Python 高性能并行计算之 mpi4py
MPI 和 MPI4PY 的搭建上一篇文章已经介绍,这里面介绍一些基本用法。
mpi4py 的 helloworld
from mpi4py import MPI
print("hello world")
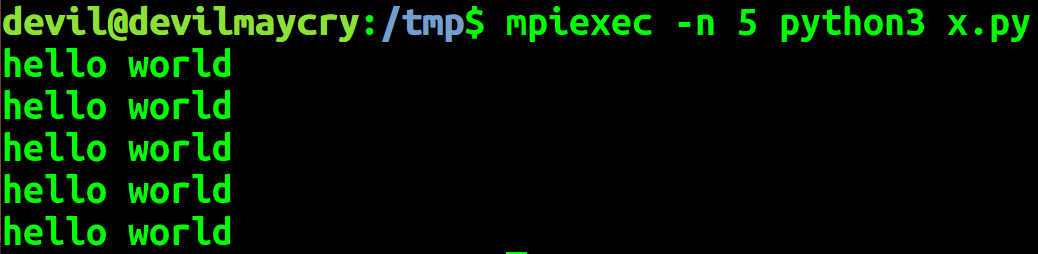
mpiexec -n 5 python3 x.py
2. 点对点通信
因为 mpi4py 中点对点的 通信 send 语句 在数据量较小的时候是把发送数据拷贝到缓存区,是非堵塞的操作, 然而在数据量较大时候是堵塞操作,由此如下:
在 发送较小数据时:
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() # point to point communication
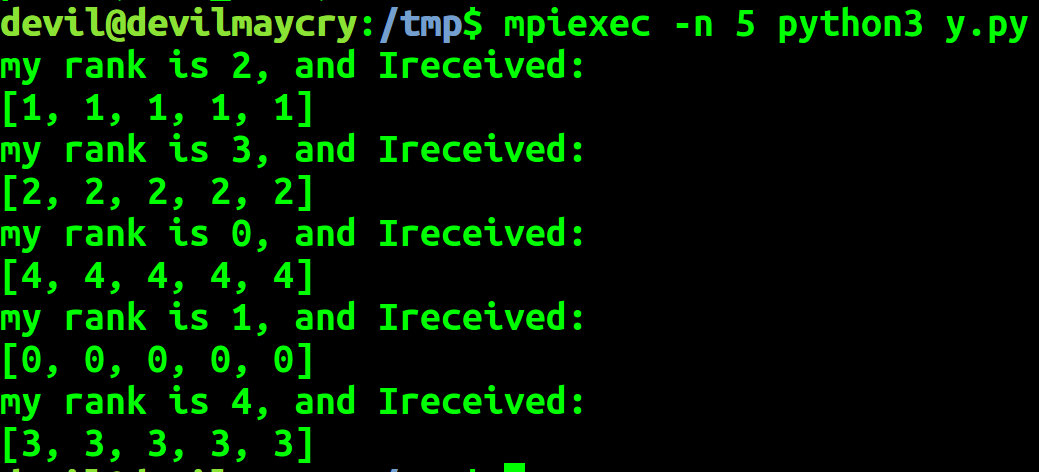
data_send = [comm_rank]*5 comm.send(data_send,dest=(comm_rank+1)%comm_size) data_recv =comm.recv(source=(comm_rank-1)%comm_size) print("my rank is %d, and Ireceived:" % comm_rank)
print(data_recv)
在数据量较大时, 比如发送 :
# point to point communication
data_send = [comm_rank]*1000000
这时候就会造成各个进程之间的死锁。(因为这时候各个进程是堵塞执行,每个进程都在等待另一个进程的发送数据)
修改后的代码,所有进程顺序执行, 0进程发送给1,1接收然后发送给2,以此类推:
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() data_send = [comm_rank]*1000000 if comm_rank == 0:
comm.send(data_send, dest=(comm_rank+1)%comm_size) if comm_rank > 0:
data_recv = comm.recv(source=(comm_rank-1)%comm_size)
comm.send(data_send, dest=(comm_rank+1)%comm_size) if comm_rank == 0:
data_recv = comm.recv(source=(comm_rank-1)%comm_size) print("my rank is %d, and Ireceived:" % comm_rank)
print(data_recv)
3 群体通信
3.1 广播bcast
一个进程把数据发送给所有进程
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() if comm_rank == 0:
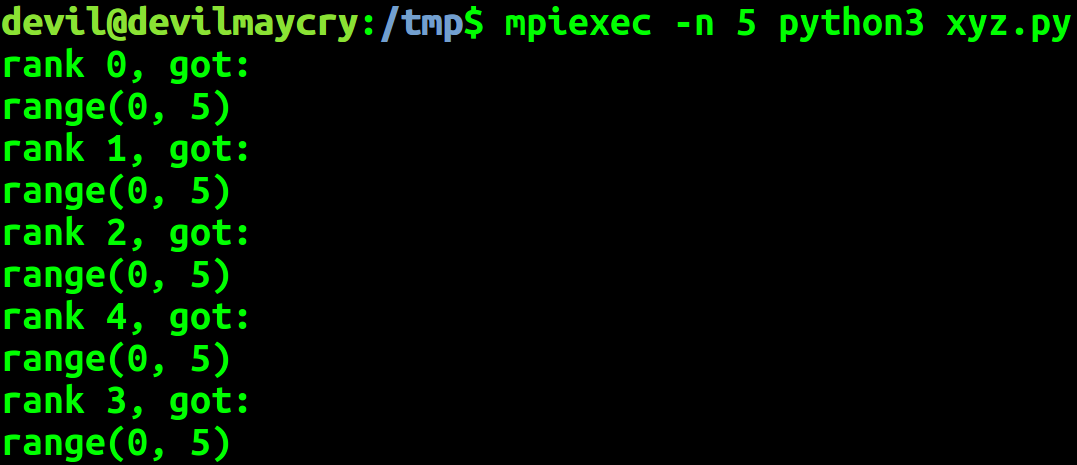
data = range(comm_size) dat = comm.bcast(data if comm_rank == 0 else None, root=0) print('rank %d, got:' % (comm_rank))
print(dat)
发送方 也会收到 这部分数据,当然发送方这份数据并不是网络传输接受的,而是本身内存空间中就是存在的。
3.2 散播scatter
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() if comm_rank == 0:
data = range(comm_size)
else:
data = None local_data = comm.scatter(data, root=0) print('rank %d, got:' % comm_rank)
print(local_data)

3.3 收集gather
将所有数据搜集回来
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() if comm_rank == 0:
data = range(comm_size)
else:
data = None local_data = comm.scatter(data, root=0)
local_data = local_data * 2 print('rank %d, got and do:' % comm_rank)
print(local_data) combine_data = comm.gather(local_data,root=0) if comm_rank == 0:
print("root recv {0}".format(combine_data))

3.4 规约reduce
import mpi4py.MPI as MPI comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() if comm_rank == 0:
data = range(comm_size)
else:
data = None local_data = comm.scatter(data, root=0)
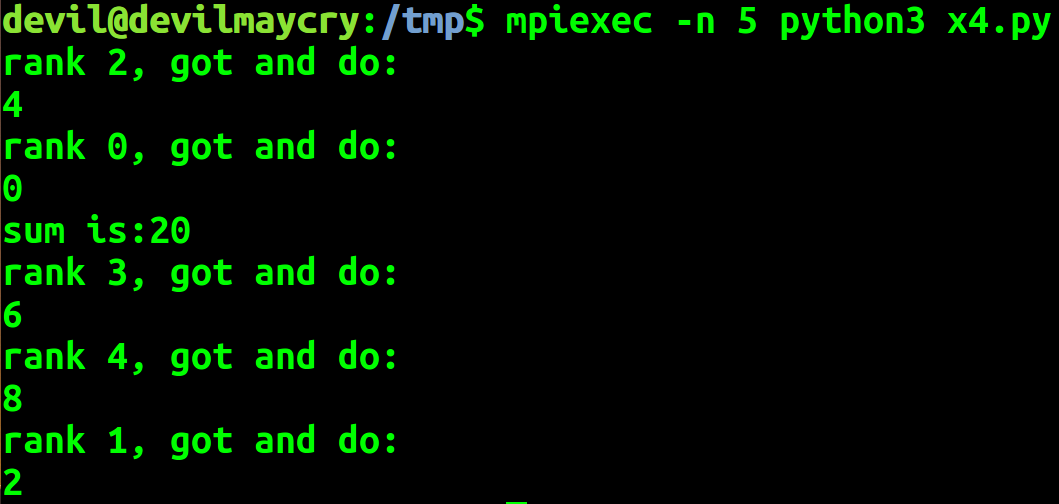
local_data = local_data * 2 print('rank %d, got and do:' % comm_rank)
print(local_data) all_sum = comm.reduce(local_data, root=0,op=MPI.SUM) if comm_rank == 0:
print('sum is:%d' % all_sum)
SUM MAX MIN 等操作在数据搜集是在各个进程中进行一次操作后汇总到 root 进程中再进行一次总的操作。
op=MPI.SUM
op=MPI.MAX
op=MPI.MIN
3.5 对一个文件的多个行并行处理
#!usr/bin/env python
#-*- coding: utf-8 -*-
import sys
import os
import mpi4py.MPI as MPI
import numpy as np # Global variables for MPI
# instance for invoking MPI relatedfunctions
comm = MPI.COMM_WORLD
# the node rank in the whole community
comm_rank = comm.Get_rank()
# the size of the whole community, i.e.,the total number of working nodes in the MPI cluster
comm_size = comm.Get_size() if __name__ == '__main__':
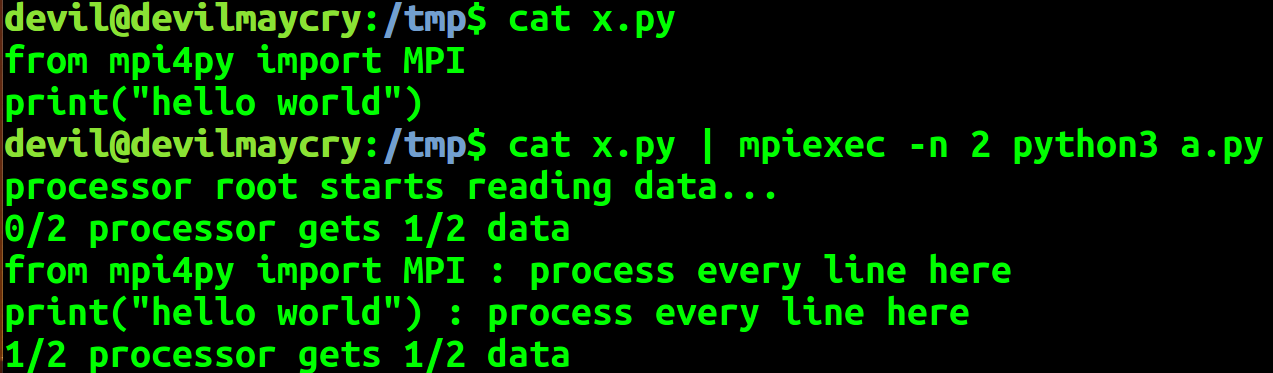
if comm_rank == 0:
sys.stderr.write("processor root starts reading data...\n")
