java问题诊断
http://techblog.youdao.com/?p=961
http://linuxtools-rst.readthedocs.org/zh_CN/latest/advance/03_optimization.html
http://www.dbafree.net/?p=1128
www.xuebuyuan.com/2199692.html
一个多线程程序挂起问题解决


N个线程,做同样的事,跑的一直好好的,突然某个线程就挂住了。于是使用 ps -eLf|grep name查看了线程相关的PID,并对其进行了strace.如下:
$ strace -p 13251
Process 13251 attached - interrupt to quit
futex(0x1fcc500, FUTEX_WAIT_PRIVATE, 0, NULL
发现其一直hang在futex-FUTEX_WAIT_PRIVATE这里,可以看到futex一直在wait状态,长时间被挂起,就好象睡觉睡着了,没有人叫他起床。
我们的程序代码如下:
while 1:
#操作线程共享变量:
#1.操作一个线程安全的队列
if(queue.size>0):
queue.get()
#2.操作线程不安全的hash结构,不过N个线程操作的key都是各不同的
#操作方式为hash{线程名}=xxx)。
hash{thread_name}=xxx
开始有点怀疑这个hash字典,因为非线程安全的,不过strace看到的是一个futex,那么应该和它关系不大,而跟线程安全的queue有更大的关系。因为futex可以对它进行保护。
于是先了解futex相关的情况,下面这段解释很清楚:
Futex是一种用户态和内核态混合的同步机制。首先,同步的进程间通过mmap共享一段内存,futex变量就位于这段共享
的内存中且操作是原子的,当进程尝试进入互斥区或者退出互斥区的时候,先去查看共享内存中的futex变量,如果没有竞争发生,则只修改futex,而不
用再执行系统调用了。当通过访问futex变量告诉进程有竞争发生,则还是得执行系统调用去完成相应的处理(wait 或者 wake
up)。简单的说,futex就是通过在用户态的检查,(motivation)如果了解到没有竞争就不用陷入内核了,大大提高了low-
contention时候的效率。
FUTEX_WAIT: 原子性的检查uaddr中计数器的值是否为val,如果是则让进程休眠,直到FUTEX_WAKE或者超时(time-out)。也就是把进程挂到uaddr相对应的等待队列上去。
futex这个方法,有timeout等参数,如果不加timeout参数,它会一直被阻塞,直到FUTEX_WAKE
int futex (int *uaddr, int op, int val, const struct timespec *timeout,int *uaddr2, int val3);
所以基本确认,挂起是由于futex没有被唤醒的原因导致的。
if(queue.size()>0
#在多线程并发情况,执行下面这步get操作的时候,可能队列是空的,此时get()方法会阻塞
queue.get()
而我在另一个线程里面,如果执行了queue.put(),那么应该是可以唤醒get()的,难道程序会这么笨?
于是检查了下我的put方法,发现我其实不是一个真正的put.代码如下:
for 1..1000
tmpqueue.put(xx)
#因为queue并没有真正的put,而是直接指向了一个新对象,所以不能唤醒get.
queue=tmpqueue
找到了原因,问题就好解决了。当然因为程序设计上面的问题,我不能修改put的情况,于是,我修改get()方法,增加timeout参数。问题解决。
if(queue.size()):
queue.get(timeout=0.1)
类似这种多线程的问题排查很困难,麻烦。不过碰到好几次,在同事们的帮助下,都比较幸运的很快就找到原因了。
这次也学到了不少。这篇文章挺不错的http://www.cnblogs.com/yysblog/archive/2012/11/03/2752728.html,转一下:
Linux中的线程同步机制(一) — Futex
引子
在编译2.6内核的时候,你会在编译选项中看到[*] Enable futex support这一项,上网查,有的资料会告诉你”不选这个内核不一定能正确的运行使用glibc的程序”,那futex是什么?和glibc又有什么关系呢?
1. 什么是Futex
Futex 是Fast Userspace muTexes的缩写,由Hubertus Franke, Matthew Kirkwood,
Ingo Molnar and Rusty Russell共同设计完成。几位都是linux领域的专家,其中可能Ingo
Molnar大家更熟悉一些,毕竟是O(1)调度器和CFS的实现者。
Futex按英文翻译过来就是快速用户空间互斥体。其设计思想其实 不难理解,在传统的Unix系统中,System V IPC(inter
process communication),如 semaphores, msgqueues,
sockets还有文件锁机制(flock())等进程间同步机制都是对一个内核对象操作来完成的,这个内核对象对要同步的进程都是可见的,其提供了共享
的状态信息和原子操作。当进程间要同步的时候必须要通过系统调用(如semop())在内核中完成。可是经研究发现,很多同步是无竞争的,即某个进程进入
互斥区,到再从某个互斥区出来这段时间,常常是没有进程也要进这个互斥区或者请求同一同步变量的。但是在这种情况下,这个进程也要陷入内核去看看有没有人
和它竞争,退出的时侯还要陷入内核去看看有没有进程等待在同一同步变量上。这些不必要的系统调用(或者说内核陷入)造成了大量的性能开销。为了解决这个问
题,Futex就应运而生,Futex是一种用户态和内核态混合的同步机制。首先,同步的进程间通过mmap共享一段内存,futex变量就位于这段共享
的内存中且操作是原子的,当进程尝试进入互斥区或者退出互斥区的时候,先去查看共享内存中的futex变量,如果没有竞争发生,则只修改futex,而不
用再执行系统调用了。当通过访问futex变量告诉进程有竞争发生,则还是得执行系统调用去完成相应的处理(wait 或者 wake
up)。简单的说,futex就是通过在用户态的检查,(motivation)如果了解到没有竞争就不用陷入内核了,大大提高了low-
contention时候的效率。 Linux从2.5.7开始支持Futex。
2. Futex系统调用
Futex是一种用户态和内核态混合机制,所以需要两个部分合作完成,linux上提供了sys_futex系统调用,对进程竞争情况下的同步处理提供支持。
其原型和系统调用号为
#include <linux/futex.h>
#include <sys/time.h>
int futex (int *uaddr, int op, int val, const struct timespec *timeout,int *uaddr2, int val3);
#define __NR_futex 240
虽然参数有点长,其实常用的就是前面三个,后面的timeout大家都能理解,其他的也常被ignore。
uaddr就是用户态下共享内存的地址,里面存放的是一个对齐的整型计数器。
op存放着操作类型。定义的有5中,这里我简单的介绍一下两种,剩下的感兴趣的自己去man futex
