python爬虫-有道翻译-js加密破解
有道翻译-js加密破解
这是本地爬取的网址:http://fanyi.youdao.com/
一、分析请求
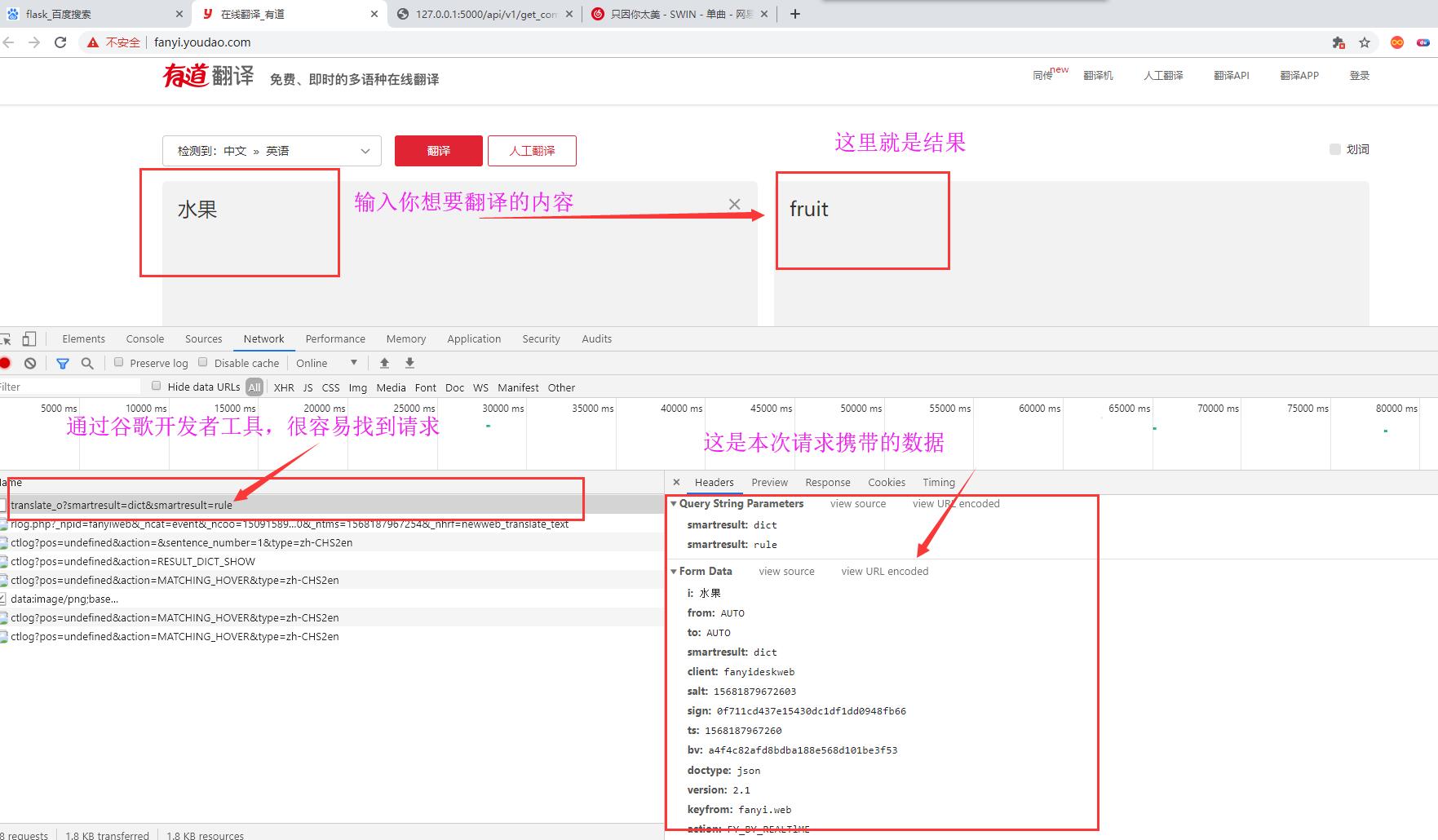
我们在页面中输入:水果,翻译后的英文就是:fruit。请求携带的参数有很多,先将参数数据保存下来,做一个记录。
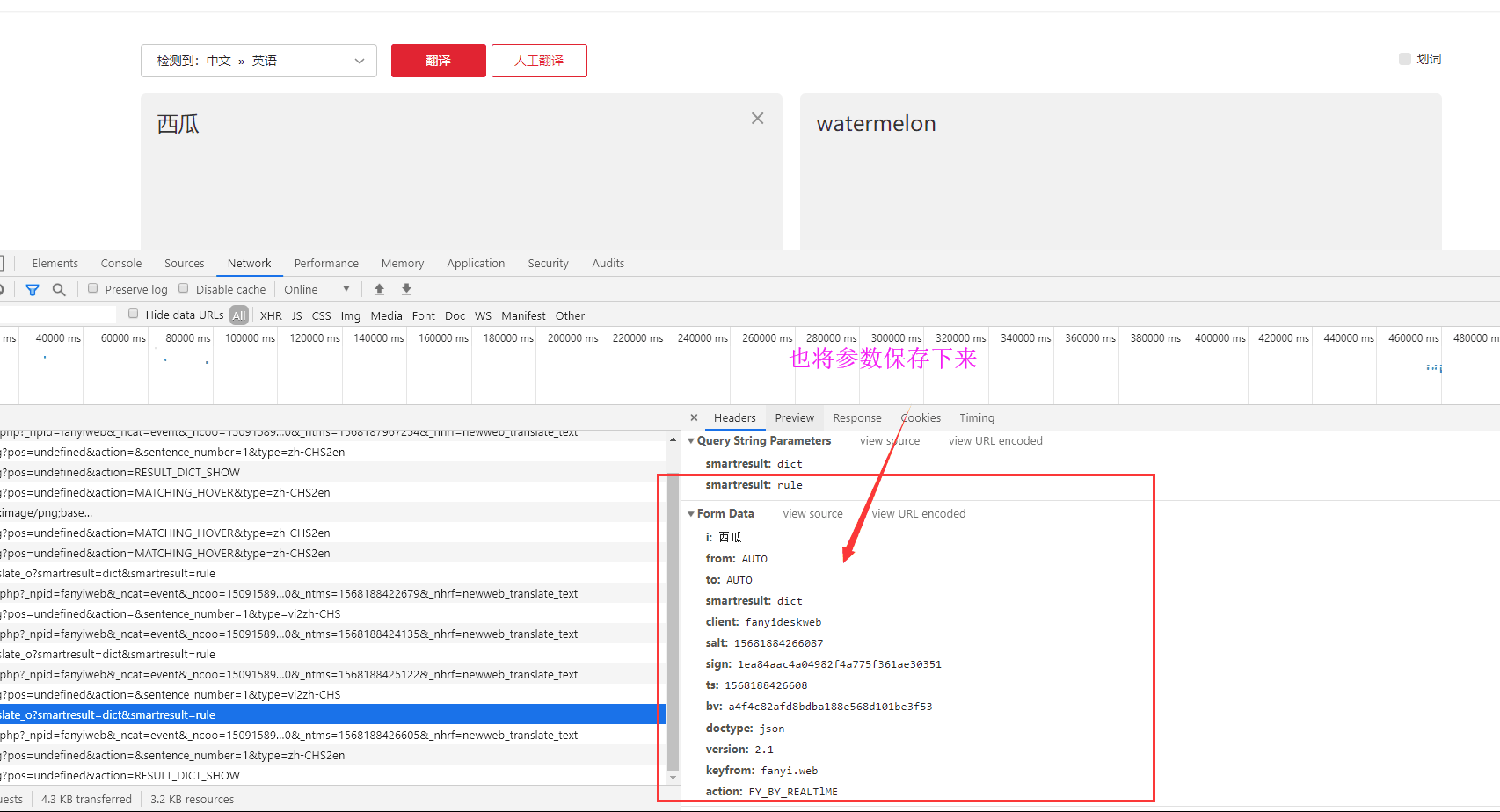
我们再输入一个新的词:西瓜
i: 西瓜
from: AUTO
to: AUTO
smartresult: dict
client: fanyideskweb
salt: 15681884266087
sign: 1ea84aac4a04982f4a775f361ae30351
ts: 1568188426608
bv: a4f4c82afd8bdba188e568d101be3f53
doctype: json
version: 2.1
keyfrom: fanyi.web
action: FY_BY_REALTlME
i: 水果
from: AUTO
to: AUTO
smartresult: dict
client: fanyideskweb
salt: 15681879672603
sign: 0f711cd437e15430dc1df1dd0948fb66
