用Python+Aria2写一个自动选择最优下载方式的E站爬虫
前言
E站爬虫在网上已经有很多了,但多数都只能以图片为单位下载,且偶尔会遇到图片加载失败的情况;熟悉E站的朋友们应该知道,E站许多资源都是有提供BT种子的,而且通常打包的是比默认看图模式更高清的文件;但如果只下载种子,又会遇到某些资源未放种/种子已死的情况。本文将编写一个能自动检测最优下载来源并储存到本地的E站爬虫,该爬虫以数据库作为缓冲区,支持以后台服务方式运行,可以轻易进行分布式扩展,并对于网络错误有良好的鲁棒性。
环境要求
Python3,MySQL,安装了Aria2并开启PRC远程访问
Aria2是一个强大的命令行下载工具,并支持web界面管理,可以运行在window和Linux下。介绍及安装使用可参见
基础配置
在MySQL中按如下格式建表
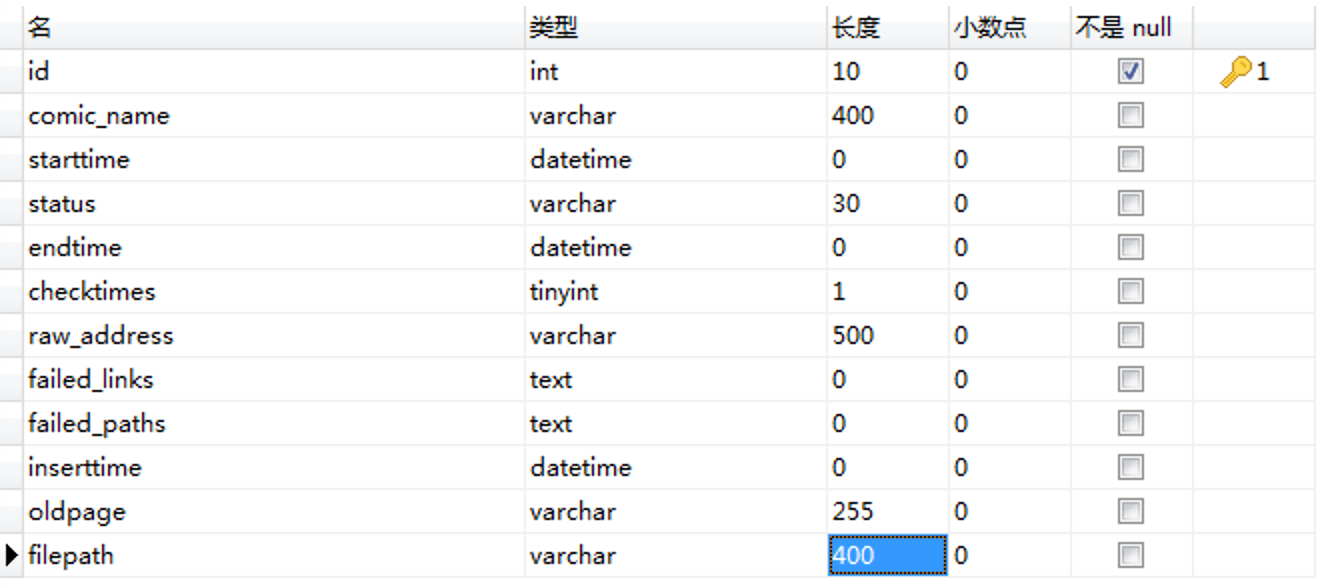
| 字段名称 | 字段意义 |
| id | id主键 |
| comic_name | 本子名称 |
| starttime | 开始下载的时间 |
| endtime | 下载结束的时间 |
| status | 当前下载状态 |
| checktimes | 遇错重试次数 |
| raw_address | e-hentai页面地址 |
| failed_links | 记录由于网络波动暂时访问失败的页面地址 |
| failed_paths | 记录失败页面地址对应的图片本地路径 |
| inserttime | 记录地址进入到数据库的时间 |
| oldpage | 存放Aria2条目的gid |
| filepath | bt下载路径 |
本文之后假设MySQL数据库名为comics_local,表名为comic_urls
aria2配置为后台服务,假设RPC地址为:127.0.0.1:6800,token为12345678
需要安装pymysql, requests, filetype, zipfile, wget等Python包
pip install pymysql requests filetype zipfile wget
项目代码
工作流程
整个爬虫服务的工作流程如下:用户将待抓取的E站链接(形式如 https://e-hentai.org/g/xxxxxxx/yyyyyyyyyy/ )放入数据表的raw_address字段,设置状态字段为待爬取;爬取服务可以在后台轮询或回调触发,提取出数据库中待爬取的链接后访问页面,判断页面里是否提供了bt种子下载,如有则下载种子并传给Aria2下载,如无则直接下载图片(图片优先下载高清版)。
在图片下载模式下,如果一切正常,则结束后置状态字段为已完成;如出现了问题,则置字段为相应异常状态,在下次轮询/调用时进行处理。
在bt下载模式下,另开一个后台进程定时询问Aria2的下载状态,在Aria2返回下载完成报告后解压目标文件,并置状态字段为已完成;如出现了种子已死等问题,则删除Aria2任务并切换到图片下载模式。
数据库操作模块
该模块包装了一些MySQL的操作接口,遵照此逻辑,MySQL可以换成其他数据库,如Redis,进而支持分布式部署。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: sql_module.py Created on Sun Sep 22 23:24:39 2019 @author: qjfoidnh
""" import pymysql
from pymysql.err import IntegrityError class MySQLconn_url(object):
def __init__(self): self.conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='username',
passwd='password',
db='comics_local'
)
self.conn.autocommit(True) #开启自动提交,生产环境不建议数据库DBA这样做
self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
#让MySQL以字典形式返回数据 def __del__(self): self.conn.close() #功能:取指定状态的一条数据
def fetchoneurl(self, mode="pending", tabname='comic_urls'): sql = "SELECT * FROM %s \
WHERE status = '%s'" %(tabname, mode)
self.conn.ping(True) #mysql长连接防止timeut自动断开
try:
self.cursor.execute(sql)
except Exception as e:
return e
else:
item = self.cursor.fetchone()
if not item:
return None
if mode=="pending" or mode=='aria2':
if item['checktimes']<3:
sql = "UPDATE %s SET starttime = now(), status = 'ongoing' \
WHERE id = %d" %(tabname, item['id'])
else:
sql = "UPDATE %s SET status = 'error' \
WHERE id = %d" %(tabname, item['id'])
if mode=='aria2':
sql = "UPDATE %s SET status = 'pending', checktimes = 0, raw_address=CONCAT('chmode',raw_address) \