FUTEX_WAIT: 原子性的检查uaddr中计数器的值是否为val,如果是则让进程休眠,直到FUTEX_WAKE或者超时(time-out)。也就是把进程挂到uaddr相对应的等待队列上去。
FUTEX_WAKE: 最多唤醒val个等待在uaddr上进程。
可见FUTEX_WAIT和FUTEX_WAKE只是用来挂起或者唤醒进程,当然这部分工作也只能在内核态下完成。有些人尝试着直接使用futex
系统调
用来实现进程同步,并寄希望获得futex的性能优势,这是有问题的。应该区分futex同步机制和futex系统调用。futex同步机制还包括用户态
下的操作,我们将在下节提到。
3. Futex同步机制
所有的futex同步操作都应该从用户空间开始,首先创建一个futex同步变量,也就是位于共享内存的一个整型计数器。
当
进程尝试持有锁或者要进入互斥区的时候,对futex执行”down”操作,即原子性的给futex同步变量减1。如果同步变量变为0,则没有竞争发生,
进程照常执行。如果同步变量是个负数,则意味着有竞争发生,需要调用futex系统调用的futex_wait操作休眠当前进程。
当进程释放锁或
者要离开互斥区的时候,对futex进行”up”操作,即原子性的给futex同步变量加1。如果同步变量由0变成1,则没有竞争发生,进程照常执行。如
果加之前同步变量是负数,则意味着有竞争发生,需要调用futex系统调用的futex_wake操作唤醒一个或者多个等待进程。
这里的原子性加减通常是用CAS(Compare and Swap)完成的,与平台相关。CAS的基本形式是:CAS(addr,old,new),当addr中存放的值等于old时,用new对其替换。在x86平台上有专门的一条指令来完成它: cmpxchg。
可见: futex是从用户态开始,由用户态和核心态协调完成的。
4. 进/线程利用futex同步
进程或者线程都可以利用futex来进行同步。
对于线程,情况比较简单,因为线程共享虚拟内存空间,虚拟地址就可以唯一的标识出futex变量,即线程用同样的虚拟地址来访问futex变量。
对
于进程,情况相对复杂,因为进程有独立的虚拟内存空间,只有通过mmap()让它们共享一段地址空间来使用futex变量。每个进程用来访问futex的
虚拟地址可以是不一样的,只要系统知道所有的这些虚拟地址都映射到同一个物理内存地址,并用物理内存地址来唯一标识futex变量。
小结:
1. Futex变量的特征:1)位于共享的用户空间中 2)是一个32位的整型 3)对它的操作是原子的
2. Futex在程序low-contention的时候能获得比传统同步机制更好的性能。
3. 不要直接使用Futex系统调用。
4. Futex同步机制可以用于进程间同步,也可以用于线程间同步。
Linux中的线程同步机制(二)–In Glibc
在linux中进行多线程开发,同步是不可回避的一个问题。在POSIX标准中定义了三种线程同步机制: Mutexes(互斥量),
Condition Variables(条件变量)和POSIX
Semaphores(信号量)。NPTL基本上实现了POSIX,而glibc又使用NPTL作为自己的线程库。因此glibc中包含了这三种同步机制
的实现(当然还包括其他的同步机制,如APUE里提到的读写锁)。
Glibc中常用的线程同步方式举例:
Semaphore
变量定义: sem_t sem;
初始化: sem_init(&sem,0,1);
进入加锁: sem_wait(&sem);
退出解锁: sem_post(&sem);
Mutex
变量定义: pthread_mutex_t mut;
初始化: pthread_mutex_init(&mut,NULL);
进入加锁: pthread_mutex_lock(&mut);
退出解锁: pthread_mutex_unlock(&mut);
这些用于同步的函数和futex有什么关系?下面让我们来看一看:
以Semaphores为例,
进入互斥区的时候,会执行sem_wait(sem_t *sem),sem_wait的实现如下:
int sem_wait (sem_t *sem)
{
int *futex = (int *) sem;
if (atomic_decrement_if_positive (futex) > 0)
return 0;
int err = lll_futex_wait (futex, 0);
return -1;
)
atomic_decrement_if_positive()的语义就是如果传入参数是正数就将其原子性的减一并立即返回。如果信号量为正,在Semaphores的语义中意味着没有竞争发生,如果没有竞争,就给信号量减一后直接返回了。
如果传入参数不是正数,即意味着有竞争,调用lll_futex_wait(futex,0),lll_futex_wait是个宏,展开后为:
#define lll_futex_wait(futex, val) \
({ \
…
__asm __volatile (LLL_EBX_LOAD \
LLL_ENTER_KERNEL \
LLL_EBX_LOAD \
: “=a” (__status) \
: “0″ (SYS_futex), LLL_EBX_REG (futex), “S” (0), \
“c” (FUTEX_WAIT), “d” (_val), \
“i” (offsetof (tcbhead_t, sysinfo)) \
: “memory”); \
… \
})
可以看到当发生竞争的时候,sem_wait会调用SYS_futex系统调用,并在val=0的时候执行FUTEX_WAIT,让当前线程休眠。
从
这个例子我们可以看出,在Semaphores的实现过程中使用了futex,不仅仅是说其使用了futex系统调用(再重申一遍只使用futex系统调
用是不够的),而是整个建立在futex机制上,包括用户态下的操作和核心态下的操作。其实对于其他glibc的同步机制来说也是一样,都采纳了
futex作为其基础。所以才会在futex的manual中说:对于大多数程序员不需要直接使用futexes,取而代之的是依靠建立在futex之上
的系统库,如NPTL线程库(most programmers will in fact not be using futexes
directly but instead rely on system libraries built on them, such as the
NPTL pthreads implementation)。所以才会有如果在编译内核的时候不 Enable futex
support,就”不一定能正确的运行使用Glibc的程序”。
小结:
1. Glibc中的所提供的线程同步方式,如大家所熟知的Mutex,Semaphore等,大多都构造于futex之上了,除了特殊情况,大家没必要再去实现自己的futex同步原语。
2. 大家要做的事情,似乎就是按futex的manual中所说得那样: 正确的使用Glibc所提供的同步方式,并在使用它们的过程中,意识到它们是利用futex机制和linux配合完成同步操作就可以了。
Linux中的线程同步机制(三)–Practice
上回说到Glibc中(NPTL)的线程同步方式如Mutex,Semaphore等都使用了futex作为其基础。那么实际使用是什么样子,又会碰到什么问题呢?
