HTTP协议漫谈 C#实现图(Graph) C#实现二叉查找树 浅谈进程同步和互斥的概念 C#实现平衡多路查找树(B树)
HTTP协议漫谈
简介
园子里已经有不少介绍HTTP的的好文章。对HTTP的一些细节介绍的比较好,所以本篇文章不会对HTTP的细节进行深究,而是从够高和更结构化的角度将HTTP协议的元素进行分类讲解。
HTTP的定义和历史
在一个网络中。传输数据需要面临三个问题:
1.客户端如何知道所求内容的位置?
2.当客户端知道所求内容的位置后,如何获取所求内容?
3.所求内容以何种形式组织以便被客户端所识别?
对于WEB来说,回答上面三种问题分别采用三种不同的技术,分别为:统一资源定位符(URIs),超文本传输协议(HTTP)和超文本标记语言(HTML)。对于大多数WEB开发人员来说URI和HTML都是非常的熟悉。而HTTP协议在很多WEB技术中都被封装的过多使得HTTP反而最不被熟悉。
HTTP作为一种传输协议,也是像HTML一样随着时间不断演进的,目前流行的HTTP1.1是HTTP协议的第三个版本。
HTTP 0.9
HTTP 0.9作为HTTP协议的第一个版本。是非常弱的。请求(Request)只有一行,比如:
GET www.cnblogs.com
从如此简单的请求体,没有POST方法,没有HTTP 头可以看出,那个时代的HTTP客户端只能接收一种类型:纯文本。并且,如果得不到所求的信息,也没有404 500等错误出现。
虽然HTTP 0.9看起来如此弱,但已经能满足那个时代的需求了。
HTTP 1.0
随着1996年后,WEB程序的需求,HTTP 0.9已经不能满足需求。HTTP1.0最大的改变是引入了POST方法,使得客户端通过HTML表单向服务器发送数据成为可能,这也是WEB应用程序的一个基础。另一个巨大的改变是引入了HTTP头,使得HTTP不仅能返回错误代码,并且HTTP协议所传输的内容不仅限于纯文本,还可以是图片,动画等一系列格式。
除此之外,还允许保持连接,既一次TCP连接后,可以多次通信,虽然HTTP1.0 默认是传输一次数据后就关闭。
HTTP 1.1
2000年5月,HTTP1.1确立。HTTP1.1并不像HTTP1.0对于HTTP0.9那样的革命性。但是也有很多增强。
首先,增加了Host头,比如访问我的博客:
GET /Careyson HTTP/1.1 Host: www.cnblogs.com
Get后面仅仅需要相对路径即可。这看起来虽然仅仅类似语法糖的感觉,但实际上,这个提升使得在Web上的一台主机可以存在多个域。否则多个域名指向同一个IP会产生混淆。
此外,还引入了Range头,使得客户端通过HTTP下载时只下载内容的一部分,这使得多线程下载也成为可能。
还有值得一提的是HTTP1.1 默认连接是一直保持的,这个概念我会在下文中具体阐述。
HTTP的网络层次
在Internet中所有的传输都是通过TCP/IP进行的。HTTP协议作为TCP/IP模型中应用层的协议也不例外。HTTP在网络中的层次如图1所示。

图1.HTTP在TCP/IP中的层次
可以看出,HTTP是基于传输层的TCP协议,而TCP是一个端到端的面向连接的协议。所谓的端到端可以理解为进程到进程之间的通信。所以HTTP在开始传输之前,首先需要建立TCP连接,而TCP连接的过程需要所谓的“三次握手”。概念如图2所示。

图2.TCP连接的三次握手
在TCP三次握手之后,建立了TCP连接,此时HTTP就可以进行传输了。一个重要的概念是面向连接,既HTTP在传输完成之间并不断开TCP连接。在HTTP1.1中(通过Connection头设置)这是默认行为。所谓的HTTP传输完成我们通过一个具体的例子来看。
比如访问我的博客,使用Fiddler来截取对应的请求和响应。如图3所示。
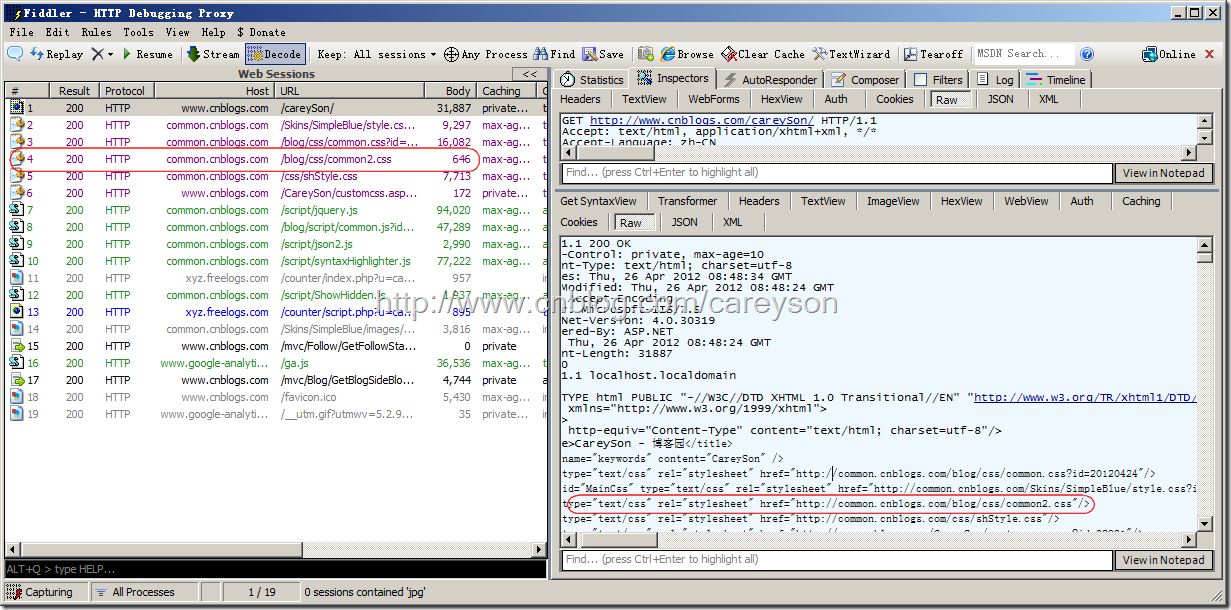
图3.用fiddler抓取请求和相应
可以看出,虽然仅仅访问了我的博客,但锁获取的不仅仅是一个HTML而已,而是浏览器对HTML解析的过程中,如果发现需要获取的内容,会再次发起HTTP请求去服务器获取,比如图2中的那个common2.css。这上面19个HTTP请求,只依靠一个TCP连接就够了,这就是所谓的持久连接。也是所谓的一次HTTP请求完成。
HTTP请求(HTTP Request)
所谓的HTTP请求,也就是Web客户端向Web服务器发送信息,这个信息由如下三部分组成:
1.请求行
2.HTTP头
3.内容
一个典型的请求行比如:
GET www.cnblogs.com HTTP/1.1
请求行写法是固定的,由三部分组成,第一部分是请求方法,第二部分是请求网址,第三部分是HTTP版本。
第二部分HTTP头在HTTP请求可以是3种HTTP头:1.请求头(request header) 2.普通头(general header) 3.实体头(entity header)
通常来说,由于Get请求往往不包含内容实体,因此也不会有实体头。
第三部分内容只在POST请求中存在,因为GET请求并不包含任何实体。
我们截取一个具体的Post请求来看这三部分,我在一个普通的aspx页面放一个BUTTON,当提交后会产生一个Post请求,如图4所示。

图4.HTTP请求由三部分组成
HTTP请求方法
虽然我们所常见的只有Get和Post方法,但实际上HTTP请求方法还有很多,比如: PUT方法,DELETE方法,HEAD方法,CONNECT方法,TRACE方法。这里我就不细说了,自行Bing。
这里重点说一下Get和Post方法,网上关于Get和Post的区别满天飞。但很多没有说到点子上。Get和Post最大的区别就是Post有上面所说的第三部分:内容。而Get不存在这个内容。因此就像Get和Post其名称所示那样,Get用于从服务器上取内容,虽然可以通过QueryString向服务器发信息,但这违背了Get的本意,QueryString中的信息在HTTP看来仅仅是获取所取得内容的一个参数而已。而Post是由客户端向服务器端发送内容的方式。因此具有请求的第三部分:内容。
HTTP响应(HTTP Response)
当Web服务器收到HTTP请求后,会根据请求的信息做某些处理(这些处理可能仅仅是静态的返回页,或是包含Asp.net,PHP,Jsp等语言进行处理后返回),相应的返回一个HTTP响应。HTTP响应在结构上很类似于HTTP请求,也是由三部分组成,分别为:
1.状态行
2.HTTP头
3.返回内容
首先来看状态行,一个典型的HTTP状态如下:
HTTP/1.1 200 OK
第一部分是HTTP版本,第二部分是响应状态码,第三部分是状态码的描述,因此也可以把第二和第三部分看成一个部分。
对于HTTP版本没有什么好说的,而状态码值得说一下,网上对于每个具体的HTTP状态码所代表的含义都有解释,这里我说一下分类。
信息类 (100-199)
响应成功 (200-299)
重定向类 (300-399)
客户端错误类 (400-499)
服务端错误类 (500-599)
HTTP响应中包含的头包括1.响应头(response header) 2.普通头(general header) 3.实体头(entity header)。
第三部分HTTP响应内容就是HTTP请求所请求的信息。这个信息可以是一个HTML,也可以是一个图片。比如我访问百度,HTTP Response如图5所示。

图5.一个典型的HTTP响应
图5中的响应是一个HTML,当然还可以是其它类型,比如图片,如图6所示。

图6.HTTP响应内容是图片
这里会有一个疑问,既然HTTP响应的内容不仅仅是HTML,还可以是其它类型,那么浏览器如何正确对接收到的信息进行处理?
