Linux编程之文件锁
1. 使用 fcntl() 给记录加锁
使用 fcntl() 能够在一个文件的任意部分上放置一把锁,这个文件部分既可以是一个字节,也可以是整个文件。这种形式的文件加锁通常被称为记录加锁,但这种称谓是不恰当的,因为 UNIX 系统上的文件是一个字节序列,并不存在记录边界的概念,文件记录概念只存在于应用程序中。
通常,fcntl() 会被用来锁住文件中与应用程序定义的记录边界对应的字节范围。
如下图演示了如何使用记录锁来同步两个进程对一个文件中的同一块区域的访问。

用来创建或删除一个文件锁的 fcntl() 调用的常规形式如下:
struct flock flocstr;
/* Set fields of 'flockstr' to describe lock to be placed or removed */
fcntl(fd, cmd, &flockstr); /* Place lock defined by 'fl' */
- fd 参数是一个打开着的文件描述符,它引用了待加锁的文件。
flock 结构
flock 结构定义了待获取或删除的锁,其定义如下:
struct flock {
short l_type; // Lock type: F_RDLCK, F_WRLCK, F_UNLCK
short l_whence; // How to interpret 'l_start': SEEK_SET,
// SEEK_CUR, SEEK_END
off_t l_start; // Offset where the lock begins
off_t l_len; // Number of bytes to lock; 0 means "until EOF"
pid_t l_pid; // Process preventing our lock (F_GETLK only)
};
- l_type: 表示需放置的锁的类型:
- F_RDLCK:放置一把读锁
- F_WRLCK:放置一把写锁
- F_UNLCK:删除一个既有锁
- l_whence、l_start、l_len:这三个字段一起指定了待加锁的字节范围。
- 前两个字段类似于传入 lseek() 的 whence 和 offset 参数。
- l_start 字段指定了文件中的一个偏移量,具体含义需根据如下规则来解释:
- 当 l_whence 为 SEEK_SET 时,为文件的起始位置
- 当 l_whence 为 SEEK_CUR 时,为当前的文件偏移量
- 当 l_whence 为 SEEK_END 时,为文件的结尾位置
- l_len 字段包含一个指定待加锁的字节数的整数,其起始位置由 l_whence 和 l_start 定义。对文件结尾之后并不存在的字节进行加锁时可以的,但无法对在文件起始文件之前的字节进行加锁。
通常,应用程序应该只对所需的最小字节范围进行加锁,这样其他进程就能够同时对同一个文件的不同区域进行加锁,进而取得更大的并发性。
将 l_len 指定为 0 具有特殊含义,即 "对范围从 l_start 和 l_whence 确定的起始位置到文件结尾位置之内的所有字节加锁,不管文件增长到多大"。这种处理方式在无法提前知道向一个文件中加入多少个字节的情况下是比较方便的。要锁住整个文件则可以将 l_whence 指定为 SEEK_SET,并将 l_start 和 l_len 都设为 0.
cmd 参数
fcntl() 在操作文件锁时其 cmd 参数的可能取值有以下三个,其中前两个值用来获取和释放锁。
- F_SETLK:
获取(l_type 是 F_RDLCK 或 F_WRLCK)或释放(l_type 是 F_UNLCK)由 flockstr 指定的字节上的锁。如果另一个进程持有了一把待加锁的区域中任意部分上的不兼容的锁时,fcntl() 就会失败并返回 EAGAIN 错误。 - F_SETLKW:
