[AlwaysOn Availability Groups]监控AG性能
监控AG性能
AG的性能的性能方面,在关键任务数据库上进行语句级维护性能是很重要的。理解AG如何传输日志到secondary副本对评估RTO和RPO,表明AG是否性能不好。
1. 数据同步步骤
为了评估是否有性能问题,首先需要理解同步过程。性能问题可能出现在同步过程的任何一个环节,瓶颈的定位可以让你深入的理解问题。以下图标演示了数据通过过程:

|
Sequence |
Step Description |
Comments |
Useful Metrics |
|
1 |
Log Generation |
日志数据被刷新到磁盘。日志必须被复制到secondary副本。日志记录进入到发送队列. |
|
|
2 |
Capture |
每个数据库的日志被获取并且发送到相关的partner队列,每个数据库副本都有一个队列。在可用组在连接的情况下,并且数据移动并没有被挂起,获取进程持续运行,并且数据库副本显示要不是同步的,要不是正在同步,如果获取进程不能及时扫描并把消息放入队列,日志发送队列就会筑高。 |
SQL Server:Availability Replica > Bytes Sent to Replica\sec, which is an aggregation of the sum of all database messages queued for that availability replica. log_send_queue_size (KB) and log_bytes_send_rate(KB/sec) on the primary replica. |
|
3 |
Send |
数据库副本中的消息出队列,并且发送到相关的secondary副本. |
SQL Server:Availability Replica > Bytes sent to transport\sec and SQL Server:Availability Replica > Message Acknowledgement Time(ms) |
|
4 |
Receive and Cache |
每个secondary副本接受并且缓存这些信息. |
Performance counter SQL Server:Availabiltiy Replica > Log Bytes Received/sec |
|
5 |
Harden |
日志在secondary副本被刷新。在日志刷新后,一个通知被发送到primary副本。一旦日志被固化,就表示不会再有数据丢失。 |
Performance counter SQL Server:Database > Log Bytes Flushed/sec Wait typeHADR_LOGCAPTURE_SYNC |
|
6 |
Redo |
Redo刷新secondary副本中的page。Page被存放在redo队列等待被redo完成。 |
SQL Server:Database Replica > Redone Bytes/sec redo_queue_size (KB) andredo_rate. Wait type REDO_SYNC |
2.流量控制门(Flow Control Gates)
AG被设计时,在primary副本上带了流量控制,为了避免太多资源消耗,比如网络,内存资源在所有可用副本上的消耗。这些流量控制不会影响可用副本的健康状态,但是会影响可用数据库性能,包括RPO。
日志被primary副本捕获之后,有2个级别的流量控制。
|
Level |
Number of Gates |
Number of messages |
Useful Metrics |
|
Transport |
1 per availabiltiy replica |
8192 |
Extended event database_transport_flow_control_action |
|
Database |
1 per availability database |
11200 (x64) 1600 (x86) |
Extended event hadron_database_flow_control_action |
一旦到达任意一个阀值,log信息就不会被发送到指定副本或者指定数据库。一旦从副本收到通知,已发送的消息下降,就可以再发。
除了流量控制,还有一个因素会阻止日志发送。副本的同步要保证LSN是顺序的被发送的。在日志被发送之前,日志的LSN会通过最小通知LSN检查,保证小于阀值。如果2个LSN的空隙大于阀值,消息就不会被发送。一旦空隙小于阀值,消息就会被发送。
有2个性能指标,SQL Server:Availability Replica > Flow control/sec 和SQL Server:Availability Replica > Flow Control Time (ms/sec) 表示在上一秒,有多少流量控制被激活并且有多少时间是用来等待流量控制。等待值越高表示RPO越多。跟多信息查看:排查:AG超过RPO
3.评估故障转移时间
故障转移时间的公式如下: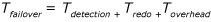
如果AG有多个可用库,最高的故障转移时间变长了限制RTO总要因素。
Tdetection错误诊断时间,是用来发现系统错误的时间。这个时间依赖于集群设置级别,而不是个别可用性副本的设置。根据设置的自动故障转移的条件,故障转移在SQL
Server出现严重的内部错误会出发,比如,孤立的自旋锁。这个时候诊断在sp_server_diagnostics发送到WSFC集群马上启动。故障转移也会因为超时发生,比如集群健康检查超时(HealthCheck Timeout 默认30秒)或者资源DLL和SQL Server实例的租用超时(Leasetimeout 默认20秒)。这个诊断时间为超时的间隙。具体看:Flexible
Failover Policy for Automatic Failover of an Availability Group (SQL Server).
