STL++?pb_ds平板电视初步探索
什么是pb_ds?
除了众所周知的STL库,c++还自带了ext库(应该可以这么叫吧),其中有用pb_ds命名的名称空间(俗称平板电视)。这个名称空间下有四个数据类型结构。这些都是鲜为人知的。经过测试目前所有的OJ都支持pb_ds库,OI据说也支持。网上资料显示只要是稍微高级一点的linux判卷机都是支持的。这个库的网上资料甚少,百度wiki也没有找到相关的词条,我靠东拼西凑凑出来这么一篇不成形的博客,以后也会继续研究更新
pb_ds包含的数据结构
导言
要想运用pb_ds库有两种方法
①直接使用
#include<bits/extc++.h>
using namespace __gnu_pbds;//两个_在gnu前面
但是可惜的是这个头文件大部分的oj还是不支持的,并且本地的dev也不支持,所以还是不要这么写的好
②按照需求写头文件
#include <bits/stdc++.h>
#include <ext/pb_ds/assco_container.hpp>//这个必须在各个pb_ds的数据结构之前写,不知道为啥
using namespace __gnu_pbds;
①哈希
哈希大家都知道,就是一种映射。但是我们STL中已经有map了,这个还有什么用呢?实际上根据网上资料显示这个hash_table比map要快map是nlogn这个是n。
头文件
#include <ext/pb_ds/hash_policy.hpp>
定义方法有两种
cc_hash_table<int,bool> h;
gp_hash_table<int,bool> h;
根据网上的大佬评测后者速度更快一些。
具体用法跟map相似不在赘述,下面摆一个示例用pb_ds库中的哈希做的a+b且在QLUOJ上通过
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/hash_policy.hpp>
using namespace std;
using namespace __gnu_pbds;
gp_hash_table<long long,long long> mp;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
long long a,b;
cin>>a>>b;
mp[0]=a;
mp[1]=b;
cout<<mp[0]+mp[1];
}
感觉可以是map的上位替换
②堆(优先队列)
基本运用与STL的优先队列没有什么其他的区别,多了堆的合并操作和分离操作
头文件
#include <ext/pb_ds/priority_queue_policy,hpp>//真的长
定义方法
priority_queue<int,greater<int>,TAG> Q;
第一个参数是数据类型
第二个是排序方式
第三个是堆的类型
其中堆的类型有下面几种
pairing_heap_tag
thin_heap_tag
binomial_heap_tag
rc_binomial_heap_tag
binary_heap_tag
其中pairing_heap_tag最快
并且这个东西是带默认参数的,只需要定义一个int也可以
①join函数
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/priority_queue.hpp>
using namespace std;
//using namespace __gnu_pbds;
__gnu_pbds::priority_queue<int> a,b;//注意这个地方为了避免与std的stl发生冲突,所以带上名称空间
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int n,m;
cin>>n>>m;
while(n--)
{
int t1;
cin>>t1;
a.push(t1);
}
while(m--)
{
int t1;
cin>>t1;
b.push(t1);
}
a.join(b);
while(a.size())
{
cout<<a.top()<<" ";
a.pop();
}
}
这样会把两个优先队列合并成一个,b优先队列清空
结果
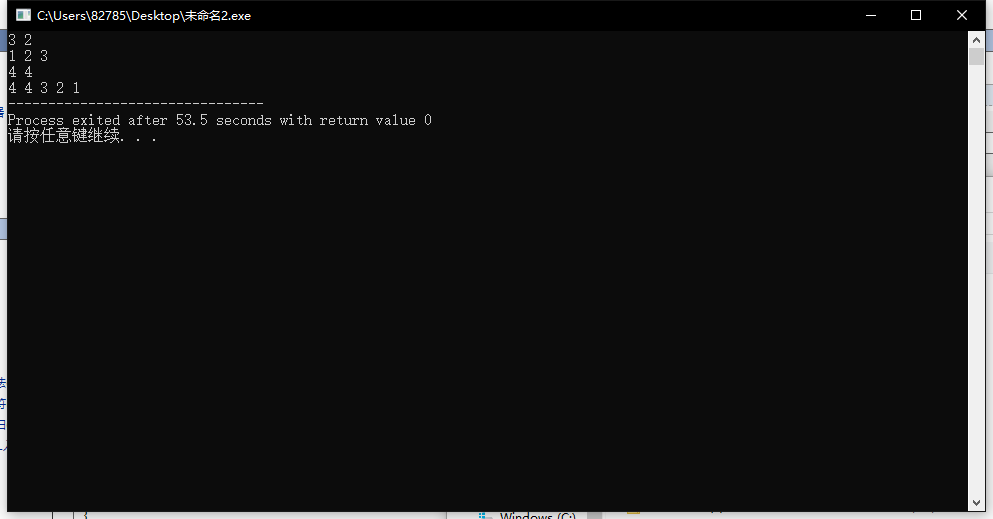
②split函数用法
此处省略,材料过少无法知道split函数的第一个参数的具体意思
③trie字典树
我觉得完全没有什么卵用的东西,只能完成基本的模板操作,而且不知道为啥我试了试还超时,是不是我姿势不对,网上也说没啥用
头文件
#include<ext/pb_ds/trie_policy.hpp>
具体用法(这里复制了洛谷日报第三十九期)
typedef trie<string,null_type,trie_string_access_traits<>,pat_trie_tag,trie_prefix_search_node_update> tr;
//第一个参数必须为字符串类型,tag也有别的tag,但pat最快,与tree相同,node_update支持自定义
tr.insert(s); //插入s
tr.erase(s); //删除s
tr.join(b); //将b并入tr
pair//pair的使用如下:
pair<tr::iterator,tr::iterator> range=base.prefix_range(x);
for(tr::iterator it=range.first;it!=range.second;it++)
cout<<*it<<' '<<endl;
//pair中第一个是起始迭代器,第二个是终止迭代器,遍历过去就可以找到所有字符串了。
遍历一个前缀所包含的单词数(hdu1251 TLE)可能是我的操作问题。。。
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/trie_policy.hpp>
using namespace std;
using namespace __gnu_pbds;
typedef trie<string,null_type,trie_string_access_traits<>,pat_trie_tag,trie_prefix_search_node_update> tr;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
tr base;
string a;
while(getline(cin,a))
{
if(a.size()==0)
break;
else
base.insert(a);
}
string b;
while(getline(cin,b))
{
int sum=0;
auto range=base.prefix_range(b);
for(auto it=range.first;it!=range.second;it++)
sum++;
cout<<sum<<"\n";
}
}
反正trie建议手搓
④平衡树
这个真心的感觉是这里面最牛逼的,所以我放倒了压轴的位置。唯一需要注意的是这个平衡树是set的形状,也就是说他是会自动去重的。。。当然也可以不自动去重,但是目前我还没有研究出来
头文件
#include <ext/pb_ds/tree_policy.hpp>
具体用法
可以理解为是set++
tree<int,null_type,less<int>,rb_tree_tag,tree_order_statistics_node_update> tr;
第一个参数是数据类型
第二个参数是没有映射直接照抄即可
第三个排序方式
第四个是平衡树的类型,这里网上一致认为红黑树最快,好像比手搓的还快?
第五个是自定义节点更新方式(这个可以自定义,但是我目前不会)
//这一部分更改于洛谷日报第39期
tr.insert(x); //插入;
tr.erase(x); //删除;
tr.order_of_key(x); //求排名
tr.find_by_order(x-1); //找k小值,返回迭代器
tr.join(b); //将b并入tr,前提是两棵树类型一样且没有重复元素
tr.split(v,b); //分裂,key小于等于v的元素属于tr,其余的属于b
tr.lower_bound(x); //返回第一个大于等于x的元素的迭代器
tr.upper_bound(x); //返回第一个大于x的元素的迭代器
//以上所有操作的时间复杂度均为O(logn)
完整代码
1.插入x数
2.删除x数(若有多个相同的数,因只删除一个)
3.查询x数的排名(排名定义为比当前数小的数的个数+1。若有多个相同的数,因输出最小的排名)
4.查询排名为x的数
5.求x的前驱(前驱定义为小于x,且最大的数)
6.求x的后继(后继定义为大于x,且最小的数)
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
using namespace std;
using namespace __gnu_pbds;
tree<int,null_type,less<int>,rb_tree_tag,tree_order_statistics_node_update> a;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int n;
cin>>n;
while(n--)
{
int t1,t2;
cin>>t1>>t2;
if(t1==1)
a.insert(t2);
else if(t1==2)
a.erase(t2);
else if(t1==3)
cout<<a.order_of_key(t2)<<"\n";
else if(t1==4)
cout<<*a.find_by_order(t2-1)<<"\n";
else if(t1==5)
cout<<*--a.lower_bound(t2)<<"\n";
else if(t1==6)
cout<<*a.upper_bound(t2)<<"\n";
}
}
STL++?pb_ds平板电视初步探索的更多相关文章
- NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 【转】 NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 企查查app 初步探索
企查查app sign算法破解初步探索 之前有说过企查查的sign的解密,但这次是企查查app的sign算法破解,目前是初步进程. 已删除!!!! 上边一些变量已经找到了,其中就有时间戳,其余两个需要 ...