这个值与 F_SETLK 是一样的,除了在有另一个进程持有一把待加锁的区域中任意部分上的不兼容的锁时,调用就会阻塞直到锁的请求得到满足。如果正在处理一个信号并且没有指定 SA_RESTART,那么 F_SETLKW 操作就可能会被中断(即失败并返回 EINTR 错误)。 - F_GETLK:
检测是否能够获取 flockstr 指定的区域上的锁,但实际上不获取这把锁。l_type 字段的值必须为 F_RDLCK 或 F_WRLCK。flockstr 结构是一个值-结果参数,在返回时它包含了有关是否能够放置指定的锁的信息。如果允许加锁(即在指定的文件区域上不存在不兼容的锁),那么在 l_type 字段中会返回 F_UNLCK,并且剩余的字段会保持不变。如果在区域上存在一个或多个不兼容的锁,那么 flockstr 会返回与那些锁中其中一把锁(无法确定是哪把锁)相关的信息,包括其类型(l_type)、字节范围(l_start 和 l_len;l_whence 总是返回为 SEEK_SET)以及持有这把锁的进程的进程 ID(l_pid)。
在使用 F_GETLK 之后接着使用 F_SETLK 或 F_SETLKW 的话就可能会出现竞争条件,因为在执行后面一个操作时,F_GETLK 返回的信息可能已经过时了,因此 F_GETLK 的实际作用比其一开始看起来的作用要小很多。即使 F_GETLK 表示可以放置一把锁,仍然需要为 F_SETLK 返回一个错误或 F_SETLKW 阻塞做好准备。
锁获取和释放的细节
获取和释放由 fcntl() 创建的锁需要注意以下几点:
- 解锁一块文件区域总是会立即成功。即使当前并不持有一块区域上的锁,对这块区域解锁也不是一个错误。
- 在任何一个时刻,一个进程只能持有一个文件的某个特定区域上的一种锁。在之前已经锁住的区域上放置一把新锁会导致不发生任何事情(新锁的类型与既有锁的类型是一样的)或原子地将既有锁转换成新模式。在后一种情况中,当将一个读锁转换成写锁时需要为调用返回一个错误(F_SETLK)或阻塞(F_SETLKW)做好准备。
- 一个进程永远都无法将自己锁在一个文件区域之外,即使通过多个引用同一文件的文件描述符放置锁也是如此。
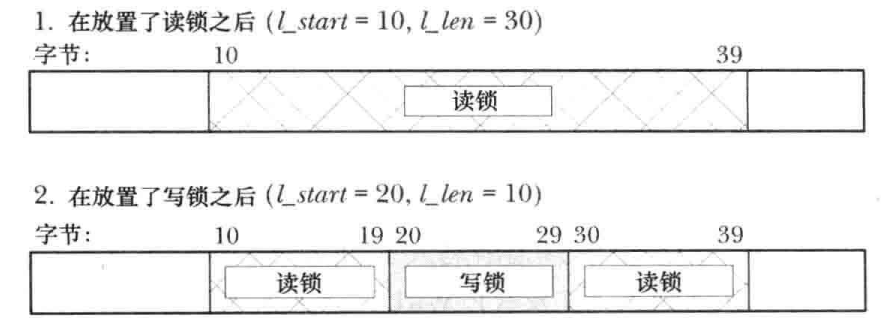
- 在已经持有的锁中间放置一把模式不同的锁会产生三把锁:在新锁的两端会创建两个模式为之前模式的更小一点的锁。于此相反的是,获取与模式相同的一把既有锁相邻或重叠的第二把锁会产生单个覆盖两个锁的合并区域的聚合锁。除此之外,还存在其他的组合情况。如对一个大型既有锁的中间的一个区域进行解锁会在已解锁区域的两端产生两个更小一点的已锁住区域。如果一个新锁与一个模式不同的既有锁重叠了,那么既有锁就会收缩,因为重叠的字节会合并仅新锁中。如下图为在同一个进程中使用一把写锁分割一个既有读锁:
1.1 死锁
当两个进程拒绝对方的加锁请求时会死锁
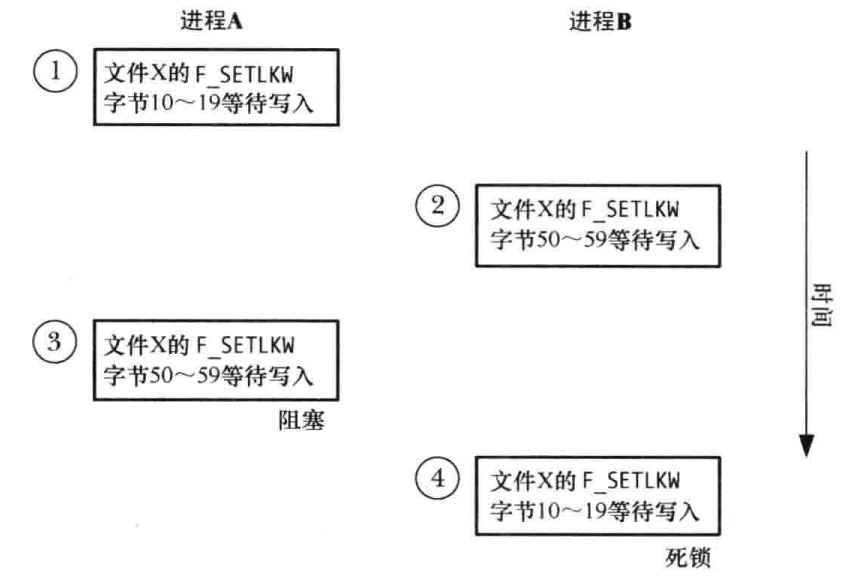
如上图场景中,每个进程的第二个锁请求会被另一个进程持有的锁阻塞。这种场景被称为死锁。如果内核不对这种情况进行抑制,那么会导致两个进程永远阻塞。为避免这种情况,内核会对通过 F_SETLKW 发起的每个新锁请求进行检查以判断是否会导致死锁。如果会导致死锁,那么内核就会选中其中一个被阻塞的进程使其 fcntl() 调用解除阻塞并返回错误 EDEADLK。因此使用 F_SETLKW 的所有进程都必须要为处理 EDEADLK 错误做好准备。
1.2 示例:一个交互式加锁程序
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MAX_LINE 100
static void displaycmdfmt(void)
{
printf("\n Format: cmd lock start length [whence]\n\n");
printf(" 'cmd' is 'g' (GETLK), 's' (SETLK), or 'w' (SETLKW)\n");