这是通过媒体类型确定的(Media Type),具体来说对应Content-Type这个HTTP头,比如图5中是text/html,图6是image/jpeg。
媒体类型的格式为:大类/小类 比如图5中的html是小类,而text是大类。
IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)定义了8个大类的媒体类型,分别是:
application— (比如: application/vnd.ms-excel.)
audio (比如: audio/mpeg.)
image (比如: image/png.)
message (比如,:message/http.)
model(比如:model/vrml.)
multipart (比如:multipart/form-data.)
text(比如:text/html.)
video(比如:video/quicktime.)
HTTP头
HTTP头仅仅是一个标签而已,比如我在Aspx中加入代码:
Response.AddHeader("测试头","测试值");
对应的我们可以在fiddler抓到的信息如图7所示。

图7.HTTP头
不难看出,HTTP头并不是严格要求的,仅仅是一个标签,如果浏览器可以解析就会按照某些标准(比如浏览器自身标准,W3C的标准)去解释这个头,否则不识别的头就会被浏览器无视。对服务器也是同理。假如你编写一个浏览器,你可以将上面的头解释成任何你想要的效果
下面我们说的HTTP头都是W3C标准的头,我不会对每个头的作用进行详细说明,关于HTTP头作用的文章在网上已经很多了,请自行Bing。HTTP头按照其不同的作用,可以分为四大类。
通用头(General header)
通用头即可以包含在HTTP请求中,也可以包含在HTTP响应中。通用头的作用是描述HTTP协议本身。比如描述HTTP是否持久连接的Connection头,HTTP发送日期的Date头,描述HTTP所在TCP连接时间的Keep-Alive头,用于缓存控制的Cache-Control头等。
实体头(Entity header)
实体头是那些描述HTTP信息的头。既可以出现在HTTP POST方法的请求中,也可以出现在HTTP响应中。比如图5和图6中的Content-Type和Content-length都是描述实体的类型和大小的头都属于实体头。其它还有用于描述实体的Content-Language,Content-MD5,Content-Encoding以及控制实体缓存的Expires和Last-Modifies头等。
请求头(HTTP Request Header)
请求头是那些由客户端发往服务端以便帮助服务端更好的满足客户端请求的头。请求头只能出现在HTTP请求中。比如告诉服务器只接收某种响应内容的Accept头,发送Cookies的Cookie头,显示请求主机域的HOST头,用于缓存的If-Match,If-Match-Since,If-None-Match头,用于只取HTTP响应信息中部分信息的Range头,用于附属HTML相关请求引用的Referer头等。
响应头(HTTP Response Header)
HTTP响应头是那些描述HTTP响应本身的头,这里面并不包含描述HTTP响应中第三部分也就是HTTP信息的头(这部分由实体头负责)。比如说定时刷新的Refresh头,当遇到503错误时自动重试的Retry-After头,显示服务器信息的Server头,设置COOKIE的Set-Cookie头,告诉客户端可以部分请求的Accept-Ranges头等。
状态保持
还有一点值得注意的是,HTTP协议是无状态的,这意味着对于接收HTTP请求的服务器来说,并不知道每一次请求来自同一个客户端还是不同客户端,每一次请求对于服务器来说都是一样的。因此需要一些额外的手段来使得服务器在接收某个请求时知道这个请求来自于某个客户端。如图8所示。

图8.服务器并不知道请求1和请求2来自同一个客户端
通过Cookies保持状态
为了解决这个问题,HTTP协议通过Cookies来保持状态,对于图8中的请求,如果使用Cookies进行状态控制,则变成了如图9所示。

图9.通过Cookies,服务器就可以清楚的知道请求2和请求1来自同一个客户端
通过表单变量保持状态
除了Cookies之外,还可以使用表单变量来保持状态,比如Asp.net就通过一个叫ViewState的Input=“hidden”的框来保持状态,比如:
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUKMjA0OTM4MTAwNGRkXUfhlDv1Cs7/qhBlyZROCzlvf5U=" />
这个原理和Cookies大同小异,只是每次请求和响应所附带的信息变成了表单变量。
通过QueryString保持状态
这个原理和上述两种状态保持方法原理是一样的,QueryString通过将信息保存在所请求地址的末尾来向服务器传送信息,通常和表单结合使用,一个典型的QueryString比如:
总结
本文从一个比较高的视角来看HTTP协议,对于HTTP协议中的细节并没有深挖,但对于HTTP大框架有了比较系统的介绍,更多关于HTTP的细节信息,请去Bing或参看相关书籍:-)
C#实现图(Graph)
简介
图表示点之间的关系,在C#中通过节点对象的集合来表示点(Vertex),用邻接矩阵(adjacency matrix)来表示点之间的关系。下面来看C#实现。
PS:本片文章是我复习的笔记,代码注释很全。勿吐槽。
表示点的对象
下面实现代码:
class Vertex
{
public string Data;
public bool IsVisited;
public Vertex(string Vertexdata)
{
Data = Vertexdata;
}
}
每个节点包含两个字段,分别为节点数据以及表示是否被访问过的一个布尔类型。
表示图的对象
图中除了需要点的集合和邻接矩阵之外,还需要一些基本的向图中添加或删除元素的方法,以及一个构造方法来对图进行初始化。
public class Graph
{
//图中所能包含的点上限
private const int Number = 10;
//顶点数组
private Vertex[] vertiexes;
//邻接矩阵
public int[,] adjmatrix;
//统计当前图中有几个点
int numVerts = 0;
//初始化图
public Graph()
{
//初始化邻接矩阵和顶点数组
adjmatrix = new Int32[Number, Number];
vertiexes = new Vertex[Number];
//将代表邻接矩阵的表全初始化为0
for (int i = 0; i < Number; i++)
{
for (int j = 0; j < Number; j++)
{
adjmatrix[i, j] = 0;
}
}
}
//向图中添加节点
public void AddVertex(String v)
{
vertiexes[numVerts] = new Vertex(v);
numVerts++;
}
//向图中添加有向边
public void AddEdge(int vertex1, int vertex2)
{
adjmatrix[vertex1, vertex2] = 1;
//adjmatrix[vertex2, vertex1] = 1;
}
//显示点
public void DisplayVert(int vertexPosition)
{
Console.WriteLine(vertiexes[vertexPosition]+" ");
}
}
拓扑排序(TopSort)
拓扑排序是对一个有向的,并且不是环路的图中所有的顶点线性化。需要如下几个步骤
1.首先找到没有后继的节点。
2.将这个节点加入线性栈中
3.在图中删除这个节点
4.重复步骤1,2,3
因此,首先需要找到后继节点的方法:
//寻找图中没有后继节点的点
//具体表现为邻接矩阵中某一列全为0
//此时返回行号,如果找不到返回-1
private int FindNoSuccessor()
{
bool isEdge;
//循环行
for (int i = 0; i < numVerts; i++)
{
isEdge = false;
//循环列,有一个1就跳出循环
for (int j = 0; j < numVerts; j++)
{
if (adjmatrix[i, j] == 1)
{
isEdge = true;
break;
}
}
if (!isEdge)
{
return i;
}
}
return -1;
}
