Elasticsearch 索引管理和内核探秘
1. 创建索引,修改索引,删除索引
//创建索引
PUT /my_index
{
"settings": {
"number_of_shards": ,
"number_of_replicas":
},
"mappings": {
"my_type": {
"properties": {
"my_field": {
"type": "text"
}
}
}
}
} //修改索引
PUT /my_index/_settings
{
"number_of_replicas":
} //删除索引
DELETE /my_index
DELETE /index_one,index_two
DELETE /index_*
DELETE /_all
2. 默认分词器standard
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
修改分词器设置:
启用english停用词token filter PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
3.内核--type底层数据结构
type,是一个index中用来区分类似的数据的,类似的数据但可能有不同的fields;
field的value,在底层的lucene中建立索引的时候,全部是opaque bytes类型,不区分类型的,因为lucene是没有type的概念的,在document中,实际上将type作为一个document的field来存储,即_type,es通过_type来进行type的过滤和筛选;
一个index中的多个type,实际上是放在一起存储的,因此一个index下,不能有多个type重名,而类型或者其他设置不同的,因为那样是无法处理的;
最佳实践,将类似结构的type放在一个index下,这些type应该有多个field是相同的;
假如说,你将两个type的field完全不同,放在一个index下,那么就每条数据都至少有一半的field在底层的lucene中是空值,会有严重的性能问题;
//底层存储,一个index下所有的field都会存储,对于不同type下的字段若不存在,则置为空;
{
"_type": "elactronic_goods",
"name": "geli kongtiao",
"price": 1999.0,
"service_period": "one year",
"eat_period": ""
} {
"_type": "fresh_goods",
"name": "aozhou dalongxia",
"price": 199.0,
"service_period": "",
"eat_period": "one week"
}
4. 定制dynamic策略和dynamic mapping策略
定制dynamic策略:
true:遇到陌生字段,就进行dynamic mapping;
false:遇到陌生字段,就忽略;
strict:遇到陌生字段,就报错;
dynamic mapping策略:
1)date_detection
默认会按照一定格式识别date,比如yyyy-MM-dd。但是如果某个field先过来一个2017-01-01的值,就会被自动dynamic mapping成date,后面如果再来一个"hello world"之类的值,就会报错。可以手动关闭某个type的date_detection,如果有需要,自己手动指定某个field为date类型。
PUT /my_index/_mapping/my_type
{
"date_detection": false
}
2)定制自己的dynamic mapping template(type level)
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic_templates": [
{ "en": {
"match": "*_en",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"analyzer": "english"
}
}}
]
}}}
PUT /my_index/my_type/
{
"title": "this is my first article"
}
PUT /my_index/my_type/
{
"title_en": "this is my first article"
} title没有匹配到任何的dynamic模板,默认就是standard分词器,不会过滤停用词,is会进入倒排索引,用is来搜索是可以搜索到的
title_en匹配到了dynamic模板,就是english分词器,会过滤停用词,is这种停用词就会被过滤掉,用is来搜索就搜索不到了
3)定制自己的default mapping template(index level)
PUT /my_index
{
"mappings": {
"_default_": {
"_all": { "enabled": false }
},
"blog": {
"_all": { "enabled": true }
}
}
}
5. 重建索引
一个field的设置是不能被修改的,如果要修改一个Field,那么应该重新按照新的mapping,建立一个index,然后将数据批量查询出来,重新用bulk api写入index中;批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来reindex数据,每次scoll就查询指定日期的一段数据,交给一个线程即可;