Secondary副本唯一要做的事情就是,redo这些获取的日志。Redo时间是Tredo,公式如下:

Redo_queue是redo队列的长度,redo_rate是redo的速度。这2个值可以查看:sys.dm_hadr_database_replica_states
Toverhead
over head的时间就是WSFC集群故障转移,数据库online的时间。通常这个时间都很小。
4.评估RPO
RPO,RPO的公司如下:

Log_send_queue可以查看sys.dm_hdar_database_replica_states的log_send_queue_size和日志的生成速度,SQL
Server:Database > Log Bytes Flushed/sec.
如果AG包含了多个可用性数据库,最大的 Tdata_loss
会变成限制RPO的关键。
Log发送队列表示所有数据会因为严重错误丢失的。不能使用log_send_rate来代替log生成速度,因为RPO评估数据丢失是基于日志生成速度的,而不是基于同步速度的。
最简单的评估 Tdata_loss 是使用last_commit_time.priamry会把这个值发给所有的secondary,你可以计算primary副本和secondary 副本的值的差,来评估需要多久secondary副本可以追上primary副本。虽然不能准确的表示数据丢失,但是已经很接近了。
5.监控RPO和RTO
本章介绍如何对RPO和RTO进行监控,RPO和RTO的计算请查看上面2节的介绍。你可以监控这2个值,在超过阀值时发送告警。
通过以下步骤创建AG的告警:
1.启动ageng服务
2.点开ALwaysOn启动用户定义AlwaysOn策略
3.创建条件, Database Replica State/ Add(@EstimatedRecoveryTime,
60) <= 600
4.创建条件 Database Replica State/EstimatedDataLoss<=3600
5.创建RTO策略,创建RPO策略
6.性能排查场景
|
Scenario |
Description |
|
自动或者手动故障转移后,没有数据丢失,但是故障转移超过了RTO。或者评估发现故障转移时间超过了 |
|
|
强制故障转移后,都是的数据超过了RPO。或者异步提交的replica能够承受的数据丢失超过了RPO。 |
|
|
客户端程序可以成功的完成primary的修改,但是查询replia却没有反应。 |
7. 使用扩展事件
以下扩展时间可以用来排查副本在同步中的情况:
|
Event Name |
Category |
Channel |
Availability Replica |
|
redo_caught_up |
transactions |
Debug |
Secondary |
|
redo_worker_entry |
transactions |
Debug |
Secondary |
|
hadr_transport_dump_message |
alwayson |
Debug |
Primary |
|
hadr_worker_pool_task |
alwayson |
Debug |
Primary |
|
hadr_dump_primary_progress |
alwayson |
Debug |
Primary |
|
hadr_dump_log_progress |
alwayson |
Debug |
Primary |
|
hadr_undo_of_redo_log_scan |
alwayson |
Analytic |
Secondary |
[AlwaysOn Availability Groups]监控AG性能的更多相关文章
- [AlwaysOn Availability Groups]AG排查和监控指南
AG排查和监控指南 1. 排查场景 如下表包含了常用排查的场景.根据被分为几个场景类型,比如Configuration,client connectivity,failover和performance ...
- [AlwaysOn Availability Groups]排查:AG配置
排查AG配置 本文主要用来帮助排查在AG配置时出现的问题,包括,AG功能被禁用,账号配置不正确,数据库镜像endpoint不存在,endpoint不能访问. Section Description A ...
- [AlwaysOn Availability Groups]DMV和系统目录视图
DMV和系统目录视图 这里主要介绍AlwaysON的动态管理视图,可以用来监控和排查你的AG. 在AlwaysOn Dashboard,你可以简单的配置的GUI显示很多可用副本的DMV和可用数据库通过 ...
- [SQL in Azure] Tutorial: AlwaysOn Availability Groups in Azure (GUI)
http://msdn.microsoft.com/en-us/library/azure/dn249504.aspx Tutorial: AlwaysOn Availability Groups i ...
