keras实现不同形态的模型
keras提供了Sequential线性的模型,但是有些网络需要多个输入,有些网络有多个输出,更甚之层与层之间有内部分支,这使得网络看起来像是层构成的图,而不是线性的堆叠。有些场景需要多模态的输入,这些的输入来源于不同的数据,例如下面的例子
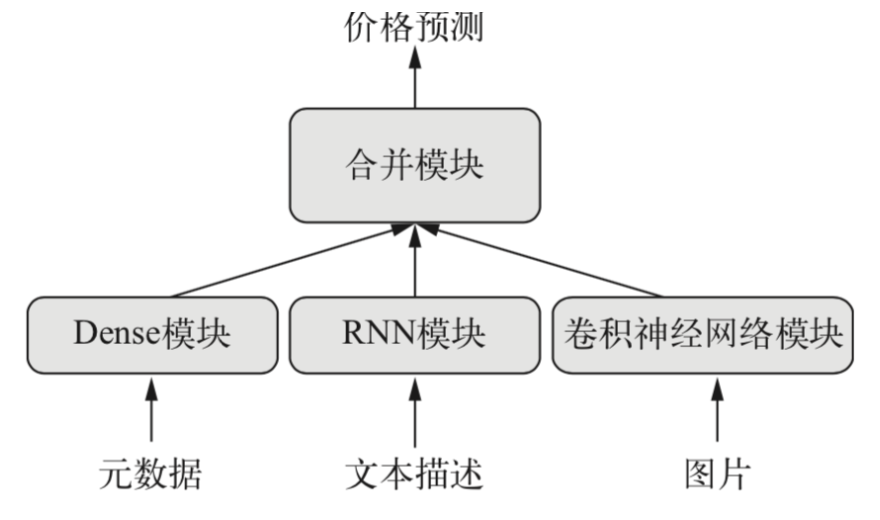
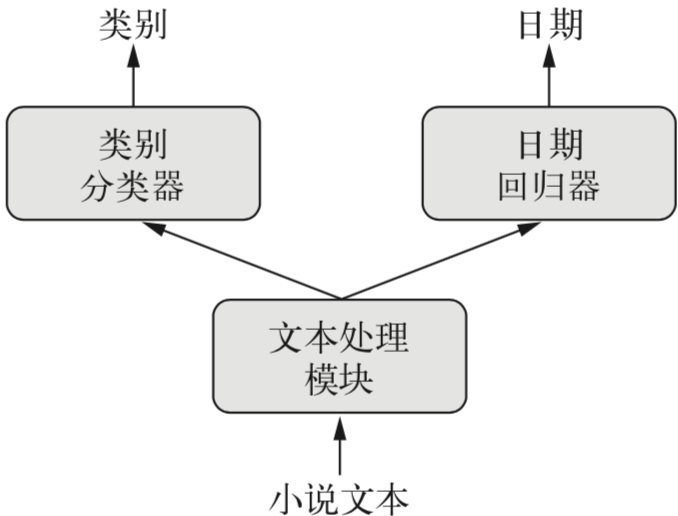
而有些场景是多个输出,例如给定一部小说,希望将其自动分类(比如爱情、惊悚),同时还希望预测其写作的日期。当然可以训练两个独立的模型,但由于这些属性并非是统计无关的,你可以构造一个更好的模型,进行联合训练输出想要的结果。
那么如何该用keras实现这类模型呢?
