JDK源码那些事儿之LinkedBlockingQueue
今天继续讲解阻塞队列,涉及到了常用线程池的其中一个队列LinkedBlockingQueue,从类命名部分我们就可以看出其用意,队列中很多方法名是通用的,只是每个队列内部实现不同,毕竟实现的都是同一个接口BlockingQueue,可以自行查看接口源码,下面我们一起看下LinkedBlockingQueue实现的源码部分
前言
JDK版本号:1.8.0_171
LinkedBlockingQueue是链表实现的线程安全的无界的阻塞队列
- 内部是通过Node节点组成的链表来实现的
- 线程安全说明的是内部通过两个ReentrantLock锁保护竞争资源,实现了多线程对竞争资源的互斥访问,这里入队和出队互不影响
- 无界,默认链表长度为Integer.MAX_VALUE,本质上还是有界
- 阻塞队列,是指多线程访问竞争资源时,当竞争资源已被某线程获取时,其它要获取该资源的线程需要阻塞等待
队列通过Node对象组成的链表实现,与ArrayBlockingQueue不同的地方在于,ArrayBlockingQueue是有界的,初始化需指定长度,LinkedBlockingQueue不定义长度时,默认Integer.MAX_VALUE,相当于“无界”了,但是这样会造成一些问题,这部分后边说,同时保证并发和阻塞部分使用了2个互斥锁分别对入队和出队互斥操作,这样来看,独立开来提升了队列的吞吐量,入队和出队操作可同时进行
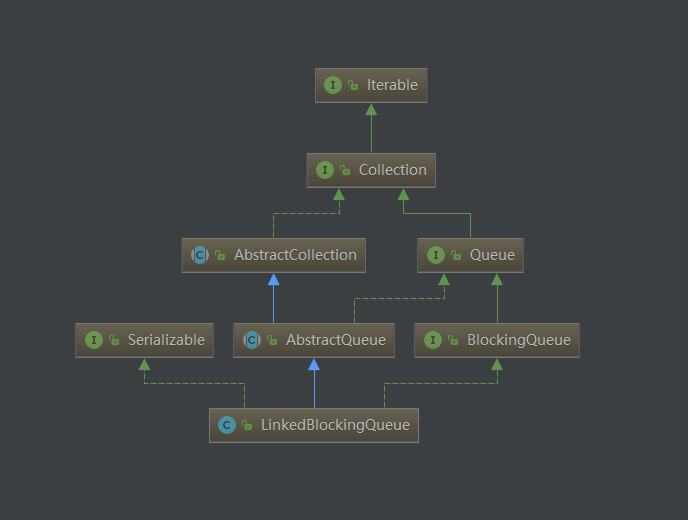
类定义
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable
常量/变量
/**
* Linked list node class
*
* 链表Node
* next引用指向后一个Node
*/
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
/** The capacity bound, or Integer.MAX_VALUE if none */
// 链表容量大小,不传参数,默认Integer.MAX_VALUE
// 这里final说明一旦确定链表容量就不能再改变了
private final int capacity;
/** Current number of elements */
// 队列实际包含元素的长度,这里使用了原子类保证数据的准确性
private final AtomicInteger count = new AtomicInteger();
/**
* Head of linked list.
* Invariant: head.item == null
*/
// 链表头节点,head.item == null
transient Node<E> head;
/**
* Tail of linked list.
* Invariant: last.next == null
*/
// 链表尾节点,last.next == null
private transient Node<E> last;
/** Lock held by take, poll, etc */
// 出队操作互斥锁
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
// 非空信号量,当无元素时阻塞等待入队操作
private final Condition notEmpty = takeLock.newCondition();
// 入队操作互斥锁
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
// 非满信号量,当队列已满时阻塞等待出队操作
private final Condition notFull = putLock.newCondition();
构造方法
无参构造方法中默认取Integer.MAX_VALUE,使得链表容量限制为最大值,同时初始化头尾节点,值置为null
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
// 这里使用锁的原因和ArrayBlockingQueue相同,确保可见性,因为链表本身并不保证可见性,防止并发操作下链表不一致的情况出现
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
// 设置队列长度
count.set(n);
} finally {
putLock.unlock();
}
}
重要方法
signalNotEmpty/signalNotFull
在每次唤醒非空信号量的等待线程时,需要先获取出队互斥锁,简单说,就是当队列为空时,有线程在执行出队操作,通过notEmpty.await()阻塞等待,这时有线程入队操作,调用signalNotEmpty()唤醒执行notEmpty.await()的阻塞线程,在唤醒这个线程之前必须拿到takeLock互斥锁,为什么?因为执行唤醒操作的时候要获取到该signal对应的Condition对象的锁才行,在ArrayBlockingQueue中是同样的操作
/**
* Signals a waiting take. Called only from put/offer (which do not
* otherwise ordinarily lock takeLock.)
