vue 的多页面应用
vue-cli3 中构建多页面的应用
第一步:先创建一个 vue-cli3 的项目:vue create app
然后运行项目:npm run serve
现在开始多页面的应用:
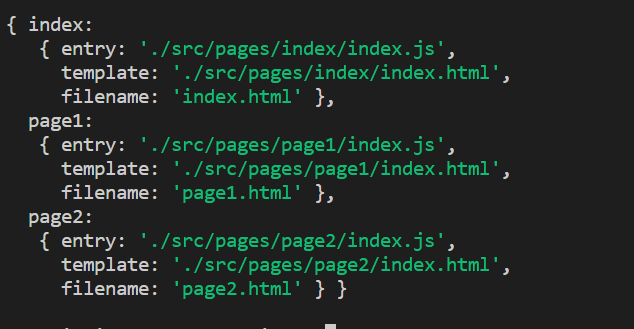
首先在 src 的目录下面,创建一个 pages 的文件,然后如图,创建这样的目录结构,每一个文件夹,对应的是一个页面;

接下来说每个文件所对应的内容,所有的文件都是这样的套路
index.html
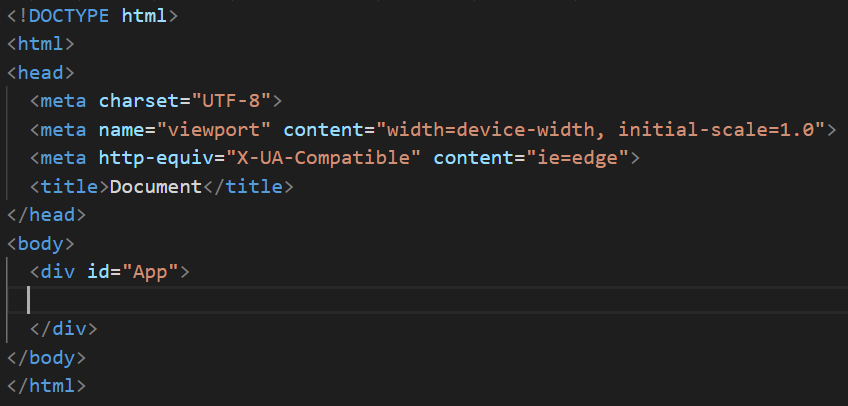
代码:
index.js
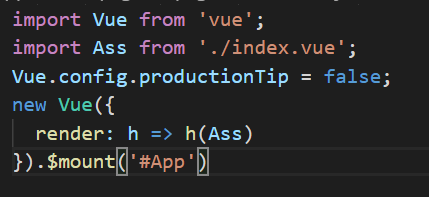
代码:
index.vue
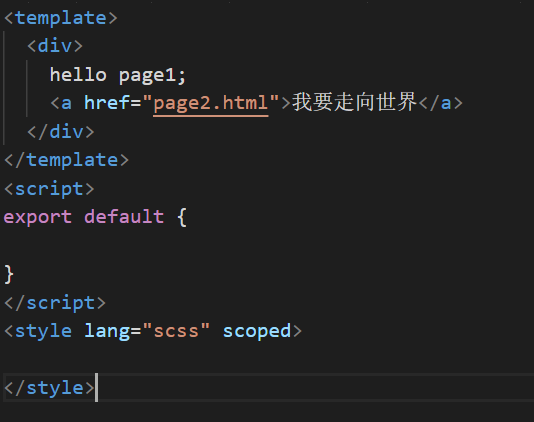
代码:
然后我们需要在跟目录下创建一个 vue.config.js 的文件
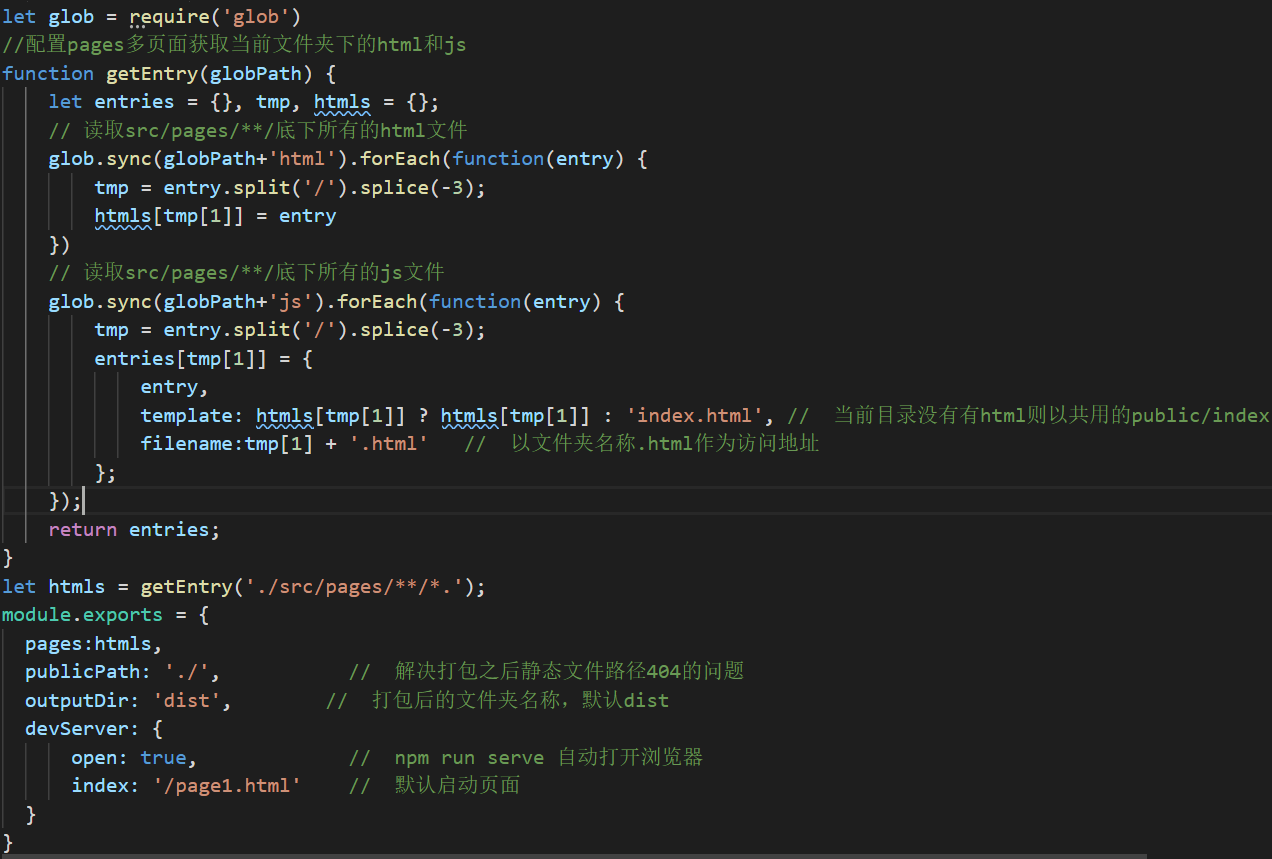
代码:
然后我们打包指令:npm run build
我们跳转的方式就可以通过 a 标签来实现了
然后我们可以看到出口文件的打包情况
vue 的多页面应用的更多相关文章
- vue获得当前页面URL动态拼接URL复制邀请链接方法
vue获得当前页面URL动态拼接URL复制邀请链接方法 当前页面完整url可以用 location.href路由路径可以用 this.$route.path路由路径参数 this.$route.par ...
- 【vue】使用vue构建多页面应用
先了解一些单页面和多页面的区别 mm 多页应用模式MPA 单页应用模式SPA 应用构成 由多个完整页面构成 一个外壳页面和多个页面片段构成 跳转方式 页面之间的跳转是从一个页面跳转到另一个页面 页面片 ...
- vue实现部分页面导入底部 vue配置公用头部、底部,可控制显示隐藏
vue实现部分页面导入底部 vue配置公用头部.底部,可控制显示隐藏 在app.vue文件里引入公共的header 和 footer header 和 footer 默认显示,例如某个页面不需要显示h ...
- vue 监听页面宽度变化 和 键盘事件
vue 监听页面窗口大小 export default { name: 'Full', components: { Header, Siderbar }, data () { return { scr ...