ts: 1568187967260
bv: a4f4c82afd8bdba188e568d101be3f53
doctype: json
version: 2.1
keyfrom: fanyi.web
action: FY_BY_REALTlME
对比一下,这两次请求携带的数据哪些参数不一样:很容易看出i,salt,ts,sign这四个参数是不一样的。i:就是你需要翻译的词,ts的话应该能够猜到是时间戳,salt他就是ts参数后面加了一个数字对吧。现在的话,我们就差sign的参数不知道是什么了吧。它是32位的数据,不出意外的话应该就是md5加密字符串了。
二、加密参数破解
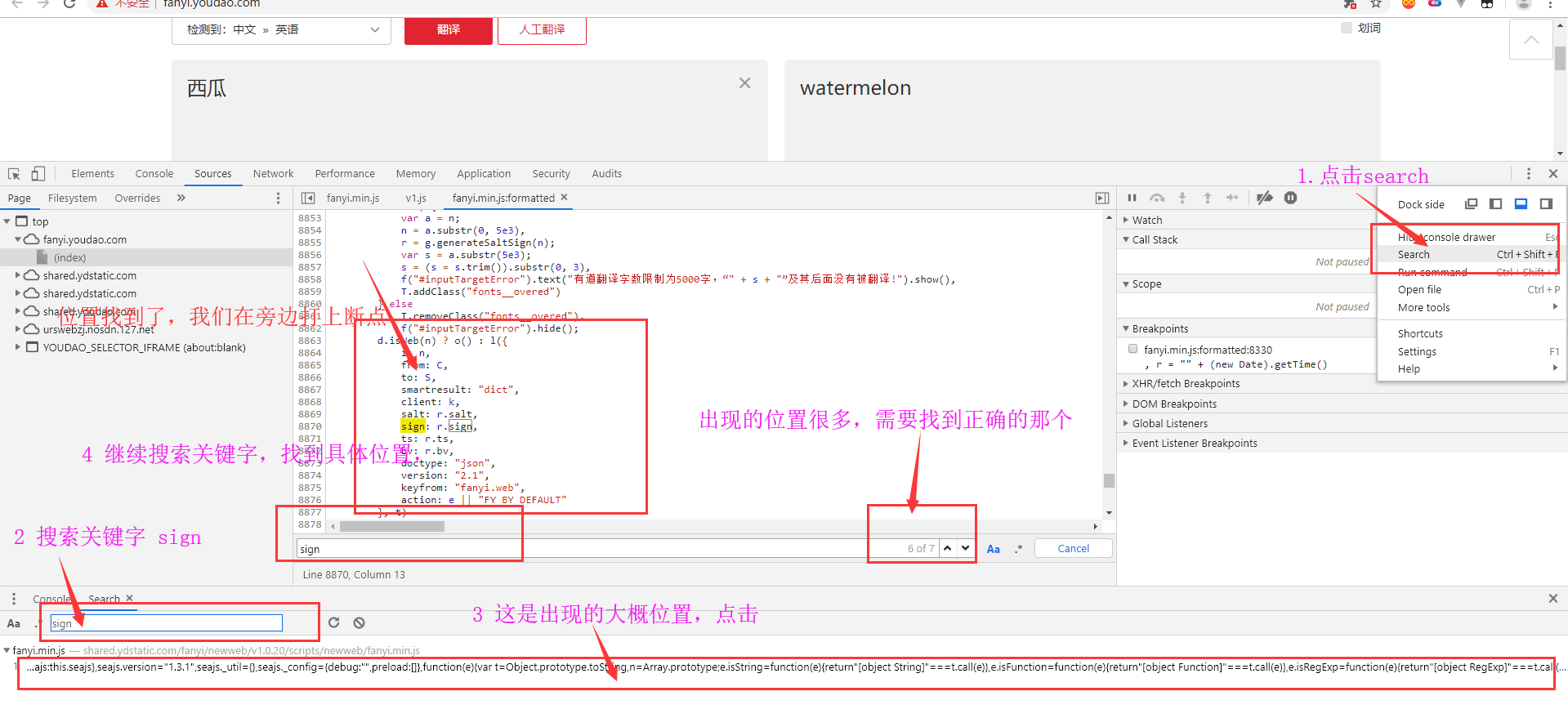
就差sign不知道是怎么生成的,那就以sign为关键字,进行搜索就好。看看它出现的位置。
打好断点之后,我们在换个词进行翻译:香蕉

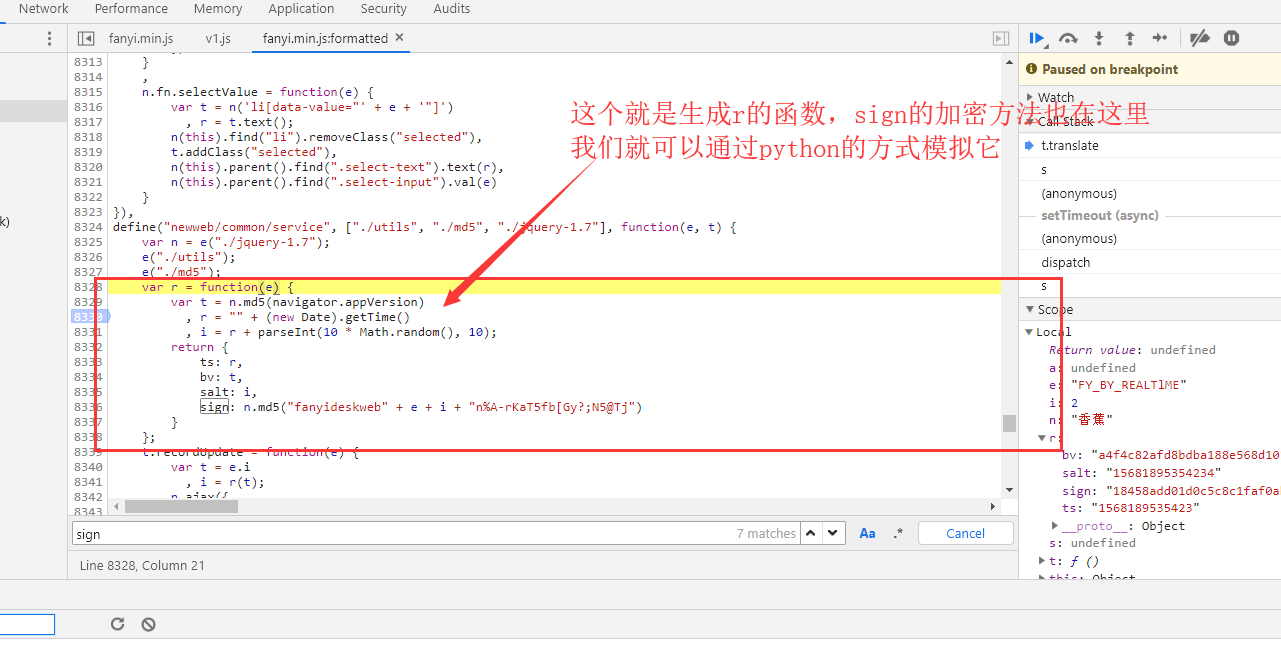
加密函数我就不解释了,navigator.appVersion就是浏览器的user-agent
def get_encrypt_data(keyword):
t = "5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