all_lines = sys.stdin.readlines() all_lines = comm.bcast(all_lines if comm_rank == 0 else None, root = 0) num_lines = len(all_lines)
local_lines_offset = np.linspace(0, num_lines, comm_size +1).astype('int') local_lines = all_lines[local_lines_offset[comm_rank] :local_lines_offset[comm_rank + 1]] sys.stderr.write("%d/%d processor gets %d/%d data \n" %(comm_rank, comm_size, len(local_lines), num_lines)) for line in local_lines:
output = line.strip() + ' : process every line here'
print(output)
3.6 对多个文件并行处理
#!usr/bin/env python
#-*- coding: utf-8 -*-
import sys
import os
import mpi4py.MPI as MPI
import numpy as np # Global variables for MPI
# instance for invoking MPI relatedfunctions
comm = MPI.COMM_WORLD
# the node rank in the whole community
comm_rank = comm.Get_rank()
# the size of the whole community, i.e.,the total number of working nodes in the MPI cluster
comm_size = comm.Get_size() if __name__ == '__main__':
if len(sys.argv) != 2:
sys.stderr.write("Usage: python *.py directoty_with_files\n")
sys.exit(1) path = sys.argv[1] if comm_rank == 0:
file_list = os.listdir(path)
sys.stderr.write("......%d files......\n" % len(file_list)) file_list = comm.bcast(file_list if comm_rank == 0 else None, root = 0)
num_files = len(file_list)
local_files_offset = np.linspace(0, num_files, comm_size +1).astype('int')
local_files = file_list[local_files_offset[comm_rank] :local_files_offset[comm_rank + 1]] sys.stderr.write("%d/%d processor gets %d/%d data \n" %(comm_rank, comm_size, len(local_files), num_files)) sys.stderr.write("processor %d has %s files \n"%(comm_rank, local_files))

3.7 联合numpy对矩阵的多个行或者多列并行处理
import os, sys, time
import numpy as np
import mpi4py.MPI as MPI # instance for invoking MPI relatedfunctions