*/
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
/**
* Signals a waiting put. Called only from take/poll.
*/
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
enqueue/dequeue
入队出队最终调用的方法,enqueue方法首先将原尾节点的next引用指向新节点,然后将尾节点更新为新节点。dequeue方法移除头节点,更新头节点,注意这里实际上返回的节点是第二个节点,因为头节点head.item == null
/**
* Links node at end of queue.
*
* @param node the node
*/
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
last = last.next = node;
}
/**
* Removes a node from head of queue.
*
* @return the node
*/
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
// 使用h保存原头节点,头节点这里head.item == null
Node<E> h = head;
// 使用first保存原头节点之后的节点,实际上的第一个节点,我们需要的出队节点也是这个节点
Node<E> first = h.next;
// 原头节点next指向自己,这里指向自己在后边迭代器中nextNode方法中有用到,通过这种方式判断节点类型
h.next = h; // help GC
// 头节点更新为第二个节点
head = first;
// 保存第二个节点的值
E x = first.item;
// 更新头节点head.item == null,之后这个节点将作为头节点
first.item = null;
return x;
}
fullyLock/fullyUnlock
两个操作全部加锁,在删除,验证是否包含某个元素,迭代等操作中使用
/**
* Locks to prevent both puts and takes.
*/
void fullyLock() {
putLock.lock();
takeLock.lock();
}
/**
* Unlocks to allow both puts and takes.
*/
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
put
put入队操作,队列已满时阻塞等待,队列未满则插入队列同时判断是否唤醒其他入队线程和出队线程,几种入队操作区别同ArrayBlockingQueue中的说明,这里不再一一说明了
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// 可中断putLock锁
putLock.lockInterruptibly();
try {
// 队列已满则入队操作线程阻塞等待
while (count.get() == capacity) {
notFull.await();
}
// 队列未满则入队操作
enqueue(node);
// 原子类更新队列长度值,返回值为原count的值
c = count.getAndIncrement();
// 再次判断队列是否有可用空间,如果有唤醒下一个线程进行添加操作
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 队列原本有0条数据,现在有了1条数据,则唤醒消费线程进行消费
// 因为原本队列无元素,消费线程都被阻塞,只需要判断有一条数据的时候就可以
if (c == 0)
signalNotEmpty();
}
take
take出队操作,队列为空时阻塞等待,队列非空时则出队同时队列长度减1,同时判断是否唤醒其他出队操作,方法区别同样可参考前面的ArrayBlockingQueue文章
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
// 队列为空则等待
while (count.get() == 0) {
notEmpty.await();
}
// 出队操作
x = dequeue();
// 减1
c = count.getAndDecrement();
// 队列是否有可用空间
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 队列原本是满的状态,现在一条数据出队,则可以唤醒非满信号量,进行入队操作
if (c == capacity)
signalNotFull();
return x;
}
unlink
remove操作调用,删除p与trail节点之间的关系,重新构建p.next节点和trail节点关系,相当于删除p节点后对引用的处理
/**
* Unlinks interior Node p with predecessor trail.
*/
void unlink(Node<E> p, Node<E> trail) {
// assert isFullyLocked();
// p.next is not changed, to allow iterators that are
// traversing p to maintain their weak-consistency guarantee.
// 删除节点置空
p.item = null;
// 删除节点前一个节点指向删除节点的后一个节点
trail.next = p.next;
// p是最后一个节点,则删除p后最后一个节点为trail
if (last == p)
last = trail;
// 删除p之前队列是已满状态则删除p后调用notFull.signal()唤醒入队线程操作
if (count.getAndDecrement() == capacity)
notFull.signal();
}
contains
判断是否包含某个对象,在执行时需同时获得入队锁和出队锁,保证在判断过程中不会有数据的变更。在toArray,toString,clear方法中都是如此
/**
* Returns {@code true} if this queue contains the specified element.
* More formally, returns {@code true} if and only if this queue contains
* at least one element {@code e} such that {@code o.equals(e)}.