printf(" 'lock' is 'r' (READ), 'w' (WRITE), or 'u' (UNLOCK)\n");
printf(" 'start' and 'length' specify byte range to lock\n");
printf(" 'whence' is 's' (SEEK_SET, default), 'c' (SEEK_CUR), "
"or 'e' (SEEK_END)\n\n");
}
int main(int argc, char *argv[])
{
int fd, numRead, cmd, status;
char lock, cmdCh, whence, line[MAX_LINE];
struct flock fl;
long long len, st;
fd = open(argv[1], O_RDWR);
if (fd == -1)
{
printf("open failed");
exit(-1);
}
for ( ;; ) {
printf("Enter ? for help\n");
printf("PID=%ld> ", (long) getpid());
fflush(stdout);
if (fgets(line, MAX_LINE, stdin) == NULL)
{
printf("stdin EOF");
exit(EXIT_SUCCESS);
}
line[strlen(line) - 1] = '\0';
if (*line == '\0')
continue;
if (line[0] == '?')
{
displaycmdfmt();
continue;
}
whence = 's';
numRead = sscanf(line, "%c %c %lld %lld %c", &cmdCh, &lock,
&st, &len, &whence);
fl.l_start = st;
fl.l_len = len;
if (numRead < 4 || strchr("gsw", cmdCh) == NULL ||
strchr("rwu", lock) == NULL || strchr("sce", whence) == NULL) {
printf("Invalid command!\n");
continue;
}
cmd = (cmdCh == 'g') ? F_GETLK :
(cmdCh == 's') ? F_SETLK : F_SETLKW;
fl.l_type = (lock == 'r') ? F_RDLCK :
(lock == 'w') ? F_WRLCK : F_UNLCK;
fl.l_whence = (whence == 'c') ? SEEK_CUR :
(whence == 'e') ? SEEK_END : SEEK_SET;
status = fcntl(fd, cmd, &fl);
if (cmd == F_GETLK) {
if (status == -1) {
printf("fcntl - F_GETLK failed");
exit(-1);
} else {
if (fl.l_type == F_UNLCK) {
printf("[PID=%ld] Lock can be placed\n", (long) getpid());
} else {
printf("[PID=%ld] Denied by %s lock on %lld:%lld "
"(held by PID %ld)\n", (long) getpid(),
(fl.l_type == F_RDLCK) ? "READ" : "WRITE",
(long long) fl.l_start,
(long long) fl.l_len, (long) fl.l_pid);
}
}
} else { // F_SETLK, F_SETLKW
