InnoDB的B+树索引使用
何时使用索引
并不是在所有的查询条件下出现的列都需要添加索引。对于什么时候添加B+树索引,我的经验是访问表中很少一部分行时,使用B+树索引才有意义。对于性别字段、地区字段、类型字段,它们可取值的范围很小,即低选择性。如:
SELECT * FROM student WHERE sex='M'
对于性别,可取值的范围只有'M'、'F'。对上述SQL语句得到的结果可能是该表50%的数据(我们假设男女比例1:1),这时添加B+树索引是完全没有必要的。相反,如果某个字段的取值范围很广,几乎没有重复,即高选择性,则此时使用B+树索引是最适合的,例如姓名字段,基本上在一个应用中都不允许重名的出现。
因此,当访问高选择性字段并从表中取出很少一部分行时,对这个字段添加B+树索引是非常有必要的。但是如果出现了访问字段是高选择性的,但是取出的行数据占表中大部分的数据时,这时MySQL数据库就不会使用B+树索引了,我们先来看一个例子:
show index from member;
表member大约有500万行数据。usernick字段上有一个唯一的索引。这时如果我们查找'David'这个用户时,得到执行计划如下:
explain select * from member where usernick='David';
可以看到使用了usernick这个索引,这也符合我们前面提到的高选择性、选取表中很少行的原则。但是如果执行下面这条语句:
explain select * from member where usernick>'David';
可以看到possible_keys依然是usernick,但是实际优化器使用的索引key显示的是NULL。为什么?因为这不符合我们前面说的原则,虽然usernick这个字段的值是高选择性的,但是我们取出的行占了表中很大的一部分。
select @a:=count(id) from member where usernick>'David'; 4544637
select @b:=count(id) from member; 4827542
select @a/@b; 0.9414
可以看到我们将取出表中94%的行,因此优化器没有使用索引。也许有人看到这里会问,谁会执行这句话啊?查找姓名大于David的字段,这种情况几乎不存在。的确如此,但是我们来考虑member表上的registdate字段(代表用户的注册时间),该字段是日期类型,字段上有一个regdate的非唯一索引。
我们来看下面两条语句的执行计划:
explain select * from member where registdate<'2006-04-23';
explain select * from member where registdate<'2006-04-24';
查找用户注册时间小于某个时间的SQL语句。出人意料的是,只是相差了1天,2条SQL语句的执行计划竟然不同。在执行第二条SQL语句的时候,虽然同样可以使用idx_regdate索引,但是优化器却没有使用该索引,而是对其全表进行扫描。MySQL数据库的优化器会通过EXPLAIN的rows字段预估查询可能得到的行,如果大于某一个值,则B+树会选择全表的扫表。至于这个值,根据我的经验(并没有在源代码中得到验证)一般在20%。即当取出的数据量超过表中数据的20%,优化器就不会使用索引,而是进行全表的扫表。
但是,预估的返回行数的值是不准确的,可以看到优化器判断注册日期小于2006-04-23的行为788 696,但实际得到的却是:
select count(id) from member where registdate<'2006-04-23'; 523046
实际却只有523 046行,少了33%。这可能对于优化器的选择产生一定的后果,如果我们对比强制使用索引和使用优化器选择的全表扫描来查询注册日期小于2006-04-24的数据,最终会发现:
select id,userid,sex,registdate into outfile 'a' from member force index(idx_regdate) where registdate<'2006-04-24';
select id,userid,sex,registdate into outfile 'b' from member where registdate<'2006-04-24';
第一句SQL语句我们强制使用idx_regdate索引,所用的时间为4.15秒,根据优化器选择的全表扫方式,执行第二句SQL语句却需要18.7秒。因此优化器的选择并不完全是正确的,有时你更应该相信自己的判断。
顺序读、随机读与预读取
任何时候Why都比What重要,索引使用的原则,即高选择、取出表中少部分的数据。但是为什么只能是少部分数据?