- 高性能流媒体服务器EasyDSS前端重构(一)-从零开始搭建 webpack + vue + AdminLTE 多页面脚手架
本文围绕着实现EasyDSS高性能流媒体服务器的前端框架来展开的,具体EasyDSS的相关信息可在:www.easydss.com 找到! EasyDSS 高性能流媒体服务器前端架构概述 EasyDS ...
- vue使用nprogress页面加载进度条
vue使用nprogress页面加载进度条 NProgress是页面跳转是出现在浏览器顶部的进度条 官网:http://ricostacruz.com/nprogress/ github:https: ...
- 用vue实现登录页面
vue和mui一起完成登录页面(在hbuilder编辑器) <!DOCTYPE html> <html> <head> <meta charset=" ...
- 高性能流媒体服务器EasyDSS前端重构(三)- webpack + vue + AdminLTE 多页面引入 element-ui
接上篇 接上篇<高性能流媒体服务器EasyDSS前端重构(二) webpack + vue + AdminLTE 多页面提取共用文件, 优化编译时间> 本文围绕着实现EasyDSS高性能流 ...
- 高性能流媒体服务器EasyDSS前端重构(二) webpack + vue + AdminLTE 多页面提取共用文件, 优化编译时间
本文围绕着实现EasyDSS高性能流媒体服务器的前端框架来展开的,具体EasyDSS的相关信息可在:www.easydss.com 找到! 接上回 <高性能流媒体服务器EasyDSS前端重构(一 ...
- vue 配置多页面应用
前言: 本文基于vue 2.5.2, webpack 3.6.0(配置多页面原理类似,实现方法各有千秋,可根据需要进行定制化) vue 是单页面应用.但是在做大型项目时,单页面往往无法满足我们的需求, ...
随机推荐
- fastadmin 中的日期时间,日期时间范围范围插件和key-value插件
//A/a代表字段名<div class="form-group"> <label class="control-label col-xs-12 col ...
- 04-【servlet转发和重定向】
转发: //forward(将 数据传给下一个资源(servlet,jsp ,html等 ,把请求和响应的数据和参数设置带过去 ) request.getRequestDispatcher(" ...
- FASTCGI/CGI
在了解这两个协议之前,我们先谈一下动态网页 动态网页 是指跟静态网页相对的一种网页编程技术.静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了--除非你修改页面代码.而动态网 ...
- BLE 5协议栈-链路层
文章转载自:http://www.sunyouqun.com/2017/04/page/3/ 链路层LL(Link Layer)是协议栈中最重要的一层. 链路层的核心是状态机,包含广播.扫描.发起和连 ...
- 基于docker安装pxc集群
基于docker安装pxc集群 一.PXC 集群的安装 PXC集群比较特殊,需要安装在 linux 或 Docker 之上.这里使用 Docker进行安装! Docker的镜像仓库中包含了 PXC数据 ...
- NB-IOT无线帧结构和下行物理信道
NB-IOT Downlink OFDM参数 1.下行基于OFDMA, FF点数=128,基带采样速率1.92MHz,子载波间距15kHz,有效带宽180kHz=1PRB OFDMA: 正交频分多址, ...
- CSS基础学习-13.CSS 浮动
如果前一个元素设置浮动属性,则之后的元素也会继承float属性,我觉得这里说是继承不太对,可以理解为会影响到之后的元素,所以在设置浮动元素之后的元素要想不被影响就需要清除浮动.元素设置左浮动,则清除左 ...
- js数据持久化本地数据存储-JSON.parse和JSON.stringify的区别
JSON.stringify()的作用是将 JavaScript 值转换为 JSON 字符串, 而JSON.parse()可以将JSON字符串转为一个对象. 简单点说,它们的作用是相对的,我用JSON ...
- MyBatis注解开发-@Insert和@InsertProvider
@Insert和@InsertProvider都是用来在实体类的Mapper类里注解保存方法的SQL语句.不同的是,@Insert是直接配置SQL语句,而@InsertProvider则是通过SQL工 ...
- [Functional Programming] Church Encodings: Numberals
const log = console.log; // zero :: &fa.a const zero = f => x => x; // zero is F // once : ...