bv = hashlib.md5(bytes(t, encoding="utf-8")).hexdigest()
ts = str(int(round(time.time(), 3) * 1000))
salt = ts + str(random.randint(1, 10))
sign = hashlib.md5(
bytes("fanyideskweb" + keyword + salt + "n%A-rKaT5fb[Gy?;N5@Tj", encoding="utf-8")).hexdigest()
return ts, bv, salt, sign
三、成功响应:
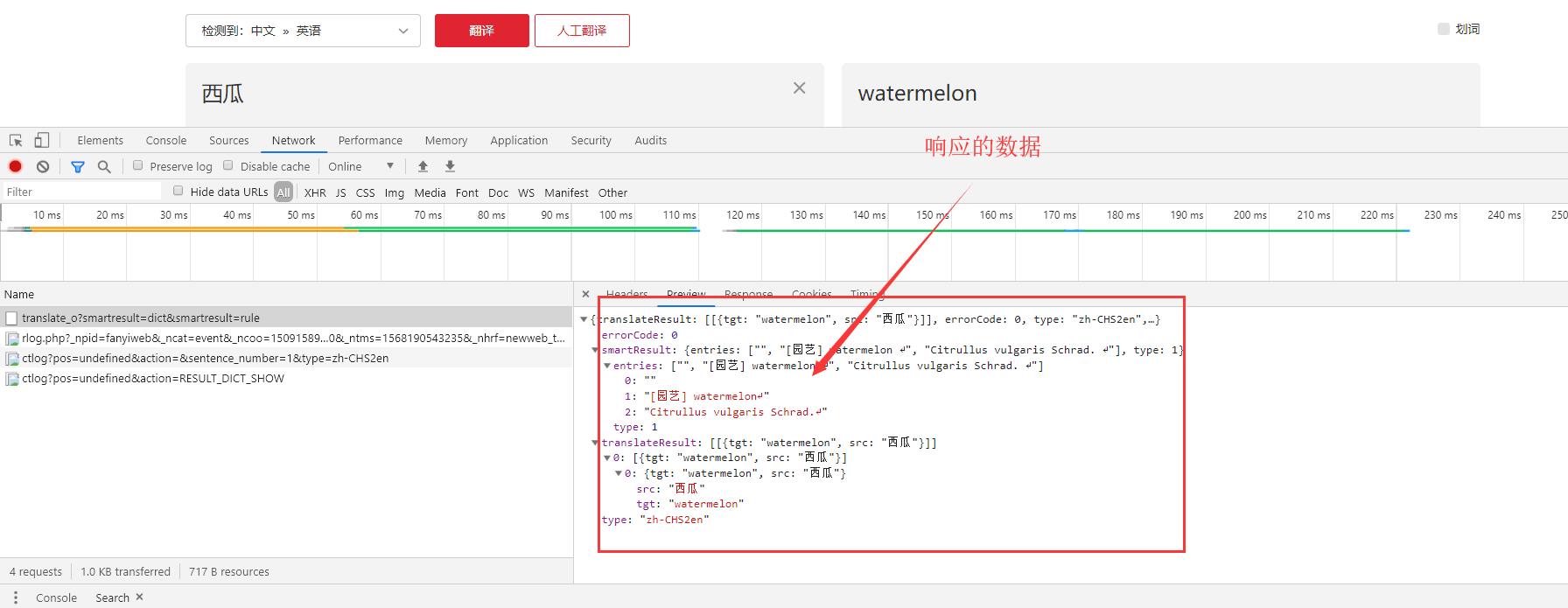
import requests, time, random, hashlib
from fake_useragent import UserAgent
ua = UserAgent()
url = "http://fanyi.youdao.com/translate_o"
headers = {
"User-Agent": ua.random,
"Referer": "http://fanyi.youdao.com/",
}
s = requests.Session()
def get_encrypt_data(keyword):