WHERE id = %d" %(tabname, item['id'])
self.cursor.execute(sql)
return 'toomany'
elif mode=="except":
sql = "UPDATE %s SET status = 'ongoing' \
WHERE id = %d" %(tabname, item['id'])
try:
self.cursor.execute(sql)
except Exception as e:
self.conn.rollback()
return e
else:
return item #功能:更新指定id条目的状态字段
def updateurl(self, itemid, status='finished', tabname='comic_urls'):
sql = "UPDATE %s SET endtime = now(),status = '%s' WHERE id = %d" %(tabname, status, itemid)
self.conn.ping(True)
try:
self.cursor.execute(sql)
except Exception as e:
self.conn.rollback()
return e
else:
return itemid #功能:更新指定id条目状态及重试次数字段
def reseturl(self, itemid, mode, count=0, tabname='comic_urls'): sql = "UPDATE %s SET status = '%s', checktimes=checktimes+%d WHERE id = %d" %(tabname, mode, count, itemid)
self.conn.ping(True)
try:
self.cursor.execute(sql)
except Exception as e:
print(e)
self.conn.rollback()
return e
else:
return itemid #功能:将未下载完成图片的网址列表写入数据库,
def fixunfinish(self, itemid, img_urls, filepaths, tabname='comic_urls'): img_urls = "Š".join(img_urls) #用不常见拉丁字母做分隔符,避免真实地址中有分隔符导致错误分割
filepaths = "Š".join(filepaths)
sql = "UPDATE %s SET failed_links = '%s', failed_paths = '%s', status='except' WHERE id = %d" %(tabname, img_urls, filepaths, itemid)
self.conn.ping(True)
try:
self.cursor.execute(sql)
except Exception as e:
self.conn.rollback()
return e
else:
return 0 #功能:在尝试完一次未完成补全后,更新未完成列表
def resetunfinish(self, itemid, img_urls, filepaths, tabname='comic_urls'):
failed_num = len(img_urls)
if failed_num==0:
sql = "UPDATE %s SET failed_links = null, failed_paths = null, status = 'finished', endtime = now() WHERE id = %d" %(tabname, itemid)
else:
img_urls = "Š".join(img_urls) #用拉丁字母做分隔符,避免真实地址中有分隔符导致错误分割
filepaths = "Š".join(filepaths)
sql = "UPDATE %s SET failed_links = '%s', failed_paths = '%s', status = 'except' WHERE id = %d" %(tabname, img_urls, filepaths, itemid)
self.conn.ping(True)
try:
self.cursor.execute(sql)
except Exception as e:
self.conn.rollback()
return e
else:
return failed_num #功能:为条目补上资源名称
def addcomicname(self, address, title, tabname='comic_urls'):
sql = "UPDATE %s SET comic_name = '%s' WHERE raw_address = '%s'" %(tabname, title, address) #由于调用地点处没有id值,所以这里用address定位。也是本项目中唯二处用address定位的
self.conn.ping(True)
try:
self.cursor.execute(sql)
except IntegrityError:
self.conn.rollback()
sql_sk = "UPDATE %s SET status = 'skipped' \
WHERE raw_address = '%s'" %(tabname, address)
self.cursor.execute(sql_sk)
return Exception(title+" Already downloaded!")