此外还需要删除图中点的方法,这个方法不仅需要删除图中对应位置的点,还需要删除邻接矩阵对应的行和列,因此设置了两个辅助方法,见代码。
//删除图中的点
//需要两个操作,分别从数组中删除点
//从邻接矩阵中消去被删点的行和列
private void DelVertex(int vert)
{
//保证不越界
if (vert <= numVerts - 1)
{
//删除节点
for (int i = vert; i < numVerts; i++)
{
vertiexes[i] = vertiexes[i + 1];
}
//删除邻接矩阵的行
for (int j = vert; j < numVerts; j++)
{
MoveRow(j, numVerts);
}
//删除邻接矩阵中的列,因为已经删了行,所以少一列
for (int k = vert; k < numVerts - 1;k++ )
{
MoveCol(k, numVerts-1);
}
//删除后减少一个
numVerts--;
}
}
//辅助方法,移动邻接矩阵中的行
private void MoveRow(int row, int length)
{
for (int col = row; col < numVerts; col++)
{
adjmatrix[row, col] = adjmatrix[row + 1, col];
}
}
//辅助方法,移动邻接矩阵中的列
private void MoveCol(int col, int length)
{
for (int row = col; row < numVerts; row++)
{
adjmatrix[row, col] = adjmatrix[row, col+1];
}
}
有了这几个方法,就可以按照步骤开始拓扑排序了:
//拓扑排序
//找到没有后继节点的节点,删除,加入一个栈,然后输出
public void TopSort()
{
int origVerts = numVerts;
//存放返回节点的栈
System.Collections.Stack result = new Stack();
while (numVerts > 0)
{
//找到第一个没有后继节点的节点
int currVertex = FindNoSuccessor();
if (currVertex == -1)
{
Console.WriteLine("图为环路图,不能搞拓扑排序");
return;
}
//如果找到,将其加入返回结果栈
result.Push(vertiexes[currVertex].Data);
//然后删除此节点
DelVertex(currVertex);
}
/*输出排序后的结果*/
Console.Write("拓扑排序的顺序为:");
while (result.Count > 0)
{
Console.Write(result.Pop()+" ");
}
/*输出排序后的结果*/
}
下面,对拓扑排序进行测试,代码如下:
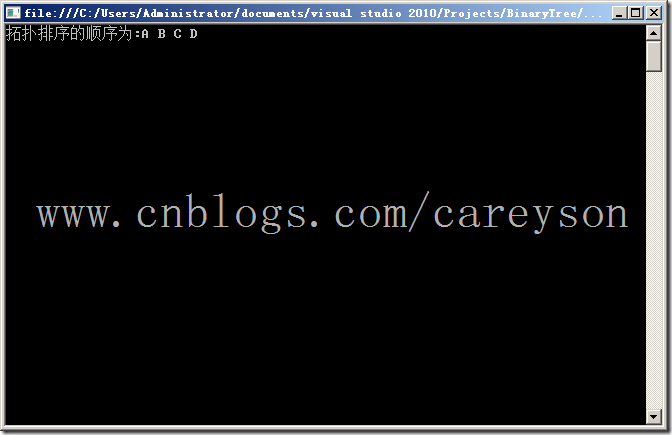
static void Main(string[] args)
{
Graph g = new Graph();
g.AddVertex("A");
g.AddVertex("B");
g.AddVertex("C");
g.AddVertex("D");
g.AddEdge(0, 1);
g.AddEdge(1, 2);
g.AddEdge(2, 3);
g.AddEdge(3, 4);
g.TopSort();
Console.ReadKey();
}
测试结果:
图的遍历
很多时候,我们需要知道从图中给定点到另一个点是否能走通,比如几个车站之间是否可以连接。这时我们需要对图进行查找,查找大概可以分为两类,深度优先遍历和广度优先遍历,下面先来看深度优先遍历。
深度优先遍历(Depth-First Search)
深度优先遍历首先从一个点开始,到一条路径结束,然后循环找第二条路径,到结束,依此往复。
首先我们需要一个辅助方法返回给定的点最近一个连接并且未被访问过的序号。
//从邻接矩阵查找给定点第一个相邻且未被访问过的点
//参数v是给定点在邻接矩阵的行
private int GetAdjUnvisitedVertex(int v)
{
for (int j = 0; j < numVerts; j++)
{
if (adjmatrix[v,j]==1 && vertiexes[j].IsVisited == false)
{
return j;
}
}
return -1;
}
下面,就可以进行深度优先遍历了:
//深度优先遍历
public void DepthFirstSearch()
{
//声明一个存储临时结果的栈
System.Collections.Stack s = new Stack();
//先访问第一个节点
vertiexes[0].IsVisited = true;
DisplayVert(0);
s.Push(0);
int v;
while (s.Count > 0)
{
//获得和当前节点连接的未访问过节点的序号
v = GetAdjUnvisitedVertex((int)s.Peek());
if (v == -1)
{
s.Pop();
}
else
{
//标记为已经被访问过
vertiexes[v].IsVisited = true;
DisplayVert(v);
s.Push(v);
}
}
//重置所有节点为未访问过
for (int u = 0; u < numVerts; u++)
{
vertiexes[u].IsVisited = false;
}
}
广度优先遍历(Breadth-First Search)
广度优先遍历首先遍历层级。算法如下:
//广度优先遍历
public void BreadthFirstSearch()
{
System.Collections.Queue q = new Queue();
/*首先访问第一个节点*/
vertiexes[0].IsVisited = true;
DisplayVert(0);
q.Enqueue(0);
/*第一个节点访问结束*/
int vert1, vert2;
while (q.Count > 0)
{
/*首先访问同层级第一个节点*/
vert1 = (int)q.Dequeue();
vert2 = GetAdjUnvisitedVertex(vert1);
/*结束*/
while (vert2 != -1)
{
/*首先访问第二个节点*/
vertiexes[vert2].IsVisited = true;
DisplayVert(vert2);
q.Enqueue(vert2);
//寻找邻接的
vert2 = GetAdjUnvisitedVertex(vert1);
}
}
//重置所有节点为未访问过
for (int u = 0; u < numVerts; u++)
{
vertiexes[u].IsVisited = false;
}
}
下面我们来测试深度优先和广度优先遍历:
我们的测试生成一个如下的图:
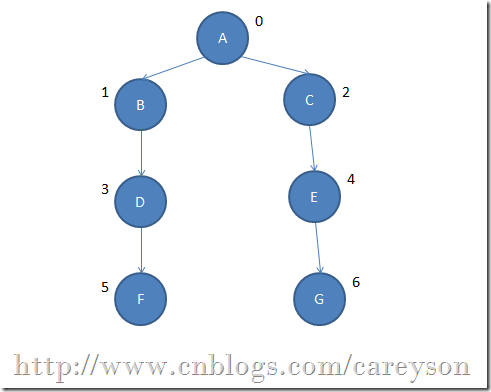
测试代码:
static void Main(string[] args)
{
Graph g = new Graph();
g.AddVertex("A");
g.AddVertex("B");
g.AddVertex("C");
g.AddVertex("D");
g.AddVertex("E");
g.AddVertex("F");
g.AddVertex("G");
g.AddEdge(0, 1);
g.AddEdge(0, 2);
g.AddEdge(1, 3);
g.AddEdge(2, 4);
g.AddEdge(3, 5);
g.AddEdge(4, 6);
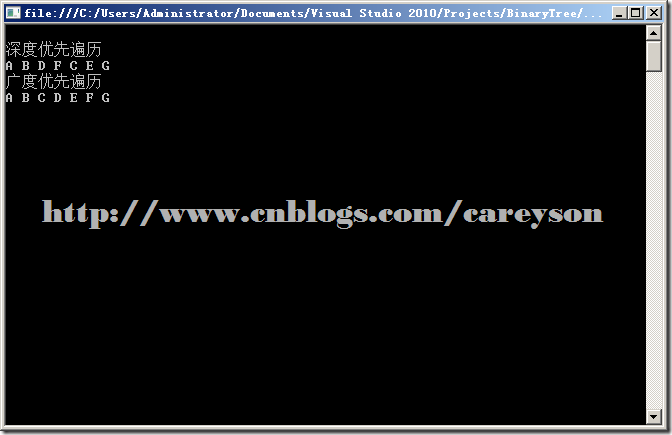
Console.WriteLine("\n深度优先遍历");
g.DepthFirstSearch();
Console.WriteLine("\n广度优先遍历");
g.BreadthFirstSearch();
Console.ReadKey();
}
运行结果:
C#实现二叉查找树
简介
树是一种非线性结构。树的本质是将一些节点由边连接起来,形成层级的结构。而二叉树是一种特殊的树,使得树每个子节点必须小于等于2.而二叉查找树又是一类特殊的二叉树。使得每一个节点的左节点或左子树的所有节点必须小于这个节点,右节点必须大于这个节点。从而方便高效搜索。
下面来看如何使用C#实现二叉查找树。
实现节点
二叉查找树是节点的集合。因此首先要构建节点,如代码1所示。
