标签一致项(LC-KSVD)-全文解读
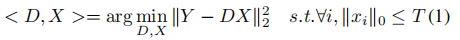 ,
,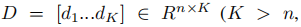 (过完备字典),
(过完备字典),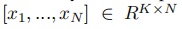 是输入信号Y的稀疏编码。T是稀疏约束项,(每个信号在分解后都少于T个原子),||Y-DX||22表示重建误差。通过最小化重构误差和满足稀疏约束来实现D的构造。K-SVD算法是一种最小化方程1能量的迭代方法,学习一个用于信号稀疏表示的重建字典。该方法效率高,适用于图像复原和压缩等领域。根据D,Y的稀疏编码X:
是输入信号Y的稀疏编码。T是稀疏约束项,(每个信号在分解后都少于T个原子),||Y-DX||22表示重建误差。通过最小化重构误差和满足稀疏约束来实现D的构造。K-SVD算法是一种最小化方程1能量的迭代方法,学习一个用于信号稀疏表示的重建字典。该方法效率高,适用于图像复原和压缩等领域。根据D,Y的稀疏编码X: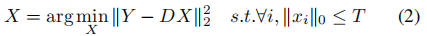
2.2 字典学习用于分类
稀疏编码x可以直接的作为特征进行分类。通过模型参数W∈Rm×K,可以得到一个好的分类器。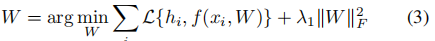
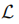 :分类损失函数,hi是yi的标签,λ1:正则参数。字典学习和分类器分离可能使D成为分类的次优选择,联合学习字典和分类模型,尝试优化用于分类任务的学习字典,结合字典D和w的目标函数定义为:
:分类损失函数,hi是yi的标签,λ1:正则参数。字典学习和分类器分离可能使D成为分类的次优选择,联合学习字典和分类模型,尝试优化用于分类任务的学习字典,结合字典D和w的目标函数定义为: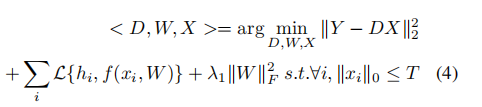
这些方法需要学习相对较大的字典来获得较好的分类性能,导致计算量较大。当只能基于多个两两分类器的分类体系结构来获得好的分类结果时,这个问题会变得更加严重。
· 通过联合字典和分类器构造的目标函数的简单扩展,我们将证明仅使用一个小的单一的统一字典来得到良好的分类结果。这个扩展强制了一个标签一致性约束在字典上-直观的说,字典元素在分类过程中贡献的类分布在一个类中达到了顶峰。这个方法时LC-KSVD,利用了原始的K-SVD求解。
3 Label Consistent K-SVD
目标是利用输入信号的有监督信息学习一个重建的和判决字典。每个字典项都将被选中,这样它就代表了训练信号的一个子集,理想情况下来自单个类,因此,每一个字典项都可以与特征的标签相关联。因此,在我们的方法中,字典项和标签之间有明确的对应关系。
在方程1的目标函数中加入标签一致性正则项,联合分类错误误差和标签一致性正则项对学习具有更平衡的重构能力和辨别能力的词典的影响。分别称他们为 LC-KSVD1和LC-KSVD2.
3.1 LC-KSVD1
线性分类器的性能依赖于输入的稀疏编码x的判别性,对于用D得到的可判别性稀疏编码x,用于字典构建的目标函数定义为:
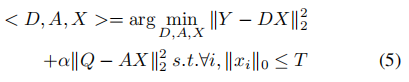
其中α是是控制重建和标签一致正则化之间的相对贡献。Q = [q1...qN]∈RK×N是用于分类的输入信号Y的判决稀疏编码。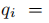
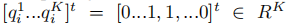 是和输入信息yi相对应的稀疏编码,条件是qi的非零值出现在输入信号yi和字典项dk共享相同标签的索引处。A是一个线性转换矩阵。定义的转换函数,g(x; A) = Ax,将原始的稀疏编码x在稀疏特征空间中更具判决性
是和输入信息yi相对应的稀疏编码,条件是qi的非零值出现在输入信号yi和字典项dk共享相同标签的索引处。A是一个线性转换矩阵。定义的转换函数,g(x; A) = Ax,将原始的稀疏编码x在稀疏特征空间中更具判决性

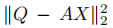 表示判决稀疏编码误差,强使稀疏编码X接近判决稀疏编码Q。它使来自下相同类的信号有非常相似的稀疏表示,利用简单分类器就能取得好的分类性能。
表示判决稀疏编码误差,强使稀疏编码X接近判决稀疏编码Q。它使来自下相同类的信号有非常相似的稀疏表示,利用简单分类器就能取得好的分类性能。
3.2 LC-KSVD2
为了使分类最优,将分类错误作为一项添加到目标函数中。在此利用了一个线性预测分类器 f(x;W) = Wx.目标函数用于学习一个具有重建和判别能力的字典D。定义如下:
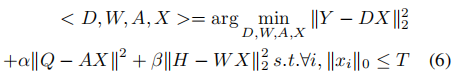
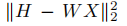 表示分类误差,W表示分类器参数。H=[h1...hN ]∈Rm×N是输入信号Y的类标签。hi = [0,0..1...0,0]∈Rm 是yi相应的标签向量,非零位置表示yi的类别,α和β是是控制相应项的相对贡献。