- [AlwaysOn Availability Groups]使用Powershell监控AlwayOn健康
使用Powershell监控AlwayOn健康 1.基本命令概述 AlwayOn Dashboard是很有用的查看整体AG健康状况的工具.但是这个工具不是用于7*24监控的.如果应用程序夜间发送严重的 ...
- [AlwaysOn Availability Groups]CLUSTER.LOG(AG)
CLUSTER.LOG(AG) 作为故障转移资源,在SQL Server和windows故障转移集群服务的资源DLL(hadrres.dll)之间有额外的内部交流,DLL无法被SQL Server监控 ...
- [AlwaysOn Availability Groups]AG扩展事件
AG扩展事件 SQL Server 2012定义了一些关于AlwaysOn的扩展事件.你可以监控这些扩展事件来帮助诊断AG的根本问题.你也可以使用以下语句查看扩展事件: SELECT * FROM s ...
- [AlwaysOn Availability Groups]排查:AG超过RTO
排查:AG超过RTO 自动故障转移或者手动转移之后,没有数据都是,你可能会发现切换时间超过了你的RTO.或者当你评估切换时间同步提交secondary副本,发现超过了你的RTO. 1. 通常原因 通常 ...
- [AlwaysOn Availability Groups]排查:AG超过RPO
排查:AG超过RPO 在异步提交的secondary上执行了切换,你可能会发现数据的丢失大于RPO,或者在计算可以忍受的数据都是超过了RPO. 1.通常原因 1.网络延迟太高,网络吞吐量太低,导致Pr ...
随机推荐
- CSharpGL(24)用ComputeShader实现一个简单的图像边缘检测功能
CSharpGL(24)用ComputeShader实现一个简单的图像边缘检测功能 效果图 这是红宝书里的例子,在这个例子中,下述功能全部登场,因此这个例子可作为使用Compute Shader的典型 ...
- 快速Android开发系列网络篇之Android-Async-Http
先来看一下最基本的用法 AsyncHttpClient client = new AsyncHttpClient(); client.get("http://www.google.com&q ...
- HTML5_07之WebSocket
1.HTML5新特性之WebSocket: ①HTTP协议的不足:基于“请求——响应”模型,只有在客户端发送请求后,服务器才会给予响应:对于实时的股票走势图,以及聊天通讯等无法满足需求: ②解决方案: ...
- 我为NET狂官方面试题
基础牢不牢测一测便了解,工作没工作测一测便清楚,工作有几年测一测便知道 最近帮人过一遍C#基础,出了点题目,有需要的同志拿走 答案不唯一,官方答案只供参考,若有错误欢迎提出~ 更新ing 1.面向过程 ...
- 你可能不知道的陷阱, IEnumerable接口
1. IEnumerable 与 IEnumerator IEnumerable枚举器接口的重要性,说一万句话都不过分.几乎所有集合都实现了这个接口,Linq的核心也依赖于这个万能的接口.C语言的 ...
- TortoiseSVN的使用
1.安装和下载client客户端 (1)下载windows端程序:http://tortoisesvn.net/downloads.一般而言,如果是32bit操作系统,运行TortoiseSVN-1. ...
- 【NLP】揭秘马尔可夫模型神秘面纱系列文章(三)
向前算法解决隐马尔可夫模型似然度问题 作者:白宁超 2016年7月11日22:54:57 摘要:最早接触马尔可夫模型的定义源于吴军先生<数学之美>一书,起初觉得深奥难懂且无什么用场.直到学 ...
- Java 位运算2-LeetCode 201 Bitwise AND of Numbers Range
在Java位运算总结-leetcode题目博文中总结了Java提供的按位运算操作符,今天又碰到LeetCode中一道按位操作的题目 Given a range [m, n] where 0 <= ...
- 跨域之Ajax
提到Ajax,一般都会想到XMLHttpRequest对象,通过这个对象向服务器发送请求,可以实现页面无刷新而更新数据. 由于同源策略的限制,一般情况下,只能通过XMLHttpRequest对象向同源 ...
- Linux发邮件之mail命令
一.mail命令 1.配置 vim /etc/mail.rc 文件尾增加以下内容 set from=1968089885@qq.com smtp="smtp.qq.com" set ...