分布式缓存 - hash环/一致性hash
一 引言
当前memcached,redis这类分布式kv缓存已经非常普遍。我们知道memcached的分布式其实是一种"伪分布式",也就是它的服务器节点之间其实是无关联的,之间没有网络拓扑关系,由客户端来决定一个key要存放在哪台机器。
具体来讲,假设我们有多台memcached服务器,编号分别为m0, m1, m2.. 对于一个key,由客户端来决定存放到哪台机器,最简单的办法就是key % N, 其中N是机器的总数
但是有一个问题,一旦机器数增加或减少,N发生变化,key去mod新旧N得到的机器编号大概率不相等,那么之前存放的数据就全部无效了。
二 hash环
基于上面的问题,提出了hash环的概念。hash环的过程有两次hash
(1) 把所有的机器编号hash到这个环上
(2) 把key也hash到这个环上,然后在这个环上进行匹配,看这个key和哪台机器匹配
具体过程是这样: 假定有一个hash函数,其值空间为(0 ~ 2^32-1)。也就是说,其hash值是个32位无整型数字,这些数字组成一个环。首先对机器进行hash(比如根据机器ip),算出每台机器在这个环上的位置; z再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value)存储到该机器上,如下图所示。
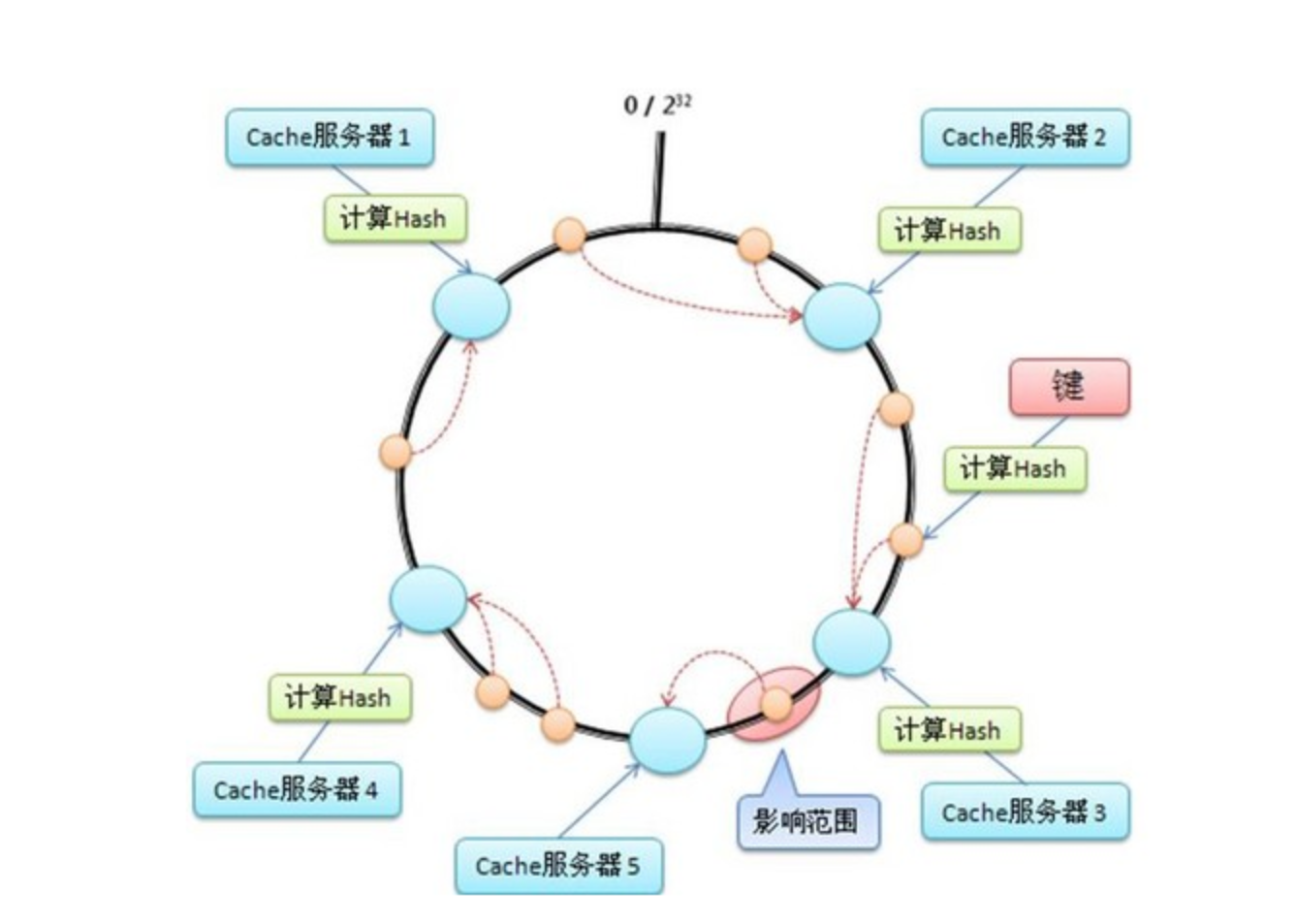
首先计算出每台cache服务器在环上的位置(图中浅蓝色的大圆圈),然后每来一个key计算出value填到环上的位置(图中橙色的小圆圈),然后顺时针走,遇到的第一个机器,就是要存储的机器
这里的关键点是:当机器数N变化时,其他机器在环上的位置并不会发生改变。这样只有增加/减少的那台机器附近的数据会失效,其他机器上的数据还是有效的。
三 数据倾斜问题
当机器不很多时,很可能出现几台机器在环上面贴的很近,分布很不均匀。这将会导致大部门数据集中在某几台机器上。
为了解决这个问题,可以引入"虚拟机器"的概念,也就是说,一台机器需要在环上映射出多个位置。比如我们用机器的ip来hash,那么我们可以在ip后面加几个编号,形如ip_1, ip_2, ip_3... 这样就实现了一台物理机器映射出了多个虚拟机器的编号。
数据首先映射到"虚拟机器"上,再从"虚拟机器"映射到物理机器上。因为虚拟机器可以很多,在环上均匀分布,从而保证数据相对均匀地分布在物理机器上。
四 zk的引入
上面我们提到了服务器的机器数N的变化,那么如何通知到客户端呢
一种笨方法就是手动,当机器数N变化,重新配置客户端,重启客户端。
另外一种,引入zk,服务器的节点列表注册到zk上面,客户端监听zk。发现节点数发生变化,自动更新自己的配置。
当然不用zk用一个其他的中心节点也可以,只要能实现这种更改的通知即可(也即分布式服务协调)
分布式缓存 - hash环/一致性hash的更多相关文章
- 分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- 搞懂分布式技术11:分布式session解决方案与一致性hash
搞懂分布式技术11:分布式session解决方案与一致性hash session一致性架构设计实践 原创: 58沈剑 架构师之路 2017-05-18 一.缘起 什么是session? 服务器为每个用 ...
- 分方式缓存常用的一致性hash是什么原理
分方式缓存常用的一致性hash是什么原理 一致性hash是用来解决什么问题的?先看一个场景有n个cache服务器,一个对象object映射到哪个cache上呢?可以采用通用方法计算object的has ...
