GoogLeNet网络的Pytorch实现
1.文章原文地址
Going deeper with convolutions
2.文章摘要
我们提出了一种代号为Inception的深度卷积神经网络,它在ILSVRC2014的分类和检测任务上都取得当前最佳成绩。这种结构的主要特点是提高了网络内部计算资源的利用率。这是通过精心的设计实现的,它允许增加网络的深度和宽度,同时保持计算预算不变。为了提高效果,这个网络的架构确定是基于Hebbian原则和多尺度处理的直觉。其中一个典型的实例用于提交到ILSVRC2014上,我们称之为GoogLeNet,它是一个22层的深度网络,该网络的效果通过分类和检测任务来加以评估。
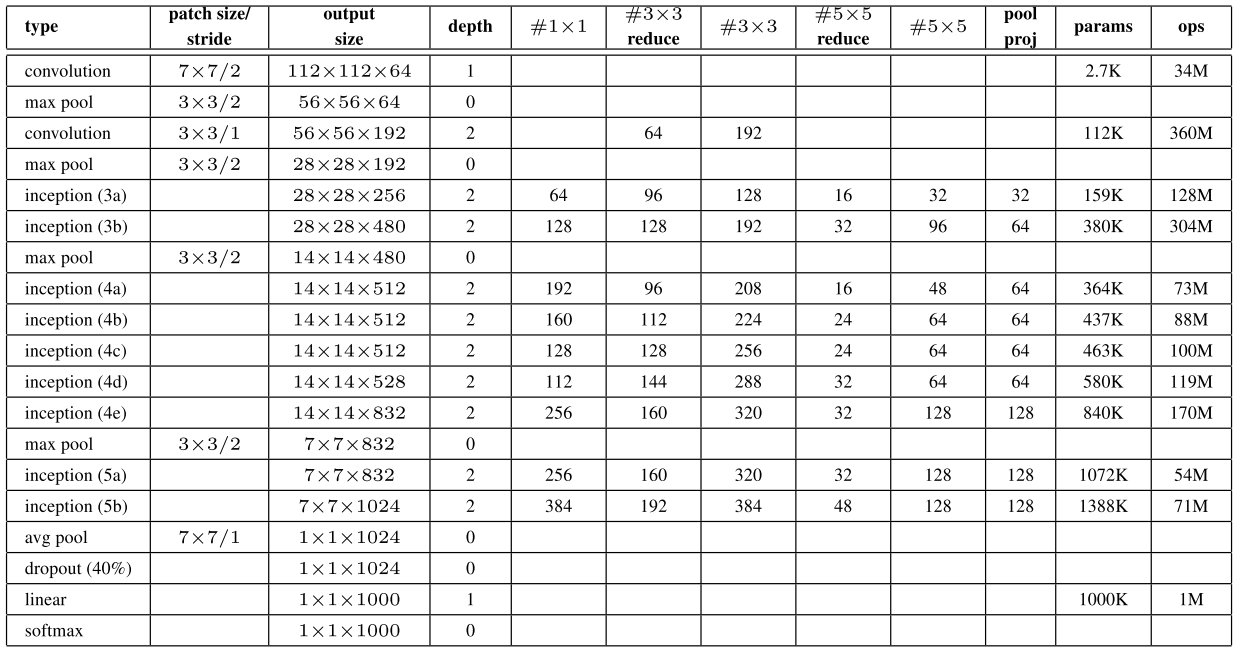
3.网络结构

4.Pytorch实现
import warnings
from collections import namedtuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.model_zoo import load_url as load_state_dict_from_url
from torchsummary import summary __all__ = ['GoogLeNet', 'googlenet'] model_urls = {
# GoogLeNet ported from TensorFlow
'googlenet': 'https://download.pytorch.org/models/googlenet-1378be20.pth',
} _GoogLeNetOuputs = namedtuple('GoogLeNetOuputs', ['logits', 'aux_logits2', 'aux_logits1']) def googlenet(pretrained=False, progress=True, **kwargs):
r"""GoogLeNet (Inception v1) model architecture from
`"Going Deeper with Convolutions" <http://arxiv.org/abs/1409.4842>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
aux_logits (bool): If True, adds two auxiliary branches that can improve training.