comm = MPI.COMM_WORLD
# the node rank in the whole community
comm_rank = comm.Get_rank()
# the size of the whole community, i.e.,the total number of working nodes in the MPI cluster
comm_size = comm.Get_size() # test MPI
if __name__ == "__main__":
#create a matrix
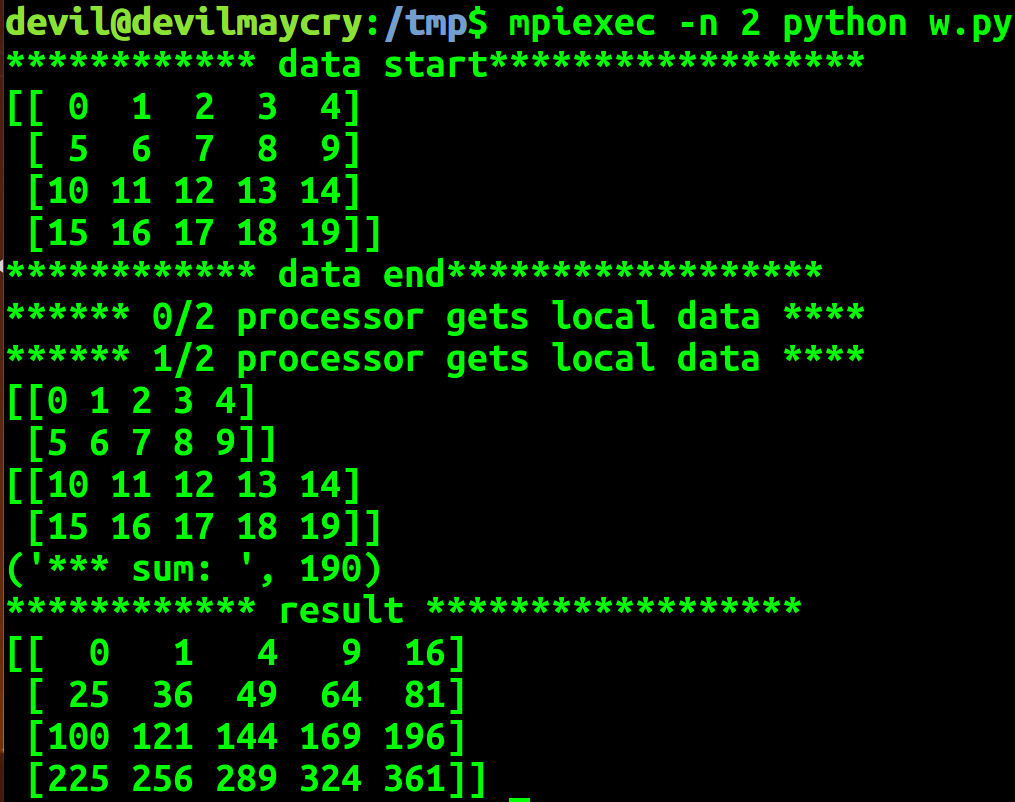
if comm_rank == 0:
all_data = np.arange(20).reshape(4, 5)
print("************ data start******************")
print(all_data)
print("************ data end******************") #broadcast the data to all processors
all_data = comm.bcast(all_data if comm_rank == 0 else None, root = 0) #divide the data to each processor
num_samples = all_data.shape[0]
local_data_offset = np.linspace(0, num_samples, comm_size + 1).astype('int') #get the local data which will be processed in this processor
local_data = all_data[local_data_offset[comm_rank] :local_data_offset[comm_rank + 1]]
print("****** %d/%d processor gets local data ****" %(comm_rank, comm_size))
print(local_data) #reduce to get sum of elements
local_sum = local_data.sum()
all_sum = comm.reduce(local_sum, root = 0, op = MPI.SUM) #process in local
local_result = local_data ** 2 #gather the result from all processors and broadcast it
result = comm.allgather(local_result)
result = np.vstack(result) if comm_rank == 0:
print("*** sum: ", all_sum)
print("************ result ******************")
print(result)
参考文章:
《Python多核编程mpi4py实践》
https://blog.csdn.net/zouxy09/article/details/49031845
Python 高性能并行计算之 mpi4py的更多相关文章
- Python猫荐书系列之五:Python高性能编程
稍微关心编程语言的使用趋势的人都知道,最近几年,国内最火的两种语言非 Python 与 Go 莫属,于是,隔三差五就会有人问:这两种语言谁更厉害/好找工作/高工资…… 对于编程语言的争论,就是猿界的生 ...