表示分类误差,W表示分类器参数。H=[h1...hN ]∈Rm×N是输入信号Y的类标签。hi = [0,0..1...0,0]∈Rm 是yi相应的标签向量,非零位置表示yi的类别,α和β是是控制相应项的相对贡献。
假设判决稀疏编码X' = AX , A∈RK×K,D' = DA-1,W'=WT-1,(wx = w'x',W'应该为WA-1)公式6重写为
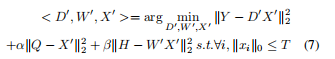
第一项是重建误差,第二项是判决稀疏编码误差,第三项是分类误差。
这种方式学习的字典与训练数据的底层结构相适应,不管字典的大小,都将生成有区别的稀疏编码X,这些稀疏编码可以被分类器直接利用。稀疏编码x的判别性质对线性分类器的性质非常重要。
优化过程:LC-KSVD1 ,LC-KSVD2采用相同的方法,LCKSVD1将方程8和14中的H,W分类排除在外。在训练过程中,首先由公式5计算D,A,X,然后利用公式14对矩阵W进行分类训练。
3.3 优化
利用有效的K-SVD算法对所有的参数进行优化。方式6重写为
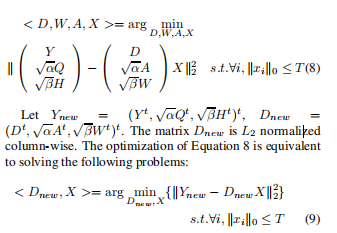
xRk:X的第k行,
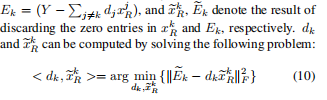

D,A,W同步,避免了局部最小化。
3.3.1 初始化 LC-KSVD
对于d0,我们在每个类中使用几个k-svd迭代,然后合并每个k-svd的所有输出(即从每个类学习的字典项)。然后,每个字典项dk的标签根据其对应的类初始化,并且在1700整个字典学习过程1中保持固定,尽管dk在学习过程中被更新。字典元素被统一地分配给每个类,元素的数量与字典的大小成比例。A0采用了多元岭回归模型,二次方损失,L2范数正则。

3.4 分类方法
D = {d1,...dk},A = {a1,...ak},

4.实验
扩展YaleB和AR数据集中使用的特征描述符是任意的人脸,将一张人脸投影到一个随机向量生成的。扩展YaleB是504维,AR是540维。Caltech101数据集,首先从16*16的块中提取sift描述符,是由步长6像素大小的网格密采样得到的,然后再提取sift的基础上,采用1*1,2*2,4*4的网格提取空间金字塔特征。为了训练金字塔的码本,我们使用k=1024的标准k-means聚类。最后将空间金字塔降至3000维。
在空间金字塔的每个空间子区域中,矢量量化码被汇集在一起以形成汇集特征。这些来自每个子区域的集合特征被连接并规范化为图像的最终空间金字塔特征。caltech101数据集的稀疏代码是根据空间金字塔特征计算的。这有两种池方法:和池化:xout = x1+, ..., +xn,最大池化:xout = max(x1, ..., xn),xi是矢量量化码。这些特征归一化:
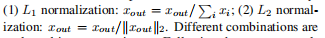 ,我们的实验评估了不同的组合。按照常用的评价方法,对训练图像和测试图像进行10次不同随机的重复实验,以获得可靠的结果。最终识别率报告为每次运行的平均值。我们所有实验中使用的稀疏因子是30。
,我们的实验评估了不同的组合。按照常用的评价方法,对训练图像和测试图像进行10次不同随机的重复实验,以获得可靠的结果。最终识别率报告为每次运行的平均值。我们所有实验中使用的稀疏因子是30。
4.1 扩展YaleB数据集
此数据集包括2414张38个人的图片,一个人约64张图像。原始原始被裁剪为192*168。具有光照条件和表达式的不同,此数据集很具有挑战性。随机选取每个人32张图片作为训练,其他作为测试。每张图片用随机生成矩阵投影为504维的向量,该向量具有从零均值正态分布随机生成的矩阵。矩阵的每一行都是L2标准化的。学习的字典包括570个原子,一个人平均15个原子。字典原子和标签是对应的。
α和β设置为16和4,分别计算带有很强光照的准确率,和除去光照的图片的准确率,另外,对所有测试图片的时间求了平均,来计算一张测试图片的时间
4.2 AR数据集
126个人的图像超过4000找种颜色,每个人有26个人脸图像。相比较扩展YaleB数据集,此数据集包括更多的面部多样性包括不同的光照条件,不同的表情和不同的‘伪装’(眼镜,围巾)。
数据集包括50个男人和50个女人共2600张图像,每一个人20张作为训练,6张作为测试。每张人脸大小165*120,用随机的生成矩阵投影成540维的向量。
学习的字典有500个原子,一个人有5个,字典原子和标签有对应关系。
比较单张测试图像时间。
4.3 caltech 101数据集
102个类,共9144张图片。每一类图片数目从31到800不等。每一类将5,10,15,20,25,和30训练,其余作为测试。
每一类随机选取30张图片作为训练,利用不同的字典原子,K = 510,1020,1530,2040,3060;
计算一张测试图片所用时间。
标签一致项(LC-KSVD)-全文解读的更多相关文章
- PyQt(Python+Qt)学习随笔:工具箱(QToolBox)的用途及标签部件项(tabbed widget item)作用介绍
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 1.概述 toolBox工具箱是一个容器部件,对应类为QToolBox,在其内有一列从上到下顺序排列 ...