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- 追踪分布式Memcached默认的一致性hash算法
<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255) ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
- 图解一致性hash算法和实现
更多内容,欢迎关注微信公众号:全菜工程师小辉.公众号回复关键词,领取免费学习资料. 一致性hash算法是什么? 一致性hash算法,是麻省理工学院1997年提出的一种算法,目前主要应用于分布式缓存当中 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
随机推荐
- Luogu5072 [Ynoi2015]盼君勿忘 【莫队】
题目描述:对于一个长度为\(n\)的序列,\(m\)次询问\(l,r,p\),计算\([l,r]\)的所有子序列的不同数之和\(\mathrm{mod} \ p\). 数据范围:\(n,m,a_i\l ...
- 使用vscode快速建立vue模板
当我们希望每次新建.vue文件后,vscode能够根据配置,自动生成我们想要的内容. 打开vscode编辑器,依次选择“文件 -> 首选项 -> 用户代码片段”,此时,会弹出一个搜索框,我 ...
- Vue源码分析(二) : Vue实例挂载
Vue源码分析(二) : Vue实例挂载 author: @TiffanysBear 实例挂载主要是 $mount 方法的实现,在 src/platforms/web/entry-runtime-wi ...
- golang通过ssh实现远程文件传输
使用ssh远程操作文件, 主要是创建ssh, 直接上代码 import ( "fmt" "github.com/pkg/sftp" "golang.o ...
- VUE -- iview table 组件 中使用 upload组件 上传组件 on render 事件不会触发问题
碰到的问题是: upload 组件在 on中写的监听事件不会被触发 在 props 中来监听:==>
- Android简单实现滚动悬停效果
import android.content.Context; import android.support.design.widget.TabLayout; import android.suppo ...
- VS2015编译GDAL库出现宏重复定义 snprintf: 宏重定义
E:\OpenSourceGraph\gdal-1.10.0\gdal\port cpl_config.h 20行 #define HAVE_VPRINTF 1#define HAVE_ ...
- 【Leetcode_easy】617. Merge Two Binary Trees
problem 617. Merge Two Binary Trees 参考 1. Leetcode_easy_617. Merge Two Binary Trees; 完
- 【ARTS】01_36_左耳听风-201900715~201900721
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- 股票PE的应用
投资股票前,需要先分析公司,然后做估值.最后拿这估值对比现在它的现价,如果现价远低于估值,那就买入,因为这时候相当于打折价. 分析要怎么分析,估值要怎么估值 就像拿不同的旋头去维修不同的电器是一样的原 ...