if (status == 0) {
printf("[PID=%ld] %s\n", (long) getpid(),
(lock == 'u') ? "unlocked" : "got lock");
} else if (errno == EAGAIN || errno == EACCES) { // F_SETLK
printf("[PID=%ld] failed (incompatible lock)\n",
(long) getpid());
} else if (errno == EDEADLK) { // F_SETLKW
printf("[PID=%ld] failed (deadlock)\n",
(long) getpid());
} else {
printf("fcntl - F_SETLK(w) failed");
exit(-1);
}
}
}
}
如下,运行两个实例来在同一个大小为 100 字节的文件(tfile.txt)上放置锁。
首先启动第一个实例(进程A)并在文件中 0~39 字节区域上放置一把读锁。
# ls -l tfile.txt
-rwxr--r-- 1 rong rong 100 Jun 17 01:49 tfile.txt
PID=3624> s r 0 40
[PID=3624] got lock
接着启动程序的第二个实例(进程B)并在文件中第 70 个字节到文件结尾的区域上放置一把读锁。
# ./i_fcntl_locking tfile.txt
Enter ? for help
PID=3764> s r -30 0 e
[PID=3764] got lock
运行 running i_fcntl_locking.c 时被准予的和排队的加锁请求的状态图
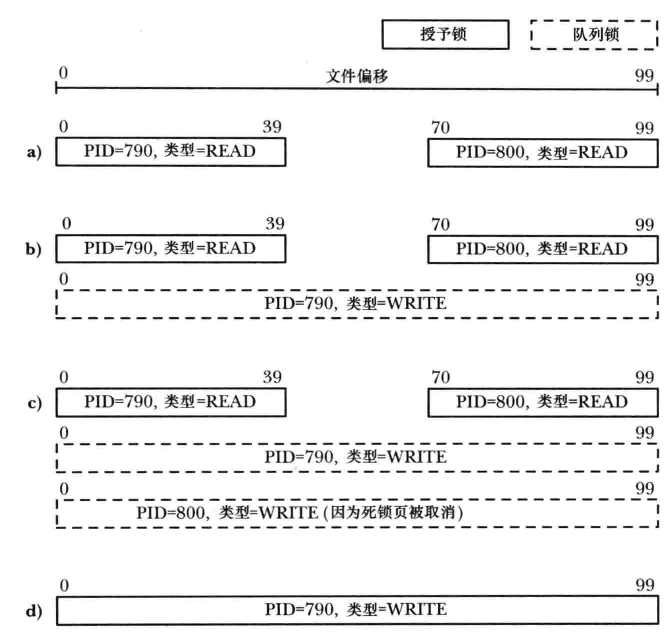
此刻出现上图中 a 部分的情形,其中进程 A (进程 ID 为 3624)和进程 B(进程 ID 为 3764)持有了文件的不同部分上的锁。
现在回到进程 A 让其尝试在整个文件上放置一把写锁。首先通过 F_GETLK 检测是否可以加锁并得到存在一个冲突的锁的信息。接着尝试通过 F_SETLK 放置一把写锁,当这个操作也会失败。最后尝试通过 F_SETLKW 放置一把锁,这次将会阻塞。
PID=3624> g w 0 0
[PID=3624] Denied by READ lock on 70:0 (held by PID 3764)
PID=3624> s w 0 0
[PID=3624] failed (incompatible lock)
PID=3624> w w 0 0
// 此时进程 A 在这里阻塞
此刻出现了上图中 b 部分的情形,其中进程 A 和进程 B 分别持有了文件的不同部分上的锁,并且进程 A 还有一个排着队的对整个文件的加锁请求。
接着继续在进程 B 中尝试在整个文件上放置一把写锁。首先使用 F_GETLK 检测一下是否可以加锁并得到存在一个冲突的锁的信息。接着尝试使用 F_SETLKW 加锁。
PID=3764> g w 0 0
[PID=3764] Denied by READ lock on 0:40 (held by PID 3624)
PID=3764> w w 0 0
[PID=3764] failed (deadlock)
上图中的 c 部分给出了当进程 B 发起一个在整个文件上放置一把写锁的阻塞请求发生的情形: 死锁。此刻内核将会选择让其中一个加锁请求失败 -- 在本例中进程 B 的请求将会被选中并从其 fcntl() 调用中接收到 EDEADLK 错误。
接着继续在进程 B 中删除其在文件上的所有锁。
// 进程 B 删除所有锁
PID=3764> s u 0 0
[PID=3764] unlocked
// 接着进程 A 即可在之前的阻塞中返回,并将整个文件加上写锁
PID=3624> w w 0 0
// 从这里的阻塞中返回