//二叉查找树的节点定义
public class Node
{
//节点本身的数据
public int data;
//左孩子
public Node left;
//右孩子
public Node right;
public void DisplayData()
{
Console.Write(data+" ");
}
}
代码1.节点的定义
构建二叉树
构建二叉树是通过向二叉树插入元素得以实现的,所有小于根节点的节点插入根节点的左子树,大于根节点的,插入右子树。依此类推进行递归。直到找到位置进行插入。二叉查找树的构建过程其实就是节点的插入过程。C#实现代码如代码2所示。
public void Insert(int data)
{
Node Parent;
//将所需插入的数据包装进节点
Node newNode=new Node();
newNode.data=data;
//如果为空树,则插入根节点
if(rootNode==null)
{
rootNode=newNode;
}
//否则找到合适叶子节点位置插入
else
{
Node Current = rootNode;
while(true)
{
Parent=Current;
if(newNode.data<Current.data)
{
Current=Current.left;
if(Current==null)
{
Parent.left=newNode;
//插入叶子后跳出循环
break;
}
}
else
{
Current = Current.right;
if (Current == null)
{
Parent.right = newNode;
//插入叶子后跳出循环
break;
}
}
}
}
}
代码2.实现二叉树的插入
二叉树的遍历
二叉树的遍历分为先序(PreOrder),中序(InOrder)和后序(PostOrder)。先序首先遍历根节点,然后是左子树,然后是右子树。中序首先遍历左子树,然后是根节点,最后是右子树。而后续首先遍历左子树,然后是右子树,最后是根节点。因此,我们可以通过C#递归来实现这三种遍历,如代码3所示。
//中序
public void InOrder(Node theRoot)
{
if (theRoot != null)
{
InOrder(theRoot.left);
theRoot.DisplayData();
InOrder(theRoot.right);
}
}
//先序
public void PreOrder(Node theRoot)
{
if (theRoot != null)
{
theRoot.DisplayData();
PreOrder(theRoot.left);
PreOrder(theRoot.right);
}
}
//后序
public void PostOrder(Node theRoot)
{
if (theRoot != null)
{
PostOrder(theRoot.left);
PostOrder(theRoot.right);
theRoot.DisplayData();
}
}
代码3.实现二叉排序树的先序,中序和后续遍历
找到二叉查找树中的最大值和最小值
二叉查找树因为已经有序,所以查找最大值和最小值非常简单,找最小值只需要找最左边的叶子节点即可。而找最大值也仅需要找最右边的叶子节点,如代码4所示。
//找到最大节点
public void FindMax()
{
Node current = rootNode;
//找到最右边的节点即可
while (current.right != null)
{
current = current.right;
}
Console.WriteLine("\n最大节点为:" + current.data);
}
//找到最小节点
public void FindMin()
{
Node current = rootNode;
//找到最左边的节点即可
while (current.left != null)
{
current = current.left;
}
Console.WriteLine("\n最小节点为:" + current.data);
}
代码4.二叉查找树找最小和最大节点
二叉查找树的查找
因为二叉查找树已经有序,所以查找时只需要从根节点开始比较,如果小于根节点,则查左子树,如果大于根节点,则查右子树。如此递归,如代码5所示。
//查找
public Node Search(int i)
{
Node current = rootNode;
while (true)
{
if (i < current.data)
{
if (current.left == null)
break;
current = current.left;
}
else if (i > current.data)
{
if (current == null)
break;
current = current.right;
}
else
{
return current;
}
}
if (current.data != i)
{
return null;
}
return current;
}
代码5.二叉查找树的查找
二叉树的删除
二叉树的删除是最麻烦的,需要考虑四种情况:
- 被删节点是叶子节点
- 被删节点有左孩子没右孩子
- 被删节点有右孩子没左孩子
- 被删节点有两个孩子
我们首先需要找到被删除的节点和其父节点,然后根据上述四种情况分别处理。如果遇到被删除元素是根节点时,还需要特殊处理。如代码6所示。
//删除二叉查找树中的节点,最麻烦的操作
public Node Delete(int key)
{
Node parent = rootNode;
Node current = rootNode;
//首先找到需要被删除的节点&其父节点
while (true)
{
if (key < current.data)
{
if (current.left == null)
break;
parent = current;
current = current.left;
}
else if (key > current.data)
{
if (current == null)
break;
parent = current;
current = current.right;
}
//找到被删除节点,跳出循环
else
{
break;
}
}
//找到被删除节点后,分四种情况进行处理
//情况一,所删节点是叶子节点时,直接删除即可
if (current.left == null && current.right == null)
{
//如果被删节点是根节点,且没有左右孩子
if (current == rootNode&&rootNode.left==null&&rootNode.right==null)
{
rootNode = null;
}
else if (current.data < parent.data)
parent.left = null;
else
parent.right = null;
}
//情况二,所删节点只有左孩子节点时
else if(current.left!=null&¤t.right==null)
{
if (current.data < parent.data)
parent.left = current.left;
else
parent.right = current.left;
}
//情况三,所删节点只有右孩子节点时
else if (current.left == null && current.right != null)
{
if (current.data < parent.data)
parent.left = current.right;
else
parent.right = current.right;
}
//情况四,所删节点有左右两个孩子
else
{
//current是被删的节点,temp是被删左子树最右边的节点
Node temp;
//先判断是父节点的左孩子还是右孩子
if (current.data < parent.data)
{
parent.left = current.left;
temp = current.left;
//寻找被删除节点最深的右孩子
while (temp.right != null)
{
temp = temp.right;
}
temp.right = current.right;
}
//右孩子
else if (current.data > parent.data)
{
parent.right = current.left;
temp = current.left;
//寻找被删除节点最深的左孩子
