Ordered Neurons: Integrating Tree Structures Into Recurrent Neural Networks
这是一篇发表在ICLR2019上的论文,并且还是ICLR2019的Best paper之一。该论文提出了能够学习树结构信息的ON-LSTM模型,这篇论文的开源代码可以在GitHub找到。
自然语言都是层次结构的,小的单元(如词组)堆叠成大的单元(如子句)。当一个大的成分结束时,其内部的所有小成分也要结束。然而标准的LSTM模型无法显式地建模这种层次结构。因此这篇论文通过对神经元进行排序来加入这种归纳偏置(即学习层次信息),所提出的模型叫做ordered neurons LSTM(ON-LSTM)。
引言
自然语言通常都表现为序列形式,比如说话与书写都是序列式表达一个个语言单元。然而语言潜在的结构却不是严格的序列式,而是类似于树结构(比如语法树),这种方式也符合人的认知。从实践的角度看,将树结构集成到神经网络语言模型中可能有以下几个理由:
- 为了获得分层次的语义表示,提升抽象的等级
- 为了建模语言的组成以及处理长期依赖问题
- 为了通过归纳偏置改进生成效果,同时减少训练数据量
一种直接的办法是利用语法解析模型解析句子语法树,但这类有监督方法同样存在许多问题:1)缺少标注数据;2)在某些领域,语法规则不是那么严格(比如网络用语);3)语言在不断变化,语法规则可能会失效。另一方面,无监督地直接学习语法结构(grammer induction)还是一个没有很好解决方式的问题,并且往往非常复杂。
循环神经网络在语言建模方面被证明是相当有效的,它假设数据是序列结构的。但这种假设在语言是非序列结构时可能会出现问题,在捕获长期依赖或者生成任务上出现问题。同时,通过在LSTM中隐式编码树结构也可以实现语法处理机制。
在这篇论文中,作者提出了有序神经元(Ordered Neurons),每个神经元内的信息具有不同的生命周期:高阶神经元存储长期信息,可以保持更多的步数,低阶神经元存储短期信息,可能快速被遗忘。为了避免硬性的对高阶低阶神经元划分,论文还提出了cumax()这种激活函数。最终,模型在Language modeling, unsupervised constituency parsing, targeted syntactic evaluation和logical inference四个任务上进行了实验,在语法分析上优于先前模型,同时在捕获长期依赖和长句生成上也优于标准LSTM。
相关工作
目前已经有许多工作将树结构应用到自然语言处理任务中,并且也证明了在LSTM中引入结构信息对任务十分具有帮助。然而,高效推断这种结构也成为了一个问题。有一部分工作直接进行语法归纳(grammer induction),但这类方法过于复杂难以应用。还有一些工作选择改进循环网络,使用不同时间尺度的循环机制捕获层次信息。但这些工作一般会预先定义好层次的深度。
有序神经元
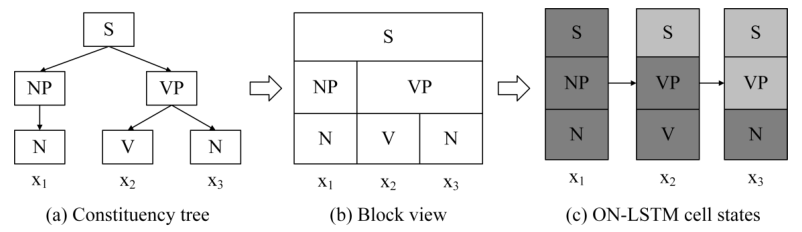
给定一个句子\(S=(x_1,\dots,x_T)\),图中(a)对应于它的成分树,模型的目标是基于可观测的序列数据推断不可观测的树结构信息。像图中(c)中显示的,在每一个时间步的隐状态中,既要包含当前输入(叶子节点)的信息,也要包含更高层次的信息。但隐状态\(h_t\)的维度是固定的(c中为3),在不同的时间步和句子中,各层次的信息又可能有不同的跨度,因此需要动态地将从根节点到叶子节点的每个节点映射到隐状态的一片神经元上。比如从(a)到(c)刚好层次对应,但也可能树的层次有4层,而隐状态的神经元数目只有3。
因此在有序神经元工作中,作者希望高阶的神经元(对应于c中上层)包含长期依赖或者全局信息,这些信息可能持续多个时间步甚至整个过程,低阶神经元(对应于c中下层)编码短期记忆或者局部信息,这些信息只持续较少时间步。也就是说低阶神经元更新的频率要比高阶神经元更快。
ON-LSTM
标准LSTM可以表示为:
\[
f_t = \sigma(W_fx_t + U_f xh_{t-1} + b_f) \\
i_t = \sigma(W_ix_t + U_i xh_{t-1} + b_i) \\
o_t = \sigma(W_ox_t + U_o xh_{t-1} + b_o) \\
\hat{c}_t = \text{tanh}(W_c x_t + U_c h_{t-1} + b_c) \\
h_t = o_t \circ \text{tanh}(c_t) \\
c_t = f_t \circ c_{t-1} + i_t \circ \hat{c_t}
\]