- Springboot与ActiveMQ、Solr、Redis中分布式事物的初步探索
Springboot与ActiveMQ.Solr.Redis中分布式事物的初步探索 解决的场景:事物中的异步问题,当要求数据库与solr服务器的最终一致时. 程序条件: 利用消息队列,当数据库添加成功 ...
- 侯捷STL学习(八)-- 深度探索deque
layout: post title: 侯捷STL学习(八) date: 2017-07-19 tag: 侯捷STL --- 第十八节 深度探索deque上 duque内存结构 分段连续,用户看起来是 ...
- 侯捷STL学习(七)--深度探索vector&&array
layout: post title: 侯捷STL学习(七) date: 2017-06-13 tag: 侯捷STL --- 第十六节 深度探索vector vector源码剖析 vector内存2倍 ...
- ASP.Net请求处理机制初步探索之旅 - Part 1 前奏
开篇:ASP.Net是一项动态网页开发技术,在历史发展的长河中WebForm曾一时成为了ASP.Net的代名词,而ASP.Net MVC的出现让这项技术更加唤发朝气.但是,不管是ASP.Net Web ...
- ASP.Net请求处理机制初步探索之旅 - Part 2 核心
开篇:上一篇我们了解了一个请求从客户端发出到服务端接收并转到ASP.Net处理入口的过程,这篇我们开始探索ASP.Net的核心处理部分,借助强大的反编译工具,我们会看到几个熟悉又陌生的名词(类):Ht ...
- swiper初步探索
最近要做一个效果,初步想到了使用swiper,不过貌似最后并不能完全通过swiper来实现,整整试了一天的时间都没有试出来,真是...压力很大,不过自己选的路,总要坚持走下去了. Swiper(Swi ...
随机推荐
- Flask的多app应用,多线程如何体现
一.多app应用 在一个py文件中创建多个Flask的app对象 from werkzeug.wsgi import DispatcherMiddleware from werkzeug.servin ...
- bzoj3339
线段树+离线 这种题既可以用莫队做也可以用线段树做,跟hh的项链差不多 首先我们处里出前缀mex,也就是1->i的mex值,再预处理出每个数下一次出现的位置,然后把每个前缀mex插入线段树,每个 ...
- JavaScript代码优化新工具UglifyJS
jQuery 1.5 发布的时候 john resig 大神说所用的代码优化程序从Google Closure切换到UglifyJS,新工具的压缩效果非常令人满意. UglifyJS 是一个服务端no ...
- Same origin policy
Chrome: Origin null is not allowed by Access-Control-Allow-Origin 的问题 发送 http request 时遇到 error: Ori ...
- MyBatis基本应用
框架的概念: 框架(Framework)是一个提供了可重用的公共结构的半成品. 数据持久化: 数据持久化是将内存中的数据模型转换为存储模型,以及将存储模型转换为内存中的数据模型的统称. ORM(Obj ...
- E20171102-E
segment n. 环节; 部分,段落; [计算机] (字符等的) 分段; [动物学] 节片; distinct adj. 明显的,清楚的; 卓越的,不寻常的; 有区别的; 确切的;
- 在sql语句中使用关键字
背景 开发过程中遇到了遇到了一句sql语句一直报错,看了一下字段名和表名都对应上了,但是还是一直报错 sql语句如下: update table set using = ""hh ...
- 洛谷 P1414 又是毕业季II(未完成)
题目背景 “叮铃铃铃”,随着高考最后一科结考铃声的敲响,三年青春时光顿时凝固于此刻.毕业的欣喜怎敌那离别的不舍,憧憬着未来仍毋忘逝去的歌.1000多个日夜的欢笑和泪水,全凝聚在毕业晚会上,相信,这一定 ...
- [C和指针] 6-指针
6.1 内存和地址 我们可以把计算机的内存看作是一条长街上的一排房屋,每座房子都可以容纳数据,并通过一个房号来标识. 这个比喻颇为有用,但也存在局限性.计算机的内存由以亿万计的位(bit)组成,每个位 ...
- C#命名空间 using的用法
using的用法: 1. using指令:引入命名空间 这是最常见的用法,例如: using System; using Namespace1.SubNameSpace; 2. using stati ...