join多表连接和group by分组
join多表连接和group by分组
上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组。
一、多表连接
多表连接的时间是数据库一个非常耗时的操作,因为连接的时间复杂度是M*N(M,N是要连接的表的记录数),如果不对进行优化,连接的产生的临时表可能非常大,需要写入磁盘,分多趟进行处理。
1、双表等值join
我们看这样一个连接sql:
- select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
- from SUPPLIER,PARTSUPP
- where PS_SUPPKEY = S_SUPPKEY and PS_AVAILQTY > 2000and S_NATIONKEY = 1;
可以把这个sql理解为在SUPPLIER表的S_SUPPKEY属性和PARTSUPP表的PS_SUPPKEY属性上作等值连接,并塞选出满足PS_AVAILQTY > 2000和 S_NATIONKEY = 1的记录,输入满足条件记录的PS_AVAILQTY,PS_SUPPLYCOST,S_NAME属性。这样的理解对我们人来说是很明了的,但数据库不能照这样的方式执行,上面的PS_SUPPKEY其实是PARTSUPP的外键,两个表进行等值连接,得到的连接结果是很大的。所以我们应该先从单表查询条件入手,在单表查询过滤之后再进行等值连接,这样需要连接的记录数会少很多。
首先根据PS_AVAILQTY > 2000找出满足条件的PARTSUPP表的记录行号集A,然后根据S_NATIONKEY = 1找出SUPPLIER表找出相应的记录行号集B,在记录集A、B上进行等值连接,看图很简单:

依次扫描的时间复杂度为max(m,n),加上折半查找,总的时间复杂度为max(m,n)*(log(m1)+log(n1)),其中m1、n1表示where条件塞选出的记录数。
来看一下执行的结果:

- Input SQL:
- select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
- from SUPPLIER,PARTSUPP
- where PS_SUPPKEY = S_SUPPKEY
- and PS_AVAILQTY > 2000
- and S_NATIONKEY = 1;
- {'FROM': ['SUPPLIER', 'PARTSUPP'],
- 'GROUP': None,
- 'ORDER': None,
- 'SELECT': [['PARTSUPP.PS_AVAILQTY', None, None],
- ['PARTSUPP.PS_SUPPLYCOST', None, None],
- ['SUPPLIER.S_NAME', None, None]],
- 'WHERE': [['PARTSUPP.PS_AVAILQTY', '>', '2000'],
- ['SUPPLIER.S_NATIONKEY', '=', '1'],
- ['PARTSUPP.PS_SUPPKEY', '=', 'SUPPLIER.S_SUPPKEY']]}
- Quering: PARTSUPP.PS_AVAILQTY > 2000
- Quering: SUPPLIER.S_NATIONKEY = 1
- Quering: PARTSUPP.PS_SUPPKEY = SUPPLIER.S_SUPPKEY
- Output:
- The result hava 26322 rows, here is the fisrt 10 rows:
- -------------------------------------------------
- rows PARTSUPP.PS_AVAILQTY PARTSUPP.PS_SUPPLYCOST SUPPLIER.S_NAME
- -------------------------------------------------
- 1 8895 378.49 Supplier#000000003
- 2 4286 502.00 Supplier#000000003
- 3 6996 739.71 Supplier#000000003
- 4 4436 377.80 Supplier#000000003
- 5 6728 529.58 Supplier#000000003
- 6 8646 722.34 Supplier#000000003
- 7 9975 841.19 Supplier#000000003
- 8 5401 139.06 Supplier#000000003
- 9 6858 786.94 Supplier#000000003
- 10 8268 444.21 Supplier#000000003
- -------------------------------------------------
- Take 26.58 seconds.
