一个关于vue+mysql+express的全栈项目(四)------ sequelize中部分解释
一、模型的引入
引入db.js
const sequelize = require('./db')
sequelize本身就是一个对象,他提供了众多的方法,
const account = sequelize.model('account') //获取account这个模型
二,数据库基本操作(增、删、改、查)
增:
account.create(data).then(doc => {
const {user_name, user_id, user_info, avatar} = doc
res.cookie('user_id', user_id)
return res.json({
code: 0,
data: {
user_name: user_name,
user_id: user_id,
user_info: user_info,
avatar: avatar
}
})
})
删:
Router.get('/cleardata', function(req,res) {
// 清空全部数据
poetrylist.destroy({
// where: {id: 123}
// 这里可以根据我们定义的条件删除满足条件的数据
}).then((doc) => {
return res.json({
code: 0,
data: doc
})
})
})
改:
Router.post('/updataUserInfo', function(req,res) {
// 完善用户信息
const user_id = req.cookies.user_id
const user_info = req.body.userinfo
account.update(
user_info, // 这里是我们要更新的字段,使用逗号隔开
{
'where': {
'user_id': user_id // 这里是我们要更新那条数据的条件
}
}
).then((doc) => {
return res.json({
code: 0,
data: {
user_info: user_info
}
})
})
})
查:
Router.post('/getUserInfo', function(req,res) {
// 完善用户信息
const user_id = req.body.user_id ? req.body.user_id : req.cookies.user_id
account.findOne({
'where': {'user_id': user_id},
// attributes属性可以指定返回结果,返回那些字段的信息
attributes: ['user_name', 'avatar', 'user_info', 'user_fans', 'attention', 'poetry_num', 'user_id']
}).then((doc) => {
poetrylist.findAll({
where: {'user_id': user_id},
order: [
['create_temp', 'DESC'],
]
}).then((metadata) => {
return res.json({
code: 0,
data: {
user_info: doc,
list: metadata
}
})
})
})
})
这里使用的是findOne,还有findAll,findById等等,具体参考官方文档
三、模型关系
这里就要就要求我们指定数据表之间的关系,这里直说关系,详解请看官方文档
1.一对一(BelongsTo, HasOne )
一对一关联是由一个单一的外键,实现两个模型之间的精确关联。 BelongsTo关联表示一对一关系的外键存在于源模型。
var Player = this.sequelize.define('player', {/* attributes */})
, Team = this.sequelize.define('team', {/* attributes */}); Player.belongsTo(Team); // 会为Player添加一个teamId 属性以保持与Team 主键的关系
默认情况下,一个属于关系的外键将从目标模型的名称和主键名称生成。
目标键是位于目标模型上通过源模型外键列指向的列。默认情况下,目标键是会belongsTo关系中目标模型的主键。要使用自定义列,请用targetKey选项来指定 HasOne关联表示一对一关系的外键存在于目标模型。
虽然被称为HasOne 关联,但大多数 1:1关系中通常会使用BelongsTo 关联,因为BelongsTo 会在源模型中添加外键,而HasOne 则会在目标模型中添加外键。
HasOne 与BelongsTo 的不同 在1:1 的关系中,可使用HasOne 或BelongsTo来定义。但它们的使用场景有所不同
2.一对多(HasMany)
One-To-Many关联是指一个源模型连接多个目标模型。反之目标模型都会有一个明确的源。
var User = sequelize.define('user', {/* ... */})
var Project = sequelize.define('project', {/* ... */})
// 定义 hasMany 关联
Project.hasMany(User, {as: 'Workers'})
会向 User 中添加一个projectId或project_id属性。Project 的实例中会有访问器getWorkers 和 setWorkers。这是一种单向关联方式,如果两个模型间还有其它关联方式请参考下面的多对多关系。
3.多对多(Belongs-To-Many)
多对多(Belongs-To-Many)关联
Belongs-To-Many 关联是指一个源模型连接多个目标模型。而且,目标模型也可以有多个相关的源。 Project.belongsToMany(User, {through: 'UserProject'});
User.belongsToMany(Project, {through: 'UserProject'});
这会创建一个新模型UserProject其中会projectId和userId两个外键。是否使用驼峰命名取决与相关联的两个表。 定义through选项后,Sequelize会尝试自动生成名字,但并一定符合逻辑。 在本例中,会为User添加方法 getUsers, setUsers, addUser,addUsers to Project, and getProjects, setProjects, addProject, and addProjects 有时我们会对连接的模型进行重命名,同样可以使用as实现。
四、多表联查(我们进行用户信息模型和文章模型的联合查询)如下图的结果

const sequelize = require('./db')
const account = sequelize.model('account') // 获取模型
const poetrylist = sequelize.model('poetrylist')
poetrylist.belongsTo(account, {foreignKey: 'user_id', targetKey: 'user_id'}); // 指定模型关系可查询的外键字段