ON-LSTM和标准LSTM的区别就在于\(c_t\)的更新,也就是上面最后的公式。因为遗忘门\(f_t\)和输入门\(i_t\)控制了记忆单元\(c_t\)的更新,而且对于每个神经元这些门都是独立的,因此论文实际上也是改进了遗忘门和输入门。
激活函数 cumax()
为了区分高阶神经元和低阶神经元,并分别对应不同的更新方式,首先需要找到两者的边界,即分割点。论文的做法是希望生成一个n-hot向量\(g=(0,\dots,0,1,\dots,1)\),这个向量共分为两段,一段为全0,一段为全1,模型就可以在两段上实行不同的更新规则。
为了得到上面的向量,论文首先介绍了cumsum这个函数,它表示累计求和,在一个one-hot向量上进行cumsum对应的效果就是将向量分成0,1组成两段,比如
\[
\text{cumsum}((0,0,1,0,0)) = (0,0,1,1,1)
\]
因此上面生成n-hot向量就转换成了生成one-hot向量,即找到一个整数分割点(第一个1的位置)。但是此时分割点取值是离散的,计算梯度是行不通的,因此作者使用了一个软化的办法转而求期望。具体来说,假设位置\(d\)出现1的概率可以用下式表示:
\[
p(d) = \text{softmax}(\dots)
\]
因为\(g\)是由cumsum产生的,因此\(g\)的第\(k\)个位置为1的概率应该是前\(k\)个位置概率的累加和,即
\[
p(g_k=1)=p(d \leq k) = \sum_{i \leq k} p(d=i)
\]
因此最终的向量就可以用作者提出的激活函数cumax()生成,也就是:
\[
\hat{g} = \text{cumax}(\dots) = \text{cumsum}(\text{softmax}(\dots)) = \text{cumsum}((p(1), p(2), \dots, p(k), \dots))
\]
而softmax可以是一个可学习的概率预测网络,因此论文就把找分界点问题变成了一个概率预测问题。
结构化门机制
基于上面的cumax()激活函数,论文提出了自己的主遗忘门\(\tilde{f}_t\)和主输入门\(\tilde{i}_t\):
\[
\tilde{f}_t = \text{cumax}(W_{\tilde{f}}x_t + U_{\tilde{f}}h_{t-1} + b_{\tilde{f}}) \\
\tilde{i}_t = 1 - \text{cumax}(W_{\tilde{i}}x_t + U_{\tilde{i}}h_{t-1} + b_{\tilde{i}})
\]
使用上面的式子,主遗忘门和主输入门生成的向量都是单调的,但主遗忘门是从0到1递增,主输入门是从1到0递减。使用这两个门后,记忆单元的更新规则如下:
\[
w_t = \tilde{f}_t \circ \tilde{i}_t \\
\hat{f}_t = f_t \circ w_t + (\tilde{f}_t - w_t) = \tilde{f}_t \circ (f_t \circ \tilde{i}_t + 1 - \tilde{i}_t) \\
\hat{i}_t = i_t \circ w_t + (\tilde{i}_t - w_t) = \tilde{i}_t \circ (i_t \circ \tilde{f}_t + 1 - \tilde{f}_t) \\
c_t = \hat{f}_t \circ c_{t-1} + \hat{i}_t \circ \hat{c}_t
\]
接下来我们讲怎么理解上面这个更新规则。为了简单起见,我们仍然假设主遗忘门\(\tilde{f}_t\)是\((0,\dots,1,\dots,1)\)类型,对应的主输入门\(\tilde{i}_t\)是\((1,\dots,1,0,\dots,0)\)类型的向量。
其中\(w_t\)是\(\tilde{i}_t\)和\(\tilde{f}_t\)的交集部分,它的形式应该是\((0,\dots,1,\dots,1,0,\dots,0)\)(也可能没有1)。所以,下面我们来讨论一下:
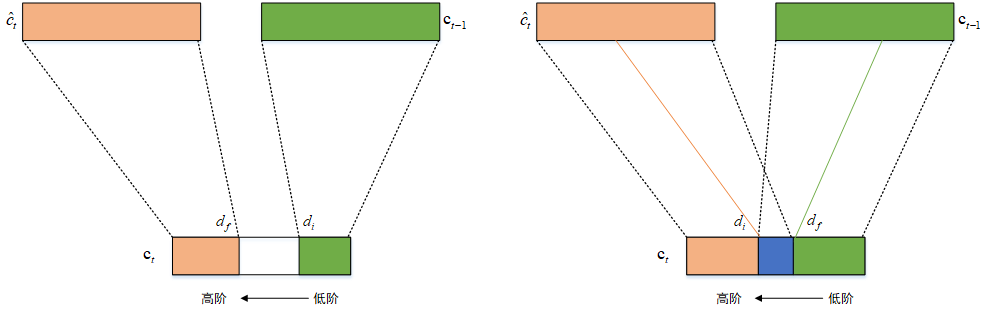
当\(w_t\)全为0时,也就是说两个门没有交集,此时有:
\[
\hat{f}_t = \tilde{f}_t \\
\hat{i}_t = \tilde{i}_t \\
c_t = \hat{f}_t \circ c_{t-1} + \hat{i}_t \circ \hat{c}_t = \tilde{f}_t \circ c_{t-1} + \tilde{i}_t \circ \hat{c}_t