- 《Python高性能编程》——列表、元组、集合、字典特性及创建过程
这里的内容仅仅是本人阅读<Python高性能编程>后总结的一些知识,用于自己更好的了解Python机制.本人现在并不从事计算密集型工作:人工智能.数据分析等.仅仅只是出于好奇而去阅读这本书 ...
- 进阶《Python高性能编程》中文PDF+英文PDF+源代码
入门使用高性能 Python,建议参考<Python高性能编程>,例子给的很多,讲到高性能就会提到性能监控,里面有cpu mem 方法的度量,网络讲了一点异步,net profiler 没 ...
- python高性能编程方法一
python高性能编程方法一 阅读 Zen of Python,在Python解析器中输入 import this. 一个犀利的Python新手可能会注意到"解析"一词, 认为 ...
- python并行计算之mpi4py的安装与基本使用
技术背景 在之前的博客中我们介绍过concurrent等python多进程任务的方案,而之所以我们又在考虑MPI等方案来实现python并行计算的原因,其实是将python的计算任务与并行计算的任务调 ...
- Python高性能编程
一.进程池和线程池 1.串行 import time import requests url_lists = [ 'http://www.baidu.com', 'http://fanyi.baidu ...
- python高性能web框架——Japronto
近期做了一个简单的demo需求,搭建一个http server,支持简单的qa查询.库中有10000个qa对,需要支持每秒10000次以上的查询请求. 需求比较简单,主要难点就是10000+的RPS. ...
- python高性能编程方法一-乾颐堂
阅读 Zen of Python,在Python解析器中输入 import this. 一个犀利的Python新手可能会注意到"解析"一词, 认为Python不过是另一门脚本语言. ...
- 两款高性能并行计算引擎Storm和Spark比較
对Spark.Storm以及Spark Streaming引擎的简明扼要.深入浅出的比較,原文发表于踏得网. Spark基于这种理念.当数据庞大时,把计算过程传递给数据要比把数据传递给计算过程要更富效 ...
随机推荐
- make clean 与 make distclean 的区别
make clean仅仅是清除之前编译的可执行文件及配置文件. 而make distclean要清除所有生成的文件. Makefile 在符合GNU Makefiel惯例的Makefile中,包含了一 ...
- Js中的filter()方法
/* filter()方法使用指定的函数测试所有元素,并创建一个包含所有通过测试的元素的新数组. filter()基本语法: arr.filter(callback[, thisArg]) filte ...
- centos远程访问mssql数据库
http://blog.path8.net/archives/5921.html http://www.jaggerwang.net/2013/03/18/centos%E4%B8%8B%E5%AE% ...
- Web开发相关笔记 #03#
HTTP Status 500 ※ jsp 放在 WEB-INF 外面 ※ 使用 JDBC 时需要 close 什么 ※ execute 和 executeUpdate ※ How can I ...
- bzoj1607 / P2926 [USACO08DEC]拍头Patting Heads
P2926 [USACO08DEC]拍头Patting Heads 把求约数转化为求倍数. 累计每个数出现的个数,然后枚举倍数累加答案. #include<iostream> #inclu ...
- OpenCV中的新函数connectedComponentsWithStats使用
主要内容:对比新旧函数,用于过滤原始图像中轮廓分析后较小的区域,留下较大区域. 关键字 :connectedComponentsWithStats 在以前,常用的方法是"是先调用 cv ...
- VMware Vcenter Server 6.0忘记密码
windows 版Vcenter6.0 重置密码首先要登录到安装Vcenter的windows服务器上 用管理员身份打开CMD命令行 进入VMware VCenter的目录 默认是C:\Program ...
- 内核加载模块时出现Unknown symbol等提示
一.背景 1.更改了内核的配置,重新编译了内核 2.未重新编译内核模块 3.板子上只更新了内核,并未更新文件系统 二.分析 发现是在加载内核模块时出现Unknown symbol等信息,恰逢当时只更新 ...
- Minimum Depth of Binary Tree,求树的最小深度
算法分析:递归和非递归两种方法. public class MinimumDepthofBinaryTree { //递归,树的最小深度,就是它左右子树的最小深度的最小值+1 public int m ...
- [osgearth]Earth文件详解
<!—type 属性可以是geocentric和projected两种模式,分别对应地心坐标系和平面投影坐标系,默认是地心坐标模式.Version是osgEarth的主版本号,必须有版本号--& ...