从Quering后面的信息可以看到我们处理where子条件的顺序,先处理单表查询,再处理多表连接。
2、多表join
处理完双表join后,我们看一下怎么实现三个的join,示例sql:
- select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
- from SUPPLIER,PART,PARTSUPP
- where PS_PARTKEY = P_PARTKEY
- and PS_SUPPKEY = S_SUPPKEY
- and PS_AVAILQTY > 2000
- and P_BRAND = 'Brand#12'
- and S_NATIONKEY = 1;
这里进行三个表的连接,三个表连接得到的应该是三个表的记录合并的结果,那根据where条件选出的记录行号应当包含三列,每一列是一个表的行号:
三个表的连接事实上建立在两个表连接的基础上的,先进行两个表的连接后,得到两组行号表,再将这两组行号表合并:
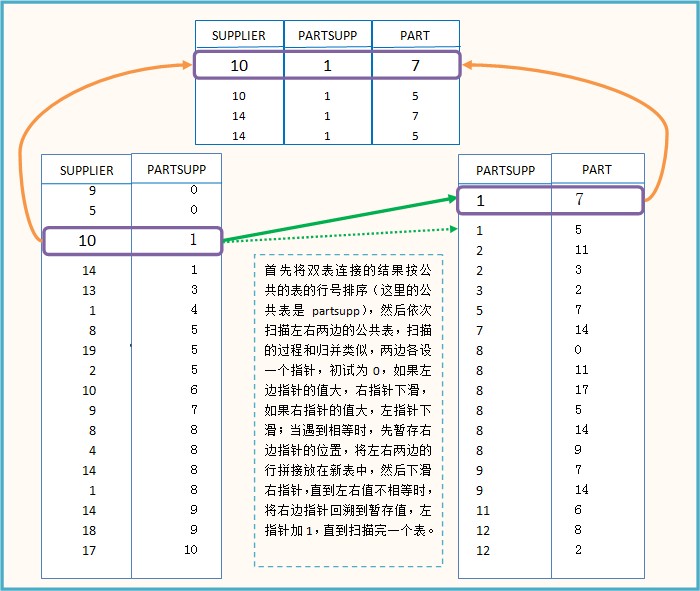
主要代码如下:
- 1 sortJoin(joina,cloumi)#cloumi表示公共表在joina的列号
- 2 sortJoin(joinb,cloumj)#cloumj表示公共表在joinb的列号
- 3 i = j = 0#左右指针初试为0
- 4 while i < len(joina) and j < len(joinb):
- 5 if joina[i][cloumi] < joinb[j][cloumj]:
- 6 i += 1
- 7 elif joina[i][cloumi] > joinb[j][cloumj]:
- 8 j += 1
- 9 else:#相等,进行连接
- 10 lastj = j
- 11 while j < len(joinb) and joina[i][cloumi] == joinb[j][cloumj]:
- 12 temp = joina[i] + joinb[j]
- 13 temp.remove(joina[i][cloumi])#删掉重复的元素
- 14 mergeResult.append(temp)
- 15 j += 1
- 16 j = lastj#右指针回滚
- 17 i += 1
我们分析一下这个算法的时间复杂度,首先要对两个表排序,复杂度为O(m1log(m1)),在扫描的过程中,右边指针会回溯,所以不再是O(max(m1,n1)),我们可以认为是k*O(m1*n1),这个系数k应该是很小的,因为一般右指针不会回溯太远,总的时间复杂度是O(m1log(m1))+k*O(m1*n1),应该是小于N方的复杂度。
看一下执行的结果:
- Input SQL:
- select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME
- from SUPPLIER,PART,PARTSUPP
- where PS_PARTKEY = P_PARTKEY
- and PS_SUPPKEY = S_SUPPKEY
- and PS_AVAILQTY > 2000
- and P_BRAND = 'Brand#12'
- and S_NATIONKEY = 1;
- {'FROM': ['SUPPLIER', 'PART', 'PARTSUPP'],
- 'GROUP': None,
- 'ORDER': None,
- 'SELECT': [['PARTSUPP.PS_AVAILQTY', None, None],
- ['PARTSUPP.PS_SUPPLYCOST', None, None],
- ['SUPPLIER.S_NAME', None, None]],
- 'WHERE': [['PARTSUPP.PS_AVAILQTY', '>', '2000'],
- ['PART.P_BRAND', '=', 'Brand#12'],
- ['SUPPLIER.S_NATIONKEY', '=', '1'],
- ['PARTSUPP.PS_PARTKEY', '=', 'PART.P_PARTKEY'],
- ['PARTSUPP.PS_SUPPKEY', '=', 'SUPPLIER.S_SUPPKEY']]}
- Quering: PARTSUPP.PS_AVAILQTY > 2000
- Quering: PART.P_BRAND = Brand#12