except Exception as e:
self.conn.rollback()
return e
else:
return 0 #功能:通过网址查询标识Aria2里对应的gid
def fetchonegid(self, address, tabname='comic_urls'):
sql = "SELECT * FROM %s \
WHERE raw_address = '%s'" %(tabname, address)
self.conn.ping(True)
try:
self.cursor.execute(sql)
except Exception as e:
return e
else:
item = self.cursor.fetchone()
if not item:
return None
else:
return item.get('oldpage') mq = MySQLconn_url()
初级处理模块
该模块对E站链接进行初步处理,包括获取资源名称,指定下载类型,以及调用次级处理模块,并返回给主函数表示处理结果的状态量。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: init_process.py Created on Sun Sep 22 21:20:54 2019 @author: qjfoidnh
""" from settings import *
from tools import Get_page, Download_img
from second_process import Ehentai
from checkdalive import removetask
from sql_module import mq
import time
import os #功能:尝试下载未完成列表里的图片到指定路径
def fixexcepts(itemid, img_urls, filepaths):
img_urls_new = list()
filepaths_new = list()
img_urls = img_urls.split("Š") #从字符串还原回列表
filepaths = filepaths.split("Š")
for (imglink,path) in zip(img_urls,filepaths):
try:
content = Get_page(imglink, cookie=cookie_ehentai(imglink))
if not content:
img_urls_new.append(imglink)
filepaths_new.append(path)
continue
time.sleep(10)
try:
img_src = content.select_one("#i7 > a").get('href') #高质量图
except AttributeError: #如果高质量图没提供资源
img_src = content.select_one("img[id='img']").get("src") #一般质量图
src_name = content.select_one("#i2 > div:nth-of-type(2)").text.split("::")[0].strip() #图文件名
raw_path = path
if os.path.exists(raw_path+'/'+src_name):
continue
http_code = Download_img(img_src, raw_path+'/'+src_name, cookie=cookie_ehentai(imglink))
if http_code!=200:
raise Exception("Network error!")
except Exception:
img_urls_new.append(imglink)
filepaths_new.append(path)
result = mq.resetunfinish(itemid, img_urls_new, filepaths_new)
return result class DownEngine:
def __init__(self):
pass #功能:根据传入地址,选择优先下载模式。获取资源标题,写入数据库,并调用次级处理模块
def engineEhentai(self, address):
if 'chmode' in address:
mode='normal'
removetask(address=address)
else:
mode='bt'
address = address.replace('chmode', '')
content = Get_page(address, cookie=cookie_ehentai(address))
if not content:
return 2
warning = content.find('h1', text="Content Warning")
#e站对部分敏感内容有二次确认
if warning:
address += '?nw=session'
content = Get_page(address, cookie=cookie_ehentai(address))
if not content:
return 2
title = content.select_one("h1[id='gj']").text
if not len(title): #有些资源没有日文名,则取英文名
title = content.select_one("h1[id='gn']").text
if not len(title):
return 2 title = title.replace("'",'''"''') #含有单引号的标题会令sql语句中断
title_st = mq.addcomicname(address, title)
if type(title_st)==Exception:
return title_st ehentai = Ehentai(address, title, mode=mode)
result = ehentai.getOthers()
return result
次级处理模块
该模块由初级处理模块调用,其通过预设规则寻找给定资源对应的bt种子/所有图片页面,然后进行下载。bt下载模式直接将种子文件和下载元信息传给Aria2,图片下载模式按顺序下载资源里的每一张图片。
并未引入grequests等多协程库来进行请求是因为E站会封禁短时间内过频访问的IP;事实上,我们甚至还需要设置下载间隔时间,如果有更高的效率要求,可考虑缩短下载间隔以及开启多个使用不同代理的进程。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: second_process.py Created on Mon Sep 23 20:35:48 2019 @author: qjfoidnh
""" import time
import datetime
import requests
from tools import Get_page, Download_img, postorrent
from checkdalive import getinfos
from settings import proxies
from settings import *
import re
import os
from logger_module import logger formatted_today=lambda:datetime.date.today().strftime('%Y-%m-%d')+'/' #返回当前日期的字符串,建立文件夹用 #功能:处理资源标题里一些可能引起转义问题的特殊字符
def legalpath(path):
path = list(path)
path_raw = path[:]
for i in range(len(path_raw)):
if path_raw[i] in [' ','[',']','(',')','/','\\']:
path[i] = '\\'+ path[i]
elif path_raw[i]==":":
path[i] = '-'
return ''.join(path) class Ehentai(object):
def __init__(self, address, comic_name, mode='normal'):
self.head = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'upgrade-insecure-requests': '',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