先来看一个使用semaphore同步的例子。
sem_t sem_a;
void *task1();
int main(void){
int ret=0;
pthread_t thrd1;
sem_init(&sem_a,0,1);
ret=pthread_create(&thrd1,NULL,task1,NULL); //创建子线程
pthread_join(thrd1,NULL); //等待子线程结束
}
void *task1()
{
int sval = 0;
sem_wait(&sem_a); //持有信号量
sleep(5); //do_nothing
sem_getvalue(&sem_a,&sval);
printf(“sem value = %d\n”,sval);
sem_post(&sem_a); //释放信号量
}
程序很简单,我们在主线程(执行main的线程)中创建了一个线程,并用join等待其结束。在子线程中,先持有信号量,然后休息一会儿,再释放信号量,结束。
因为这段代码中只有一个线程使用信号量,也就是没有线程间竞争发生,按照futex的理论,因为没有竞争,所以所有的锁操作都将在用户态中完成,而不会执行系统调用而陷入内核。我们用strace来跟踪一下这段程序的执行过程中所发生的系统调用:
…
20533 futex(0xb7db1be8, FUTEX_WAIT, 20534, NULL <unfinished …>
20534 futex(0×8049870, FUTEX_WAKE, 1) = 0
20533 <… futex resumed> ) = 0
…
20533是main线程的id,20534是其子线程的id。出乎我们意料之外的是这段程序还是发生了两次futex系统调用,我们来分析一下这分别是什么原因造成的。
1. 出人意料的”sem_post()”
20534 futex(0×8049870, FUTEX_WAKE, 1) = 0
子
线程还是执行了FUTEX_WAKE的系统调用,就是在sem_post(&sem_a);的时候,请求内核唤醒一个等待在sem_a上的线程,
其返回值是0,表示现在并没有线程等待在sem_a(这是当然的,因为就这么一个线程在使用sem_a),这次futex系统调用白做了。这似乎和
futex的理论有些出入,我们再来看一下sem_post的实现。
int sem_post (sem_t *sem)
{
int *futex = (int *) sem;
int nr = atomic_increment_val (futex);
int err = lll_futex_wake (futex, nr);
return 0;
}
我们看到,Glibc在实现sem_post的时候给futex原子性的加上1后,不管futex的值是什么,都执行了lll_futex_wake(),即futex(FUTEX_WAKE)系统调用。
在
第二部分中(见前文),我们分析了sem_wait的实现,当没有竞争的时候是不会有futex调用的,现在看来真的是这样,但是在sem_post的时
候,无论有无竞争,都会调用sys_futex(),为什么会这样呢?我觉得应该结合semaphore的语义来理解。在semaphore的语义
中,sem_wait()的意思是:”挂起当前进程,直到semaphore的值为非0,它会原子性的减少semaphore计数值。” 我们可以看
到,semaphore中是通过0或者非0来判断阻塞或者非阻塞线程。即无论有多少线程在竞争这把锁,只要使用了
semaphore,semaphore的值都会是0。这样,当线程推出互斥区,执行sem_post(),释放semaphore的时候,将其值由0改
1,并不知道是否有线程阻塞在这个semaphore上,所以只好不管怎么样都执行futex(uaddr, FUTEX_WAKE,
1)尝试着唤醒一个进程。而相反的,当sem_wait(),如果semaphore由1变0,则意味着没有竞争发生,所以不必去执行futex系统调
用。我们假设一下,如果抛开这个语义,如果允许semaphore值为负,则也可以在sem_post()的时候,实现futex机制。
2. 半路杀出的”pthread_join()”
那另一个futex系统调用是怎么造成的呢?
