SSD源码解读——损失函数的构建
之前,对SSD的论文进行了解读,可以回顾之前的博客:https://www.cnblogs.com/dengshunge/p/11665929.html。
为了加深对SSD的理解,因此对SSD的源码进行了复现,主要参考的github项目是ssd.pytorch。同时,我自己对该项目增加了大量注释:https://github.com/Dengshunge/mySSD_pytorch
搭建SSD的项目,可以分成以下三个部分:
接下来,本篇博客重点分析损失函数的构建。
检测任务的损失函数,与分类任务的损失函数具有很大不同。在检测的损失函数中,不仅需要计类别置信度的差异,坐标的差异,还需要使用到各种tricks,例如hard negative mining等。
在train.py中,首先需要对损失函数MultiBoxLoss()进行初始化,需要传入的参数为num_classes类别数,正例的IOU阈值和hard negative mining的正负样本比例。在论文中,VOC的类别总数是21(20个类别加上1个背景);当预测框与GT框的IOU大于0.5时,认为该预测框是正例;hard negative mining的正样本和负样本的比例是1:3。
# 损失函数
criterion = MultiBoxLoss(num_classes=voc['num_classes'],
overlap_thresh=0.5,
neg_pos=3)
在models/multibox_loss中,定义了损失函数MultiBoxLoss()。在函数forward()中,需要传进来两个参数,分别是predictions和targets,其中,predictions是SSD网络得到的结果,分别是预测框坐标,类别置信度和先验锚点框;而targets是则是数据读取中的值,是GT框的坐标和类别label。首先,需要创建坐标loc_t和类别置信度conf_t的tensor,其shape分别是[batch_size,8732,4]和[batch_size,8732]。然后,使用一个for循环,将GT框与先验锚点框的坐标与label进行match,得到每个锚点框的label和坐标偏差,并将结果保存与loc_t和conf_t中。由于制定了某些锚点框用于预测目标,因此,接下来,需要使用这部分锚点框信息来计算损失。取出含目标的锚点框,得到其index,其中,pos的shape为[batch_size,8732],每个元素是true或者false。再从网络预测的8732个预测框中,取出同样index的预测框的坐标偏差loc_p,而loc_t则是同样index的先验锚点框的坐标偏差。由于锚点框对应上了,则使用smooth_l1来计算预测框回归的算是loss_l,如下图所示的$L_{loc}$,图片来源。

接下来,则是使用hard negative mining和计算置信度损失。首先为模型预测出来的置信度conf_data进行维度变换,由[batch_size,8732,21]变成[batch_size*8732,21]的batch_conf,应该是为了方便下面进行计算。接下来,计算所有预测框的置信度损失loss_c,将含目标的锚点框(正例)的损失置0,并对损失进行排名,从而选出损失最大的前num_neg个损失的index。将正例的pos_index和损失最大的负例neg_idx提取出来成conf_p,用于参与训练中,与相同index的先验锚点框进行计算交叉熵损失计算。最后将置信度损失和位置损失返回。
class MultiBoxLoss(nn.Module):
'''
SSD损失函数的计算
''' def __init__(self, num_classes, overlap_thresh, neg_pos):
super(MultiBoxLoss, self).__init__()
self.num_classes = num_classes # 类别数
self.threshold = overlap_thresh # GT框与先验锚点框的阈值
self.negpos_ratio = neg_pos # 负例的比例 def forward(self, predictions, targets):
'''
对损失函数进行计算:
1.进行GT框与先验锚点框的匹配,得到loc_t和conf_t,分别表示锚点框需要匹配的坐标和锚点框需要匹配的label
2.对包含目标的先验锚点框loc_t(即正例)与预测的loc_data计算位置损失函数
3.对负例(即背景)进行损失计算,选择损失最大的num_neg个负例和正例共同组成训练样本,取出这些训练样本的锚点框targets_weighted
与置信度预测值conf_p,计算置信度损失:
a)为Hard Negative Mining计算最大置信度loss_c
b)将loss_c中正例对应的值置0,即保留了所有负例
c)对此loss_c进行排序,得到损失最大的idx_rank
d)计算用于训练的负例的个数num_neg,约为正例的3倍
e)选择idx_rank中前num_neg个用作训练
f)将正例的index和负例的index共同组成用于计算损失的index,并从预测置信度conf_data和真实置信度conf_t提出这些样本,形成
conf_p和targets_weighted,计算两者的置信度损失.