[PID=3624] got lock
注:即使进程 B 的死锁请求被取消之后它仍然持有了其他的锁,因此进程 A 的排着队的加锁请求仍然会阻塞。进程 A 加锁请求只有在进程 B 删除了其持有的锁之后才会被准予,这就出现了上图中 d 的情形。
1.3 锁的限制和性能
获取和释放记录锁的速度有多快?这些操作的速度取决于用来维护记录锁的内核数据结构和具体的某一把锁在这个数据结构中所处的位置。首先考虑几点能够影响其设计的需求。
- 内核需要能够将一个新锁和任意位于新锁任意一端的模式相同的既有锁(由同一个进程持有)合并起来。
- 新锁可能会完全取代调用进程持有的一把或多把即有锁。内核需要容易地定位出所有这些锁。
- 当在一把既有锁的中间创建一个模式不同的新锁时,分隔既有锁的工作应该是比较简单的。
用来维护锁相关信息的内核数据结构需要被设计成满足这些需求。每个打开着的文件都有一个关联链表,链表中保存着该文件上的锁。列表中的锁会先按照进程 ID 再按照起始偏移量来排序。下图即为这样的单个文件上的记录锁列表:
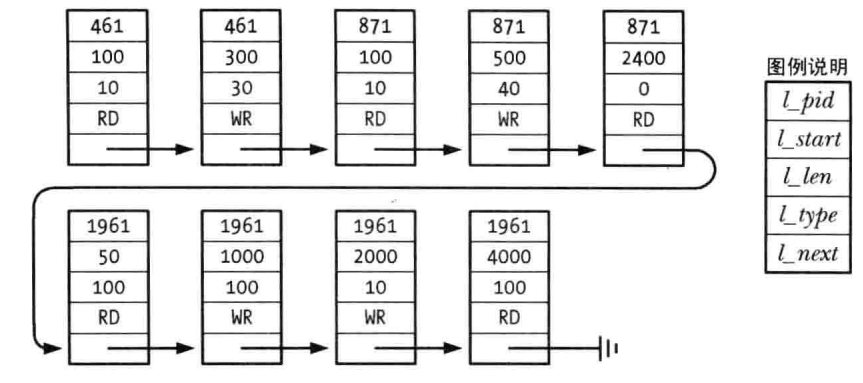
每次需要在这个数据结构中添加一把新锁时,内核都必须要检查是否与文件上的既有锁有冲突。这个搜索过程是从列表头开始顺序开展的。
假设有大量的锁随机地分布在很多进程中,那么就可以说,添加或删除一个锁所需的时间与文件上已有的锁的数量之间大概是一个线性的关系。
1.4 锁继承和释放的语义
- 由 fork() 创建的子进程不会继承记录锁。
- 记录锁在 exec() 中会得到保留。(但需要注意 close-on-exec 标记的作用)。
- 一个进程中的所有线程会共享同一组记录锁。
- 记录锁同时与一个进程和一个 i-node 关联。从这种关联关系可以得出两个结果:一是当一个进程终止之后,其所有记录锁会被释放;二是当一个进程关闭了一个文件描述符之后,进程持有的对应文件上的所有锁会被释放,不管这些锁是通过哪个文件描述符获得的。如下示例:
struct flock fl;
fl.l_type = F_WRLCK;
fl.l_whence = SEEK_SET;
fl.l_start = 0;
fl.l_len = 0;
fd1 = open("testfile", O_RDWR);
fd2 = open("testfile", O_RDWR);
if (fcntl(fd1, cmd, &fl) == -1)
exit(-1);
// 这里会释放调用进程持有的 testfile 文件之上的锁,
// 尽管这把锁是通过文件描述符 fd1 获得的
close(fd2);
不管引用同一个文件的各个描述符是如何获得的以及不管描述符是如何被关闭的,上面最后一点中描述的语义都是适用的。如 dup()、dup2() 以及 fcntl() 都可以用来获取一个打开着的文件描述符的副本。除了执行一个显式的 close() 之外,一个描述符在设置了 close-on-exec 标记时会被一个 exec() 调用关闭,或者也可以通过一个 dup2() 调用来关闭其第二个文件描述符参数,当前前提是该描述符已经被打开了。
1.5 锁定饿死和排队加锁请求的优先级
一个进程是否能够等待以便在由一系列进程放置读锁的同一块区域上放置一把写锁并因此可能会导致饿死?在 Linux 上,一系列的读锁确实能够导致一个被阻塞的写锁饿死,甚至会无限地饿死。
Linux 的规则如下:
- 排队的锁请求被准予的顺序是不确定的。如果多个进程正在等待加锁,那么它们被满足的顺序取决于进程的调度。
- 写者并不比读者拥有更高的优先权,反之亦然。
Linux编程之文件锁的更多相关文章
- 牛人整理分享的面试知识:操作系统、计算机网络、设计模式、Linux编程,数据结构总结 转载
基础篇:操作系统.计算机网络.设计模式 一:操作系统 1. 进程的有哪几种状态,状态转换图,及导致转换的事件. 2. 进程与线程的区别. 3. 进程通信的几种方式. 4. 线程同步几种方式.(一定要会 ...