Router.get('/getPoetryList', function(req, res) {
// 获取文章列表
poetrylist.findAll({
include: [{ // 通过include字段执行要联合那个模型进行查询
model: account, // 执行模型
attributes: ['user_name', 'avatar', 'user_id'] // 想要只选择某些属性可以使用 attributes: ['foo', 'bar']
}],
attributes: [
'content',
'poetrylist_id',
'recommend',
'star',
'user_id',
'create_temp',
'guest_num',
'transmit_content',
'transmit_user_id',
'transmit_user_name',
'transmit_poetrylist_id',
'id'],
order: [ // 使用order进行排序
['create_temp', 'DESC'], // 这;i按照时间顺序进行排序
]
}).then((doc) => {
supportlist.findAll({
// 获取当前用户的点赞文章的列表
where: {
"user_id": req.cookies.user_id
}
}).then(suplist => {
// 数据处理
for (let i = 0; i < doc.length; i++) {
doc[i].dataValues.isAttention = false
if (suplist.length) {
for (let j = 0; j < suplist.length; j++) {
if (doc[i].dataValues.poetrylist_id === suplist[j].dataValues.poetrylist_id){
doc[i].dataValues.isAttention = true
}
}
} else {
doc[i].dataValues.isAttention = false
}
}
return res.json({
code: 0,
data: doc,
suplist: suplist
})
})
})
})
以上查询代码转换位sql语句为:
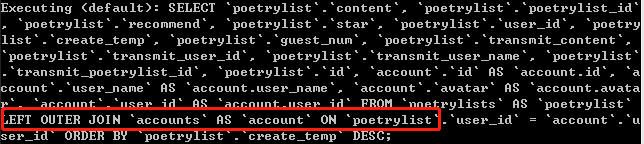
五、事物
Transaction是Sequelize中用于实现事务功能的子类,通过调用Sequelize.transaction()方法可以创建一个该类的实例。在Sequelize中,支持自动提交/回滚,也可以支持用户手动提交/回滚。
Sequelize有两种使用事务的方式:
- 基于
Promise结果链的自动提交/回滚 - 另一种是不自动提交和回滚,而由用户控制事务
受管理的事务(auto-callback)
受管理的事务会自动提交或回滚,你可以向sequelize.transaction方法传递一个回调函数来启动一个事务。
需要注意,在这种方式下传递给回调函数的transaction会返回一个promise链,在promise链中(then或catch)中并不能调用t.commit()或t.rollback()来控制事务。在这种方式下,如果使用事务的所有promise链都执行成功,则自动提交;如果其中之一执行失败,则自动回滚。
return sequelize.transaction(function (t) {
// 要确保所有的查询链都有return返回
return User.create({
firstName: 'Abraham',
lastName: 'Lincoln'
}, {transaction: t}).then(function (user) {
return user.setShooter({
firstName: 'John',
lastName: 'Boothe'
}, {transaction: t});
});
}).then(function (result) {
// Transaction 会自动提交
// result 是事务回调中使用promise链中执行结果
}).catch(function (err) {
// Transaction 会自动回滚
// err 是事务回调中使用promise链中的异常结果
});
不受管理的事务(then-callback)
不受管理的事务需要你强制提交或回滚,如果不进行这些操作,事务会一直保持挂起状态直到超时。
启动一个不受管理的事务,同样是调用sequelize.transaction()方法,但不传递回调函数参数(仍然可以传递选项参数)。然后可以在其返回的promisethen方法中手工控制事务:
Router.post('/subscription', function (req, res) {
// 关注功能
const data = {
user_id: req.cookies.user_id,
target_id: req.body.target_id
}
// Transaction是Sequelize中用于实现事务功能的子类,
// 通过调用Sequelize.transaction()方法可以创建一个该类的实例。
// 在Sequelize中,支持自动提交/回滚,也可以支持用户手动提交/回滚。
return sequelize.transaction({
autocommit: true
}, t => {
return attentionlist.findOne({
'where': {
'user_id': req.cookies.user_id,
'target_id': req.body.target_id
}
},{transaction: t}).then(doc => {
if (!doc) {
return attentionlist.create(data,{transaction: t}).then(ret => {
return account.findOne({
'where': {'user_id': req.cookies.user_id}
}, {transaction: t}).then(rets => {
// increment自增函数
return rets.increment('attention').then(retss => {
return 'success'
})
})
}, {transaction: t}).then(docs => {
return docs
})
} else {
return 100
}
})
}).then(result => {
return res.json({
code: 0,
data: result
})
})
})
项目地址:https://github.com/songdongdong123/vue_chat
一个关于vue+mysql+express的全栈项目(四)------ sequelize中部分解释的更多相关文章
- 一个关于vue+mysql+express的全栈项目(一)
最近学了mysql数据库,寻思着能不能构思一个小的全栈项目,思来想去,于是就有了下面的项目: 先上几张效果图吧 目前暂时前端只有这几个页面,后端开发方面,有登录,注册,完善用户信息,获取用 ...