1)一开始,依靠dynamic mapping,插入数据,但是些数据是2017-01-01这种日期格式的,所以title这种field被自动映射为了date类型,实际上它应该是string类型的;
2)当后期向索引中加入string类型的title值的时候,就会报错;如果此时想修改title的类型,是不可能的;
3)唯一的办法是进行reindex,也就是说,重新建立一个索引,将旧索引的数据查询出来,再导入新索引;
4)如果说旧索引的名字,是old_index,新索引的名字是new_index,终端java应用,已经在使用old_index在操作了,难道还要去停止java应用,修改使用的index为new_index,才重新启动java应用吗?这个过程中,就会导致java应用停机,可用性降低;所以说,给java应用一个别名,这个别名是指向旧索引的,java应用先用着,java应用先用goods_index alias来操作,此时实际指向的是旧的my_index; PUT /my_index/_alias/goods_index
5)新建一个index,调整其title的类型为string;
6)使用scroll api将数据批量查询出来;采用bulk api将scoll查出来的一批数据,批量写入新索引;
POST /_bulk
{ "index": { "_index": "my_index_new", "_type": "my_type", "_id": "" }}
{ "title": "2017-01-02" }
7)反复循环6,查询一批又一批的数据出来,采取bulk api将每一批数据批量写入新索引
8)将goods_index alias切换到my_index_new上去,java应用会直接通过index别名使用新的索引中的数据,java应用程序不需要停机,零提交,高可用;
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index", "alias": "goods_index" }},
{ "add": { "index": "my_index_new", "alias": "goods_index" }}
]
}
9)直接通过goods_index别名来查询,GET /goods_index/my_type/_search
5.2 基于alias对client透明切换index
PUT /my_index_v1/_alias/my_index client对my_index进行操作
reindex操作,完成之后,切换v1到v2
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
6. 倒排索引不可变的好处
(1)不需要锁,提升并发能力,避免锁的问题;
(2)数据不变,一直保存在os cache中,只要cache内存足够;
(3)filter cache一直驻留在内存,因为数据不变;
(4)可以压缩,节省cpu和io开销;
倒排索引不可变的坏处:每次都要重新构建整个索引;
7. document写入的内核级原理
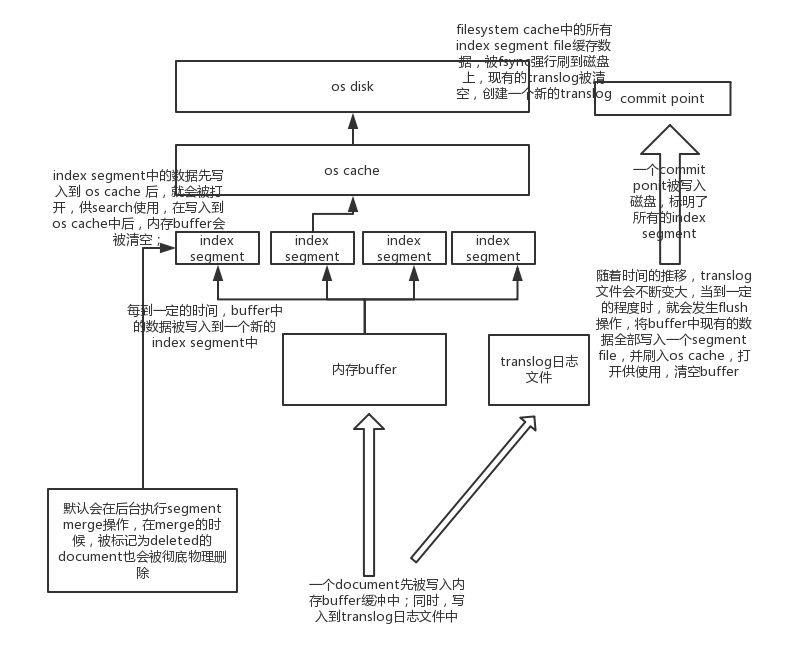
(1)数据写入buffer缓冲和translog日志文件
(2)每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用,不立即执行commit;--实现近实时;
数据写入os cache,并被打开供搜索的过程,叫做refresh,默认是每隔1秒refresh一次。也就是说,每隔一秒就会将buffer中的数据写入一个新的index segment file,先写入os cache中。所以,es是近实时的,数据写入到可以被搜索,默认是1秒。
(3)buffer被清空
(4)重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
(5)当translog长度达到一定程度的时候,commit操作发生
(5-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
(5-2)buffer被清空
(5-3)一个commit ponit被写入磁盘,标明了所有的index segment;会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了;
(5-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
(5-5)现有的translog被清空,创建一个新的translog
//调整刷新的频率
PUT /my_index
{
"settings": {
"refresh_interval": "30s"
}
}
默认会在后台执行segment merge操作,在merge的时候,被标记为deleted的document也会被彻底物理删除;
每次merge操作的执行流程:
(1)选择一些有相似大小的segment,merge成一个大的segment;
(2)将新的segment flush到磁盘上去;
(3)写一个新的commit point,包括了新的segment,并且排除旧的那些segment;
(4)将新的segment打开供搜索;
(5)将旧的segment删除;
POST /my_index/_optimize?max_num_segments=1,尽量不要手动执行,让它自动默认执行;
Elasticsearch 索引管理和内核探秘的更多相关文章
- Elasticsearch -- 索引管理
1.#获取当前索引 # curl -u elastic:changeme 'localhost:9200/_cat/indices?v' 2. #删除指定索引 # curl -XDELETE - ...