Default: *False* when pretrained is True otherwise *True*
transform_input (bool): If True, preprocesses the input according to the method with which it
was trained on ImageNet. Default: *False*
"""
if pretrained:
if 'transform_input' not in kwargs:
kwargs['transform_input'] = True
if 'aux_logits' not in kwargs:
kwargs['aux_logits'] = False
if kwargs['aux_logits']:
warnings.warn('auxiliary heads in the pretrained googlenet model are NOT pretrained, '
'so make sure to train them')
original_aux_logits = kwargs['aux_logits']
kwargs['aux_logits'] = True
kwargs['init_weights'] = False
model = GoogLeNet(**kwargs)
state_dict = load_state_dict_from_url(model_urls['googlenet'],
progress=progress)
model.load_state_dict(state_dict)
if not original_aux_logits:
model.aux_logits = False
del model.aux1, model.aux2
return model return GoogLeNet(**kwargs) class GoogLeNet(nn.Module): def __init__(self, num_classes=1000, aux_logits=True, transform_input=False, init_weights=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True) #向上取整
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True) self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128) if aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes) self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(1024, num_classes) if init_weights:
self._initialize_weights() def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0) def forward(self, x):
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1) # N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x) # N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits:
aux1 = self.aux1(x) x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits:
aux2 = self.aux2(x) x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7 x = self.avgpool(x)
# N x 1024 x 1 x 1
x = x.view(x.size(0), -1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits:
return _GoogLeNetOuputs(x, aux2, aux1)
return x class Inception(nn.Module): #Inception模块 def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__() self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
) self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=3, padding=1)
) self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
) def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x) outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) class InceptionAux(nn.Module): #辅助分支 def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes) def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = x.view(x.size(0), -1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = F.dropout(x, 0.7, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes return x class BasicConv2d(nn.Module): #Conv2d+BN+Relu def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001) def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True) if __name__=="__main__":
model=googlenet()
print(model,(3,224,224))
参考
https://github.com/pytorch/vision/tree/master/torchvision/models
GoogLeNet网络的Pytorch实现的更多相关文章
- 跟我学算法-图像识别之图像分类(下)(GoogleNet网络, ResNet残差网络, ResNext网络, CNN设计准则)
1.GoogleNet 网络: Inception V1 - Inception V2 - Inception V3 - Inception V4 1. Inception v1 split - me ...
- 群等变网络的pytorch实现
CNN对于旋转不具有等变性,对于平移有等变性,data augmentation的提出就是为了解决这个问题,但是data augmentation需要很大的模型容量,更多的迭代次数才能够在训练数据集合 ...
- U-Net网络的Pytorch实现
1.文章原文地址 U-Net: Convolutional Networks for Biomedical Image Segmentation 2.文章摘要 普遍认为成功训练深度神经网络需要大量标注 ...
- ResNet网络的Pytorch实现
1.文章原文地址 Deep Residual Learning for Image Recognition 2.文章摘要 神经网络的层次越深越难训练.我们提出了一个残差学习框架来简化网络的训练,这些 ...
- AlexNet网络的Pytorch实现
1.文章原文地址 ImageNet Classification with Deep Convolutional Neural Networks 2.文章摘要 我们训练了一个大型的深度卷积神经网络用于 ...
- VGG网络的Pytorch实现
1.文章原文地址 Very Deep Convolutional Networks for Large-Scale Image Recognition 2.文章摘要 在这项工作中,我们研究了在大规模的 ...
- googLeNet网络
1.什么是inception结构 2.什么是Hebbian原理 3.什么是多尺度处理 最近深度学习的发展,大多来源于新的想法,算法以及网络结构的改善,而不是依赖于硬件,新的数据集,更深的网络,并且深度 ...
- SegNet网络的Pytorch实现
1.文章原文地址 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation 2.文章摘要 语义分 ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
随机推荐
- iOS-UIPasteboard的使用
剪贴板的使用以及自定义剪贴板. 系统剪贴板的直接调用 其实整个过程非常的简单,我就用我写的一个自定义UILable来说明调用系统剪贴板. 首先,因为苹果只放出来了 UITextView,UITextF ...
- RBF神经网络学习算法及与多层感知器的比较
对于RBF神经网络的原理已经在我的博文<机器学习之径向基神经网络(RBF NN)>中介绍过,这里不再重复.今天要介绍的是常用的RBF神经网络学习算法及RBF神经网络与多层感知器网络的对比. ...
- HTTP权威指南-报文与状态码
所有的报文都向下流动 报文流向 报文组成 HTTP方法 状态码 GET示例 HEAD示例 100~199 信息性状态码 200~299 成功状态码 300~399重定向状态码 400~499 客户端错 ...
- springboot的propteis的基本配置参考
其中mybatis.cfg.xml文件可以不加,这个文件最主要是开启mybatis的二级缓存:
- LeetCode 20. 有效的括号(Valid Parentheses)
20. 有效的括号 20. Valid Parentheses 题目描述 给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效. 有效字符串需满足: 左括号必须 ...
- WiFi、ZigBee、BLE用哪个?
小米是这么选的: 1) 插电的设备,用WiFi: 2) 需要和手机交互的,用BLE: 3) 传感器用ZigBee. WIFI,WIFI是目前应用最广泛的无线通信技术,传输距离在100-300M,速率可 ...
- ABP中的AutoMapper
在我们的业务中经常需要使用到类型之间的映射,特别是在和前端页面进行交互的时候,我们需要定义各种类型的Dto,并且需要需要这些Dto和数据库中的实体进行映射,对于有些大对象而言,需要赋值太多的属性,这样 ...
- (7)Spring Boot web开发 --- servlet容器
文章目录 配置嵌入式 Servlet 容器 注册 三大组件 使用其他 servlet 容器 使用外置的 `Servlet` 容器 配置嵌入式 Servlet 容器 Spirng Boot 默认使用自带 ...
- 机器学习-聚类-k-Means算法笔记
聚类的定义: 聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,它是无监督学习. 聚类的基本思想: 给定一个有N个对象的数据集 ...
- Symmetric Order
#include<stdio.h> int main() { ; ][]; ) { ;i<=n;i++) { scanf("%s",&str[i]); } ...