while (temp.left != null)
{
temp = temp.left;
}
temp.right = current.right;
}
//当被删节点是根节点,并且有两个孩子时
else
{
temp = current.left;
while (temp.right != null)
{
temp = temp.right;
}
temp.right = rootNode.right;
rootNode = current.left;
}
}
return current;
}
代码6.二叉查找树的删除
测试二叉查找树
现在我们已经完成了二叉查找树所需的各个功能,下面我们来对代码进行测试:
BinarySearchTree b = new BinarySearchTree();
/*插入节点*/
b.Insert(5);
b.Insert(7);
b.Insert(1);
b.Insert(12);
b.Insert(32);
b.Insert(15);
b.Insert(22);
b.Insert(2);
b.Insert(6);
b.Insert(24);
b.Insert(17);
b.Insert(14);
/*插入结束 */
/*对二叉查找树分别进行中序,先序,后序遍历*/
Console.Write("\n中序遍历为:");
b.InOrder(b.rootNode);
Console.Write("\n先序遍历为:");
b.PreOrder(b.rootNode);
Console.Write("\n后序遍历为:");
b.PostOrder(b.rootNode);
Console.WriteLine(" ");
/*遍历结束*/
/*查最大值和最小值*/
b.FindMax();
b.FindMin();
/*查找结束*/
/*搜索节点*/
Node x = b.Search(15);
Console.WriteLine("\n所查找的节点为" + x.data);
/*搜索结束*/
/*测试删除*/
b.Delete(24);
Console.Write("\n删除节点后先序遍历的结果是:");
b.InOrder(b.rootNode);
b.Delete(5);
Console.Write("\n删除根节点后先序遍历的结果是:");
b.InOrder(b.rootNode);
Console.ReadKey();
/*删除结束*/
代码7.测试二叉查找树
运行结果如图1所示:
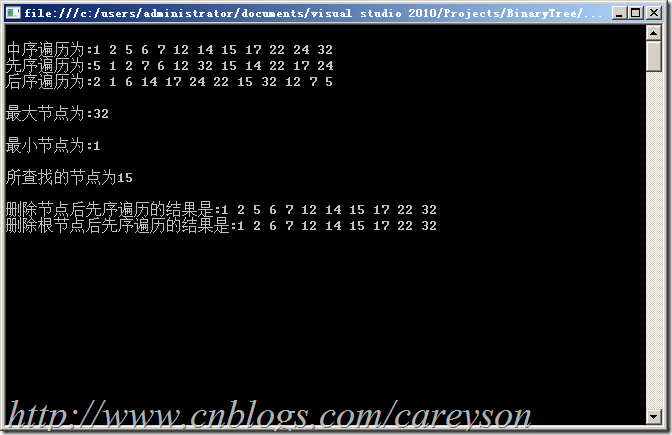
图1.测试运行结果
总结
树是节点的层级集合,而二叉树又是将每个节点的孩子限制为小于等于2的特殊树,二叉查找树又是一种特殊的二叉树。二叉树对于查找来说是非常高效,尤其是查找最大值和最小值。
浅谈进程同步和互斥的概念
简介
进程同步是一个操作系统级别的概念,是在多道程序的环境下,存在着不同的制约关系,为了协调这种互相制约的关系,实现资源共享和进程协作,从而避免进程之间的冲突,引入了进程同步。
临界资源
在操作系统中,进程是占有资源的最小单位(线程可以访问其所在进程内的所有资源,但线程本身并不占有资源或仅仅占有一点必须资源)。但对于某些资源来说,其在同一时间只能被一个进程所占用。这些一次只能被一个进程所占用的资源就是所谓的临界资源。典型的临界资源比如物理上的打印机,或是存在硬盘或内存中被多个进程所共享的一些变量和数据等(如果这类资源不被看成临界资源加以保护,那么很有可能造成丢数据的问题)。
对于临界资源的访问,必须是互诉进行。也就是当临界资源被占用时,另一个申请临界资源的进程会被阻塞,直到其所申请的临界资源被释放。而进程内访问临界资源的代码被成为临界区。
对于临界区的访问过程分为四个部分:
1.进入区:查看临界区是否可访问,如果可以访问,则转到步骤二,否则进程会被阻塞
2.临界区:在临界区做操作
3.退出区:清除临界区被占用的标志
4.剩余区:进程与临界区不相关部分的代码
进程间同步和互诉的概念
进程同步
进程同步也是进程之间直接的制约关系,是为完成某种任务而建立的两个或多个线程,这个线程需要在某些位置上协调他们的工作次序而等待、传递信息所产生的制约关系。进程间的直接制约关系来源于他们之间的合作。
比如说进程A需要从缓冲区读取进程B产生的信息,当缓冲区为空时,进程B因为读取不到信息而被阻塞。而当进程A产生信息放入缓冲区时,进程B才会被唤醒。概念如图1所示。
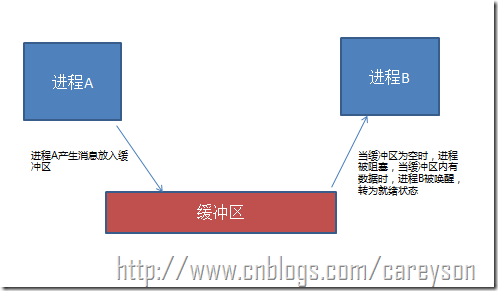
图1.进程之间的同步
用C#代码模拟进程之间的同步如代码1所示。
class ProcessSyn
{
private static Mutex mut = new Mutex();
static void Main()
{
Console.WriteLine("进程1执行完了进程2才能执行.......");
Thread Thread1 = new Thread(new ThreadStart(Proc1));
Thread Thread2 = new Thread(new ThreadStart(Proc2));
Thread1.Start();
Thread2.Start();
Console.ReadKey();
}
private static void Proc1()
{
mut.WaitOne();
Console.WriteLine("线程1执行操作....");
Thread.Sleep(3000);
mut.ReleaseMutex();//V操作
}
private static void Proc2()
{
mut.WaitOne();//P操作
Console.WriteLine("线程2执行操作....");
mut.WaitOne();
}
}
代码1.C#模拟进程之间的同步
运行结果如图2所示。
图2.运行结果
进程互斥
进程互斥是进程之间的间接制约关系。当一个进程进入临界区使用临界资源时,另一个进程必须等待。只有当使用临界资源的进程退出临界区后,这个进程才会解除阻塞状态。
比如进程B需要访问打印机,但此时进程A占有了打印机,进程B会被阻塞,直到进程A释放了打印机资源,进程B才可以继续执行。概念如图3所示。
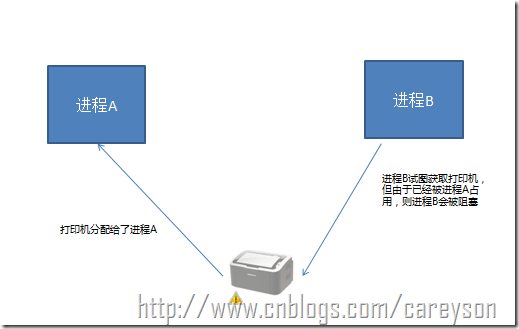
图3.进程之间的互斥
用C#模拟进程之间的互斥,这里我启动了5个线程,但同一时间内只有一个线程能对临界资源进行访问。如代码2所示。
class ProcessMutex
{
private static Mutex mut = new Mutex();
private const int numThreads = 5;
static void Main()
{
for (int i = 0; i <= numThreads; i++)
{
Thread myThread = new Thread(new ThreadStart(UseResource));
myThread.Name = String.Format("线程{0}", i + 1);
myThread.Start();
}
Console.ReadKey();
}
//同步
private static void UseResource()
{
// 相当于P操作
mut.WaitOne();
/*下面代码是线程真正的工作*/
Console.WriteLine("{0}已经进入临界区",
Thread.CurrentThread.Name);
Random r = new Random();
int rNum = r.Next(2000);
Console.WriteLine("{0}执行操作,执行时间为{1}ms", Thread.CurrentThread.Name,rNum);
Thread.Sleep(rNum);
Console.WriteLine("{0}已经离开临界区\r\n",
Thread.CurrentThread.Name);
/*线程工作结束*/
// 相当于V操作
mut.ReleaseMutex();
}
//互斥
}
代码2.C#模拟进程之间的互斥
运行结果如图4所示。
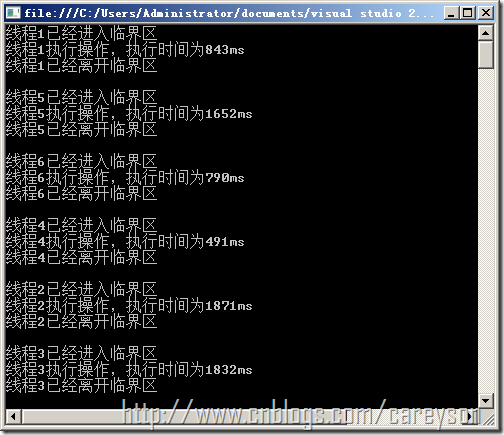
图4.C#模拟进程互斥
实现临界区互斥的基本方法
硬件实现方法
通过硬件实现临界区最简单的办法就是关CPU的中断。从计算机原理我们知道,CPU进行进程切换是需要通过中断来进行。如果屏蔽了中断那么就可以保证当前进程顺利的将临界区代码执行完,从而实现了互斥。这个办法的步骤就是:屏蔽中断--执行临界区--开中断。但这样做并不好,这大大限制了处理器交替执行任务的能力。并且将关中断的权限交给用户代码,那么如果用户代码屏蔽了中断后不再开,那系统岂不是跪了?