- 一文带您了解 Elasticsearch 中,如何进行索引管理(图文教程)
欢迎关注笔者的公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site/ ...
- ElasticSearch权威指南学习(索引管理)
创建索引 当我们需要确保索引被创建在适当数量的分片上,在索引数据之前设置好分析器和类型映射. 手动创建索引,在请求中加入所有设置和类型映射,如下所示: PUT /my_index { "se ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- elasticsearch最全详细使用教程:入门、索引管理、映射详解、索引别名、分词器、文档管理、路由、搜索详解
一.快速入门1. 查看集群的健康状况http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 状 ...
- ElasticSearch——Curator索引管理
简介 curator 是一个官方的,可以管理elasticsearch索引的工具,可以实现创建,删除,段合并等等操作.详见官方文档 功能 curator允许对索引和快照执行许多不同的操作,包括: 从别 ...
- Elasticsearch索引容量管理实践【>>戳文章免费体验Elasticsearch服务30天】
[活动]Elasticsearch Service免费体验馆>> Elasticsearch Service自建迁移特惠政策>>Elasticsearch Service新用户 ...
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
随机推荐
- JAVA基础-面向对象07
一.代码块 1. 含义: 就是使用大括号括起来的一段代码 格式 { 代码: } 2.静态代码块 格式 static{ 代码: } 书写位置: 直接书写在类中成员位置: 怎么执行呢? 在类加载的最后一步 ...
- 更新gitignore
更新: 2017/04/26 修正windows版本下的命令 git rm -r --cached . (Windows 下的版本) 更新: 2017/06/06 mac下的命令也 ...
- 组合数学1.4&3.10 By cellur925
本文引用于清华大学出版社卢开澄.卢华明<组合数学第五版>. 今天我们稍微讨论下圆排列以及$n$对夫妻的问题. 1.4圆周排列 这个问题是:从$n$个人中取$r$个在圆周上,我们用$Q(n, ...
- Failed to convert property value of type 'java.util.LinkedHashMap' to required type 'java.util.Map' for property 'filters'
在使用shiro的自定义filter出现的问题 <property name="filters"> <util:map> <entry key=&qu ...
- CSS3向外扩散的圆
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- 【bzoj2084】[Poi2010]Antisymmetry
2084: [Poi2010]Antisymmetry Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 1205 Solved: 756[Submit ...
- 转--oracle查看允许的最大连接数和当前连接数等信息
两个参数间的关系:sessions=1.1*processes+5 目前总结的语句,在查看数据的连接情况很有用,写完程序一边测试代码一边查看数据库连接的释放情况有助于分析优化出一个健壮的系统程序来. ...
- 万能makefile模板
这里一份万能makefile模板,写opencv项目时候使用的. 前提是提前配置好 包管理工具 pkg 然后就不用每次都去 -lopencv_xxx了. ####################### ...
- 外文翻译 《How we decide》被情感愚弄 第三节
本科论文答辩终于结束啦,一切都要继续回到正轨. 这是第三章章最后一节 书的导言 本章第二节 本章第一节 "信用卡是我的敌人."Herman Palmer这样说到.在平日,Herma ...
- springboot之项目打包
通过win中的cmd或者idea中终端,打包并启动项目: 1.mvn package [打包,在target中生成jar] 2.java -jar xxxxx.jar [启动jar]