是因为pthread_join();在Glibc中,pthread_join也是用futex系统调用实现的。程序中的
pthread_join(thrd1,NULL); 就对应着20533 futex(0xb7db1be8, FUTEX_WAIT, 20534,
NULL <unfinished …>很
好解释,主线程要等待子线程(id号20534上)结束的时候,调用futex(FUTEX_WAIT),并把var参数设置为要等待的子线程号
(20534),然后等待在一个地址为0xb7db1be8的futex变量上。当子线程结束后,系统会负责把主线程唤醒。于是主线程就20533
<… futex resumed> ) =
0恢复运行了。要注意的是,如果在执行pthread_join()的时候,要join的线程已经结束了,就不会再调用futex()阻塞当前进程了。
3. 更多的竞争。
我们把上面的程序稍微改改:
在main函数中:
int main(void){
…
sem_init(&sem_a,0,1);
ret=pthread_create(&thrd1,NULL,task1,NULL);
ret=pthread_create(&thrd2,NULL,task1,NULL);
ret=pthread_create(&thrd3,NULL,task1,NULL);
ret=pthread_create(&thrd4,NULL,task1,NULL);
pthread_join(thrd1,NULL);
pthread_join(thrd2,NULL);
pthread_join(thrd3,NULL);
pthread_join(thrd4,NULL);
…
}
这样就有更的线程参与sem_a的争夺了。我们来分析一下,这样的程序会发生多少次futex系统调用。
1) sem_wait()
第一个进入的线程不会调用futex,而其他的线程因为要阻塞而调用,因此sem_wait会造成3次futex(FUTEX_WAIT)调用。
2) sem_post()
所有线程都会在sem_post的时候调用futex, 因此会造成4次futex(FUTEX_WAKE)调用。
3) pthread_join()
别忘了还有pthread_join(),我们是按thread1, thread2, thread3,
thread4这样来join的,但是线程的调度存在着随机性。如果thread1最后被调度,则只有thread1这一次futex调用,所以
pthread_join()造成的futex调用在1-4次之间。(虽然不是必然的,但是4次更常见一些)
所以这段程序至多会造成3+4+4=11次futex系统调用,用strace跟踪,验证了我们的想法。
19710 futex(0xb7df1be8, FUTEX_WAIT, 19711, NULL <unfinished …>
19712 futex(0×8049910, FUTEX_WAIT, 0, NULL <unfinished …>
19713 futex(0×8049910, FUTEX_WAIT, 0, NULL <unfinished …>
19714 futex(0×8049910, FUTEX_WAIT, 0, NULL <unfinished …>
19711 futex(0×8049910, FUTEX_WAKE, 1 <unfinished …>
19710 futex(0xb75f0be8, FUTEX_WAIT, 19712, NULL <unfinished …>
19712 futex(0×8049910, FUTEX_WAKE, 1 <unfinished …>
19710 futex(0xb6defbe8, FUTEX_WAIT, 19713, NULL <unfinished …>
19713 futex(0×8049910, FUTEX_WAKE, 1 <unfinished …>
19710 futex(0xb65eebe8, FUTEX_WAIT, 19714, NULL <unfinished …>
19714 futex(0×8049910, FUTEX_WAKE, 1) = 0
(19710是主线程,19711,19712,19713,19714是4个子线程)
4. 更多的问题
事
情到这里就结束了吗? 如果我们把semaphore换成Mutex试试。你会发现当自始自终没有竞争的时候,mutex会完全符合futex机制,不管
是lock还是
unlock都不会调用futex系统调用。有竞争的时候,第一次pthread_mutex_lock的时候不会调用futex调用,看起来还正常。但