self.address = address
self.mode = mode
self.gid = address.split('/')[4]
self.tid = address.split('/')[5]
self.content = Get_page(address, cookie=cookie_ehentai(address))
self.comic_name = legalpath(comic_name)
self.raw_name = comic_name.replace("/"," ")
self.raw_name = self.raw_name.replace(":","-")
self.src_list = []
self.path_list = [] #功能:下载的主功能函数
def getOthers(self):
if not self.content:
return 2
today = formatted_today()
logger.info("E-hentai: %s start!" %self.raw_name)
complete_flag = True
pre_addr = re.search(r'(e.+org)', self.address).group(1)
if self.mode=='bt': #bt种子模式
content = Get_page("https://%s/gallerytorrents.php?gid=%s&t=%s"%(pre_addr,self.gid,self.tid), cookie=cookie_ehentai(self.address))
torrents = content.find_all(text="Seeds:")
if not torrents:
self.mode = 'normal' #图片下载模式
else:
torrents_num = [int(tag.next_element) for tag in torrents]
target_index = torrents_num.index(max(torrents_num))
torrent_link = content.select('a')[target_index].get('href')
torrent_name = content.select('a')[target_index].text.replace('/',' ') #e-hentai与exhentai有细微差别
if 'ehtracker' in torrent_link:
req = requests.get(torrent_link, proxy=proxies)
if req.status_code==200:
with open(abs_path+'bttemp/'+torrent_name+'.torrent', 'wb') as ft:
ft.write(req.content)
id = postorrent(abs_path+'bttemp/'+torrent_name+'.torrent', dir=abs_path+today)
if id:
filepath = getinfos().get(id).get('filepath')
return {'taskid':id, 'filepath':filepath}
else: self.mode = 'normal' #e-hentai与exhentai有细微差别
elif 'exhentai' in torrent_link: req = requests.get(torrent_link, headers={'Host': 'exhentai.org',
'Referer': "https://%s/gallerytorrents.php?gid=%s&t=%s"%(pre_addr,self.gid,self.tid),
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'},
cookies=cookie_ehentai(self.address), proxies=proxies)
if req.status_code==200:
with open(abs_path+'bttemp/'+torrent_name+'.torrent', 'wb') as ft:
ft.write(req.content)
id = postorrent(abs_path+'bttemp/'+torrent_name+'.torrent', dir=abs_path+today)
if id:
filepath = getinfos().get(id).get('filepath')
return {'taskid':id, 'filepath':filepath}
else:
self.mode = 'normal'
else:
self.mode = 'normal' page_tag1 = self.content.select_one(".ptds")
page_tags = self.content.select("td[onclick='document.location=this.firstChild.href']")
indexslen = len(page_tags)//2-1
if indexslen <=0:
indexslen = 0
pagetags = page_tags[0:indexslen]
pagetags.insert(0, page_tag1) #有些页面图片超过8页,页面直接链接可能获取不全,采用按规则生成链接方法
last_page = pagetags[-1]
last_link = last_page.a.get('href')
page_links = [pagetag.a.get('href') for pagetag in pagetags]
try:
last_number = int(re.findall(r'\?p=([0-9]+)',last_link)[0])
except IndexError:
pass #说明本子较短,只有一页,不需做特别处理
else:
if last_number>=8:
templete_link = re.findall(r'(.+\?p=)[0-9]+',last_link)[0]
page_links = [templete_link+str(page+1) for page in range(last_number)]
page_links.insert(0, page_tag1.a.get('href')) for page_link in page_links:
content = Get_page(page_link, cookie=cookie_ehentai(self.address))
if not content:
return 2
imgpage_links = content.select("div[class='gdtm']") #一种定位标签
if not imgpage_links:
imgpage_links = content.select("div[class='gdtl']") #有时是另一种标签
for img_page in imgpage_links:
try:
imglink = img_page.div.a.get('href') #对应第一种
except:
imglink = img_page.a.get('href') #对应第二种
content = Get_page(imglink, cookie=cookie_ehentai(self.address))
if not content:
complete_flag = False
self.src_list.append(imglink)
self.path_list.append(abs_path+today+self.raw_name)
continue
try:
img_src = content.select_one("#i7 > a").get('href') #高质量图
except AttributeError:
img_src = content.select_one("img[id='img']").get("src") #小图
src_name = content.select_one("#i2 > div:nth-of-type(2)").text.split("::")[0].strip() #图文件名
raw_path = abs_path+today+self.raw_name
try:
os.makedirs(raw_path)
except FileExistsError:
pass