在知道为什么之前,了解两个概念——顺序读和随机读:
- 顺序读(Sequntial Read)是指顺序地读取磁盘上的块(Block)。
- 随机读(Random Read)是指访问的块不是连续的,需要磁盘的磁头不断移动。
当前传统机械磁盘的瓶颈之一就是随机读取的速度较低。
不管是否开启RAID卡的Write Back功能,磁盘的随机读性能都远远小于顺序读的性能。
在数据库中,顺序读是指根据索引的叶节点数据就能顺序地读取所需的行数据。这个顺序只是逻辑地顺序读,在物理磁盘上可能还是随机读取。但是相对来说,物理磁盘上的数据还是比较顺序的,因为是根据区来管理的,区是64个连续页。如根据主键进行读取,或许通过辅助索引的叶节点就能读取到数据。
随机读,一般是指访问辅助索引叶节点不能完全得到结果的,需要根据辅助索引叶节点中的主键去找实际行数据。因为一般来说,辅助索引和主键所在的数据段不同,因此访问是随机的方式。
SQL语句select id,userid,sex,registdate into outfile 'a' from member force index(idx_regdate) where registdate<'2006-04-24';
就是一句典型的随机读取。而正是因为读取的方式是随机的,并且随机读的性能会远低于顺序读,因此优化器才会选择全表的扫描方式,而不是去走idx_regdate这个辅助索引。
为了提高读取的性能,InnoDB存储引擎引入了预读取技术(read ahead或者prefetch)。预读取是指通过一次IO请求将多个页预读取到缓冲池中,并且估计预读取的多个页马上会被访问。传统的IO请求每次只读取1个页,在传统机械硬盘较低的IOPS下,预读技术可以大大提高读取的性能。
InnoDB存储引擎有两个预读方法,称为随机预读取(random read ahead)和线性预读取(linear read ahead)。
随机预读是指当一个区(64个连续页)中13个页也在缓冲区中,并在LRU列表的前端(即页是频繁地被访问),则InnoDB存储引擎会将这个区中剩余的所有页预读到缓冲区。
线性预读基于缓冲池中页的访问模式,而不是数量。如果一个区中的24个页都被顺序地访问了,则InnoDB存储引擎会读取下一个区的所有页。
对比数据库TPC-C测试性能,发现TPC-C的结果禁用预读取的性能比启用预读取的性能提高了10%。InnoDB存储引擎官方也发现了这个问题,从InnoDB Plugin 1.0.4开始,随机访问的预读取被取消了,而线性的预读取还是保留了,并且加入了innodb_read_ahead_threshold参数。该参数表示一个区中的多少页被顺序访问时,InnoDB存储引擎才启用预读取,即预读下一个区的所有页。参数innodb_read_ahead_threshold的默认值为56,即当一个区中56个页都已被访问过并且访问模式是顺序的,则预读取下一个区的所有页。
show variables like 'innodb_read_ahead_threshold';

另一个问题是固态硬盘,固态硬盘的接口规范、定义、功能和使用等方面与传统机械硬盘相同,但是它们的内部构造完全不同,固态硬盘没有读写磁头,读取数据不需要围绕中心轴旋转,因此,它的随机读性能得到了质的飞跃。在使用固态硬盘的情况下,优化器的20%选择原理可能就不怎么准确了,我们应该更充分地利用固态硬盘的特性。当然,这不只是InnoDB存储引擎遇到的问题,对于其他数据库,目前都存在没有充分利用固态硬盘特性的情况。相信随着固态硬盘的普及,各数据库厂商会加快这一方面的优化。
辅助索引的优化使用
辅助索引的叶节点包含有主键,但是辅助索引的叶并不包含完整的行信息。因此,InnoDB存储引擎总是会先从辅助索引的叶节点判断是否能得到所需的数据。
让我们来看一个例子:
create table t(a int not null,b varchar(20),primary key(a),key(b));
insert into t select 1,'kangaroo';
insert into t select 2,'dolphin';
insert into t select 3,'dragon';
insert into t select 4,'antelope';
如果执行select * from t,估计很多人以为会得到如下的结果:
select * from t order by a;
***************************1.row***************************
a:1
b:kangaroo
***************************2.row***************************
a:2
b:dolphin
***************************3.row***************************
a:3
b:dragon
***************************4.row***************************
a:4
b:antelope
4 rows in set(0.01 sec)
但是实际执行的结果却是:select * from t;
***************************1.row***************************
a:4
b:antelope
***************************2.row***************************
a:2
b:dolphin
***************************3.row***************************
a:3
b:dragon
***************************4.row***************************
a:1
b:kangaroo
4 rows in set(0.00 sec)
因为辅助索引中包含了主键a的值,因此访问b列上的辅助索引就能得到a值,那这样就可以得到表中所有的数据。并且通常情况下,一个辅助索引页中能存放的数据比主键页上存放的数据多,因此优化器选择了辅助索引,如果我们解释这句SQL语句,可得到如下结果:
explain select * from t;
可以看到,优化器最终选择的索引是b,如果想得到对列a排序的结果,你还需对其进行ORDER BY操作,这样优化器会直接走主键,避免对a列的排序操作。
如:explain select * from t order by a;