- Quering: SUPPLIER.S_NATIONKEY = 1
- Quering: PARTSUPP.PS_PARTKEY = PART.P_PARTKEY
- Quering: PARTSUPP.PS_SUPPKEY = SUPPLIER.S_SUPPKEY
- Output:
- The result hava 1022 rows, here is the fisrt 10 rows:
- -------------------------------------------------
- rows PARTSUPP.PS_AVAILQTY PARTSUPP.PS_SUPPLYCOST SUPPLIER.S_NAME
- -------------------------------------------------
- 1 4925 854.19 Supplier#000002515
- 2 4588 455.04 Supplier#000005202
- 3 8830 852.13 Supplier#000007814
- 4 8948 689.89 Supplier#000002821
- 5 3870 488.38 Supplier#000005059
- 6 6968 579.03 Supplier#000005660
- 7 9269 228.31 Supplier#000000950
- 8 8818 180.32 Supplier#000003453
- 9 9343 785.01 Supplier#000003495
- 10 3364 545.25 Supplier#000006030
- -------------------------------------------------
- Take 50.42 seconds.
这个查询的时间比Mysql快了很多,在mysql上运行这个查询需要10分钟(建立了索引),想想也是合理的,我们的设计已经大大简化了,完全不考虑表的修改,牺牲这么的实用性必然能提升在查询上的效率。
二、group by分组
在执行完where条件后,读取原始记录,然后可以按group by的属性分组,分组的属性可能有多条,比如这样一个查询:
- select PS_AVAILQTY,PS_SUPPLYCOST,S_NAME,COUNT(*)
- from SUPPLIER,PART,PARTSUPP
- where PS_PARTKEY = P_PARTKEY
- and PS_SUPPKEY = S_SUPPKEY
- and PS_AVAILQTY > 2000
- and P_BRAND = 'Brand#12'
- and S_NATIONKEY = 1;
- group by PS_AVAILQTY,PS_SUPPLYCOST,S_NAME;
按 PS_AVAILQTY,PS_SUPPLYCOST,S_NAME这三个属性分组,我们实现时使用了一个技巧,将每个候选记录的这三个字段按字符串格式拼接成一个新的属性,拼接的示例如下:
- "4925" "854.19" "Supplier#000002515" -->> "4925+854.19+Supplier#000002515"
注意中间加了一个加号“+”,这个加号是必须的,如果没有加号,"105","201"与"10","5201"的拼接结果都是"105201",这样得到的group by结果将会出错,而添加一个加号它们两的拼接结果是不同的。
拼接后,我们只需要按新的属性进行分组,可以使用map来实现,map的key为新的属性值,value为新属性值key的后续记录。再在组上进行聚集函数的运算。
这个小项目就写到这里了,或许这压根只是一个数据处理,谈不上数据库实现,不过通过这个小项目我对数据库底层的实现还是了解了很多,以后做数据库优化理解起来也容易一些。
谢谢关注,欢迎评论。
join多表连接和group by分组的更多相关文章
- python实现简易数据库之三——join多表连接和group by分组
上一篇里面我们实现了单表查询和top N查询,这一篇我们来讲述如何实现多表连接和group by分组. 一.多表连接 多表连接的时间是数据库一个非常耗时的操作,因为连接的时间复杂度是M*N(M,N是要 ...
- MySQL JOIN 多表连接
除了常用的两个表连接之外,SQL(MySQL) JOIN 语法还支持多表连接.多表连接基本语法如下: 1 ... FROM table1 INNER|LEFT|RIGHT JOIN table2 ON ...