是最后一次pthread_mutex_unlock的时候,虽然已经没有线程在等待mutex了,可还是会调用futex(FUTEX_WAKE)。原
因是什么?欢迎讨论!!!
小结:
1. 虽然semaphore,mutex等同步方式构建在futex同步机制之上。然而受其语义等的限制,并没有完全按futex最初的设计实现。
2. pthread_join()等函数也是调用futex来实现的。
3. 不同的同步方式都有其不同的语义,不同的性能特征,适合于不同的场景。我们在使用过程中要知道他们的共性,也得了解它们之间的差异。这样才能更好的理解多线程场景,写出更高质量的多线程程序。
有道技术沙龙博客
分享有道人的技术思考

Main menu
Post navigation
用“逐步排除”的方法定位Java服务线上“系统性”故障
李斯宁(高级测试开发工程师)
一、摘要
二、导言
语言是广泛使用的语言,它具有跨平台的特性和易学易用的特点,很多服务端应用都采用Java语言开发。由于软件系统本身以及运行环境的复杂性,Java的
应用不可避免地会出现一些故障。尽管故障的表象通常比较明显(服务反应明显变慢、输出发生错误、发生崩溃等),但故障定位却并不一定容易。为什么呢?有如
下原因:
三、本方法适用的范围
四、有哪些异常现象
个程序由于BUG或者配置不当,可能会占用过多的系统资源,导致系统资源匮乏。这时,系统中其它程序就会出现计算缓慢、超时、操作失败等“系统性”故障。
常见的系统资源异常现象有:CPU占用过高、物理内存富余量极少、磁盘I/O占用过高、发生换入换出过多、网络链接数过多。可以通过top、iostat、vmstat、netstat工具获取到相应情况。
- Java堆满
Java堆是“Java虚拟机”从操作系统申请到的一大块内存,用于存放Java程序运行中创建的对象。当Java堆满或者较满的情况下,会触发
“Java虚拟机”的“垃圾收集”操作,将所有“不可达对象”(即程序逻辑不能引用到的对象)清理掉。有时,由于程序逻辑或者Java堆参数设置的问题,
会导致“可达对象”(即程序逻辑可以引用到的对象)占满了Java堆。这时,Java虚拟机就会无休止地做“垃圾回收”操作,使得整个Java程序会进入
卡死状态。我们可以使用jstat工具查看Java堆的占用率。 - 日志中的异常
目标服务可能会在日志中记录一些异常信息,例如超时、操作失败等信息,其中可能含有系统故障的关键信息。 - 疑难杂症
死锁、死循环、数据结构异常(过大或者被破坏)、集中等待外部服务回应等现象。这些异常现象通常采用jstack工具可以获取到非常有用的线索。
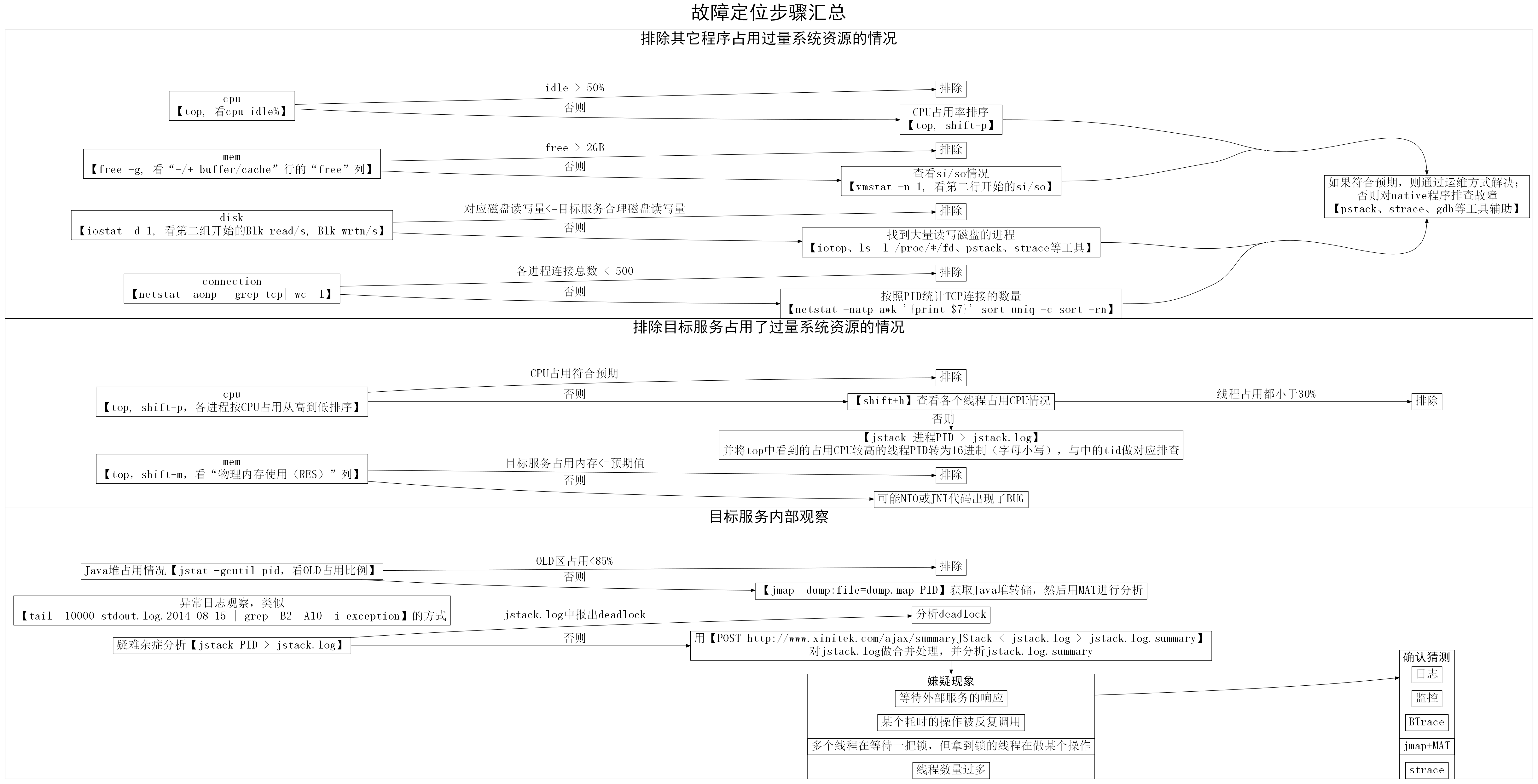
五、故障定位的步骤
于不能排除的方面,要根据该信息对应的“危险程度”来判断是应该“进一步深入”还是“暂时跳过”。例如“目标服务Java堆占用100%”这是一条危险程
度较高的信息,建议立即“进一步深入”。而对于“在CPU核数为8的机器上,其它程序偶然占用CPU达200%”这种危险程度不是很高的信息,则建议“暂
时跳过”。当然,有些具体情况还需要故障排查人员根据自己的经验做出判断。
第一步:排除其它程序占用过量系统资源的情况
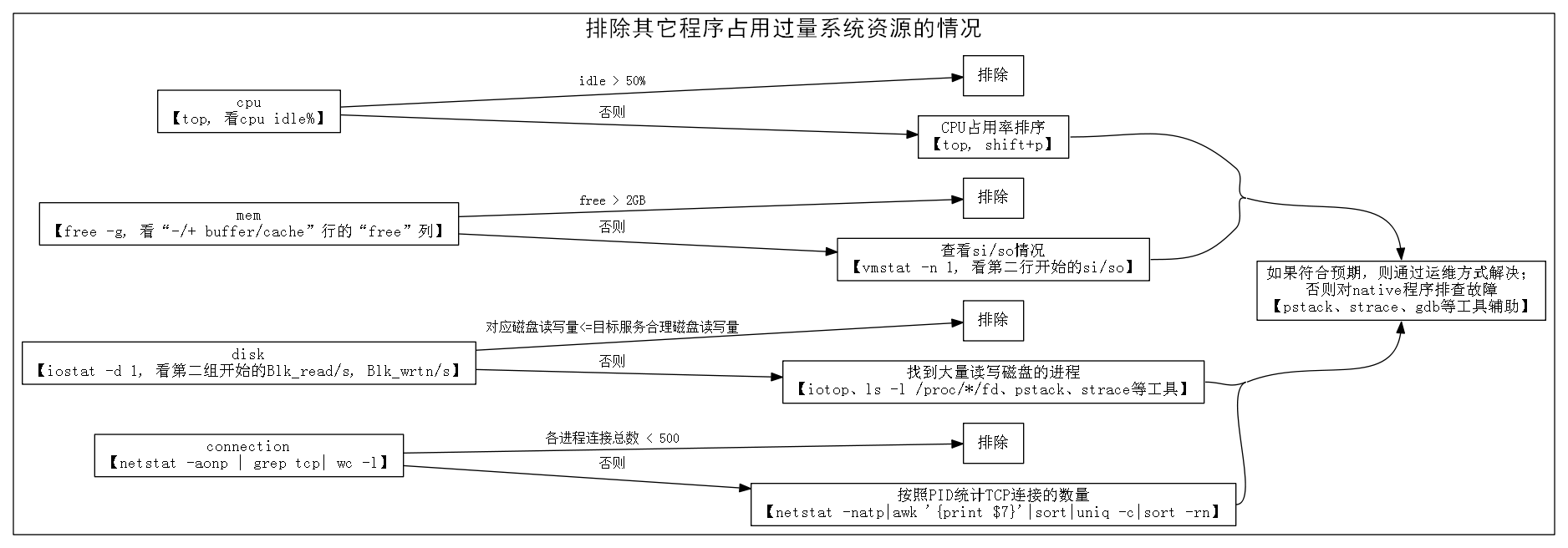



一行数值表示的是从系统启动到运行命令时的均值,我们忽略掉。从第二行开始,每一行的si/so表示该秒内si/so的block数。如果多行数值都为
零,则可以排除物理内存不足的问题。如果数值较大(例如大于1000
blocks/sec,block的大小一般是1KB)则说明存在较明显的内存不足问题。我们可以运行【top】输入shift+m,将进程按照物理内存
占用(“RES”列)从大到小进行排序,然后对排前面的进程逐一排查(见下面TIP)。
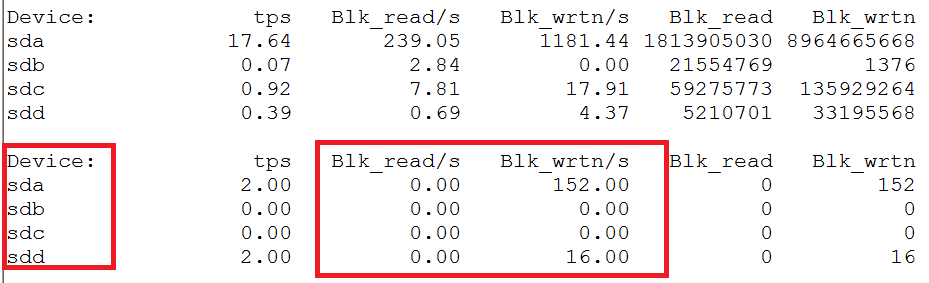
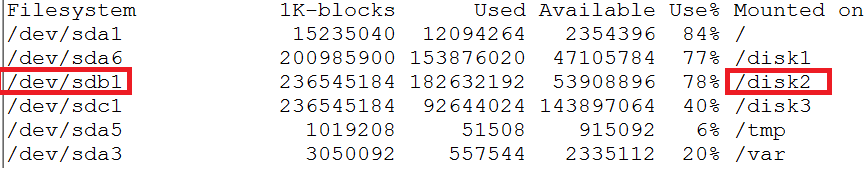
假如定位到是某个外部程序占用过量系统资源,则依据进程的功能和配置情况判断是否合乎预期。假如符合预期,则考虑将服务迁移到其他机器、修改程序运行的磁
盘、修改程序配置等方式解决。假如不符合预期,则可能是运行者对该程序不太了解或者是该程序发生了BUG。外部程序通常可能是Java程序也可能不是
Java程序,如果是Java程序,可以把它当作目标服务一样进行排查;而非Java程序具体排查方法超出了本文范围,列出三个工具供参考选用:
- 系统提供的调用栈的转储工具【pstack】,可以了解到程序中各个线程当前正在干什么,从而了解到什么逻辑占用了CPU、什么逻辑占用了磁盘等