if os.path.exists(raw_path+'/'+src_name):
continue
http_code = Download_img(img_src, raw_path+'/'+src_name, cookie=cookie_ehentai(self.address))
if http_code!=200:
time.sleep(10)
complete_flag = False
self.src_list.append(imglink)
self.path_list.append(raw_path)
continue
else:
time.sleep(10)
if not complete_flag:
logger.warning("E-hentai: %s ONLY PARTLY finished downloading!" %self.raw_name)
return (self.src_list, self.path_list) else:
logger.info("E-hentai: %s has COMPLETELY finished downloading!" %self.raw_name)
return 1
下载状态查询模块
该模块定时向Aria2查询那些使用了bt下载策略的条目的完成情况,当发现完成时即解压zip文件,然后将数据库中状态字段改为完成;如果连续三次发现下载进度都是0,则认为种子死亡,为条目添加策略切换信号,令初级处理模块在下次处理时按图片下载模式处理。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: checkdalive.py Created on Mon Sep 23 21:20:09 2019 @author: qjfoidnh
""" import os
from settings import current_path
os.chdir(current_path)
from sql_module import mq
import requests
from settings import aria2url, aria2token
import time
import json
import base64
import zipfile
import filetype # 功能:向Aria2发送查询请求
def getinfos():
id_str = "AriaNg_%s_0.043716476479668254"%str(int(time.time())) #随机生成即可,不用遵循一定格式
id = str(base64.b64encode(id_str.encode('utf-8')), 'utf-8')
id_str2 = "AriaNg_%s_0.053716476479668254"%str(int(time.time()))
id2 = str(base64.b64encode(id_str2.encode('utf-8')), 'utf-8')
data = json.dumps({"jsonrpc":"2.0","method":"aria2.tellActive","id":id,"params":["token:%s"%aria2token,["gid","totalLength","completedLength","uploadSpeed","downloadSpeed","connections","numSeeders","seeder","status","errorCode","verifiedLength","verifyIntegrityPending","files","bittorrent","infoHash"]]})
data2 = json.dumps({"jsonrpc":"2.0","method":"aria2.tellWaiting","id":id2,"params":["token:%s"%aria2token,0,1000,["gid","totalLength","completedLength","uploadSpeed","downloadSpeed","connections","numSeeders","seeder","status","errorCode","verifiedLength","verifyIntegrityPending","files","bittorrent","infoHash"]]})
req = requests.post(aria2url, data)
req2 = requests.post(aria2url, data2)
if req.status_code!=200:
return
else:
status_dict = dict()
results = req.json().get('result')
results2 = req2.json().get('result')
results.extend(results2)
for res in results:
status = res.get('status')
completelen = int(res.get('completedLength'))
totallen = int(res.get('totalLength'))
filepath = res.get('files')[0].get('path').replace('//','/').replace("'","\\'")
if completelen==totallen and completelen!=0:
status = 'finished'
status_dict[res.get('gid')] = {'status':status, 'completelen':completelen, 'filepath':filepath}
return status_dict # 功能:也是向Aria2发送另一种查询请求
def getdownloadings(status_dict):
item = mq.fetchoneurl(mode='aria2')
checkingidlist = list()
while item:
if item=='toomany':
item = mq.fetchoneurl(mode='aria2')
continue
gid = item.get('oldpage')
gid = gid or 'default'
complete = status_dict.get(gid, {'status':'finished'})
if complete.get('status')=='finished':
mq.updateurl(item['id'])
filepath = item['filepath']
flag = unzipfile(filepath)
removetask(taskid=gid)
elif complete.get('completelen')==0 and complete.get('status')!='waiting':
mq.reseturl(item['id'], 'checking', count=1)
checkingidlist.append(item['id'])
else:
mq.reseturl(item['id'], 'checking')
checkingidlist.append(item['id'])
item = mq.fetchoneurl(mode='aria2')
for id in checkingidlist:
mq.reseturl(id, 'aria2') # 功能:解压zip文件
def unzipfile(filepath):
kind = filetype.guess(filepath)
if kind.extension!='zip':
return None
f = zipfile.ZipFile(filepath, 'r')
flist = f.namelist()
depstruct = [len(file.strip('/').split('/')) for file in flist]
if depstruct[0]==1 and depstruct[1]!=1:
try:
f.extractall(path=os.path.dirname(filepath))
except:
return None
else:
return True
else:
try:
f.extractall(path=os.path.splitext(filepath)[0])
except:
return None
else:
return True #功能:把已完成的任务从队列里删除,以免后来的任务被阻塞
def removetask(taskid=None, address=None):