- sql之表连接和group by +组函数的分析
1.首先我们来先看一个简单的例子: 有[Sales.Orders]订单表和[Sales.Customers]顾客表,表的机构如下 业务要求:筛选 来自“按时打算”国家的用户以及所下的订单数 sele ...
- MySql left join 多表连接查询优化语句
先过滤条件然后再根据表连接 同时在表中建立相关查询字段的索引这样在大数据多表联合查询的情况下速度相当快 创建索引: create index ix_register_year ON dbo.selec ...
- c# DataTable join 两表连接
转:https://www.cnblogs.com/xuxiaona/p/4000344.html JlrInfodt和dtsource是两个datatable,通过[姓名]和[lqry]进行关联 v ...
- 表连接sql执行计划学习
循环嵌套连接(Nested Loop Join) 合并连接(Merge Join) 哈西匹配(Hash Join) 文章:浅谈SQL Server中的三种物理连接操作 循环嵌套,如果内循环列上有索引, ...
- Oracle之分组函数嵌套以及表连接
--1 数据环境准备 scott 用户下面的emp,dept表 --2 要求 :求平均工资最高的部门编号,部门名称,部门平均工资 select d.deptno,d.dname,e.salfrom(s ...
- 逆袭之旅DAY14.东软实训.Oracle.多表连接、分组函数、子查询
2018-07-10 08:29:55 思考应用场景 异常数据的测试 6.显示能挣得奖金的雇员的姓名.工资.奖金,并以工资和奖金降序排列.select ename,sal,commfrom empWH ...
- 010.简单查询、分组统计查询、多表连接查询(sql实例)
-------------------------------------day3------------ --添加多行数据:------INSERT [INTO] 表名 [(列的列表)] --SEL ...
随机推荐
- json.net 比jsonIgnore 更好的方法 修改源码
关于 JsonIgnore 问题, EF T4 模板 中 存在主外键关系 namespace WindowsFormsApplication1{ using System; using ...
- .net 职责链来实现 插件模式
.net 职责链来实现 插件模式 插件式的例子 QQ电脑管家,有很多工具列表,点一下工具下载后就可以开始使用了 eclipse ,X Server 等等 插件式的好处 插件降低框架的复杂性,把扩展功能 ...
- Asp.Net MVC5入门学习系列④
原文:Asp.Net MVC5入门学习系列④ 添加Model且简单的使用EF 对于EF(EntityFramework)不了解的朋友可以去百度文科或者在园子里搜一些简资源看下,假如和我一样知道EF的概 ...
- 判断小数点位数不超过2位的JS代码和在删除确认框里面插JS代码
<script type="text/javascript"> function checkDecimals(){ var decallowed = 2; var re ...
- asterisk实时添加sip号码--sqlite篇
原文:asterisk实时添加sip号码--sqlite篇 asterisk实时添加sip号码--sqlite篇 今天尝试用了asterisk的实时模式,往sqlite里面添加一个sip帐号,无需重启 ...
- JSP之项目路径问题(${pageContext.request.contextPath},<%=request.getContextPath()%>以及绝对路径获取)
本随笔这是作为一个记录使用,以备后查.项目完成之后本地部署OK,本地Linux部署OK,都可以正常的访问,可是当我把它部署到服务器上面的时候,首页可以正常访问,可是当发出请求的时候却报错误了,说找不到 ...
- leetcode第二题--Median of Two Sorted Arrays
Problem:There are two sorted arrays A and B of size m and n respectively. Find the median of the two ...
- 屏幕录制H.264视频,AAC音频,MP4复,LibRTMP现场活动
上周完成了一个屏幕录制节目,实时屏幕捕获.记录,视频H.264压缩,音频应用AAC压缩,复用MP4格公式,这使得计算机和ios设备上直接播放.支持HTML5的播放器都能够放,这是标准格式的优点.抓屏也 ...
- 如何在在网页上显示pdf文档
------解决方案--------------------通过flash插件 ------解决方案--------------------RAD PDF Release 2.7 http://www ...
- PHP中将内容循环出来
首先连接数据库: $myDate= @mysql_connect("localhost","root","") or die("数 ...