- 系统提供的调用跟踪工具【strace】,可以侦测到程序中每个系统API调用的参数、返回值、调用时间等。从而确认程序与系统API交互是否正常等。
- 系统提供的调试器【gdb】,可以设置条件断点侦测某个系统函数调用的时候调用栈是什么样的。从而了解到什么逻辑不断在分配内存、什么逻辑不断在创建新连接等
第二步:排除目标服务占用了过量系统资源的情况
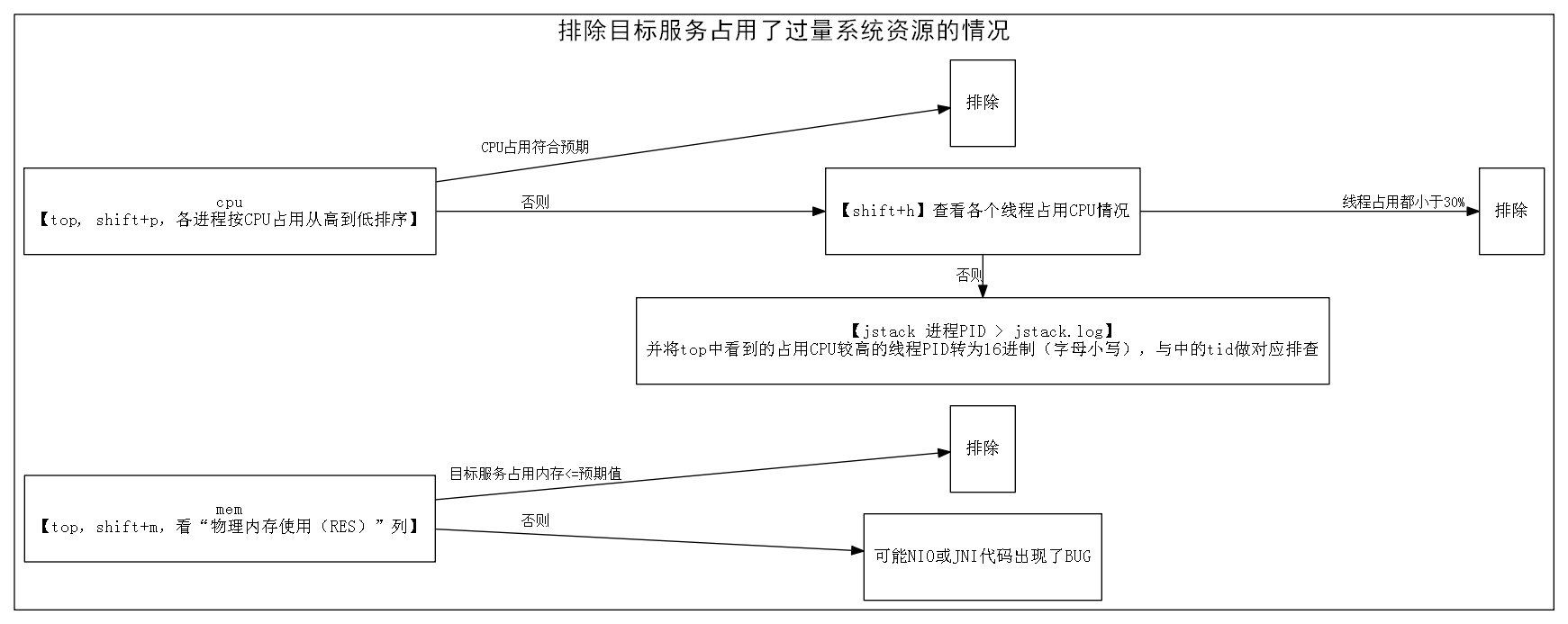
- 如果CPU使用分散到多个线程,而且每个线程占用都不算高(例如都<30%),则排除CPU占用过高的问题
- 如果CPU使用集中到一个或几个线程,而且很高(例如都>95%),则用【jstack pid >
jstack.log】获取目标服务中线程调用栈的情况。top中看到的占用CPU较高的线程的PID转换成16进制(字母用小写),然后在
jstack.log中找到对应线程,检查其逻辑:- 假如对应线程是纯计算型任务(例如GC、正则匹配、数值计算等),则排除CPU占用过高的问题。当然如果这种线程占用CPU总量如果过多(例如占满了所有核),则需要对线程数量做控制(限制线程数 < CPU核数)。
- 假如对应线程不是纯计算型任务(例如只是向其他服务请求一些数据,然后简单组合一下返回给用户等),而该线程CPU占用过高(>95%),则可能发生了异常。例如:死循环、数据结构过大等问题,确定具体原因的方法见下文“第三步:目标进程内部观察”。
第三步:目标服务内部观察

通过【jmap -dump:file=dump.map
pid】取得目标服务的Java堆转储,然后找一台空闲内存较大的机器在VNC中运行mat工具。mat工具中打开dump.map后,可以方便地分析内
存中什么对象引用了大量的对象(从逻辑意义上来说,就是该对象占用了多大比例的内存)。具体使用可以ca
- 检查jstack.log中是否有deadlock报出,如果没有则排除deadlock情况。
Found one Java-level deadlock:=============================“Thread-0″:waiting to lock monitor 0x1884337c (object 0x046ac698, a java.lang.Object),which is held by “main”“main”:waiting to lock monitor 0x188426e4 (object 0x046ac6a0, a java.lang.Object),which is held by “Thread-0″Java stack information for the threads listed above:===================================================“Thread-0″:at LockProblem$T2.run(LockProblem.java:14)- waiting to lock <0x046ac698> (a java.lang.Object)- locked <0x046ac6a0> (a java.lang.Object)“main”:at LockProblem.main(LockProblem.java:25)- waiting to lock <0x046ac6a0> (a java.lang.Object)- locked <0x046ac698> (a java.lang.Object)Found 1 deadlock.
- 用【POST http://www.xinitek.com/ajax/summaryJStack < jstack.log > jstack.log.summary】对jstack.log做合并处理,然后继续分析故障所在。
| 情况 | 嫌疑点 | 猜测原因 |
| 线程数量过多 | 某种线程数量过多 |
运行环境中“限制线程数量”的机制失效
|
|
多个线程在等待一把锁,但拿到锁的线程在做某个操作
|
拿到这把锁的线程在做网络connect操作
|
被connect的服务异常 |
|
|
拿到锁的线程在做数据结构遍历操作
|
该数据结构过大或被破坏
|
|
某个耗时的操作被反复调用
|
某个应当被缓存的对象多次被创建
|
对象池的配置错误 |
|
等待外部服务的响应
|
很多线程都在等待外部服务的响应
|
该外部服务故障
|
|
|
很多线程都在等待FutureTask完成,而FutureTask在等待外部服务的响应
|
该外部服务故障
|
用于查看Java级别内存情况。jmap是JDK自带工具,可以将Java程序的Java堆转储到数据文件中;MAT是eclipse.org上提供的一