id_str = "AriaNg_%s_0.043116476479668254"%str(int(time.time()))
id = str(base64.b64encode(id_str.encode('utf-8')), 'utf-8')
if taskid:
data = json.dumps({"jsonrpc":"2.0","method":"aria2.forceRemove","id":id,"params":["token:%s"%aria2token,taskid]})
if address:
taskid = mq.fetchonegid(address)
if taskid:
data = json.dumps({"jsonrpc":"2.0","method":"aria2.forceRemove","id":id,"params":["token:%s"%aria2token,taskid]})
else:
data = json.dumps({"jsonrpc":"2.0","method":"aria2.forceRemove","id":id,"params":["token:%s"%aria2token,"default"]})
req = requests.post(aria2url, data) if __name__=="__main__":
res = getinfos()
if res:
getdownloadings(res)
工具模块
该模块里定义了一些需要多次调用,或者完成某项功能的函数,比如获取网页内容的Get_page()
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: tools.py Created on Mon Sep 23 20:57:31 2019 @author: qjfoidnh
""" import requests
import time
from bs4 import BeautifulSoup as Bs
from settings import head, aria2url, aria2token
from settings import proxies
import json
import base64 # 功能:对requets.get方法的一个封装,返回Bs对象
def Get_page(page_address, headers={}, cookie=None):
pic_page = None
innerhead = head.copy()
innerhead.update(headers)
try:
pic_page = requests.get(page_address, headers=innerhead, proxies=proxies, cookies=cookie, verify=False)
except Exception as e:
return None
if not pic_page:
return None
pic_page.encoding = 'utf-8'
text_response = pic_page.text
content = Bs(text_response, 'lxml') return content #功能:把种子文件发给Aria2服务,文件以base64编码
def postorrent(path, dir):
with open(path, 'rb') as f:
b64str = str(base64.b64encode(f.read()), 'utf-8')
url = aria2url
id_str = "AriaNg_%s_0.043716476479668254"%str(int(time.time())) #这个字符串可以随便起,只要能保证每次调用生成时不重复就行
id = str(base64.b64encode(id_str.encode('utf-8')), 'utf-8').strip('=')
req = requests.post(url, data=json.dumps({"jsonrpc":"2.0","method":"aria2.addTorrent","id":id,"params":["token:"+aria2token, b64str,[],{'dir':dir, 'allow-overwrite':"true"}]}))
if req.status_code==200:
return req.json().get('result')
else:
return False # 功能:下载图片文件
def Download_img(page_address, filepath, cookie=None): try:
pic_page = requests.get(page_address, headers=head, proxies=proxies, cookies=cookie, timeout=8, verify=False)
if pic_page.status_code==200:
pic_content = pic_page.content
with open(filepath, 'wb') as file:
file.write(pic_content)
return pic_page.status_code
except Exception as e:
return e
日志模块
对logging进行了一个简单的包装,输出日志到文件有利于监控服务的运行状况。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: logger_module.py Created on Mon Sep 23 21:18:37 2019 @author: qjfoidnh
""" import logging LOG_FORMAT = "%(asctime)s - %(filename)s -Line: %(lineno)d - %(levelname)s: %(message)s"
logging.basicConfig(filename='downloadsys.log', level=logging.INFO, format=LOG_FORMAT, filemode='a') logger = logging.getLogger(__name__)
设置信息
该文件里定义了一些信息,比如代理地址,cookies值,下载路径等等。
虽然不需要登录,但不带cookies的访问很容易被E站认为是恶意攻击。在浏览器里打开开发者工具,然后随意访问一个E站链接,从Network标签页里就能读到Cookies字段的值。不想手动添加cookies,可以考虑使用requests中的session方法重构tools.py中的Get_page函数,自动加cookies。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: settings.py Created on Mon Sep 23 21:06:33 2019 @author: qjfoidnh
""" abs_path = "/home/user/e-hentai/"
#下载文件的目录,此处为Linux下目录格式,Windows需注意反斜杠转义问题。此目录必须事先建好,且最后一个‘/‘不能丢 current_path = "/home/user/e-hentai/"
#此目录代表项目代码的位置,不一定与上一个相同 #aria2配置
aria2url = "http://127.0.0.1:6800/jsonrpc"
aria2token = "" #浏览器通用头部
head = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} cookie_raw_ehentai = '''nw=1; __cfduid=xxxxxxxxxxxx; ipb_member_id=xxxxxx; ipb_pass_hash=xxxxx;xxxxxxxx'''
#从浏览器里复制来的cookies大概就是这样的格式,exhentai同理 cookie_raw_exhentai = '''xxxxxxxx''' #代理地址,E站需要科kx学访问,此处仅支持http代理。关于代理的获得及设置请自行学习
#听说现在不科学也可以了,如果属实,可令proxies = None
proxies = {"http": "http://localhost:10808", "https": "http://localhost:10808"}
# proxies = None def cookieToDict(cookie):
'''
将从浏览器上Copy来的cookie字符串转化为Dict格式
