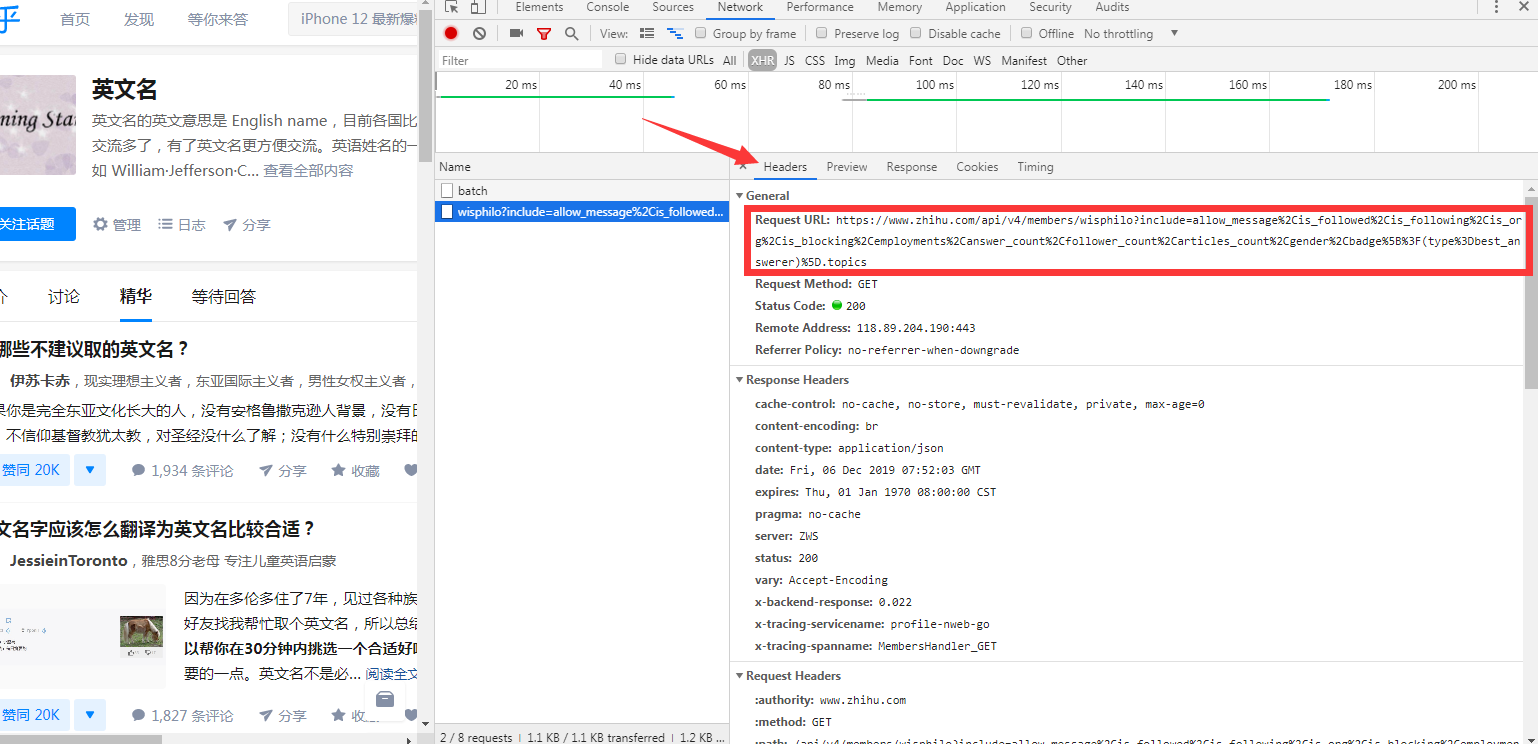
直接用浏览器打开该api即可看到json,如下图
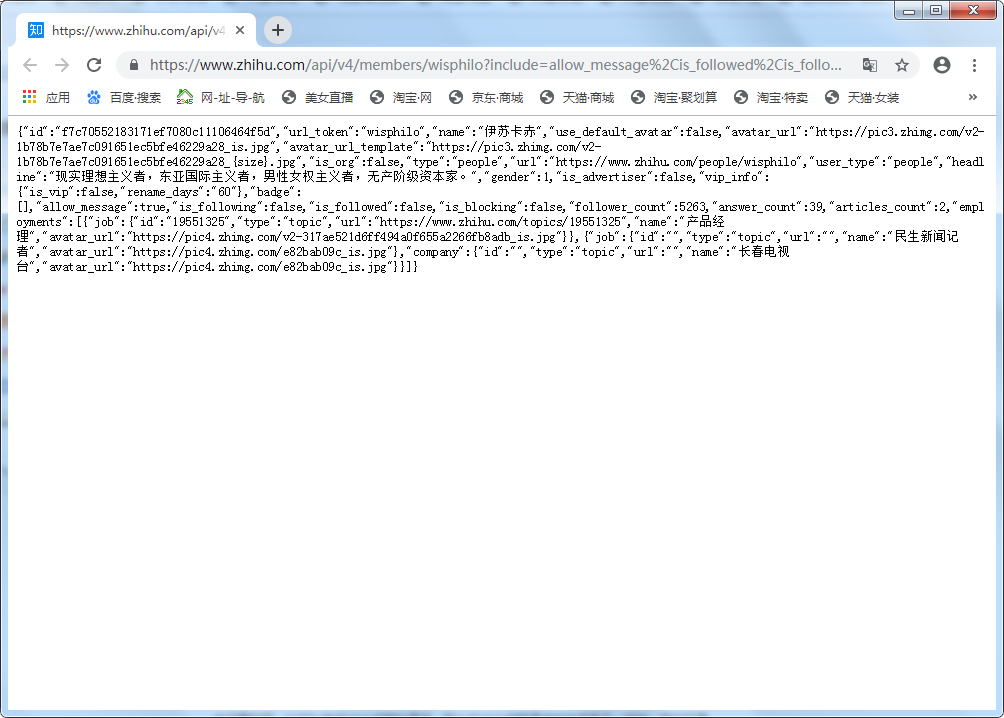
下面用python代码请求该api并解析
import requests
import json
#api
url='https://www.zhihu.com/api/v4/members/wisphilo?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
#header的目的是模拟请求,因为该api设置了反爬取
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
doc=requests.get(url,headers=header)#发起请求
doc.encoding='utf-8'#设置编码为utf-8
data=json.loads(doc.text)#将json字符串转为json
#根据位置查找数据
print('用户名:',data.get('name'))
print('个人描述:',data.get('headline'))
print('职务:'+data.get('employments')[0].get('job').get('name'))
print('回答:',data.get('answer_count'))
print('文章:',data.get('articles_count'))
print('关注者:',data.get('follower_count'))
另外查找数据最好用在线json格式化再查找,不然很难看出自己要的数据在哪eg:

一般网页的api都有规律可寻,用for循环控制变换字符即可实现自动爬取
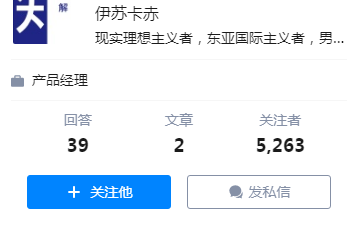
上述代码运行结果:

和该界面对照
以上
python爬取动态网页数据,详解的更多相关文章
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- 利用selenium并使用gevent爬取动态网页数据
首先要下载相应的库 gevent协程库:pip install gevent selenium模拟浏览器访问库:pip install selenium selenium库相应驱动配置 https: ...
- python爬取动态网页2,从JavaScript文件读取内容
import requests import json head = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力.在R语言中,爬取这类网页可以使用RSele ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
随机推荐