个工具,可以检查jmap转储数据文件中的数据。结合这两个工具,我们可以非常容易地看到Java程序内存中所有对象及其属性。
1000 threads at“Timer-0″ prio=6 tid=0x189e3800 nid=0x34e0 in Object.wait() [0x18c2f000]java.lang.Thread.State: TIMED_WAITING (on object monitor)at java.lang.Object.wait(Native Method)at java.util.TimerThread.mainLoop(Timer.java:552)- locked [***] (a java.util.TaskQueue)at java.util.TimerThread.run(Timer.java:505)
38 threads at“Thread-44″ prio=6 tid=0×18981800 nid=0x3a08 waiting for monitor entry [0x1a85f000]java.lang.Thread.State: BLOCKED (on object monitor)at SlowAction$Users.run(SlowAction.java:15)- waiting to lock [***] (a java.lang.Object)
1 threads at“Thread-3″ prio=6 tid=0x1894f400 nid=0×3954 runnable [0x18d1f000]java.lang.Thread.State: RUNNABLEat java.util.LinkedList.indexOf(LinkedList.java:603)at java.util.LinkedList.contains(LinkedList.java:315)at SlowAction$Users.run(SlowAction.java:18)- locked [***] (a java.lang.Object)
daemon prio=10 tid=0x000000004dc43800 nid=0x65f5 waiting for monitor
entry [0x00000000507ff000]
“Thread-0″ prio=6 tid=0x189cdc00 nid=0×2904 runnable [0x18d5f000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:150)
at java.net.SocketInputStream.read(SocketInputStream.java:121)
…
at RequestingService$RPCThread.run(RequestingService.java:24)
“pool-1-thread-1″ prio=6 tid=0x188fc000 nid=0×2834 runnable [0x1d71f000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:150)
at java.net.SocketInputStream.read(SocketInputStream.java:121)
…
at IndirectWait.request(IndirectWait.java:23)
at IndirectWait$MyThread$1.call(IndirectWait.java:46)
at IndirectWait$MyThread$1.call(IndirectWait.java:1)
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334)
at java.util.concurrent.FutureTask.run(FutureTask.java:166)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603)
at java.lang.Thread.run(Thread.java:722)
六、给运维人员的简单步骤
七、参考资料
- BTrace官网
- MAT官网
- 使用jmap和MAT观察Java程序内存数据
- 使用Eclipse远程调试Java应用程序
- Linux下输入【man strace/top/iostat/vmstat/netstat/jstack】
This entry was posted in 技术分享 by youdao. Bookmark the permalink.