- 【转】牛人整理分享的面试知识:操作系统、计算机网络、设计模式、Linux编程,数据结构总结
基础篇:操作系统.计算机网络.设计模式 一:操作系统 1. 进程的有哪几种状态,状态转换图,及导致转换的事件. 2. 进程与线程的区别. 3. 进程通信的几种方式. 4. 线程同步几种方式.(一定要会 ...
- Linux 编程中的API函数和系统调用的关系【转】
转自:http://blog.chinaunix.net/uid-25968088-id-3426027.html 原文地址:Linux 编程中的API函数和系统调用的关系 作者:up哥小号 API: ...
- linux编程获取本机网络相关参数
getifaddrs()和struct ifaddrs的使用,获取本机IP 博客分类: Linux C编程 ifaddrs结构体定义如下: struct ifaddrs { struct ifad ...
- 面试知识:操作系统、计算机网络、设计模式、Linux编程,数据结构总结
基础篇:操作系统.计算机网络.设计模式 一:操作系统 1. 进程的有哪几种状态,状态转换图,及导致转换的事件. 2. 进程与线程的区别. 3. 进程通信的几种方式. 4. 线程同步几种方式.(一定要会 ...
- Linux编程简介
Linux编程可以分为Shell(如BASH.TCSH.GAWK.Perl.Tcl和Tk等)编程和高级语言(C语言,C++语言,java语言等)编程,Linux程序需要首先转化为低级机器语言即所谓的二 ...
- Linux编程return与exit区别
Linux编程return与exit区别 exit 是用来结束一个程序的执行的,而return只是用来从一个函数中返回. return return 表示从被调函数返回到主调函数继续执行,返回时可附 ...
- linux 编程技术
linux 编程技术No.1前期准备工作 GCC的编译过程分为预处理.生成汇编代码.生成目标代码和链接成可执行文件等4个步骤. 使用vim编写C 文件 : [lining@localhost prog ...
- Linux编程之给你的程序开后门
这里说的"后门"并不是教你做坏事,而是让你做好事,搭建自己的调试工具更好地进行调试开发.我们都知道,当程序发生异常错误时,我们需要定位到错误,有时我们还想,我们在不修改程序的前提下 ...
随机推荐
- 向PHP发送HTTP-Get请求
1.get.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- \ n是将输出换行符的javascript的转义符。
\ n是将输出换行符的javascript的转义符.<br/>是表示新文本行的HTML标签.JavaScript是一种脚本语言,而HTML是一种标记语言.如果使用javascript的文档 ...
- OLE使用
ABAP操作EXCEL有多重方法,今天记录一下OLE,具体步骤如下: 1. 首先要上载EXCEL模板 事物代码:SMW0,具体步骤参考 本博客 http://www.cnblogs.com/caizj ...
- VS2012隐藏输出窗口的快捷键是什么。
纯属用键盘无法直接关闭这个窗口.有一个变通的方法是,先切换到这个输出窗口(标题呈现高亮的蓝色),使用Alt+W打开窗口菜单,选H隐藏就可以关闭.使用Ctrl+Alt+o可再次打开.按ESC就可以了.我 ...
- Java学习笔记【十一、序列化】
序列化的条件 实现Serializable接口 所有属性必须是可序列化的,或标记为transient(不做序列化) 序列化-将对象输出为序列化文件 ObjectOutputStream 反序列化-将序 ...
- c++11 移动语义move semantics
performance, expensive object copies move semantics, temporary objects implemented with rvalue refer ...
- Select,poll,epoll复用
Select,poll,epoll复用 1)select模块以列表的形式接受四个参数,分别是可读对象,可写对象,产生异常的对象,和超时设置.当监控符对象发生变化时,select会返回发生变化的对象列表 ...
- Redis08-击穿&穿透&雪崩&spring data redis
一.常见概念 击穿: 概念:redis作为缓存,设置了key的过期时间,key在过期的时候刚好出现并发访问,直接击穿redis,访问数据库 解决方案:使用setnx() ->相当于一把锁,设置的 ...
- 从输入URL到页面加载全过程
从简单讲: 1. DNS域名解析:2. 建立TCP连接:3. 发送HTTP请求:4. 返回响应结果:5. 关闭TCP连接:6. 浏览器解析HTML:7. 浏览器布局渲染: 大家基本上都知 ...
- 第八章 watch监听 85 computed-计算属性的使用和3个特点
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...