*
* @param o object to be checked for containment in this queue
* @return {@code true} if this queue contains the specified element
*/
public boolean contains(Object o) {
if (o == null) return false;
// 获取两个锁
fullyLock();
try {
// 正常循环判断
for (Node<E> p = head.next; p != null; p = p.next)
if (o.equals(p.item))
return true;
return false;
} finally {
fullyUnlock();
}
}
drainTo
一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁,在接口中已经声明这个方法,在ArrayBlockingQueue中同样有这个方法
public int drainTo(Collection<? super E> c, int maxElements) {
// 检查
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
if (maxElements <= 0)
return 0;
// 唤醒非满信号量为false
boolean signalNotFull = false;
final ReentrantLock takeLock = this.takeLock;
// 获取takeLock互斥锁
takeLock.lock();
try {
// 获取能获取队列的正常长度
int n = Math.min(maxElements, count.get());
// count.get provides visibility to first n Nodes
Node<E> h = head;
int i = 0;
try {
// 将值放入c
while (i < n) {
Node<E> p = h.next;
c.add(p.item);
p.item = null;
h.next = h;
h = p;
++i;
}
// 返回获取的队列长度n
return n;
} finally {
// Restore invariants even if c.add() threw
// 重新保存常量
if (i > 0) {
// assert h.item == null;
head = h;
// getAndAdd返回未执行前的值,与队列容量相等,则说明之前队列是已满状态,入队线程全部阻塞,
// 而这里i > 0 则表明此时操作完队列未满可以唤醒入队线程
signalNotFull = (count.getAndAdd(-i) == capacity);
}
}
} finally {
takeLock.unlock();
// 唤醒入队线程
if (signalNotFull)
signalNotFull();
}
}
迭代器及内部类
每次调用iterator创建Itr内部类,与ArrayBlockingQueue不同,LinkedBlockingQueue,内部类Itr没有那么复杂,通过fullyLock和fullyUnlock方法在每次迭代时需要获取锁才能操作,保证不会数据错乱
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
/*
* Basic weakly-consistent iterator. At all times hold the next
* item to hand out so that if hasNext() reports true, we will
* still have it to return even if lost race with a take etc.
*/
private Node<E> current;
private Node<E> lastRet;
private E currentElement;
Itr() {
fullyLock();
try {
// 保存头节点的下一个节点,头节点是无值的
current = head.next;
if (current != null)
// 获取第一个有值的数据
currentElement = current.item;
} finally {
fullyUnlock();
}
}
public boolean hasNext() {
return current != null;
}
/**
* Returns the next live successor of p, or null if no such.
*
* Unlike other traversal methods, iterators need to handle both:
* - dequeued nodes (p.next == p)
* - (possibly multiple) interior removed nodes (p.item == null)
*/
// 找到迭代的下一个节点
private Node<E> nextNode(Node<E> p) {
for (;;) {
Node<E> s = p.next;
// p.next == p 说明已经出队,上边方法dequeue中有提到
// 这里直接使用head.next即可
if (s == p)
return head.next;
// 节点为空或者节点值不为空则返回这个节点
// 节点为空说明是队列尾,直接返回即可
// 节点值不为空说明已找到下一个节点,同样返回
if (s == null || s.item != null)
return s;
// s.item == null 可能节点被删除了,则继续判断下一个节点
p = s;
}
}
public E next() {
fullyLock();
try {
if (current == null)
throw new NoSuchElementException();
E x = currentElement;
// 保存上次迭代的值
lastRet = current;
// 计算保存下次迭代值
current = nextNode(current);
currentElement = (current == null) ? null : current.item;
return x;
} finally {
fullyUnlock();
}
}
// 调用迭代的remove删除的是lastRet对应的值
public void remove() {
if (lastRet == null)
throw new IllegalStateException();
fullyLock();
try {
Node<E> node = lastRet;
lastRet = null;
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
if (p == node) {
// 删除p,调整链表
unlink(p, trail);
break;
}
}
} finally {
fullyUnlock();
}
}
}
使用说明
对于新手而言,LinkedBlockingQueue队列在线程池的使用中可能会出现一些问题,主要问题在于其创建的方式,新手使用封装类提供的方法,比如下面示例代码:
ExecutorService pool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
pool.submit(() -> System.out.println(Thread.currentThread().getName()));
}
从源码中我们可以看到其创建线程池时使用的队列方式如下:
new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
这会造成什么问题呢?