还有硬件的指令实现方式,这个方式和接下来要说的信号量方式如出一辙。但是通过硬件来实现,这里就不细说了。
信号量实现方式
这也是我们比较熟悉P V操作。通过设置一个表示资源个数的信号量S,通过对信号量S的P和V操作来实现进程的的互斥。
P和V操作分别来自荷兰语Passeren和Vrijgeven,分别表示占有和释放。P V操作是操作系统的原语,意味着具有原子性。
P操作首先减少信号量,表示有一个进程将占用或等待资源,然后检测S是否小于0,如果小于0则阻塞,如果大于0则占有资源进行执行。
V操作是和P操作相反的操作,首先增加信号量,表示占用或等待资源的进程减少了1个。然后检测S是否小于0,如果小于0则唤醒等待使用S资源的其它进程。
前面我们C#模拟进程的同步和互斥其实算是信号量进行实现的。
一些经典利用信号量实现同步的问题
生产者--消费者问题
问题描述:生产者-消费者问题是一个经典的进程同步问题,该问题最早由Dijkstra提出,用以演示他提出的信号量机制。本作业要求设计在同一个进程地址空间内执行的两个线程。生产者线程生产物品,然后将物品放置在一个空缓冲区中供消费者线程消费。消费者线程从缓冲区中获得物品,然后释放缓冲区。当生产者线程生产物品时,如果没有空缓冲区可用,那么生产者线程必须等待消费者线程释放出一个空缓冲区。当消费者线程消费物品时,如果没有满的缓冲区,那么消费者线程将被阻塞,直到新的物品被生产出来
这里生产者和消费者是既同步又互斥的关系,首先只有生产者生产了,消费着才能消费,这里是同步的关系。但他们对于临界区的访问又是互斥的关系。因此需要三个信号量empty和full用于同步缓冲区,而mut变量用于在访问缓冲区时是互斥的。
利用C#模拟生产者和消费者的关系如代码3所示。
class ProducerAndCustomer
{
//临界区信号量
private static Mutex mut = new Mutex();
private static Semaphore empty = new Semaphore(5, 5);//空闲缓冲区
private static Semaphore full = new Semaphore(0, 5);
//生产者-消费者模拟
static void Main()
{
Console.WriteLine("生产者消费者模拟......");
for (int i = 1; i < 9; i++)
{
Thread Thread1 = new Thread(new ThreadStart(Producer));
Thread Thread2 = new Thread(new ThreadStart(Customer));
Thread1.Name = String.Format("生产者线程{0}", i);
Thread2.Name = String.Format("消费者线程{0}", i);
Thread1.Start();
Thread2.Start();
}
Console.ReadKey();
}
private static void Producer()
{
Console.WriteLine("{0}已经启动",Thread.CurrentThread.Name);
empty.WaitOne();//对empty进行P操作
mut.WaitOne();//对mut进行P操作
Console.WriteLine("{0}放入数据到临界区", Thread.CurrentThread.Name);
Thread.Sleep(1000);
mut.ReleaseMutex();//对mut进行V操作
full.Release();//对full进行V操作
}
private static void Customer()
{
Console.WriteLine("{0}已经启动", Thread.CurrentThread.Name);
Thread.Sleep(12000);
full.WaitOne();//对full进行P操作
mut.WaitOne();//对mut进行P操作
Console.WriteLine("{0}读取临界区", Thread.CurrentThread.Name);
mut.ReleaseMutex();//对mut进行V操作
empty.Release();//对empty进行V操作
}
}
代码3.使用C#模拟生产者和消费者的关系
运行结果如图5所示。
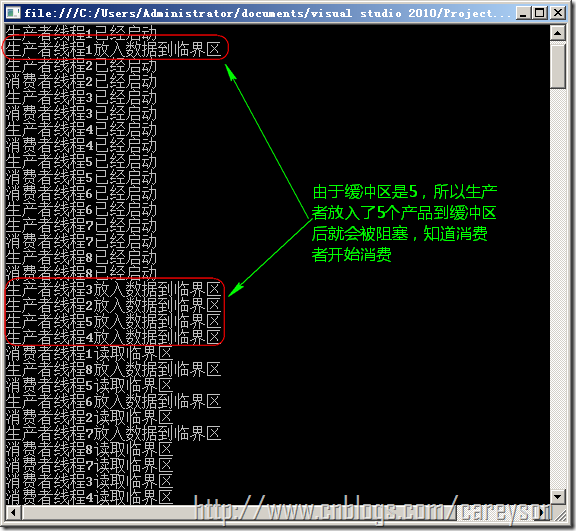
图5.生产者消费者C#模拟结果
读者--写者问题
问题描述:
一个数据文件或记录,统称数据对象,可被多个进程共享,其中有些进程只要求读称为"读者",而另一些进程要求写或修改称为"写者"。
规定:允许多个读者同时读一个共享对象,但禁止读者、写者同时访问一个共享对象,也禁止多个写者访问一个共享对象,否则将违反Bernstein并发执行条件。
通过描述可以分析,这里的读者和写者是互斥的,而写者和写者也是互斥的,但读者之间并不互斥。
由此我们可以设置3个变量,一个用来统计读者的数量,另外两个分别用于对读者数量读写的互斥,读者和读者写者和写者的互斥。如代码4所示。
class ReaderAndWriter
{
private static Mutex mut = new Mutex();//用于保护读者数量的互斥信号量
private static Mutex rw = new Mutex();//保证读者写者互斥的信号量
static int count = 0;//读者数量
static void Main()
{
Console.WriteLine("读者写者模拟......");
for (int i = 1; i < 6; i++)
{
Thread Thread1 = new Thread(new ThreadStart(Reader));
Thread1.Name = String.Format("读者线程{0}", i);
Thread1.Start();
}
Thread Thread2 = new Thread(new ThreadStart(writer));
Thread2.Name = String.Format("写者线程");
Thread2.Start();
Console.ReadKey();
}
private static void Reader()
{
mut.WaitOne();
if (count == 0)
{
rw.WaitOne();
}
count++;
mut.ReleaseMutex();
Thread.Sleep(new Random().Next(2000));//读取耗时1S
Console.WriteLine("读取完毕");
mut.WaitOne();
count--;
mut.ReleaseMutex();
if (count == 0)
{
rw.ReleaseMutex();
}
}
private static void writer()
{
rw.WaitOne();
Console.WriteLine("写入数据");
rw.ReleaseMutex();
}
代码4.C#模拟读者和写者问题
运行结果如图6所示。
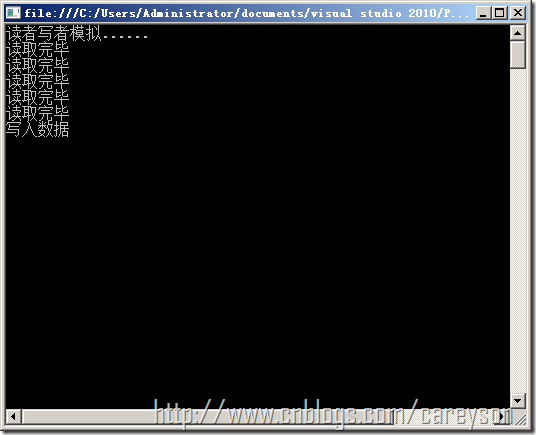
图6.读者写者的运行结果
哲学家进餐问题
问题描述:
有五个哲学家,他们的生活方式是交替地进行思考和进餐。哲学家们公用一张圆桌,周围放有五把椅子,每人坐一把。在圆桌上有五个碗和五根筷子,当一个哲学家思考时,他不与其他人交谈,饥饿时便试图取用其左、右最靠近他的筷子,但他可能一根都拿不到。只有在他拿到两根筷子时,方能进餐,进餐完后,放下筷子又继续思考。

图7.哲学家进餐问题
根据问题描述,五个哲学家分别可以看作是五个进程。五只筷子分别看作是五个资源。只有当哲学家分别拥有左右的资源时,才得以进餐。如果不指定规则,当每个哲学家手中只拿了一只筷子时会造成死锁,从而五个哲学家都因为吃不到饭而饿死。因此我们的策略是让哲学家同时拿起两只筷子。因此我们需要对每个资源设置一个信号量,此外,还需要使得哲学家同时拿起两只筷子而设置一个互斥信号量,如代码5所示。
class philosopher
{
private static int[] chopstick=new int[5];//分别代表哲学家的5只筷子
private static Mutex eat = new Mutex();//用于保证哲学家同时拿起两双筷子
static void Main()
{
//初始设置所有筷子可用
for (int k = 1; k <= 5; k++)
{
chopstick[k - 1] = 1;
}
//每个哲学家轮流进餐一次
for(int i=1;i<=5;i++)
{
Thread Thread1 = new Thread(new ThreadStart(Philosophers));
Thread1.Name = i.ToString();
Thread1.Start();
}
Console.ReadKey();
}
private static void Philosophers()
{
//如果筷子不可用,则等待2秒
while (chopstick[int.Parse(Thread.CurrentThread.Name)-1] !=1 || chopstick[(int.Parse(Thread.CurrentThread.Name))%4]!=1)
{
Console.WriteLine("哲学家{0}正在等待", Thread.CurrentThread.Name);
Thread.Sleep(2000);
}
eat.WaitOne();
//同时拿起两双筷子
chopstick[int.Parse(Thread.CurrentThread.Name)-1] = 0;
chopstick[(int.Parse(Thread.CurrentThread.Name)) % 4] = 0;
eat.ReleaseMutex();
Thread.Sleep(1000);
Console.WriteLine("哲学家{0}正在用餐...",Thread.CurrentThread.Name);
//用餐完毕后放下筷子
chopstick[int.Parse(Thread.CurrentThread.Name)-1] = 1;
chopstick[(int.Parse(Thread.CurrentThread.Name)) % 4] = 1;