- flask框架(八)—自定义命令flask-script、多app应用、wtforms表单验证、SQLAIchemy
自定义命令flask-script 用于实现类似于django中 python3 manage.py runserver ...类似的命令,用命令行启动项目 首先安装:pip3 install fla ...
- 使用VS Code快速编写HTML
VS Code 有自动补全HTML代码方法体的功能 1.打开VS Code并新建文件,点击底部右侧语言模式选项,默认为纯文本(plaintext),将其改为HTML. 2.在空文件第一行输入”!“,光 ...
- WPF内嵌网页的两种方式
在wpf程序中,有时会内嵌网页.内嵌网页有两种方法,一种是使用wpf自带WebBrowser控件来调用IE内核,另一种是使用CefSharp包来调用chrom内核. 一.第一种使用自带WebBrows ...
- VisualStudio 连接 MySql 实现增删查改
首先创建数据库,建立一个用户登录表 2.visualStudio默认是不支持MySql的,要想通过Ado.Net 操作MySql 需要在管理NeGet包添加对MySql.Data 和 MySql.D ...
- VS 引用dll版本冲突问题
1.删除项目中的对应引用: 2.如果是有用到NetGet引用的删除项目中的packages里面的对应包文件: 3.如果是在NetGet中引用的注释项目中packages.config对应的插件名: 4 ...
- 北航OO课程完结总结
什么是OO? 面向对象,是一种编程的思想方法,但是在这门课程中,我们实际学习到的是将理论运用到具体实践上,将自己的想法付诸实践,不断去探索和优化的这一体验. 后两次作业架构总结 本单元两次作业,我们面 ...
- 【开发笔记】- Java读取properties文件的五种方式
原文地址:https://www.cnblogs.com/hafiz/p/5876243.html 一.背景 最近,在项目开发的过程中,遇到需要在properties文件中定义一些自定义的变量,以供j ...
- 为什么Java中一个char能存下一个汉字
在Java中,char的长度是2字节,即16位,2的16次方是65536. 1.如果采用utf-8编码,一个汉字占3个字节,char为什么还能存下一个汉字呢? 参考:https://developer ...
- Centos部署项目
nginx + virtualenv + uwsgi + django + mysql + supervisor 部署项目 一.安装Python3 二.安装MariaDB,并授权远程 grant al ...
- 快速入门 Python 数据分析实用指南
Python 现如今已成为数据分析和数据科学使用上的标准语言和标准平台之一.那么作为一个新手小白,该如何快速入门 Python 数据分析呢? 下面根据数据分析的一般工作流程,梳理了相关知识技能以及学习 ...