:param predictions: 一个元祖,包含位置预测,置信度预测,先验锚点框
位置预测:(batch_size,num_priors,4),即[batch_size,8732,4]
置信度预测:(batch_size,num_priors,num_classes),即[batch_size, 8732, 21]
先验锚点框:(num_priors,4),即[8732, 4]
:param targets: 真实框的坐标与label,[batch_size,num_objs,5]
其中,5代表[xmin,ymin,xmia,ymax,label]
'''
loc_data, conf_data, priors = predictions
num = loc_data.shape[0] # 即batch_size大小
priors = priors[:loc_data.shape[1], :] # 取出8732个锚点框,与位置预测的锚点框数量相同
num_priors = priors.shape[0] # loc_t = torch.Tensor(num, num_priors, 4) # [batch_size,8732,4],生成随机tensor,后续用于填充
conf_t = torch.Tensor(num, num_priors) # [batch_size,8732]
# 取消梯度更新,貌似默认是False
loc_t.requires_grad = False
conf_t.requires_grad = False for idx in range(num):
truths = targets[idx][:, :-1] # 坐标值,[xmin,ymin,xmia,ymax]
labels = targets[idx][:, -1] # label
defaults = priors.cuda()
match(self.threshold, truths, defaults, labels, loc_t, conf_t, idx)
if torch.cuda.is_available():
loc_t = loc_t.cuda()
conf_t = conf_t.cuda() # shape:[batch_size,8732],其元素组成是类别标签号和背景 pos = conf_t > 0 # 排除label=0,即排除背景,shape[batch_size,8732],其元素组成是true或者false
# Localization Loss (Smooth L1),定位损失函数
# Shape: [batch,num_priors,4]
# pos.dim()表示pos有多少维,应该是一个定值(2)
# pos由[batch_size,8732]变成[batch_size,8732,1],然后展开成[batch_size,8732,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4) # [num_pos,4],取出带目标的这些框
loc_t = loc_t[pos_idx].view(-1, 4) # [num_pos,4]
# 位置损失函数
loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum') # 这里对损失值是相加,有公式可知,还没到相除的地步 # 为Hard Negative Mining计算max conf across batch
batch_conf = conf_data.view(-1, self.num_classes) # shape[batch_size*8732,21]
# gather函数的作用是沿着定轴dim(1),按照Index(conf_t.view(-1, 1))取出元素
# batch_conf.gather(1, conf_t.view(-1, 1))的shape[8732,1],作用是得到每个锚点框在匹配GT框后的label
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1).long()) # 这个不是最终的置信度损失函数 # Hard Negative Mining