- 一个关于vue+mysql+express的全栈项目(三)------ 登录注册功能的实现(已经密码安全的设计)
本系列文章,主要是一个前端的视角来实现一些后端的功能,所以不会讲太多的前端东西,主要是分享做这个项目学到的一些东西,,,,, 好了闲话不多说,我们开始搭建后端服务,这里我们采用node的express ...
- 一个关于vue+mysql+express的全栈项目(五)------ 实时聊天部分socket.io
一.基于web端的实时通讯,我们都知道有websocket,为了快速开发,本项目我们采用socket.io(客户端使用socket.io-client) Socket.io是一个WebSocket库, ...
- 一个关于vue+mysql+express的全栈项目(二)------ 前端构建
一.使用vue-cli脚手架构建 <!-- 全局安装vue-cli --> npm install -g vue-cli <!-- 设置vue webpack模板 --> vu ...
- 一个关于vue+mysql+express的全栈项目(六)------ 聊天模型的设计
一.数据模型的设计 这里我们先不讨论群聊的模型,指讨论两个人之间的聊天,我们可以把两个人实时聊天抽象为(点对点)的实时通讯,如下图 我们上面的所说的模型其实也就是数据包的模型应该怎么设计,换句话说就是 ...
- Vue、Node全栈项目~面向小白的博客系统~
个人博客系统 前言 ❝ 代码质量问题轻点喷(去年才学的前端),有啥建议欢迎联系我,联系方式见最下方,感谢! 页面有啥bug也可以反馈给我,感谢! 这是一套包含前后端代码的个人博客系统,欢迎各位提出建议 ...
- 《从零开始做一个MEAN全栈项目》(3)
欢迎关注本人的微信公众号"前端小填填",专注前端技术的基础和项目开发的学习. 上一篇文章给大家讲了一下本项目的开发计划,这一章将会开始着手搭建一个MEAN项目.千里之行,始于足下, ...
- 《从零开始做一个MEAN全栈项目》(2)
欢迎关注本人的微信公众号"前端小填填",专注前端技术的基础和项目开发的学习. 上一节简单介绍了什么是MEAN全栈项目,这一节将简要介绍三个内容:(1)一个通用的MEAN项目的技 ...
- 《从零开始做一个MEAN全栈项目》(1)
欢迎关注本人的微信公众号"前端小填填",专注前端技术的基础和项目开发的学习. 在本系列的开篇,我打算讲一下全栈项目开发的优势,以及MEAN项目各个模块的概览. 为什么选择全栈开发? ...
随机推荐
- UvaLive6441(期望概率dp)
1.涉及负数时同时维护最大和最小,互相转移. 2.考场上最大最小混搭转移WA,赛后发现如果是小的搭小的,大的搭大的就可过,类似这种: db a = (C[i] - W[i]) * dp1[i - ][ ...
- The 17th Zhejiang University Programming Contest Sponsored by TuSimple J
Knuth-Morris-Pratt Algorithm Time Limit: 1 Second Memory Limit: 65536 KB In computer science, t ...
- 洛谷 P4135 作诗
分块大暴力,跟区间众数基本一样 #pragma GCC optimize(3) #include<cstdio> #include<algorithm> #include< ...
- Codeforces Round #321 (Div. 2)
水 A - Kefa and First Steps /************************************************ * Author :Running_Time ...
- php 缩略图
<!DOCTYPE html><!-- HTML5表单 --><form method="post" action="" enct ...
- 516 Longest Palindromic Subsequence 最长回文子序列
给定一个字符串s,找到其中最长的回文子序列.可以假设s的最大长度为1000. 详见:https://leetcode.com/problems/longest-palindromic-subseque ...
- pyton 基础,运算符及字符类型。
一.python运算符: 二.数据类型: 1.数字: int :整型 32位机器上一个整数取值范围为-2**31~2**31-1即-2147483648~2147483647 64位机器上一个整数取 ...
- P3817 小A的糖果
题目描述 小A有N个糖果盒,第i个盒中有a[i]颗糖果. 小A每次可以从其中一盒糖果中吃掉一颗,他想知道,要让任意两个相邻的盒子中加起来都只有x颗或以下的糖果,至少得吃掉几颗糖. 输入输出格式 输入格 ...
- linux的top下buffer与cache的区别
buffer: 缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据 的区域.通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据 时,速度快的设备的操作进程不发 ...
- requirejs&&springboot
1.Spring Boot Spring boot 基础结构主要有三个文件夹: (1)src/main/java 程序开发以及主程序入口 (2)src/main/resources 配置文件 (3) ...