'''
itemDict = {}
items = cookie.split(';')
for item in items:
key = item.split('=')[0].replace(' ', '')
value = item.split('=')[1]
itemDict[key] = value
return itemDict def cookie_ehentai(address):
if "e-hentai" in address:
return cookieToDict(cookie_raw_ehentai)
elif "exhentai" in address:
return cookieToDict(cookie_raw_exhentai)
else:
return cookieToDict(cookie_raw_ehentai)
主函数
主函数从数据库里取条目,并根据返回结果对数据库条目进行相应的更新。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
filename: access.py Created on Mon Sep 23 20:18:01 2019 @author: qjfoidnh
""" import time
from sql_module import mq
from init_process import DownEngine, fixexcepts
import os
from logger_module import logger if __name__ =="__main__": engine = DownEngine()
On = True
print("%d进程开始运行..." %os.getpid())
while On: #先处理下载未完全的异常条目
item = mq.fetchoneurl(mode="except")
if type(item)==Exception:
logger.error(item)
elif not item:
pass
else:
img_srcs = item['failed_links']; filepaths = item['failed_paths']; itemid = item['id']; raw_address = item['raw_address'] res = fixexcepts(itemid, img_srcs, filepaths)
if type(res)!=int:
logger.error(res)
continue
elif res==0:
logger.info("%d进程,%d号页面修复完毕.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
elif res>0:
logger.warning("%d进程,%d号页面修复未完,仍余%d.\
页面地址为%s" %(os.getpid(), itemid, res, raw_address)) item = mq.fetchoneurl()
if item=='toomany': #指取到的条目超过最大重试次数上限
continue
if type(item)==Exception:
logger.error(item)
continue
elif not item:
time.sleep(600)
continue
else:
raw_address = item['raw_address']; itemid = item['id']
logger.info("%d进程,%d号页面开始下载.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
res = engine.engineSwitch(raw_address)
if type(res)==Exception:
logger.warning("%d进程,%d号页面引擎出错.\
出错信息为%s" %(os.getpid(), itemid, str(res)))
mq.reseturl(itemid, 'skipped')
continue if type(res)==tuple and len(res)==2:
response = mq.fixunfinish(itemid, res[0], res[1])
if response==0:
logger.warning("%d进程,%d号页面下载部分出错,已标志异常下载状态.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
else:
logger.warning("%d进程,%d号页面下载部分出错且标志数据库状态字段时发生错误. 错误为%s, \
页面地址为%s" %(os.getpid(), itemid, str(response), raw_address)) elif type(res)==dict:
if 'taskid' in res:
response = mq.reseturl(itemid, 'aria2')
mq.replaceurl(itemid, res['taskid'], item['raw_address'], filepath=res['filepath']) elif res==1:
response = mq.updateurl(itemid)
if type(response)==int:
logger.info("%d进程,%d号页面下载完毕.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
else:
logger.warning("%d进程,%d号页面下载完毕但更新数据库状态字段时发生错误:%s.\
页面地址为%s" %(os.getpid(), itemid, str(response), raw_address))
elif res==2:
response = mq.reseturl(itemid, 'pending', count=1)
if type(response)==int:
logger.info("%d进程,%d号页面遭遇初始请求失败,已重置下载状态.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
else:
logger.warning("%d进程,%d号页面遭遇初始请求失败,且重置数据库状态字段时发生错误.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
elif res==9:
response = mq.reseturl(itemid, 'aria2')
if type(response)==int:
logger.info("%d进程,%d号页面送入aria2下载器.\
页面地址为%s" %(os.getpid(), itemid, raw_address))
else:
logger.warning("%d进程,%d号页面送入aria2下载器,但更新状态字段时发生错误.\
页面地址为%s" %(os.getpid(), itemid, raw_address)) time.sleep(10)
使用方法
把所有文件放在同一目录,在设置信息里修改好配置,运行主函数即可。
另把checkdalive.py加入任务计划或crontab,每隔一段时间执行一次(建议半小时或一小时)
接下来只要把待抓取的页面链接写入数据库raw_address字段,status字段写为pending(可以另做一个脚本/插件来进行这个工作,笔者就是开发了一个Chrome扩展来在E站页面一键入库)即可,程序在轮询中会自动开始处理,不一会儿就能在指定目录下看到资源文件了。
后记
这个爬虫是笔者从自己开发的一套更大的系统上拆分下来的子功能,所以整体逻辑显得比较复杂;另外由于开发历时较久,有些冗余或不合理的代码,读者可自行删减不需要的功能,或进行优化。
比如说,如果不追求效率,可以弃用Aria2下载的部分,全部使用图片下载模式;对于失败图片链接的储存,诸如Redis等内存数据库其实比MySQL更适合;可以增加一个检测环节,检测代理失效或IP被封禁的情形,等等。
对于有一定爬虫基础的人来说,该爬虫的代码并不复杂,其精华实则在于设计思想和对各类异常的处理。笔者看过网上其他的一些E站爬虫,自认为在稳定性和扩展性方面,此爬虫可以说是颇具优势的。
用Python+Aria2写一个自动选择最优下载方式的E站爬虫的更多相关文章
- python 3 - 写一个自动生成密码文件的程序
1.你输入几,文件里面就给你产生多少条密码 2.密码必须包括,大写字母.小写字母.数字.特殊字符 3.密码不能重复 4.密码都是随机产生的 5.密码长度6-11 import string,rando ...