# 由于正例与负例的数据不均衡,因此不是所有负例都用于训练
loss_c[pos.view(-1, 1)] = 0 # pos与loss_c维度不一样,所以需要转换一下,选出负例
loss_c = loss_c.view(num, -1) # [batch_size,8732]
_, loss_idx = loss_c.sort(1, descending=True) # 得到降序排列的index
_, idx_rank = loss_idx.sort(1) num_pos = pos.sum(1, keepdim=True) # pos里面是true或者false,因此sum后的结果应该是包含的目标数量
num_neg = torch.clamp(self.negpos_ratio * num_pos, max=pos.size(1) - 1) # 生成一个随机数用于表示负例的数量,正例和负例的比例约3:1
neg = idx_rank < num_neg.expand_as(idx_rank) # [batch_size,8732] 选择num_neg个负例,其元素组成是true或者false # 置信度损失,包括正例和负例
# [batch_size, 8732, 21],元素组成是true或者false,但true代表着存在目标,其对应的index为label
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# pos_idx由true和false组成,表示选择出来的正例,neg_idx同理
# (pos_idx + neg_idx)表示选择出来用于训练的样例,包含正例和反例
# torch.gt(other)函数的作用是逐个元素与other进行大小比较,大于则为true,否则为false
# 因此conf_data[(pos_idx + neg_idx).gt(0)]得到了所有用于训练的样例
conf_p = conf_data[(pos_idx + neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos + neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted.long(), reduction='sum') # L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.sum() # 一个batch里面所有正例的数量
loss_l /= N
loss_c /= N
return loss_l, loss_c
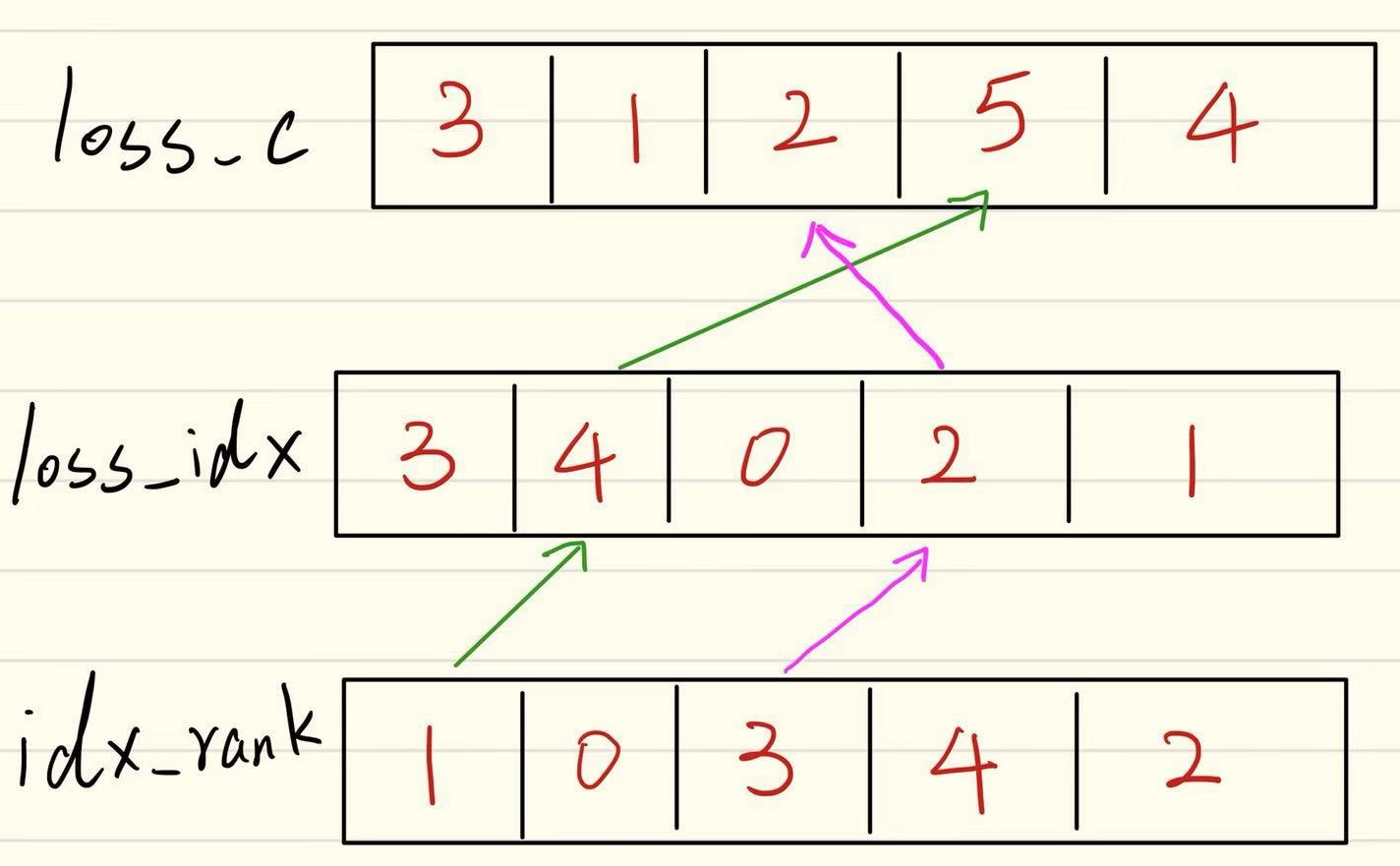
在hard negative mining中,需要先计算loss_c。从代码可以看到 loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1).long()) ,这句代码就是置信度损失的计算,可以参考公式进行理解。这里可以提及一下,对loss_c的两次排序,参考这篇博客,首先对值进行降序排序,得到排名1,然后对排名又进行降序排序,得到排名2,如下图所示,即能取出idx_rank的前N个,可获得损失最大那些值,即变量neg的作用。
在计算损失函数时,提及了函数match(),这个函数位于models/box_utils.py中,是一个非常关键的函数,对应论文的匹配策略那一章节,其作用是为每个锚点框指定GT框和为每个GT框指定锚点框。需要传进来几个参数,truths是GT框的坐标,priors是先验锚点框的坐标[中心点x,中心点y,W,H],labels是GT框对应的类别(不包含背景),loc_t和conf_t是用来保存结果的,idx是第i张图片。
为了方便表述,num_objects表示一张图中,GT框的数量;num_priors表示先验锚点框的数量,即8732。
第一步,由于先验锚点框priors的坐标形式是[中心点x,中心点y,W,H],需要使用函数point_from()来将其转化成[x_min,y_min,x_max,y_max]。然后计算每个GT框与所有先验锚点框的jaccard值,即IOU的值,使用了numpy风格的计算方式,返回的变量overlaps的shape为[GT框数量,8732]。