3 thoughts on “用“逐步排除”的方法定位Java服务线上“系统性”故障”
温水青蛙 on 2014/08/26 at 12:54 said:
最近遇到线上故障就是CPU负载高,程序响应慢。查了内存和java调用堆栈,分析了日志和代码都未发现明显问题。看来还得多用几招继续排查
李斯宁 on 2014/08/27 at 10:55 said:
你指的负载高是cpu的占用率高吧?
可以通过top中shift+h,shift+p看到的占cpu高的线程的“线程PID”。如果是单个线程CPU占用高,将PID转换到16进制,对应到jstack中的某个线程id。查看对应的调用栈情况。然后根据程序逻辑判断它是否该占用这么多cpu。
如果是很多个线程分别占用10~30%左右,但这样的线程很多。建议通过配置等方式减小该类线程数量。
地质锤 on 2014/09/12 at 13:17 said:
想咨询李工一个技术问题,我的手机(华为B199,安卓4.3)最近做了一次系统更新(华为提供升级包)后,再次安装有道词典,每次查询单词或点击其他功能时总是自动关闭程序。请您给予指导!
strace
ltrace
java问题诊断的更多相关文章
- qconshanghai2015
http://2015.qconshanghai.com/schedule 大会日程 2015年10月15日 星期四 08:30 开场致辞 地点 光大宴会厅 专题 主题演讲 数据分析与移动开发工具 ...
- Spark案例分析
一.需求:计算网页访问量前三名 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- Greys Java在线问题诊断工具
摘要: 线上系统为何经常出错?数据库为何屡遭黑手?业务调用为何频频失败?连环异常堆栈案,究竟是那次调用所为? 数百台服务器意外雪崩背后又隐藏着什么?是软件的扭曲还是硬件的沦丧? 走进科学带你了解Gre ...
- JAVA运行时问题诊断-工具应用篇
该BLOG内容是之前在部门组织讨论运行时问题时自己写的PPT内容,内容以点带面,主要是方便以后自己回顾查看. 大纲包括:1.运行时问题分类 2.服务器自带工具 3.其他工具 4.例子 5.实际情况 运 ...
- java jvm常用命令工具
[尊重原创文章出自:http://www.chepoo.com/java-jvm-command-tools.html] 一.概述 程序运行中经常会遇到各种问题,定位问题时通常需要综合各种信息,如系统 ...
- java技术知识点
1 自我介绍 2 做过的项目 (Java 基础) 3 Java的四个基本特性(抽象.封装.继承,多态),对多态的理解(多态的实现方式)以及在项目中那些地方用到多态 Java的四个基本特性 ◦ ...
- JVM相关参数配置和问题诊断<转>
原文连接:http://blog.csdn.net/chjttony/article/details/6240457 1.Websphere JVM相关问题诊断: 由JVM引起的Websphere问题 ...
- Java内存分配和GC
Java内存分配和回收的机制概括的说,就是:分代分配,分代回收. 对象将根据存活的时间被分为:年轻代(Young Generation).年老代(Old Generation).永久代(Permane ...
- java 内存管理 —— 《Hotspot内存管理白皮书》
说明 要学习Java或者任意一门技术,我觉得最好的是从官网的资料开始学习.官网所给出的资料总是最权威最知道来龙去脉的.而Java中间,垃圾回收与内存管理是Java中非常重要的一部分.<Hot ...
随机推荐
- express学习点滴- 永远不要忘记异步
直接上两段代码,因为nodejs基于异步和事件回调的解决方式,涉及到异步的时候,问题往往藏得很深,以下这个简单的问题困扰了很久.之前怀疑是各种问题,到处改.直到最后一步一步跟代码,跟操作数据库部分豁然 ...
- UITableView简单使用
在iOS开发中UITableView可以说是使用最广泛的控件,我们平时使用的软件中到处都可以看到它的影子,类似于微信.QQ.新浪微博等软件基本上随处都是UITableView.当然它的广泛使用自然离不 ...
- Java Lambda表达式入门[转]
原文链接: Start Using Java Lambda Expressions http://blog.csdn.net/renfufei/article/details/24600507 下载示 ...
- jQuery 学习小结
1,jQuery是一个简单的JavaScript库,提供了一系列辅助函数:以下简称jq; 使用jq时,通常将jq代码放到head部分的事件处理方法中,也可以将其单独写出 .js 文件,引入:但无论哪种 ...
- 在线用户管理--ESFramework 4.0 进阶(05)
无论我们采用何种通信框架来构建我们的分布式系统,在服务端进行用户管理都是非常重要的一个环节.然而用户管理是否应该隶属于通信框架了?这个并不一定,通常来说,用户管理是与具体应用紧密相关的,应该是由应用解 ...
- markdown 自己搞一个浏览工具
注意!`下不能有空行 `上也不能有空行 问题未解决 <!DOCTYPE html> <html lang="en"> <head> <me ...
- PHP ServerPush (推送) 技术
用来代替ajax的请求 转自:http://blog.163.com/bailin_li/blog/static/17449017920124811524364/ 需求: 我想做个会员站内通知的功能. ...
- Android上的远程调试
来源: http://www.seejs.com/archives/296 目录 远程调试概述 使用 Chrome 的 ADB 扩展进行远程调试 1. 安装 ADB 扩展 2. 启用你的移动设备上的 ...
- 判断pc浏览器和手机浏览器方法
一 //平台.设备和操作系统 var system = { win: false, mac: false, xll: f ...
- 错误提示 Unsupported compiler 'com.apple.compilers.llvmgcc42' selected for architecture 'i386'
转自http://blog.csdn.net/cyuyanenen/article/details/51444974 警告提示:Invalid C/C++ compiler in target Cor ...