select*from t order by a\G;
或者强制使用主键来得到结果:
select * from t force index(PRIMARY);
联合索引
联合索引是指对表上的多个列做索引。
联合索引的创建方法与之前介绍的一样,如:alter table t add key idx_a_b(a,b);
什么时候需要使用联合索引呢?在讨论这个之前,我们要来看一下联合索引内部的结果。从本质上来说,联合索引还是一颗B+树,不同的是联合索引的键值的数量不是1,而是大于等于2。讨论两个整型列组成的联合索引,假定两个键值的名称分别为a、b,可以看到多个键值的B+树情况,其实和我们之前讨论的单个键值没有什么不同,键值都是排序的,通过叶节点可以逻辑上顺序地读出所有数据,就上面的例子来说即:(1,1),(1,2),(2,1),(2,4),(3,1),(3,2)。数据按(a,b)的顺序进行了存放。
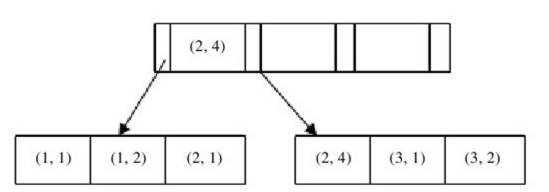
因此,对于查询SELECT * FROM TABLE WHERE a=xxx and b=xxx,显然是可以使用(a,b)的这个联合索引。对于单个的a列查询SELECT * FROM TABLE WHERE a=xxx也是可以使用这个(a,b)索引。但是对于b列的查询SELECT * FROM TABLE WHERE b=xxx,不可以使用这颗B+树索引。可以看到叶节点上的b值为1、2、1、4、1、2,显然不是排序的,因此对于b列的查询使用不到(a,b)的索引。
联合索引的第二个好处是,可以对第二个键值进行排序。例如,在很多情况下我们都需要查询某个用户的购物情况,并按照时间排序,取出最近三次的购买记录,这时使用联合索引可以避免多一次的排序操作,因为索引本身在叶节点已经排序了。
create table buy_log(userid int unsigned not null,buy_date date);
insert into buy_log values(1,'2009-01-01');
insert into buy_log values(2,'2009-01-01');
insert into buy_log values(3,'2009-01-01');
insert into buy_log values(1,'2009-02-01');
insert into buy_log values(3,'2009-02-01');
insert into buy_log values(1,'2009-03-01');
insert into buy_log values(1,'2009-04-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid,buy_date);
我们建立了两个索引来进行比较。两个索引都包含了userid字段。如果只对于userid进行查询,优化器的选择是:
explain select * from buy_log where userid=2;
可以看到possible_keys这里有两个索引可以使用,分别是单个的userid索引和userid、buy_date的联合索引。但是优化器最终的选择是userid,因为该叶节点包含单个键值,因此一个页能存放的记录应该更多。
接着看以下的查询,我们假定要取出userid=1的最近3次购买记录,并分析使用单个索引和联合索引的区别:
explain select * from buy_log where userid=1 order by buy_date desc limit 3;
同样,对于上述的SQL语句都可以使用userid和userid,buy_date的索引。但是这次优化器使用了userid、buy_date的联合索引userid_2,因为在这个联合索引中buy_date已经排序好了。
如果我们强制使用userid的单个索引,会得到如下结果:
explain select * from buy_log force index(userid) where userid=1 order by buy_date desc limit 3;
在Extra这里,我们可以看到Using filesort,filesort是指排序,但是并不是在文件中完成。我们可以对比执行:
show status like 'sort_rows';
+-----------------+-------+
|Variable_name|Value
|Sort_rows|7
+-----------------+-------+
select * from buy_log force index(userid) where userid=1 order by buy_date desc limit 3;
show status like 'sort_rows';
+-----------------+-------+
|Variable_name|Value
|Sort_rows|10
+-----------------+-------+
可以看到增加了排序的操作,但是如果使用userid、buy_date的联合索引userid_2,就不会有这一次的额外操作了,如:
show status like 'sort_rows';
+-----------------+-------+
|Variable_name|Value
|Sort_rows|10
+-----------------+-------+
select * from buy_log where userid=1 order by buy_date desc limit 3;
show status like 'sort_rows';
+-----------------+-------+
|Variable_name|Value
|Sort_rows|10
+-----------------+-------+
InnoDB的B+树索引使用的更多相关文章
- MySQL InnoDB引擎B+树索引简单整理说明
本文出处:http://www.cnblogs.com/wy123/p/7211742.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- InnoDB的B+树索引
B+树索引其本质就是B+树在数据库中的实现,但是B+索引在数据库中有一个特点就是其高扇出性,因此在数据库中,B+树的高度一般都在2-3层,也就是对于查找某一键值的行记录,最多只需要2到3次IO,这倒不 ...
