Hadoop 部署之 Hive (五)
一、Hive 简介
1、什么是 Hive
- Hive 由 Facebook 实现并开源,是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能,底层数据是存储在 HDFS 上。
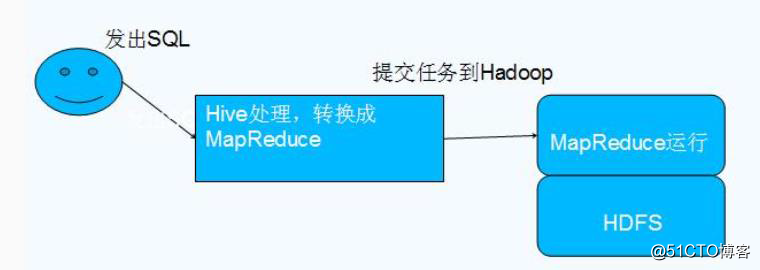
- Hive 的本质是将 SQL 语句转换为 MapReduce 任务运行,使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
- Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。
2、为什么使用 Hive
直接使用 MapReduce 所面临的问题:
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
1、更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
2、更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
3、更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
3、Hive 的特点
- 优点:
1、可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
2、延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
- 缺点:
1、Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
2、Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
3、Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
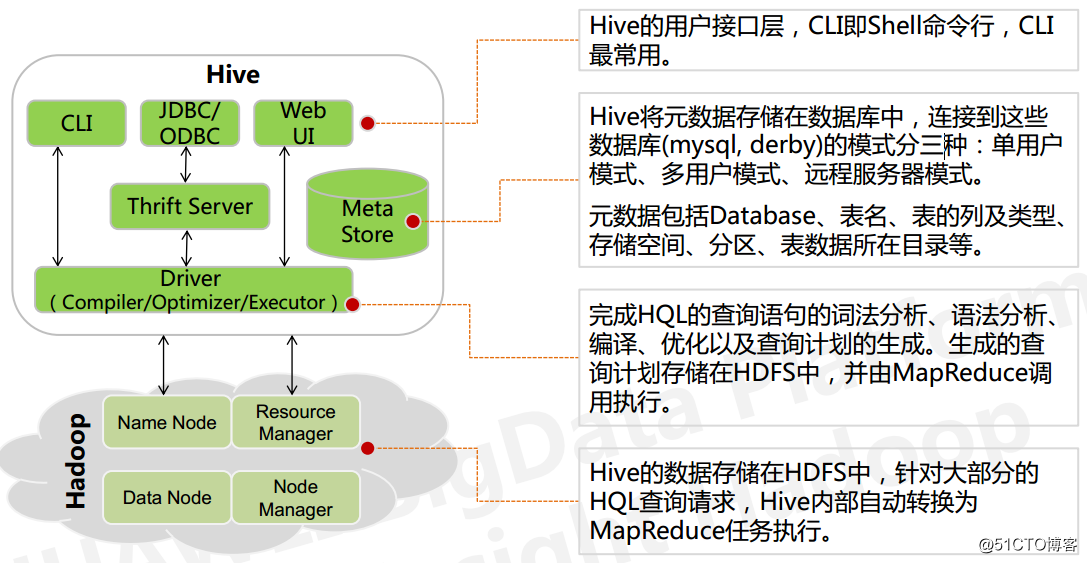
4、Hive 的架构
二、Hive 安装
1、MySQL 安装(datanode01)
Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
yum install mariadb-server
2、MySQL 启动
启动数据库
systemctl start mariadb
systemctl enable mariadb
3、Hive 下载安装
# 下载安装包
wget https://mirrors.aliyun.com/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
# 解压安装包
tar xf apache-hive-2.3.3-bin.tar.gz
mv apache-hive-2.3.3-bin /usr/local/hive
# 创建目录
mkdir -p /home/hive/{log,tmp,job}
4、配置 Hive 环境变量
编辑文件/etc/profile.d/hive.sh,修改为如下内容:
# HIVE ENV
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
使HIVE环境变量生效。
source /etc/profile.d/hive.sh
三、Hive 配置
1、配置 metastore(datanode01)
mysql> grant all privileges on *.* to 'hive'@'%' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'hive'@'datanode01' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'thbl_prd_hive'@'%' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'hive'@'localhost' identified by 'hive123456' with grant option;
mysql> grant all privileges on *.* to 'thbl_prd_hive'@'localhost' identified by 'hive123456' with grant option;
mysql> flush privileges;
2、配置 jdbc(datanode01)
wget http://mirrors.163.com/mysql/Downloads/Connector-J/mysql-connector-java-5.1.45.tar.gz
tar xf mysql-connector-java-5.1.45.tar.gz
cp mysql-connector-java-5.1.45/mysql-connector-java-5.1.45-bin.jar /usr/local/hive/lib/
3、备份template配置文件(namenode01)
cd /usr/local/hive/conf
mkdir template
mv *.template template
# 安排配置文件
cp template/hive-exec-log4j2.properties.template hive-exec-log4j2.properties
cp template/hive-log4j2.properties.template hive-log4j2.properties
cp template/hive-default.xml.template hive-default.xml
cp template/hive-env.sh.template hive-env.sh
4、配置 hive-env.sh(namenode01)
编辑文件/usr/local/hive/conf/hive-env.sh,修改内容如下:
HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
5、配置数据仓库 hive-site.xml(namenode01)
编辑文件/usr/local/hive/conf/hive-site.xml,修改内容为如下:
<configuration>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/job</value>
<description>hive的本地临时目录,用来存储不同阶段的map/reduce的执行计划</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/tmp/${hive.session.id}_resources</value>
<description>hive下载的本地临时目录</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hive/log/${system:user.name}</value>
<description>hive运行时结构化日志路径</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.1.1.war</value>
<description>HWI war文件路径, 与 ${HIVE_HOME}相关. </description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/home/hive/log/${system:user.name}/operation_logs</value>
<description>日志开启时的,操作日志路径</description>
</property>
<!--远程mysql元数据库-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>启动时自动创建必要的schema</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>Hive数据仓库在HDFS中的路径</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://datanode01:9083</value>