Console.WriteLine("哲学家{0}用餐完毕,继续思考", Thread.CurrentThread.Name);
}
}
代码5.C#模拟哲学家用餐问题
运行结果如图7所示。
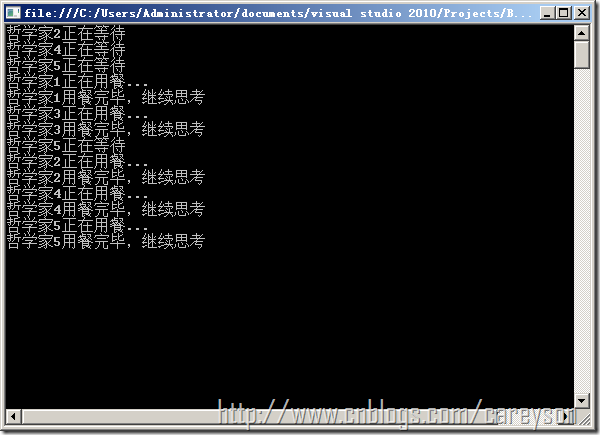
图8.哲学家问题运行结果
总结
本文介绍了进程的同步和互斥的概念,临界区的概念,以及实现进程同步互斥的方式,并解决了3种实现同步的经典问题,并给出了相应的C#模拟代码。操作系统对于进程的管理是是计算机编程的基础之一,因此掌握这个概念会使你的内功更上一层:-D
C#实现平衡多路查找树(B树)
写在前面:搞了SQL Server时间也不短了,对B树的概念也算是比较了解。去网上搜也搜不到用C#或java实现的B树,干脆自己写一个。实现B树的过程中也对很多细节有了更深的了解。
简介
B树是一种为辅助存储设计的一种数据结构,在1970年由R.Bayer和E.mccreight提出。在文件系统和数据库中为了减少IO操作大量被应用。遗憾的是,他们并没有说明为什么取名为B树,但按照B树的性质来说B通常被解释为Balance。在国内通常有说是B-树,其实并不存在B-树,只是由英文B-Tree直译成了B-树。
一个典型的 B树如图1所示。

图1.一个典型的B树
符合如下特征的树才可以称为B树:
- 根节点如果不是叶节点,则至少需要两颗子树
- 每个节点中有N个元素,和N+1个指针。每个节点中的元素不得小于最大节点容量的1/2
- 所有的叶子位于同一层级(这也是为什么叫平衡树)
- 父节点元素向左的指针必须小于节点元素,向右的指针必须大于节点元素,比如图1中Q的左指针必须小于Q,右指针必须大于Q
为什么要使用B树
在计算机系统中,存储设备一般分为两种,一种为主存(比如说CPU二级缓存,内存等),主存一般由硅制成,速度非常快,但每一个字节的成本往往高于辅助存储设备很多。还有一类是辅助存储(比如硬盘,磁盘等),这种设备通常容量会很大,成本也会低很多,但是存取速度非常的慢,下面我们来看一下最常见的辅存--硬盘。
硬盘作为主机中除了唯一的一个机械存储设备,速度远远落后于CPU和内存。图2是一个典型的磁盘驱动器。

图2.典型的磁盘驱动器工作原理
一个驱动器包含若干盘片,以一定的速度绕着主轴旋转(比如PC常见的转速是7200RPM,服务器级别的有10000RPM和15000RPM的),每个盘片表面覆盖一个可磁化的物质.每个盘片利用摇臂末端的磁头进行读写。摇臂是物理连接在一起的,通过移动远离或贴近主轴。
因为有机械移动的部分,所以磁盘的速度相比内存而言是非常的慢。这个机械移动包括两个部分:盘旋转和磁臂移动。仅仅对于盘旋转来说,比如常见的7200RPM的硬盘,转一圈需要60/7200≈8.33ms,换句话说,让磁盘完整的旋转一圈找到所需要的数据需要8.33ms,这比内存常见的100ns慢100000倍左右,这还不包括移动摇臂的时间。
因为机械移动如此的花时间,磁盘会每次读取多个数据项。一般来说最小单位为簇。而对于SQL Server来说,则为一页(8K)。
但由于要查找的数据往往很大,不能全部装入主存。需要磁盘来辅助存储。而读取磁盘则是占处理时间最重要的一部分,所以如果我们尽可能的减少对磁盘的IO操作,则会大大加快速度。这也是B树设计的初衷。
B树通过将根节点放入主存,其它所有节点放入辅存来大大减少对于辅存IO的操作。比如图1中,我如果想查找元素Y,仅仅需要从主存中取得根节点,再根据根节点的右指针做一次IO读,再根据这个节点最右的指针做一次IO读,就可以找到元素Y。相比其他数据结构,仅仅做两次辅存IO读大大减少了查找的时间。
B树的高度
根据上面的例子我们可以看出,对于辅存做IO读的次数取决于B树的高度。而B树的高度由什么决定的呢?
根据B树的高度公式: 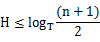
其中T为度数(每个节点包含的元素个数),N为总元素个数.
我们可以看出T对于树的高度有决定性的影响。因此如果每个节点包含更多的元素个数,在元素个数相同的情况下,则更有可能减少B树的高度。这也是为什么SQL Server中需要尽量以窄键建立聚集索引。因为SQL Server中每个节点的大小为8092字节,如果减少键的大小,则可以容纳更多的元素,从而减少了B树的高度,提升了查询的性能。
上面B树高度的公式也可以进行推导得出,将每一层级的的元素个数加起来,比如度为T的节点,根为1个节点,第二层至少为2个节点,第三层至少为2t个节点,第四层至少为2t*t个节点。将所有最小节点相加,从而得到节点个数N的公式:
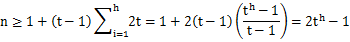
两边取对数,则可以得到树的高度公式。
这也是为什么开篇所说每个节点必须至少有两个子元素,因为根据高度公式,如果每个节点只有一个元素,也就是T=1的话,那么高度将会趋于正无穷。
B树的实现
讲了这么多概念,该到实现B树的时候了。
首先需要定义B树的节点,如代码1所示。
public class TreeNode<T>where T:IComparable<T>
{
public int elementNum = 0;//元素个数
public IList<T> Elements = new List<T>();//元素集合,存在elementNum个
public IList<TreeNode<T>> Pointer = new List<TreeNode<T>>();//元素指针,存在elementNum+1
public bool IsLeaf = true;//是否为叶子节点
}
代码1.声明节点
我给每个节点四个属性,分别为节点包含的元素个数,节点的元素数组,节点的指针数组和节点是否为叶子节点。我这里对节点存储的元素类型使用了泛型T,并且必须实现ICompable接口使得节点所存储的元素可以互相比较。
有了节点的定义后,就可以创建B树了,如代码2所示。
//创建一个b树,也是类的构造函数
public BTree()
{
RootNode = new TreeNode<T>();
RootNode.elementNum = 0;
RootNode.IsLeaf = true;
//将节点写入磁盘,做一次IO写
}
代码2.初始化B树
这是BTree类的构造函数,初始化一个根节点。全部代码我稍后给出。
下面则要考虑B树的插入,其实B树的构建过程也是向B树插入元素的过程.B树的插入相对来说比较复杂,需要考虑很多因素。
首先,每一个节点可容纳的元素个数是一样并且有限的,这里我声明了一个常量最为每个节点,如代码3所示。
const int NumPerNode = 4;
代码3.设置每个节点最多容纳的元素个数
对于B树来说,节点增加的唯一方式就是节点分裂,这个概念和SQL SERVER中的页分裂是一样的。
页分裂的过程首先需要生成新页,然后将大概一半的元素移动到新页中,然后将中间元素提升到父节点。比如我想在现有的元素中插入8,造成已满的页进行分裂,如图3所示:

图3.向已经满的叶子节点插入元素会造成页分裂
通过叶子分裂的概念不难看出,叶子节点分裂才会造成非叶子节点元素的增加。最终传递到根元素。而根元素的分裂是树长高的唯一途径。
在C#中的实现代码如代码4所示。
//B树中的节点分裂
public void BTreeSplitNode(TreeNode<T> FatherNode, int position, TreeNode<T> NodeToBeSplit)
{
TreeNode<T> newNode = new TreeNode<T>();//创建新节点,容纳分裂后被移动的元素
newNode.IsLeaf = NodeToBeSplit.IsLeaf;//新节点的层级和原节点位于同一层
newNode.elementNum = NumPerNode - (NumPerNode / 2 + 1);//新节点元素的个数大约为分裂节点的一半
for (int i = 1; i < NumPerNode - (NumPerNode / 2 + 1); i++)
{
//将原页中后半部分复制到新页中
newNode.Elements[i - 1] = NodeToBeSplit.Elements[i + NumPerNode / 2];
}
if (!NodeToBeSplit.IsLeaf)//如果不是叶子节点,将指针也复制过去
{
for (int j = 1; j < NumPerNode / 2 + 1; j++)
{
newNode.Pointer[j - 1] = NodeToBeSplit.Pointer[NumPerNode / 2];
}
}
NodeToBeSplit.elementNum = NumPerNode / 2;//原节点剩余元素个数
//将父节点指向子节点的指针向后推一位
for (int k = FatherNode.elementNum + 1; k > position + 1; k--)
{
FatherNode.Pointer[k] = FatherNode.Pointer[k - 1];
}
//将父节点的元素向后推一位
for (int k = FatherNode.elementNum; k > position + 1; k--)
{
FatherNode.Elements[k] = FatherNode.Elements[k - 1];
}
//将被分裂的页的中间节点插入父节点
FatherNode.Elements[position - 1] = NodeToBeSplit.Elements[NumPerNode / 2];
//父节点元素大小+1
FatherNode.elementNum += 1;
//将FatherNode,NodeToBeSplit,newNode写回磁盘,三次IO写操作
}
代码4.分裂节点
通过概念和代码不难看出,节点的分裂相对比较消耗IO,这也是为什么SQL Server中需要一些最佳实现比如不用GUID做聚集索引,或是设置填充因子等来减少页分裂。
而如果需要插入元素的节点不满,则不需要页分裂,则需要从根开始查找,找到需要被插入的节点,如代码5所示。
//在节点非满时寻找插入节点
public void BTreeInsertNotFull(TreeNode<T> Node, T KeyWord)
{
int i=Node.elementNum;
//如果是叶子节点,则寻找合适的位置直接插入
if (Node.IsLeaf)
{
while (i >= 1 && KeyWord.CompareTo(Node.Elements[i - 1]) < 0)