函数式API可是用于构建具有多个输入输出的模型,通常情况下,这种模型会在某一时刻用一个可以组合多个张量层将不同的输入分支合并、相加和连接等。
多输入模型
假设一个问答模型有两个输入:一个自然语言描述的问题和一个文本片段,后者提供用于回答问题的信息。然后模型要生成一个回答,在最简单的情况下,这个回答只包含一个词,可以通过对某个预定义的词表做softmax得到。
import numpy as np
from keras import layers
from keras.models import Model
from keras import Input
from keras.utils import plot_model
import keras
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
# 文本输入是一个长度可变的整数序列,注意name为可选
text_input = Input(shape=(None,), dtype='int32', name='text')
# 将输入映射为一个64的向量
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input)
#利用lstm将向量编码为单个向量
encoded_text = layers.LSTM(32)(embedded_text)
question_input = Input(shape=(None,),dtype='int32',name='question')
embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
concatenated = layers.concatenate([encoded_text, encoded_question],axis=-1)
# 拼接
answer = layers.Dense(answer_vocabulary_size,activation='softmax')(concatenated)
#在模型实例化时,指定两个输入和输出
model = Model([text_input, question_input], answer)
model.compile(optimizer='rmsprop',loss='categorical_crossentropy', metrics=['acc'])
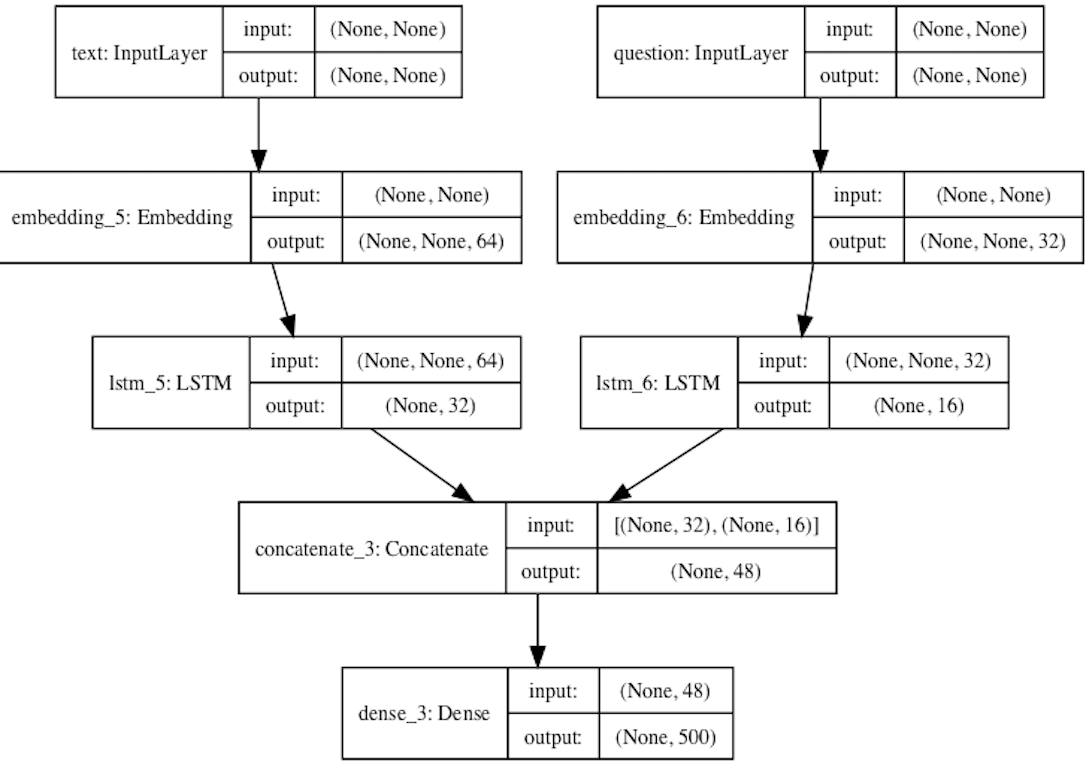
看一下模型的架构
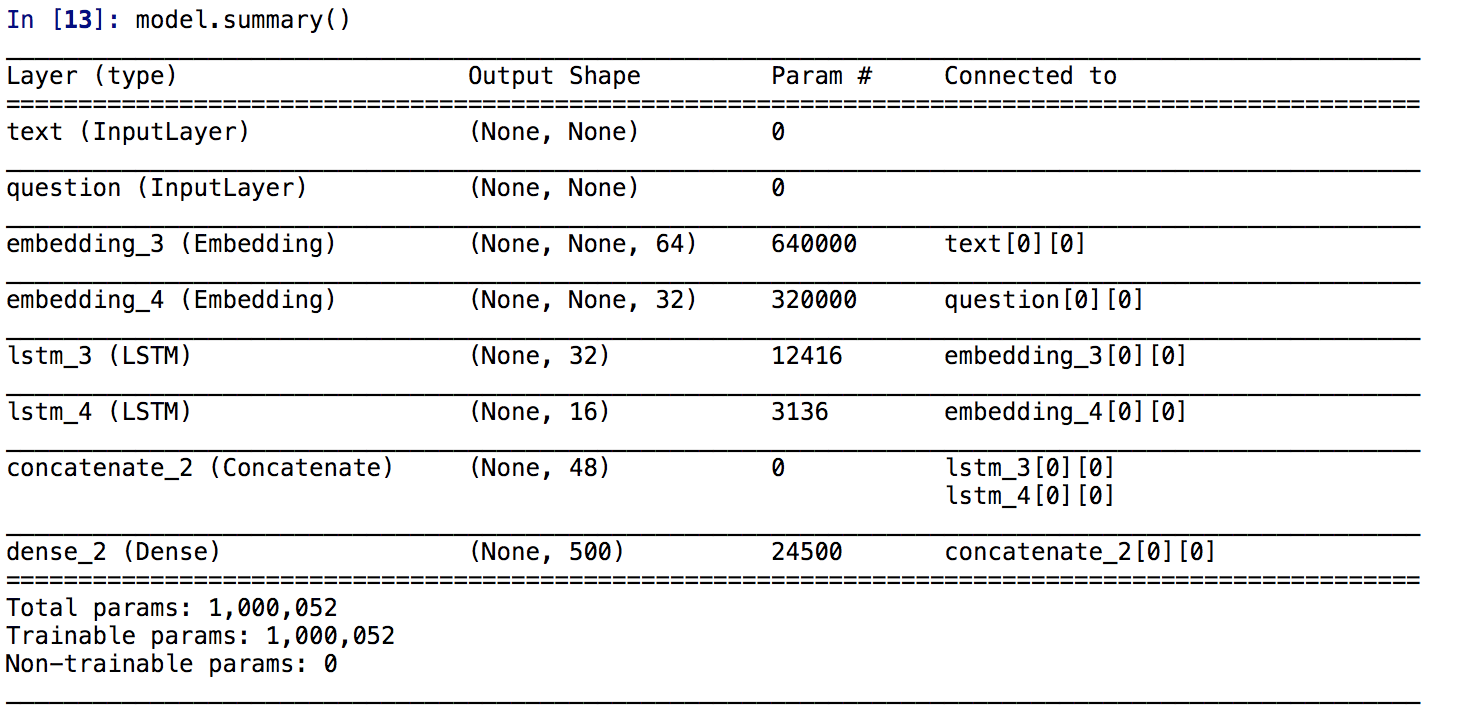
可以通过plot_model(model,show_shapes=True,to_file='model.png')内置方法将模型的结构输出出来
接下来怎么训练这个双输入模型呢?有两个可用的API:1、向模型中输入一个由numpy组成的列表 2、输入一个将输入名称映射为numpy数组的字典
num_samples = 1000
max_length = 100
text = np.random.randint(1, text_vocabulary_size, size=(num_samples, max_length))
question = np.random.randint(1, question_vocabulary_size, size=(num_samples, max_length))
answers = np.random.randint(answer_vocabulary_size, size=(num_samples))
answers = keras.utils.to_categorical(answers, answer_vocabulary_size)
#model.fit([text, question], answers, epochs=10, batch_size=128)
model.fit({'text': text, 'question': question}, answers,epochs=10, batch_size=128)
多输出模型
一个简单的例子:输入某人的一些列社交发帖,预测这个人的年龄、性别和收入水平

代码如下:
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape=(None,), dtype='int32', name='posts')
embedded_posts = layers.Embedding(256, vocabulary_size)(posts_input)
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation='relu')(x)
age_prediction = layers.Dense(1, name='age')(x)
income_prediction = layers.Dense(num_income_groups,activation='softmax',name='income')(x)
gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x)
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
model.summary()
plot_model(model,show_shapes=True,to_file='model.png')
#model.compile(optimizer='rmsprop',\
# loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'])
model.compile(optimizer='rmsprop',\
loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'],\
loss_weights=[0.25, 1., 10.])