t = "5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
bv = hashlib.md5(bytes(t, encoding="utf-8")).hexdigest()
ts = str(int(round(time.time(), 3) * 1000))
salt = ts + str(random.randint(1, 10))
sign = hashlib.md5(
bytes("fanyideskweb" + keyword + salt + "n%A-rKaT5fb[Gy?;N5@Tj", encoding="utf-8")).hexdigest()
return ts, bv, salt, sign
def param():
dic = {}
dic["i"] = keyword,
dic["from"] = "AUTO",
dic["to"] = "AUTO",
dic["smartresult"] = "dict",
dic["client"] = "fanyideskweb",
dic["doctype"] = "json",
dic["version"] = "2.1",
dic["keyfrom"] = "fanyi.web",
dic["action"] = "FY_BY_REALTlME",
dic["ts"], dic["bv"], dic["salt"], dic["sign"] = get_encrypt_data(keyword)
return dic
if __name__ == '__main__':
re = s.get("http://fanyi.youdao.com/", headers=headers)
keyword = input("输入你想翻译的内容>>>:").strip()
response = s.post(url=url, data=param(), headers=headers)
msg = response.json().get("translateResult")[0][0]
print('''翻译内容>>>:{}
翻译结果>>>:{}'''.format(msg.get("src"), msg.get("tgt")))
python爬虫-有道翻译-js加密破解的更多相关文章
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- 有道翻译js加密参数分析
平时在渗透测试过程中,遇到传输的数据被js加密的比较多,这里我以有道翻译为例,来分析一下它的加密参数 前言 这是有道翻译的界面,我们随便输入一个,抓包分析 我们发现返回了一段json的字符串,内容就是 ...