{
Node.Elements[i] = Node.Elements[i - 1];//所有的元素后推一位
i -= 1;
}
Node.Elements[i - 1] = KeyWord;//将关键字插入节点
Node.elementNum += 1;
//将节点写入磁盘,IO写+1
}
//如果是非叶子节点
else
{
while (i >= 1 && KeyWord.CompareTo(Node.Elements[i - 1]) < 0)
{
i -= 1;
}
//这步将指针所指向的节点读入内存,IO读+1
if (Node.Pointer[i].elementNum == NumPerNode)
{
//如果子节点已满,进行节点分裂
BTreeSplitNode(Node, i, Node.Pointer[i]);
}
if (KeyWord.CompareTo(Node.Elements[i - 1]) > 0)
{
//根据关键字的值决定插入分裂后的左孩子还是右孩子
i += 1;
}
//迭代找叶子,找到叶子节点后插入
BTreeInsertNotFull(Node.Pointer[i], KeyWord);
}
}
代码5.插入
通过代码5可以看出,我们没有进行任何迭代。而是从根节点开始遇到满的节点直接进行分裂。从而减少了性能损失。
再将根节点分裂的特殊情况考虑进去,我们从而将插入操作合为一个函数,如代码6所示。
public void BtreeInsert(T KeyWord)
{
if (RootNode.elementNum == NumPerNode)
{
//如果根节点满了,则对跟节点进行分裂
TreeNode<T> newRoot = new TreeNode<T>();
newRoot.elementNum = 0;
newRoot.IsLeaf = false;
//将newRoot节点变为根节点
BTreeSplitNode(newRoot, 1, RootNode);
//分裂后插入新根的树
BTreeInsertNotFull(newRoot, KeyWord);
//将树的根进行变换
RootNode = newRoot;
}
else
{
//如果根节点没有满,直接插入
BTreeInsertNotFull(RootNode, KeyWord);
}
}
代码6.插入操作
现在,我们就可以通过插入操作,来实现一个B树了。
B树的查找
既然B树生成好了,我们就可以对B树进行查找了。B树的查找实现相对简单,仅仅是从跟节点进行迭代,如果找到元素则返回节点和位置,如果找不到则返回NULL.
//从B树中搜索节点,存在则返回节点和元素在节点的值,否则返回NULL
public returnValue<T> BTreeSearch(TreeNode<T> rootNode, T keyword)
{
int i = 1;
while (i <= rootNode.elementNum && keyword.CompareTo(rootNode.Elements[i - 1])>0)
{
i = i + 1;
}
if (i <= rootNode.elementNum && keyword.CompareTo(rootNode.Elements[i - 1]) == 0)
{
returnValue<T> r = new returnValue<T>();
r.node = rootNode.Pointer[i];
r.position = i;
return r;
}
if (rootNode.IsLeaf)
{
return null;
}
else
{
//从磁盘将内容读出来,做一次IO读
return BTreeSearch(rootNode.Pointer[i], keyword);
}
}
代码7.对B树进行查找
顺带说一下,returnValue类仅仅是对返回值的一个封装,代码如代码8所示。
public class returnValue<T> where T : IComparable<T>
{
public TreeNode<T> node;
public int position;
}
代码8.returnValue的代码
总结
本文从B树的概念原理,以及为什么需要B树到B树的实现来阐述B树的概念。B树是一种非常优雅的数据结构。是关系数据库和文件系统的核心算法。对于B树的了解会使得你对于数据库的学习更加系统和容易。
HTTP协议漫谈 C#实现图(Graph) C#实现二叉查找树 浅谈进程同步和互斥的概念 C#实现平衡多路查找树(B树)的更多相关文章
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二)
本文属于图神经网络的系列文章,文章目录如下: 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一) 从图(Graph)到图卷积(Graph Convolutio ...
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一)
本文属于图神经网络的系列文章,文章目录如下: 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一) 从图(Graph)到图卷积(Graph Convolutio ...
- 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (三)
本文属于图神经网络的系列文章,文章目录如下: 从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一) 从图(Graph)到图卷积(Graph Convolutio ...
- (转)HTTP协议漫谈
HTTP协议漫谈 简介 园子里已经有不少介绍HTTP的的好文章.对HTTP的一些细节介绍的比较好,所以本篇文章不会对HTTP的细节进行深究,而是从够高和更结构化的角度将HTTP协议的元素进行分类讲 ...
- HTTP 协议漫谈
转载出处:HTTP 协议漫谈 简介 网络上已经有不少介绍 HTTP 的好文章,对HTTP的一些细节介绍的比较好,所以本篇文章不会对 HTTP 的细节进行深究,而是从够高和更结构化的角度将 HTTP 协 ...
- 纸上谈兵: 图 (graph)
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 图(graph)是一种比较松散的数据结构.它有一些节点(vertice),在某些节 ...
- 算法与数据结构基础 - 图(Graph)
图基础 图(Graph)应用广泛,程序中可用邻接表和邻接矩阵表示图.依据不同维度,图可以分为有向图/无向图.有权图/无权图.连通图/非连通图.循环图/非循环图,有向图中的顶点具有入度/出度的概念. 面 ...
- 浅谈局域网ARP攻击的危害及防范方法(图)
浅谈局域网ARP攻击的危害及防范方法(图) 作者:冰盾防火墙 网站:www.bingdun.com 日期:2015-03-03 自 去年5月份开始出现的校内局域网频繁掉线等问题,对正常的教育教 ...
- 浅谈可持久化Trie与线段树的原理以及实现(带图)
浅谈可持久化Trie与线段树的原理以及实现 引言 当我们需要保存一个数据结构不同时间的每个版本,最朴素的方法就是每个时间都创建一个独立的数据结构,单独储存. 但是这种方法不仅每次复制新的数据结构需要时 ...
随机推荐
- django insert data into mysql
#!/usr/bin/python # -*- coding:utf-8 -*- # @filename: search # @author:wwx399777 wuweiji # @date: 20 ...
- npm的替代品
npm安装依赖包太慢,cnpm也快不到哪里去,偶然发现了yarn,特快特好用! 安装yarn:npm install -g yarn 查看版本号:yarn -v 安装依赖项:yarn install
- (8) openssl rsautl(签名/验证签名/加解密文件)和openssl pkeyutl(文件的非对称加密)
rsautl是rsa的工具,相当于rsa.dgst的部分功能集合,可用于生成数字签名.验证数字签名.加密和解密文件. pkeyutl是非对称加密的通用工具,大体上和rsautl的用法差不多,所以此处只 ...
- Django-模型层(1)
ORM MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置即可以轻松更换数据库,这极大的减轻了开发人员的工作 ...
- c++ 十进制转二进制 代码实现
我初中的时候就没搞清楚手动怎么算二进制 写这个代码的时候研究了好久百度 https://jingyan.baidu.com/article/597a0643614568312b5243c0.html ...
- Farthest Nodes in a Tree (求树的直径)
题目链接,密码:hpu Description Given a tree (a connected graph with no cycles), you have to find the farthe ...
- INFO main org.springframework.context.support.AbstractApplicationContext
原因, spring-framework-5.0.2.RELEASE 需要使用 jdk8.
- POJ-2590-Steps题目详解,思路分析及代码,规律题,重要的是找到规律~~
Steps Time Limit: 1000MS Memory Limit: 65536K http://poj.org/problem?id=2590 Description One ...
- [Kubernetes]Volume
容器技术使用rootfs机制和Mount Namespace,构建出一个同宿主机完全隔离开的文件系统环境 那容器里进程新建的文件,怎么样才能让宿主机获取到?宿主机上的文件和目录,怎么样才能让容器里的进 ...
- Lucene的例子
lucene爬数据库中的数据无非也是查询数据.所有我们用lucene搜索数据主要有下面几个步骤:(代码紧供参考) 一 , 从数据库中查数据 ====爬数据 ------------- ...