对于这些多数出(多头)的模型该怎么训练呢?预测年龄是一个回归问题,性别是一个分类问题。为了能够进行训练我们必须将这些损失合并为单个标量。在合并不同的损失函数的时候,最简单的方法就是对所有的函数加权求和。在 Keras 中,你可以在编译时使用损失组成的列表或 字典来为不同输出指定不同损失,然后将得到的损失值相加得到一个全局损失,并在训练过程 中将这个损失最小化。注意,在严重不平衡的损失会导致模型单独针对单个损失最大的任务进行优化,而忽略了其他的任务。为了解决这一问题可以对每个损失指定一个权重。
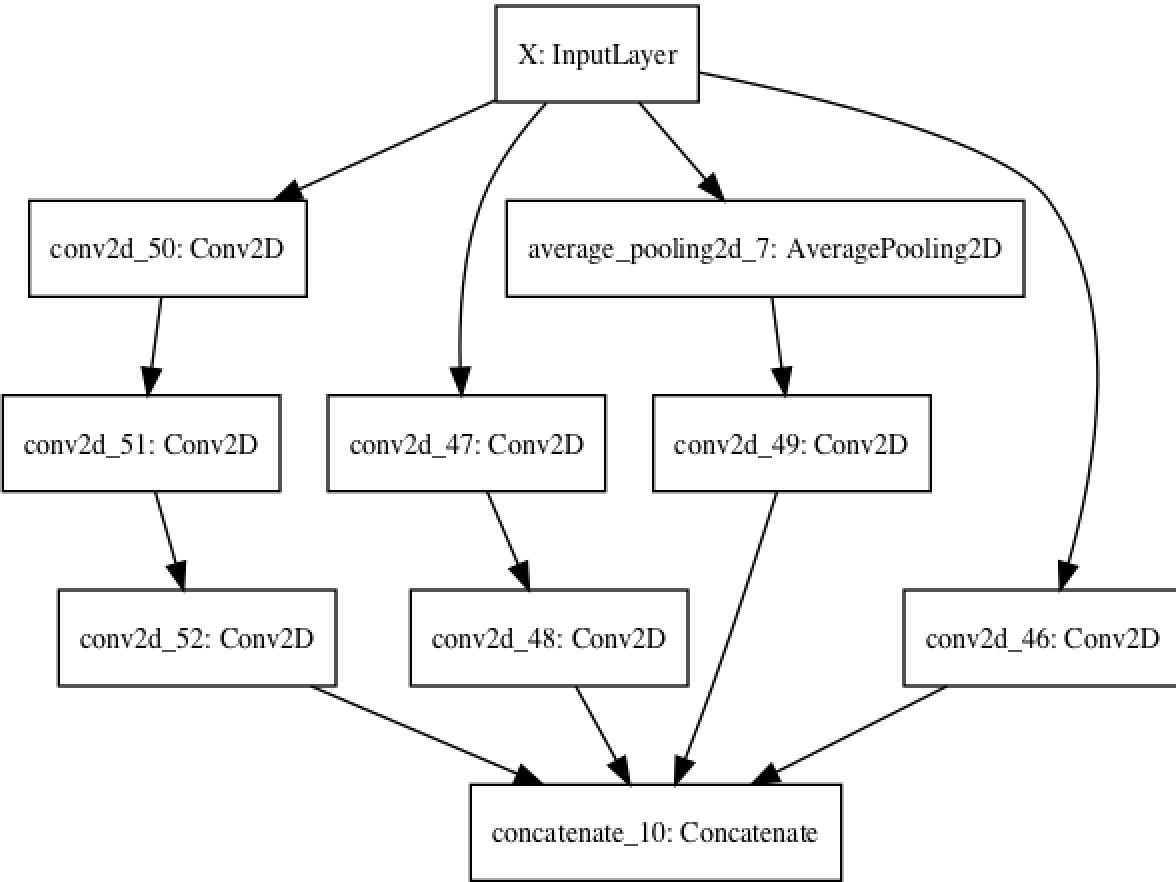
有向无环图
利用函数是API不仅能够方便的构建多输入或多输出模型,而且可以实现内部更为复杂的拓扑结构。Keras中的神经网络可以是层组成的任意有向五环图(directed acyclic graph,DAG)
代码如下:
input_x = Input(shape=(250,250,1), dtype='float32', name='X')
branch_a = layers.Conv2D(128, 1,activation='relu', strides=2,padding='same')(input_x)
branch_b = layers.Conv2D(128, 1, activation='relu',padding='same')(input_x)
branch_b = layers.Conv2D(128, 3, activation='relu',strides=2,padding='same')(branch_b)
branch_c = layers.AveragePooling2D(3, strides=2,padding='same')(input_x)
branch_c = layers.Conv2D(128, 3, activation='relu',padding='same')(branch_c)
branch_d = layers.Conv2D(128, 1, activation='relu',padding='same')(input_x)
branch_d = layers.Conv2D(128, 3, activation='relu',padding='same')(branch_d)