第二步,根据论文,为每个GT框匹配一个最大IOU的先验锚点框,确保每个GT框至少有一个锚点框进行预测。
第三步,为每个锚点框匹配上一个最大IOU的GT框来进行预测。
第四步,变量best_truth_overlap保存着每个框与GT框的最大IOU值(第三步的结果),使用index_fill()函数,将第二步的结果同步到这个变量中。在index_fill()函数中,使用数值2来进行填充,是为了确保第二步中得到的锚点框肯定会被选到。对变量best_truth_idx也进行同样的处理。
第五步,由于传入进来的labels的类别是从0开始的,SSD中认为0应该是背景,所以,需要对labels进行加一。这里需要注意一下,best_truth_idx的shape是[8732],每个元素的范围为[0,num_objects],所以conf的shape为[num_priors],每个元素表示先验锚点框的label(0是背景)。同时,需要将变量best_truth_overlap中IOU小于阈值(0.5)的锚点框的label设置为0。并将结果保存与conf_t,返回给外面的函数用于计算。
第六步,同样需要将GT框的坐标进行扩展,形成shape为[num_priors,4]的matches,这样每个锚点框都有对应的坐标进行预测,但最终并不是每个锚点框都用于训练中。
第七步,使用GT框与锚点框进行编码,对应论文中的公式2,得到shape为[num_priors,4]的值,即偏差,将此结果返回出去。
注意,这里使用的是GT框的信息和先验锚点框的信息,并没有涉及到网络预测出来的结果。得到每个锚点框的类别conf_t和坐标loc_t。由于没有用到网络预测的结果,可以认为这部分一直都是定值。
def match(threshold, truths, priors, labels, loc_t, conf_t, idx):
'''
这个函数对应论文中的matching strategy匹配策略.SSD需要为每一个先验锚点框都指定一个label,
这个label或者指向背景,或者指向每个类别.
论文中的匹配策略是:
1.首先,每个GT框选择与其IOU最大的一个锚点框,并令这个锚点框的label等于这个GT框的label
2.然后,当锚点框与GT框的IOU大于阈值(0.5)时,同样令这个锚点框的label等于这个GT框的label
因此,代码上的逻辑为:
1.计算每个GT框与每个锚点框的IOU,得到一个shape为[num_object,num_priors]的矩阵overlaps
2.选择与GT框的IOU最大的锚点框,锚点框的index为best_prior_idx,对应的IOU值为best_prior_overlap
3.为每一个锚点框选择一个IOU最大的GT框,可能会出现多个锚点框匹配一个GT框的情况,此时,每个锚点框对应GT框的index为best_truth_idx,
对应的IOU为best_truth_overlap.注意,此时IOU值可能会存在小于阈值的情况.
4.第3步可能到导致存在GT框没有与锚点框匹配上的情况,所以要和第2步进行结合.在第3步的基础上,对best_truth_overlap进行选择,选择出
best_prior_idx这些锚点框,让其对其的IOU等于一个大于1的定值;并且让best_truth_idx中index为best_prior_idx的锚点框的label
与GT框对应上.最终,best_truth_overlap表示每个锚点框与GT框的最大IOU值,而best_truth_idx表示每个锚点框用于与相应的GT框进行
匹配.
5.第4步中,会存在IOU小于阈值的情况,要将这些小于IOU阈值的锚点框的label指向背景,完成第二条匹配策略.
labels表示GT框对应的标签号,"conf=labels[best_truth_idx]+1"得到每个锚点框对应的标签号,其中label=0是背景.
"conf[best_truth_overlap < threshold] = 0"则将小于IOU阈值的锚点框的label指向背景
6.得到的conf表示每个锚点框对应的label,还需要一个矩阵,来表示每个锚点框需要匹配GT框的坐标.
truths表示GT框的坐标,"matches = truths[best_truth_idx]"得到每个锚点框需要匹配GT框的坐标.
