HBase2.0新特性之In-Memory Compaction
In-Memory Compaction是HBase2.0中的重要特性之一,通过在内存中引入LSM结构,减少多余数据,实现降低flush频率和减小写放大的效果。本文根据HBase2.0中相关代码以及社区的讨论、博客,介绍In-Memory Compaction的使用和实现原理。
原理
概念和数据结构
In-Memory Compaction中引入了MemStore的一个新的实现类 CompactingMemStore 。顾名思义,这个类和默认memstore的区别在于实现了在内存中compaction。
CompactingMemStore中,数据以 segment 作为单位进行组织,一个memStore中包含多个segment。数据写入时首先进入一个被称为 active 的segment,这个segment是可修改的。当active满之后,会被移动到 pipeline 中,这个过程称为 in-memory flush 。pipeline中包含多个segment,其中的数据不可修改。CompactingMemStore会在后台将pipeline中的多个segment合并为一个更大、更紧凑的segment,这就是compaction的过程。
如果RegionServer需要把memstore的数据flush到磁盘,会首先选择其他类型的memstore,然后再选择CompactingMemStore。这是因为CompactingMemStore对内存的管理更有效率,所以延长CompactingMemStore的生命周期可以减少总的I/O。当CompactingMemStore被flush到磁盘时,pipeline中的所有segment会被移到一个snapshot中进行合并然后写入HFile。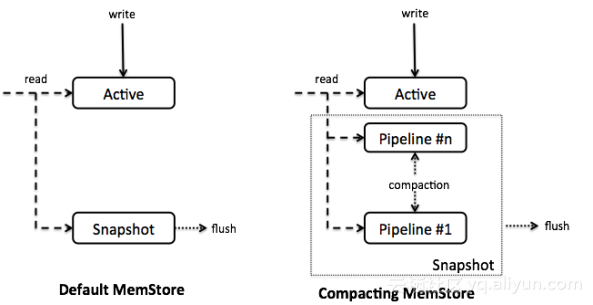
在默认的MemStore中,对cell的索引使用ConcurrentSkipListMap,这种结构支持动态修改,但是其中存在大量小对象,内存浪费比较严重。而在CompactingMemStore中,由于pipeline里面的数据是只读的,就可以使用更紧凑的数据结构来存储索引,减少内存使用。代码中使用CellArrayMap结构来存储cell索引,其内部实现是一个数组。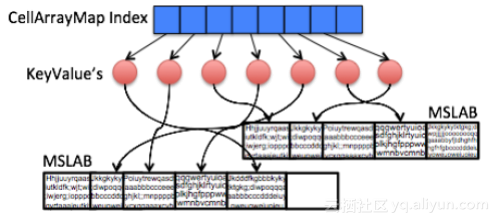
compaction策略
当一个active segment被flush到pipeline中之后,后台会触发一个任务对pipeline中的数据进行合并。合并任务会对pipeline中所有segment进行scan,将他们的索引合并为一个。有三种合并策略可供选择:Basic,Eager,Adaptive。
Basic compaction策略和Eager compaction策略的区别在于如何处理cell数据。Basic compaction不会清理多余的数据版本,这样就不需要对cell的内存进行拷贝。而Eager compaction会过滤重复的数据,并清理多余的版本,这意味着会有额外的开销:例如如果使用了MSLAB存储cell数据,就需要把经过清理之后的cell从旧的MSLAB拷贝到新的MSLAB。basic适用于所有写入模式,eager则主要针对数据大量淘汰的场景:例如消息队列、购物车等。
Adaptive策略则是根据数据的重复情况来决定是否使用Eager策略。在Adaptive策略中,首先会对待合并的segment进行评估,方法是在已经统计过不重复key个数的segment中,找出cell个数最多的一个,然后用这个segment的numUniqueKeys / getCellsCount得到一个比例,如果比例小于设定的阈值,则使用Eager策略,否则使用Basic策略。
使用
配置
2.0中,默认的In-Memory Compaction策略为basic。可以通过修改hbase-site.xml修改:
<property>
<name>hbase.hregion.compacting.memstore.type</name>
<value><none|basic|eager|adaptive></value>
</property>也可以单独设置某个列族的级别:
create ‘<tablename>’,
{NAME => ‘<cfname>’, IN_MEMORY_COMPACTION => ‘<NONE|BASIC|EAGER|ADAPTIVE>’}性能提升
社区的博客中给出了两个不同场景的测试结果。使用YCSB测试工具,100-200 GB数据集。分别在key热度符合Zipf分布和平均分布两种情况下,测试了只有写操作情况下写放大、吞吐、GC相比默认memstore的变化,以及读写各占50%情况下尾部读延时的变化。
测试结果如下表:
| key热度分布 | 写放大 | 吞吐 | GC | 尾部读延时 |
|---|---|---|---|---|
| Zipf | 30%↓ | 20% ↑ | 22% ↓ | 12% ↓ |
| 平均分布 | 25%↓ | 50% ↑ | 36% ↓ | 无变化 |
转自:https://yq.aliyun.com/articles/573702
交流
如果大家对HBase有兴趣,致力于使用HBase解决实际的问题,欢迎加入Hbase技术社区群交流:
微信HBase技术社区群,假如微信群加不了,可以加秘书微信: SH_425 ,然后邀请您。

钉钉HBase技术社区群

HBase2.0新特性之In-Memory Compaction的更多相关文章
- HBase2.0新特性解析
作者 | 个推大数据运维工程师 行者 升级背景 个推作为专业的数据智能服务商,在业务开展过程中存在海量的数据存储与查询的需求,为此个推选用了高可靠.高性能.面向列.可伸缩的分布式数据存储系统--HBa ...
- Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性 Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+ ...
- redis5.0新特性
1. redis5.0新特性 1.1. 新的Stream类型 1.1.1. 什么是Stream数据类型 抽象数据日志 数据流 1.2. 新的Redis模块API:Timers and Cluster ...
- Hadoop3.0新特性
1. Hadoop3.0简介 Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK1.8重新发布一个新的Hadoop版本,而 ...
- Redis4.0新特性
redis 4.0 新特性 Redis 4.0在2017年7月发布为GA.包含几个重大改进:更好的复制(PSYNC2),线程DEL / FLUSH,混合RDB + AOF格式,活动内存碎片整理,内存使 ...
- MySQL 8.0 新特性梳理汇总
一 历史版本发布回顾 从上图可以看出,基本遵循 5+3+3 模式 5---GA发布后,5年 就停止通用常规的更新了(功能不再更新了): 3---企业版的,+3年功能不再更新了: 3 ---完全停止更新 ...
- 浅谈Tuple之C#4.0新特性那些事儿你还记得多少?
来源:微信公众号CodeL 今天给大家分享的内容基于前几天收到的一条留言信息,留言内容是这样的: 看了这位网友的留言相信有不少刚接触开发的童鞋们也会有同样的困惑,除了用新建类作为桥梁之外还有什么好的办 ...
- Java基础和JDK5.0新特性
Java基础 JDK5.0新特性 PS: JDK:Java Development KitsJRE: Java Runtime EvironmentJRE = JVM + ClassLibary JV ...
- Visual Studio 2015速递(1)——C#6.0新特性怎么用
系列文章 Visual Studio 2015速递(1)——C#6.0新特性怎么用 Visual Studio 2015速递(2)——提升效率和质量(VS2015核心竞争力) Visual Studi ...
随机推荐
- MHA的介绍和测试(一)
MHA的介绍 MySQL的MHA:MySQL的高级可用性管理器和工具MHA的主要目标是在短(通常为10-30秒)的停机时间内自动化主故障转移和slave升级,不受复制一致性问题的困扰,不需要花费大量的 ...
- SPOJ GSS2 Can you answer these queries II ——线段树
[题目分析] 线段树,好强! 首先从左往右依次扫描,线段树维护一下f[].f[i]表示从i到当前位置的和的值. 然后询问按照右端点排序,扫到一个位置,就相当于查询区间历史最值. 关于历史最值问题: 标 ...
- cf711E ZS and The Birthday Paradox
ZS the Coder has recently found an interesting concept called the Birthday Paradox. It states that g ...
- uva 11995 判别数据类型
Problem I I Can Guess the Data Structure! There is a bag-like data structure, supporting two operati ...
- msp430项目编程57
msp430综合项目---扩展项目七57 1.电路工作原理 2.代码(显示部分) 3.代码(功能实现) 4.项目总结
- Yii 之数据库查询
模型代码: <?php namespace app\models; use yii\db\ActiveRecord; class Test extends ActiveRecord{ } 控制器 ...
- Redis数据结构之链表
Redis使用的链表是双向无环链表,链表节点可用于保存各种不同类型的值. 一.链表结构定义1. 链表节点结构定义: 2. 链表结构定义: 示例: 二.链表在Redis中的用途1. 作为列表键的底层实现 ...
- spring--路由
@RestController: Spring4之后新加入的注解,原来返回json需要@ResponseBody和@Controller配合. 即@RestController是@ResponseBo ...
- 有关 GCC 及 JNA 涉及动态库/共享库时处理库文件名的问题
动态库尤其是共享库在 Linux 环境下普遍存在库文件名包含版本号的情况,比如 Linux 环境下经常会发现一个共享库的真实文件名是 libfoo.so.1.1.0,而同时会有多个指向该真实库文件的软 ...
- 如何快速的知道Maven插件的命令行输入参数
用命令行使用Maven的插件时,-D表示属性的输入,-P表示构建配置文件的输入. 比如要使用package生命周期阶段对Application项目进行打包jar时,查找方式如下: 1.由于packag ...