branch_d = layers.Conv2D(128, 3, activation='relu', strides=2,padding='same')(branch_d)
output = layers.concatenate([branch_a, branch_b, branch_c, branch_d], axis=-1)
model = Model(input_x, output)
plot_model(model,show_shapes=True,to_file='model.png')
模型的效果图如下
权重共享
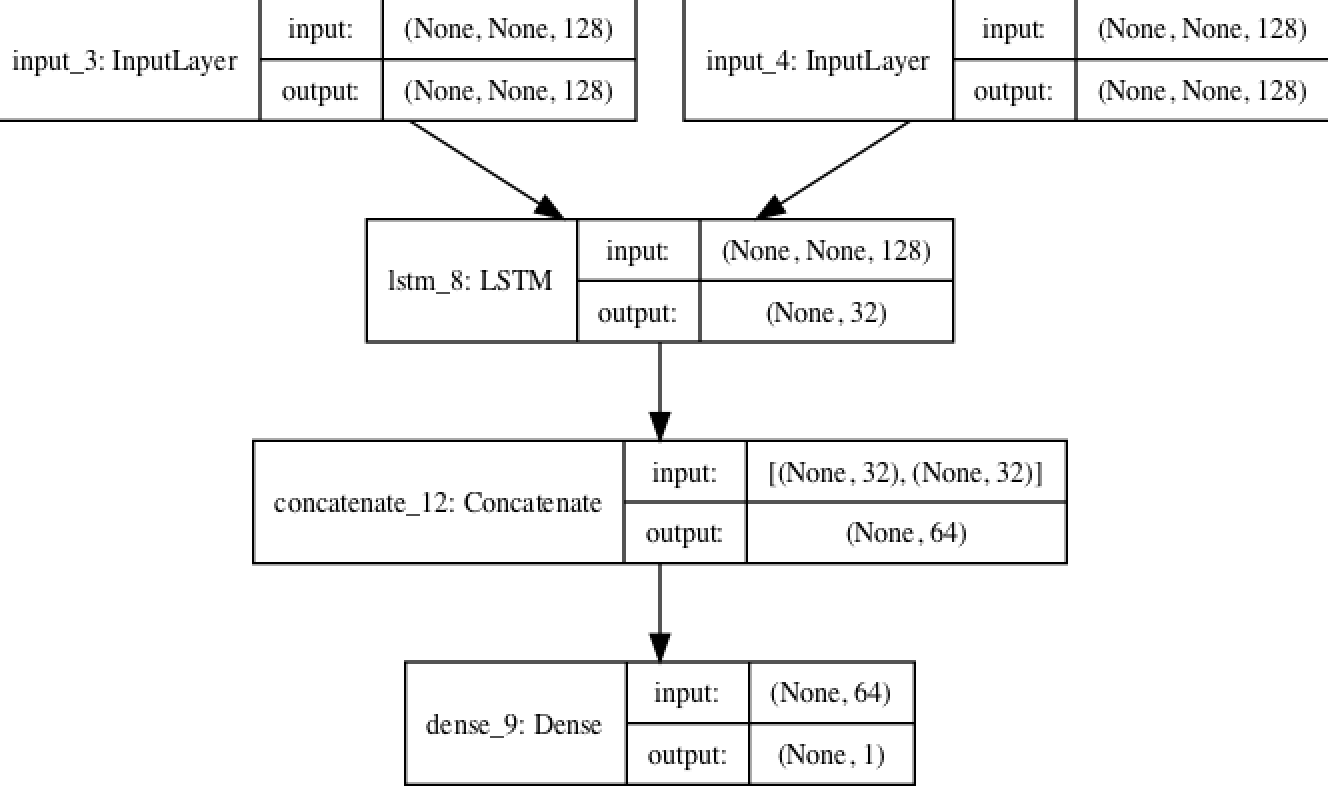
函数是API有一个重要的特性,那就是能够多次使用一层实例。如果对一个实例的层调用两次,而不是每次都实例化一个新层,那么每次调用都重复使用这个权重,这样就可以构建共享分支的模型了。据一个例子求A、B句子的相似度。A对于B等于B对于A的相似度。
lstm = layers.LSTM(32)
left_input = Input(shape=(None, 128))
left_output = lstm(left_input)
right_input = Input(shape=(None, 128))
right_output = lstm(right_input)
merged = layers.concatenate([left_output, right_output], axis=-1)
predictions = layers.Dense(1, activation='sigmoid')(merged)
model = Model([left_input, right_input], predictions)
plot_model(model,show_shapes=True,to_file='model.png')
模型如下:
keras实现不同形态的模型的更多相关文章
- keras系列︱Sequential与Model模型、keras基本结构功能(一)
引自:http://blog.csdn.net/sinat_26917383/article/details/72857454 中文文档:http://keras-cn.readthedocs.io/ ...