\]
此时记忆单元的更新如上图左边部分所示,\(\tilde{f}_t\)将\(c_{t-1}\)的高阶信息拷贝到\(c_t\),\(\tilde{i}_t\)将\(\hat{c}_t\)的低阶信息拷贝到\(c_t\),而中间不相交区域则没有任何信息。
当\(w_t\)不全为0时,也就是说两个门有交集,此时有:
\[
c_t = (\tilde{f}_t - w_t) \circ c_{t-1} + (\tilde{i}_t -w_t) \circ \hat{c}_t + [f_t \circ w_t \circ c_{t-1} + i_t \circ w_t \circ \hat{c}_t]
\]
此时记忆单元的更新如上图右边部分所示,更新被拆分为三段。主遗忘门和主输入门的作用还是一样,但是交集区域,由两个门共同作用,也就退化成了标准的LSTM形式。
主遗忘门\(\tilde{f}_t\)控制记忆的擦除,它的分割点是\(d_f\)。\(d_f\)较大表示更多的高阶信息要被擦除更新掉。主输入门\(\tilde{i}_t\)控制记忆的写入,它的分割点是\(d_i\)。\(d_i\)较大表示更多的局部信息生命周期变长。而\(w_t\)是两个门的交叉分布,这部分既包含了先前的信息也包含了当前输入信息,因此这部分使用标准LSTM处理。
因为这些主门只是关注于粗粒度的控制记忆,因此使用隐状态的维度进行计算会带来很大的计算量,也是没有必要的。因此实际上论文将门的维度定义为\(D_m=\dfrac{D}{C}\),其中\(D\)是隐状态维度,\(C\)是块大小因子(chunk size factor)。在和\(f_t\)与\(i_t\)逐元素相乘之前,将每个神经元重复\(C\)次以恢复\(D\)的维度。这种降维方式能够有效减少ON-LSTM的参数。用了这种方式后,原先一个神经元对应一个门就变成了连续\(C\)个神经元共享一个门。
实验
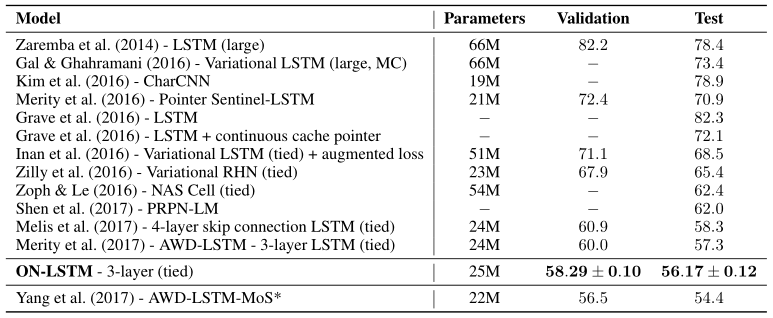
论文在language modeling,unsupervised constiuency parsing, targeted syntactic evaluation和logical inference四个任务上进行了实验。在第一个任务中的表现如下图所示:
这里重点提一下unsupervised constiuency parsing这个任务,这个任务的评测方法是将模型推断出来的树结构和人工标注的结构进行对比。为了使用预训练的模型推断一个句子的树结构,论文首先将隐状态初始化为全零,然后将句子输入模型。在每个时间步,都对\(d_f\)计算期望:
\[
\hat{d}_f = \mathbb{E}[d_f] = \sum_{k=1}^{D_m}k p_f (d_t=k) = \sum_{k=1}^{D_m} \sum_{i=1}^k p_f(d_t = k) = D_m - \sum_{k=1}^{D_m} \tilde{f}_{tk}
\]
其中\(p_f\)是主遗忘门分割点的概率分布,\(D_m\)是隐状态的大小。给定\(\hat{d}_f\),可以使用自顶向下的贪心算法进行解析。首先对\(\{\hat{d}_f\}\)进行排序,对于序列中的第一个\(\hat{d}_f\),将句子分成\(((x_{<i}), (x_i, (x_{>i})))\),然后对\((x_{<i})\)和\((x_{>i})\)两部分再次运用上述方法,知道每个部分都只包含一个单词。
Ordered Neurons: Integrating Tree Structures Into Recurrent Neural Networks的更多相关文章
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- The Unreasonable Effectiveness of Recurrent Neural Networks (RNN)
http://karpathy.github.io/2015/05/21/rnn-effectiveness/ There’s something magical about Recurrent Ne ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第一部分)
由于本章过长,分为两个部分,这是第一部分. 这几年提到RNN,一般指Recurrent Neural Networks,至于翻译成循环神经网络还是递归神经网络都可以.wiki上面把Recurrent ...