- Python爬虫有道翻译接口
import urllib.request import urllib.parse import json import hashlib from datetime import datetime i ...
- 爬虫破解js加密(一) 有道词典js加密参数 sign破解
在爬虫过程中,经常给服务器造成压力(比如耗尽CPU,内存,带宽等),为了减少不必要的访问(比如爬虫),网页开发者就发明了反爬虫技术. 常见的反爬虫技术有封ip,user_agent,字体库,js加密, ...
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- Python 爬虫js加密破解(三) 百度翻译 sign
第一步: 模拟抓包分析加密参数 第二步: 找到加密字段 调试出来的sign和抓取得到的数据一致,都是 275626.55195 第三部: 分析js加密方法 第四部:运行js代码: 仅供交流学习使用
- Python 爬虫js加密破解(四) 360云盘登录password加密
登录链接:https://yunpan.360.cn/mindex/login 这是一个md5 加密算法,直接使用 md5加密即可实现 本文讲解的是如何抠出js,运行代码 第一部:抓包 如图 第二步: ...
- Python 使用有道翻译
最近想将一些句子翻译成不同的语言,最开始想使用Python向有道发送请求包的方式进行翻译. 这种翻译方式可行,不过只能翻译默认语言,不能选定语言,于是我研究了一下如何构造请求参数,其中有两个参数最复杂 ...
- Python 实现有道翻译命令行版
一.个人需求 由于一直用Linux系统,对于词典的支持特别不好,对于我这英语渣渣的人来说,当看英文文档就一直卡壳,之前用惯了有道词典,感觉很不错,虽然有网页版的但是对于全站英文的网页来说并不支持.索性 ...
随机推荐
- ansible-playbook-常用
创建软链:file: - name: create link hosts: "{{hosts_ip}}" tasks: - name: create link file: src= ...
- 敏捷项目管理—Scrum框架总结
Scrum中的角色 Scrum Master——项目负责人.项目经理 保护团队不受外界干扰,是团队的领导和推进者,负责提升 Scrum 团队的工作效率,控制 Scrum 中的“检视和适应”周期过程.与 ...
- linux驱动由浅入深系列:高通sensor架构实例分析之二(驱动代码结构)【转】
本文转载自:https://blog.csdn.net/radianceblau/article/details/73498303 本系列导航: linux驱动由浅入深系列:高通sensor架构实例分 ...
- 【转载】 TensorFlow学习——tf.GPUOptions和tf.ConfigProto用法解析
原文地址: https://blog.csdn.net/c20081052/article/details/82345454 ------------------------------------- ...
- IfcColumn
IfcColumn is a vertical structural member which often is aligned with a structural grid intersection ...
- full text search
definition https://www.techopedia.com/definition/17113/full-text-search A full-text search is a comp ...
- HTML和CSS个人笔记
目录 定位 文字显示在图片上 ul的li元素的小圆点换成图片 关于Bootstrap的响应式 不要在container之外使用row 不要使用padding的时候固定高度 不要使用<hr p标签 ...
- 小于K的两数之和
给你一个整数数组 A 和一个整数 K,请在该数组中找出两个元素,使它们的和小于 K但尽可能地接近 K,返回这两个元素的和. 如不存在这样的两个元素,请返回 -1. 示例1: 输入:A = [34,23 ...
- distinct 数组去重,对象去重
distinct 操作符可以用来去重,将上游重复的数据过滤掉. import { of } from 'rxjs'; import { distinct} from 'rxjs/operators'; ...
- Java生成艺术二维码也可以很简单
原文点击: Quick-Media Java生成艺术二维码也可以很简单 现在二维码可以说非常常见了,当然我们见得多的一般是白底黑块,有的再中间加一个 logo,或者将二维码嵌在一张特定的背景中(比如微 ...