:param threshold:IOU的阈值
:param truths:GT框的坐标,shape:[num_obj,4]
:param priors:先验锚点框的坐标,shape:[num_priors,4],num_priors=8732
:param labels:这些GT框对应的label,shape:[num_obj],此时label=0还不是背景
:param loc_t:坐标结果会保存在这个tensor
:param conf_t:置信度结果会保存在这个tensor
:param idx:结果保存的idx
'''
# 第1步,计算IOU
overlaps = jaccard(truths, point_from(priors)) # shape:[num_object,num_priors] # 第2步,为每个真实框匹配一个IOU最大的锚点框,GT框->锚点框
# best_prior_overlap为每个真实框的最大IOU值,shape[num_objects,1]
# best_prior_idx为对应的最大IOU的先验锚点框的Index,其元素值的范围为[0,num_priors]
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True) # 第3步,若先验锚点框与GT框的IOU>阈值,也将这些锚点框匹配上,锚点框->GT框
# best_truth_overlap为每个先验锚点框对应其中一个真实框的最大IOU,shape[1,num_priors]
# best_truth_idx为每个先验锚点框对应的真实框的index,其元素值的范围为[0,num_objects]
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True) best_prior_idx.squeeze_(1) # [num_objects]
best_prior_overlap.squeeze_(1) # [num_objects]
best_truth_idx.squeeze_(0) # [num_priors],8732
best_truth_overlap.squeeze_(0) # [num_priors],8732 # 第4步
# index_fill_(self, dim: _int, index: Tensor, value: Number)对第dim行的index使用value进行填充
# best_truth_overlap为第一步匹配的结果,需要使用到,使用best_prior_idx是第二步的结果,也是需要使用上的
# 所以在best_truth_overlap上进行填充,表明选出来的正例
# 使用2进行填充,是因为,IOU值的范围是[0,1],只要使用大于1的值填充,就表明肯定能被选出来
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # 确定最佳先验锚点框
# 确保每个GT框都能匹配上最大IOU的先验锚点框
# 得到每个先验锚点框都能有一个匹配上的数字
# best_prior_idx的元素值的范围是[0,num_priors],长度为num_objects
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j # 第5步
conf = labels[best_truth_idx] + 1 # Shape: [num_priors],0为背景,所以其余编号+1
conf[best_truth_overlap < threshold] = 0 # 置信度小于阈值的label设置为0 # 第6步
matches = truths[best_truth_idx] # 取出最佳匹配的GT框,Shape: [num_priors,4] # 进行位置编码
loc = encode(matches, priors,voc['variance'])
loc_t[idx] = loc # [num_priors,4],应该学习的编码偏差
conf_t[idx] = conf # [num_priors],每个锚点框的label
在函数match()中,使用到了函数encode()来对位置进行编码。参考博客和R-CNN中的公式,假设先验锚点框的坐标为$(d^{cx},d^{cy},d^w,d^h)$,预测框的坐标为$(b^{cx},b^{cy},b^w,b^h)$,则预测框的转换值l为:
$$l^{cx}=(b^{cx}-d^{cx})/d^w, l^{cy}=(b^{cy}-d^{cy})/d^h$$
$$b^w=d^wexp(l^x), b^h=d^hexp(l^h)$$
而代码中,我们利用了方差的信息,因此进行了相应的调整,整体上是一致的。
def encode(matched, priors, variances):
'''
对坐标进行编码,对应论文中的公式2
利用GT框和先验锚点框,计算偏差,用于回归
:param matched: 每个先验锚点框对应最佳的GT框,Shape: [num_priors, 4],
其中4代表[xmin,ymin,xmax,ymax]
:param priors: 先验锚点框,Shape: [num_priors,4],
其中4代表[中心点x,中心点y,宽,高]
:return: shape:[num_priors, 4]
'''
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2] # 计算GT框与锚点框中心点的距离
g_cxcy /= (variances[0] * priors[:, 2:]) g_wh = (matched[:, 2:] - matched[:, :2]) # xmax-xmin,ymax-ymin
g_wh /= priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1] return torch.cat([g_cxcy, g_wh], 1)
至此,SSD的损失函数构建以介绍完成。相比于分类任务,目标检测的损失函数构建需要更多的代码,包含了各种tricks。
SSD源码解读——损失函数的构建的更多相关文章
- SSD源码解读——网络测试
之前,对SSD的论文进行了解读,可以回顾之前的博客:https://www.cnblogs.com/dengshunge/p/11665929.html. 为了加深对SSD的理解,因此对SSD的源码进 ...