- 使用 keras 和 tfjs 构建血细胞分类模型
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识!
- 【Keras篇】---Keras初始,两种模型构造方法,利用keras实现手写数字体识别
一.前述 Keras 适合快速体验 ,keras的设计是把大量内部运算都隐藏了,用户始终可以用theano或tensorflow的语句来写扩展功能并和keras结合使用. 二.安装 Pip insta ...
- Keras入门(二)模型的保存、读取及加载
本文将会介绍如何利用Keras来实现模型的保存.读取以及加载. 本文使用的模型为解决IRIS数据集的多分类问题而设计的深度神经网络(DNN)模型,模型的结构示意图如下: 具体的模型参数可以参考文章 ...
- keras框架 反复调用model 模型 出错
Cannot interpret feed_dict key as Tensor: Tensor Tensor("Placeholder_8:0", shape=(3, 3, 12 ...
- 1.keras实现-->自己训练卷积模型实现猫狗二分类(CNN)
原数据集:包含 25000张猫狗图像,两个类别各有12500 新数据集:猫.狗 (照片大小不一样) 训练集:各1000个样本 验证集:各500个样本 测试集:各500个样本 1= 狗,0= 猫 # 将 ...
- 人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型 经过前面稍显罗嗦的准备工作,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了.CNN擅长图像处理,keras库的te ...
- Keras之序贯(Sequential)模型
序贯模型(Sequential) 序贯模型是多个网络层的线性堆叠. 可以通过向Sequential模型传递一个layer的list来构造该模型: from Keras.models import Se ...
- keras 保存训练的最佳模型
转自:https://anifacc.github.io/deeplearning/machinelearning/python/2017/08/30/dlwp-ch14-keep-best-mode ...
随机推荐
- crc16算法,包括单片机和c#版本
c语言的#include <stdio.h> static short const wCRC16Table[256] = { 0x0000, 0xC0C1, 0xC181 ...
- WPF 在事件中绑定命令
导航:MVVMLight系列文章目录:<关于 MVVMLight 设计模式系列> 其实这也不属于MVVMLight系列中的东东了,没兴趣的朋友可以跳过这篇文章,本文主要介绍如何在WPF中实 ...
- swift - UISlider 的用法
swift的UISlider的用法和oc基本没有区别 1.创建 class SecondViewController: UIViewController { var slider = UISlider ...
- Python Scrapy 自动爬虫注意细节(1)
一.首次爬取模拟浏览器 在爬虫文件中,添加start_request函数.如: def start_requests(self): ua = {"User-Agent": 'Moz ...
- 浏览器Chrome对WebGL支持判断
1.开启方式: 第一种:打开cmd,切换到Chorme的安装目录,敲入chrome.exe --enable -webgl,回车就会打开一个chrome浏览器窗口: 第二种:找到Chrome浏览器的快 ...
- List自定义排序
List自定义排序我习惯根据Collections.sort重载方法来实现,下面我只实现自己习惯方式.还有一种就是实现Comparable接口. 挺简单的,直接上代码吧. package com.so ...
- Yarn中几个专用名称
1. ResourceManager(RM) RM是一个全局的资源管理器,负责整个系统的资源管理和分配.它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Appli ...
- ActiveMQ伪集群部署
本文借鉴http://www.cnblogs.com/guozhen/p/5984915.html,在此基础上进行了完善,使之成为一个完整版的伪分布式部署说明,在此记录一下! 一.本文目的 介绍如何在 ...
- /etc/rc.d/rc.local
/etc/rc.d/rc.local 用于用户自定义开机启动程序,可以往里写开机要执行的命令或脚本,线上的配置如下: [root@localhost ~]$ cat /etc/rc.d/rc.loca ...
- Date Json格式转换Date格式
CreateTime=\/Date(1458722493663+0800)\/ var CreateTime="/Date(1458722493663+0800)/";var st ...