- 一分钟掌握MySQL的InnoDB引擎B+树索引
MySQL的InnoDB索引结构采用B+树,B+树什么概念呢,二叉树大家都知道,我们都清楚随着叶子结点的不断增加,二叉树的高度不断增加,查找某一个节点耗时就会增加,性能就会不断降低,B+树就是解决这个 ...
- InnoDB 中 B+ 树索引的分裂
数据库中B+树索引的分裂并不总是从页的中间记录开始,这样可能会导致空间的浪费,例如下面的记录: 1, 2, 3, 4, 5, 6, 7, 8, 9 插入式根据自增顺序进行的,若这时插入10这条记录后需 ...
- MySQL:InnoDB存储引擎的B+树索引算法
很早之前,就从学校的图书馆借了MySQL技术内幕,InnoDB存储引擎这本书,但一直草草阅读,做的笔记也有些凌乱,趁着现在大四了,课程稍微少了一点,整理一下笔记,按照专题写一些,加深一下印象,不枉读了 ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- InnoDB存储引擎的 B+ 树索引
B+ 树是为磁盘设计的 m 叉平衡查找树,在B+树中,所有的记录都是按照键值的大小,顺序存放在同一层的叶子节点上,各叶子节点组成双链表.叶节点是数据,非叶节点是索引. 首先,需要清楚:B+ 树索引并不 ...
- InnoDB存储引擎的B+树索引算法
关于B+树数据结构 ①InnoDB存储引擎支持两种常见的索引. 一种是B+树,一种是哈希. B+树中的B代表的意思不是二叉(binary),而是平衡(balance),因为B+树最早是从平衡二叉树演化 ...
- 谈谈InnoDB中的B+树索引
索引类似于书的目录,他是帮助我们从大量数据中快速定位某一条或者某个范围数据的一种数据结构.有序数组,搜索树都可以被用作索引.MySQL中有三大索引,分别是B+树索引.Hash索引.全文索引.B+树索引 ...
随机推荐
- How to Baskup and Restore a MySQL database
If you're storing anything in MySQL databases that you do not want to lose, it is very important to ...
- Spring AOP详解(转载)所需要的包
上一篇文章中,<Spring Aop详解(转载)>里的代码都可以运行,只是包比较多,中间缺少了几个相应的包,根据报错,几经百度搜索,终于补全了所有包. 截图如下: 在主测试类里面,有人怀疑 ...
- Postgresql 分区表 一
Postgres 10 新特性 分区表 http://francs3.blog.163.com/blog/static/40576727201742103158135/ Postgres 10 之前分 ...
- centos7怎能开机设置文本界面
rm -f /etc/systemd/system/default.target 设置命令行级别方法:ln -sf /lib/systemd/system/runlevel3.target /etc/ ...
- iOS开发常见无法分类的小问题
iOS去除api过期警告提示
- java中集合
一. List集合: 一次只存储一个元素 1.常用的list集合是ArrayList (1)在创建这个集合的对象时, 需要指定这个集合存储的数据类型! 否则这个集合的数据是不安全的. (2)与数组的 ...
- linux环境搭建前期配置
一.永久修改主机名 1.修改network文件 # vim /etc/sysconfig/network 加入 HOSTNAME=主机名 保存退出 2.修改hosts文件 # vim /etc/hos ...
- linux系统无法启动,提示give root password for maintenance错误
电脑的虚拟机安装的是centos6.2操作系统,今天打开虚拟机时候,提示 give root password for maintenance (or type control-D to contin ...
- CTF常见加密方式汇总
1.栅栏密码 在IDF训练营里做过一道关于栅栏密码的问题. 栅栏密码的解法很简单,也有点复杂,字符长度因数多得会有很多个密码.对,栅栏密码的解法就是:计算该字符串是否为合数,若为合数,则求出该合数除本 ...
- form-inline+form-group 实现表单横排显示(Bootstrap)
运行后的效果如下: 使用时要注意如下: 如果form元素有form-line修饰,那么form-group 所修饰的元素内部只能包含一个元素,否则,不会达到预期效果