- 《转》循环神经网络(RNN, Recurrent Neural Networks)学习笔记:基础理论
转自 http://blog.csdn.net/xingzhedai/article/details/53144126 更多参考:http://blog.csdn.net/mafeiyu80/arti ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- Paper Reading - Deep Captioning with Multimodal Recurrent Neural Networks ( m-RNN ) ( ICLR 2015 ) ★
Link of the Paper: https://arxiv.org/pdf/1412.6632.pdf Main Points: The authors propose a multimodal ...
- Multi-Dimensional Recurrent Neural Networks
Multi-Dimensional Recurrent Neural Networks The basic idea of MDRNNs is to replace the single recurr ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- cs231n spring 2017 lecture10 Recurrent Neural Networks 听课笔记
(没太听明白,下次重新听一遍) 1. Recurrent Neural Networks
随机推荐
- ArcGIS Enterprise 10.7.1新特性:批量发布服务
ArcGIS Enterprise 10.7.1提供了批量发布GIS服务的功能,能大大简化GIS系统管理员的工作量. 作为发布人员和管理人员,支持向Portal for ArcGIS添加云存储.文件共 ...
- 原创:C++实现的可排序的双向链表
学习C++有一周了,今天用C++设计了一个双向链表,这个链表有排序功能,默认按升序排列,接受的参数可以是数字,也可以是字符串.现在把自己写的代码,分享出来.如果链表中接受的对象为Lexeme,可以用于 ...
- P5025 [SNOI2017]炸弹
原题链接 https://www.luogu.org/problem/P5025 闲话时刻: 第一道 AC 的黑题,虽然众人皆说水... 其实思路不是很难,代码也不是很难打,是一些我们已经学过的东西 ...
- C 库函数 - strcspn()
定义 size_t strcspn(const char *str1, const char *str2) 参数 str1 -- 要被检索的 C 字符串. str2 -- 该字符串包含了要在 str1 ...
- CentOS 6.5开放端口方法
lsof -i tcp:80 列出所有端口 netstat -ntlp 1.开启端口(以80端口为例) 方法一: /sbin/iptables -I ...
- Unity3D ACT动作游戏《武士2》项目源码附教程
武士二源码亲测unity2018.3.6能运行 仅供学习附有教程 教程完整73课,网上大部分一般为65课, 教程大小27GB,mp4格式 整理不易 扫码时备注或说明中留下邮箱 付款后如未回复请至htt ...
- Java TreeMap使用
场景: 随机生成50个10到50的数字.然后顺序输出每个数字出现的次数 实现原理: 使用TreeMap,默认带了顺序排序的功能 public static void main(String[] arg ...
- 8款超好用的SVG编辑工具用起来
随着响应式网页的发展,对于内容呈现的要求也越来越高,尤其是图像.为了在各种设备上能实现自然伸缩或扩展而不影响图片质量,所以矢量图形(SVG)正变得越来越受欢迎. 大家都知道,在计算机图形学中,有两种主 ...
- Java默认文件目录
今天看到Ehcache中设置持久化的配置: <diskStore path="java.io.tmpdir" /> 好奇这个java.io.temdir是哪个目录,于是 ...
- ActiveMQ持久化
ActiveMQ中,持久化是值对消息数据的持久化.在ActiveMQ中,默认的消息是保存在内存中的.当内存容量不足的时候,或ActiveMQ正常关闭的时候,会将内存中的未处理的消息持久化到磁盘中.具体 ...