- SSD源码解读——网络搭建
之前,对SSD的论文进行了解读,可以回顾之前的博客:https://www.cnblogs.com/dengshunge/p/11665929.html. 为了加深对SSD的理解,因此对SSD的源码进 ...
- SSD源码解读——数据读取
之前,对SSD的论文进行了解读,可以回顾之前的博客:https://www.cnblogs.com/dengshunge/p/11665929.html. 为了加深对SSD的理解,因此对SSD的源码进 ...
- Webpack探索【16】--- 懒加载构建原理详解(模块如何被组建&如何加载)&源码解读
本文主要说明Webpack懒加载构建和加载的原理,对构建后的源码进行分析. 一 说明 本文以一个简单的示例,通过对构建好的bundle.js源码进行分析,说明Webpack懒加载构建原理. 本文使用的 ...
- Webpack探索【15】--- 基础构建原理详解(模块如何被组建&如何加载)&源码解读
本文主要说明Webpack模块构建和加载的原理,对构建后的源码进行分析. 一 说明 本文以一个简单的示例,通过对构建好的bundle.js源码进行分析,说明Webpack的基础构建原理. 本文使用的W ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- AFNetworking 3.0 源码解读(五)之 AFURLSessionManager
本篇是AFNetworking 3.0 源码解读的第五篇了. AFNetworking 3.0 源码解读(一)之 AFNetworkReachabilityManager AFNetworking 3 ...
- String、StringBuffer、StringBuilder源码解读
序 好长时间没有认真写博客了,过去的一年挺忙的.负责过数据库.线上运维环境.写代码.Code review等等东西挺多. 学习了不少多方面的东西,不过还是需要回归实际.加强内功,方能扛鼎. 去年学习M ...
- nodeJS之eventproxy源码解读
1.源码缩影 !(function (name, definition) { var hasDefine = typeof define === 'function', //检查上下文环境是否为AMD ...
随机推荐
- Json+Ajax相关
Ajax前戏之json: 1.什么是json? JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式. 2.json对象和JavaScript ...
- kvm简介及创建虚拟化安装(1)
kvm虚拟化介绍 一.虚拟化分类 1.虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机.在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立 ...
- TYPES与DATA区别
例如:int a; "c语言定义 TYPES:BEGIN OF typ, filed1 TYPE c, END OF typ. "相当于int类型 DAT ...
- C基础知识(11):错误处理
C语言不提供对错误处理的直接支持,但是作为一种系统编程语言,它以返回值的形式允许您访问底层数据.在发生错误时,大多数的C或UNIX函数调用返回1或NULL,同时会设置一个错误代码errno,该错误代码 ...
- JavaScript高程第三版笔记(1-5章)
第2章:在html中使用javascript ①script标签的defer属性 <script type="text/javascript" defer="def ...
- .net core cookie滑动过期设置
HttpContext.SignInAsync( CookieAuthenticationDefaults.AuthenticationScheme, userPrincipal, new Authe ...
- 如何在VUE中使用leaflet地图框架
前言:在leaflet的官方文档只有静态的HTML演示并没有结合VUE的demo 虽然也有一些封装好的leaflet库例如Vue-Leaflet,但是总感觉用起来不是那么顺手,有些业务操作还是得用l ...
- /usr/lib/libstdc++.so.6: version `GLIBCXX_3.4.15' not found错误的解决 转载
升级cmake时,提示“Error when bootstrapping CMake:Problem while running initial CMake”,第二次运行./bootstrap时,直接 ...
- 山东省第十届ACM省赛参赛后的学期总结
5.11,5.12两天的济南之旅结束了,我也参加了人生中第一次正式的acm比赛,虽然是以友情队的身份,但是我依旧十分兴奋. 其实一直想写博客来增加自己的能力的,但是一直拖到现在,正赶上老师要求写一份总 ...
- bert系列一:《Attention is all you need》论文解读
论文创新点: 多头注意力 transformer模型 Transformer模型 上图为模型结构,左边为encoder,右边为decoder,各有N=6个相同的堆叠. encoder 先对inputs ...