<description>远程metastore的 Thrift URI,以供metastore客户端连接metastore服务端</description>
</property>
<!--mysql元数据库配置-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>JDBC驱动名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://datanode01:3306/hive_db?createDatabaseIfNotExist=true</value>
<description>JDBC连接名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>连接metastore数据库的用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive123456</value>
<description>连接metastore数据库的密码</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>强制metastore schema的版本一致性</description>
</property>
</configuration>
6、配置权限(namenode01)
scp /usr/local/hive/conf/* datanode01:/usr/local/hive/conf/
chmod 755 /usr/local/hive/conf/*
四、Hive 启动
1、在namenode01,启动hiveserver2
hive --service hiveserver2 &
2、在datanode01,启动metastore
hive --service metastore &
五、Hive 检查
1、JPS
[root@namenode01 ~]# jps
14512 NameNode
14786 ResourceManager
21348 RunJar
15894 HMaster
22047 Jps
[root@datanode01 ~]# jps
3509 DataNode
3621 NodeManager
1097 QuorumPeerMain
9930 RunJar
3935 HRegionServer
10063 Jps
2、hive shell
[root@namenode01 ~]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in file:/usr/local/hive/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show tables;
OK
Time taken: 0.833 seconds
Hadoop 部署之 Hive (五)的更多相关文章
- Hadoop生态圈-hive五种数据格式比较
Hadoop生态圈-hive五种数据格式比较 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 基于Hadoop的数据仓库Hive
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理.特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hi ...
- Hadoop框架基础(五)
** Hadoop框架基础(五) 已经部署了Hadoop的完全分布式集群,我们知道NameNode节点的正常运行对于整个HDFS系统来说非常重要,如果NameNode宕掉了,那么整个HDFS就要整段垮 ...
- Hadoop部署方式-完全分布式(Fully-Distributed Mode)
Hadoop部署方式-完全分布式(Fully-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本博客搭建的虚拟机是伪分布式环境(https://w ...
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- Hadoop 部署之 Hadoop (三)
目录 一.Hadoop 介绍 1.HDFS 介绍 2.HDFS 组成 3.MapReduce 介绍 4.MapReduce 架构 JobTracker TaskTracker 二.Hadoop的安装 ...
- Hadoop 部署之环境准备(一)
目录 一.软硬件规划 二.主机名解析 三.配置 SSH 互信 四.创建用户 五.JDK 的安装 一.软硬件规划 ID 主机类型 主机名 IP 应用软件 操作系统 硬件配置 1 物理机 namenode ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- hadoop部署小结的命令
hadoop部署总结的命令 学习笔记,转自:hadoop部署总结的命令http://www.aboutyun.com/thread-5385-1-1.html(出处: about云开发)
随机推荐
- PAT乙级1044
题目链接 https://pintia.cn/problem-sets/994805260223102976/problems/994805279328157696 题解 需要注意的几个点: 题目有指 ...
- JSP网页中文乱码
在编程过程中总是由于各种原因出现中文乱码.最好的解决方法就是把代码中所有编码格式全部设置为UTF-8,这样一般能解决大部分问题,但是今天我发现另外一种情况.我们都知道当一个jsp文件中全部都是html ...
- halcon导出类---HDevWindowStack详解
在HDevelop中编写好的程序在导出时,Halcon会帮我们转换成我们需要的语言,比如C++.例:HDevelop中有如下语句需要导出: dev_close_window() Halcon导出成C+ ...
- ComboGrid二级联动以及给二级联动赋默认值
<input name="buyStatus" id="upbuyStatus" style="width: 100%;height: 85%& ...
- 2019牛客多校E Androgynos——自补图&&构造
题目 给出一个 $n$,判断是否存在 $n$ 个顶点的自补图,如果存在,输出边和映射. 分析 一个无向图若同构于它的补图,则称该图为自补图. 定理:一个自补图一定存在 $4k$ 或 $4k+1$ 个顶 ...
- BZOJ 2039 / Luogu P1791 [2009国家集训队]employ人员雇佣 (最小割)
题面 BZOJ传送门 Luogu传送门 分析 考虑如何最小割建图,因为这仍然是二元关系,我们可以通过解方程来确定怎么建图,具体参考论文 <<浅析一类最小割问题 湖南师大附中 彭天翼> ...
- 普通java类获取spring容器bean的方法
很多时候,我们在普通的java类中需要获取spring的bean来做操作,比如,在线程中,我们需要操作数据库,直接通过spring的bean中构建的service就可以完成.无需自己写链接..有时候有 ...
- 第四章 深入C#的string类
一.String 类的常用方法 1.indexOf(); 获取指定字符串的位置,如果没有则返回-1 2.SubString(); 截取字符串,参数1代表开始位置,参数2代表截取长度 3.ToLo ...
- Catalan Number-卡特兰数入门
卡特兰数 首先,我们设f(n)=序列个数为n的出栈序列种数.同时,我们假定,从开始到栈第一次出到空为止,这段过程中第一个出栈的序数是k.特别地,如果栈直到整个过程结束时才空,则k=n. 令h(0)=1 ...
- vue中插槽(slot)的使用
刚学vue的时候,曾经学习过slot插槽的使用,但是后面接触的不多,因为之前我还没使用element-ui... 但是使用了element-ui之后,里面的许多组件,有时候会使用插槽,为了巩固一下插槽 ...