- 联合CRF和字典学习的自顶向下的视觉显著性-全文解读
top-down visual saliency via joint CRF anddictionary learning 自顶向下的视觉显著性是使用目标对象的可判别表示和一个降低搜索空间的概率图来进 ...
- torch_12_BigGAN全文解读
1.摘要: 尽管近来生成图片模型取得了进步,成功生成了高分辨率的图片,但是在复杂的数据集中,样本的多样性仍然是难以捉摸的目标.本文尝试在大规模上训练生成对抗网络,并研究这种规模下的不稳定性.我们发现将 ...
- DEDECMS标签调用汇总啊
非常有用的标签调用的方法 关键描述调用标签: <meta name="keywords" content="{dede:field name='keywords'/ ...
- RFID标签
定义: RFID无线射频识别是一种非接触式的自动识别技术,它通过射频信号自动识别目标对象并获取相关数据,识别工作无须人工干预,可工作于各种恶劣环境.RFID技术可识别高速运动物体并可同时识别多个电子标 ...
- dede标签调用
关键描述调用标签: <meta name="keywords" content="{dede:field name='keywords'/}">&l ...
- 织梦dedecms模板调用标签大全-提高制作模板速度
关键描述调用标签: ——————————————————————————–模板路径调用标签: {dede:field name=’templeturl’/}—————————————————————— ...
- 最全的dedeCMS标签调用技巧和大全
1. 页面php方法获取字段 $refObj->Fields['id']; 2. 在页面上使用PHP连接数据库查询 {dede:php} $db = new DedeSql(false); $ ...
- HTML中的<select>标签如何设置默认选中的选项
方法有两种. 第一种通过<select>的属性来设置选中项,此方法可以在动态语言如php在后台根据需要控制输出结果. 1 2 3 4 5 < select id = " ...
随机推荐
- AES加解密异常java.security.InvalidKeyException: Illegal key size
AES加解密异常 Java后台AES解密,抛出异常如下:java.security.InvalidKeyException: Illegal key size Illegal key size or ...
- tomcat的基本应用
1.JVM基本介绍 JAVA编译型 ---> 编译 C 编译型---> linux --->编译一次 windows --->编译一次 macos ubuntu 跨平台 移值型 ...
- Java面试复习(纯手打)
1.面向对象和面向过程的区别: 面向过程比面向对象高.因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素得时候,比如单片机.嵌入式开发.Linux/Unix等一般采用面向过 ...
- 【Qt编程】基于QWT的曲线绘制及图例显示操作——有样点的实现功能
在<QWT在QtCreator中的安装与使用>一文中,我们完成了QWT的安装,这篇文章我们讲讲基础曲线的绘制功能. 首先,我们新建一个Qt应用程序,然后一路默认即可.这时,你会发现总共有: ...
- 点击除指定区域外的空白处,隐藏div
<script> $(document).click(function (e) { var $target = $(e.target); //点击.zanpl和.quanzipl以外的地方 ...
- 新手入门必看:VectorDraw 常见问题整理大全(二)
VectorDraw Developer Framework(VDF)是一个用于应用程序可视化的图形引擎库.有了VDF提供的功能,您可以轻松地创建.编辑.管理.输出.输入和打印2D和3D图形文件.该库 ...
- maven 学习---Maven项目模板
Maven提供用户,使用原型的概念,不同类型的项目模板(以数字614)是一个非常大的列表. Maven帮助用户快速开始使用以下命令创建新的Java项目 mvn archetype:generate 什 ...
- dlopen动态链接库操作
void *dlopen(const char *filename, int flag); //打开一个动态链接库,并返回动态链接库的句柄 char *dlerror(void); void *dls ...
- 【分布式搜索引擎】Elasticsearch之如何安装Elasticsearch
在Macos上安装 一.下载安装过程 最新版本下载地址: https://www.elastic.co/cn/downloads/elasticsearch 历史版本下载地址: https://www ...
- odoo10学习笔记十:Actions
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/11189319.html actions定义了系统对于用户的操作的响应:登录.按钮.选择项目等. 一:窗口ac ...