- Python写一个自动点餐程序
Python写一个自动点餐程序 为什么要写这个 公司现在用meican作为点餐渠道,每天规定的时间是早7:00-9:40点餐,有时候我经常容易忘记,或者是在地铁/公交上没办法点餐,所以总是没饭吃,只有 ...
- Shell 命令行,写一个自动整理 ~/Downloads/ 文件夹下文件的脚本
Shell 命令行,写一个自动整理 ~/Downloads/ 文件夹下文件的脚本 在 mac 或者 linux 系统中,我们的浏览器或者其他下载软件下载的文件全部都下载再 ~/Downloads/ 文 ...
- 写一个nginx.conf方便用于下载某个网页的所有资源
写一个nginx.conf方便用于下载某个网页的所有资源 worker_processes 1; events { worker_connections 1024; } http { include ...
- [python] 1、python鼠标点击、移动事件应用——写一个自动下载百度音乐的程序
1.问题描述: 最近百度总爱做一些破坏用户信任度的事——文库金币变券.网盘限速,吓得我赶紧想办法把存在百度云音乐中的歌曲下载到本地. http://yinyueyun.baidu.com/ 可问题是云 ...
- 学记:为spring boot写一个自动配置
spring boot遵循"约定优于配置"的原则,使用annotation对一些常规的配置项做默认配置,减少或不使用xml配置,让你的项目快速运行起来.spring boot的神奇 ...
- Python+Appium自动化测试(9)-自动选择USB用于传输文件(不依赖appium对手机页面元素进行定位)
一,问题 app自动化测试使用Android真机连接电脑时,通常会遇到两种情况: 1.测试机连接电脑会弹窗提示USB选项,选择USB用于"传输文件",有些手机不支持设置默认USB选 ...
- Python: 如何写一个异常
例子1 try: #test area function() except Exception, e: print e.message 例子2:用raise抛出一个异常 if bool_var is ...
- 用python itchat写一个微信机器人自动回复
首先看一下效果: 进入正题: 一.首先要去图灵机器人网站注册一个机器人账号: 链接:http://www.tuling123.com/ 你可以获取自己的图灵机器人apikey 懒得话不注册也可以,我下 ...
随机推荐
- elk收集tomcat的日志
logstash收集tomcat的日志 不要修改下tomcat中server.xml的日志格式,否则tomcat无法启动,试过多次,不行,就用自带的日志让logstash去收集 首先给tomcat日志 ...
- coreDNS一直处于创建中解决
https://blog.csdn.net/gsying1474/article/details/53256599 执行: [root@lab1 coredns]# kubectl delete -f ...
- Java集合(0):概述
下面是一个Java集合的简化图,我们可以看出,集合分Collection和Map两大部分: 接下来分别以下面几个章节介绍Java集合: Java集合(1):Collections工具类中的static ...
- SpringBoot: 7.整合jsp(转)
springboot内部对jsp的支持并不是特别理想,而springboot推荐的视图是Thymeleaf,对于java开发人员来说还是大多数人员喜欢使用jsp 1.创建maven项目,添加pom依赖 ...
- curl指令的坑
今天使用curl指令构造一个docker api访问,一直得不到预期的结果.调试了半天,发现是网址没加引号. token=$(curl -v -XGET -H >& 由于网址跟了一串参数 ...
- GAN(生成对抗网络)之keras实践
GAN由论文<Ian Goodfellow et al., “Generative Adversarial Networks,” arXiv (2014)>提出. GAN与VAEs的区别 ...
- Vue.js 使用 $refs 定位 DOM 出现 undefined
找到这篇文章,写得不错,记录一下.https://www.jianshu.com/p/090937a480b5
- 代码中 方法 处提示:This method has a constructor name
“此方法具有构造方法的名字” package classpackage; public class Puppy { public void Puppy(String name) { System.ou ...
- 第十三章 字符串 (四)之Scanner类
一.Scanner简述 Scanner扫描器类本质上是由正则表达式实现的,可以接受任何能产生数据的数据源对象,默认以空白符进行分词(包括\n等),使用各种next方法进行扫描匹配,获取匹配的数据. 二 ...
- Spring4学习回顾之路05—自动装配,Bean的继承,依赖和作用域
自动装配 xml配置里的Bean的自动装配,Spring IOC容器可以自动装配Bean,仅仅需要做的是在<bean>标签里的autowire属性里指定自动装配的模式. ①byType(根 ...