默认无参构造,从LinkedBlockingQueue源码部分我们也能看到无参时默认链表最大容量为Integer.MAX_VALUE,假如我们设置了核心线程数和最大线程数都为5之后,如果线程一直被占用而没有释放,同时又有很多任务向线程池申请线程使用,这时我们会将任务放入队列中保存,生产者的速度远大于消费者,堆积的请求处理队列可能会耗费非常大的内存,甚至OOM
所以阿里规范中提及了这部分内容,指出了其中存在的隐患,需要规避资源耗尽的风险,开发人员应直接使用ThreadPoolExecutor来创建线程池,每个参数需要根据自己的需求进行设置
总结
通过对LinkedBlockingQueue源码的解读我们可以了解到如下与ArrayBlockingQueue不同的内容:
- 内部通过Node对象链表实现
- 内部有2个Lock,分别对应入队和出队操作,两者可同时进行,提高了吞吐量
- 线程池使用LinkedBlockingQueue时,最好根据需要自行创建,设置大小,否则有可能引起OOM问题
以上内容如有问题欢迎指出,笔者验证后将及时修正,谢谢
JDK源码那些事儿之LinkedBlockingQueue的更多相关文章
- JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue
JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue 目的:本文通过分析JDK源码来对比ArrayBlockingQueue 和LinkedBlocki ...
- JDK源码那些事儿之并发ConcurrentHashMap上篇
前面已经说明了HashMap以及红黑树的一些基本知识,对JDK8的HashMap也有了一定的了解,本篇就开始看看并发包下的ConcurrentHashMap,说实话,还是比较复杂的,笔者在这里也不会过 ...
- JDK源码那些事儿之红黑树基础下篇
说到HashMap,就一定要说到红黑树,红黑树作为一种自平衡二叉查找树,是一种用途较广的数据结构,在jdk1.8中使用红黑树提升HashMap的性能,今天就来说一说红黑树,上一讲已经给出插入平衡的调整 ...
- JDK源码那些事儿之浅析Thread上篇
JAVA中多线程的操作对于初学者而言是比较难理解的,其实联想到底层操作系统时我们可能会稍微明白些,对于程序而言最终都是硬件上运行二进制指令,然而,这些又太过底层,今天来看一下JAVA中的线程,浅析JD ...
- JDK源码那些事儿之LinkedBlockingDeque
阻塞队列中目前还剩下一个比较特殊的队列实现,相比较前面讲解过的队列,本文中要讲的LinkedBlockingDeque比较容易理解了,但是与之前讲解过的阻塞队列又有些不同,从命名上你应该能看出一些端倪 ...
- JDK源码那些事儿之ConcurrentLinkedDeque
非阻塞队列ConcurrentLinkedQueue我们已经了解过了,既然是Queue,那么是否有其双端队列实现呢?答案是肯定的,今天就继续说一说非阻塞双端队列实现ConcurrentLinkedDe ...
- JDK源码那些事儿之ConcurrentLinkedQueue
阻塞队列的实现前面已经讲解完毕,今天我们继续了解源码中非阻塞队列的实现,接下来就看一看ConcurrentLinkedQueue非阻塞队列是怎么完成操作的 前言 JDK版本号:1.8.0_171 Co ...
- JDK源码那些事儿之LinkedTransferQueue
在JDK8的阻塞队列实现中还有两个未进行说明,今天继续对其中的一个阻塞队列LinkedTransferQueue进行源码分析,如果之前的队列分析已经让你对阻塞队列有了一定的了解,相信本文要讲解的Lin ...
- JDK源码那些事儿之DelayQueue
作为阻塞队列的一员,DelayQueue(延迟队列)由于其特殊含义而使用在特定的场景之中,主要在于Delay这个词上,那么其内部是如何实现的呢?今天一起通过DelayQueue的源码来看一看其是如何完 ...
随机推荐
- SPSS 2019年10月24日 今日学习总结
2019年10月24日今日课上内容1.SPSS掌握基于键值的一对多合并2.掌握重构数据3.掌握汇总功能 内容: 1.基于键值的一对多合并 合并文件 添加变量 合并方法:基于键值的一对多合并 变量 2. ...
- SPSS数据分析基础考题
选择题 1. SPSS发行版本的说法,正确的是: B A. 两年发行一个新版本 B.一年发行一个新版本 C.没有任何规律 D.三年发行三个新版本 2.哪些是SPSS统计分析软件的基本窗口: A A.结 ...
- 克隆指定的分支:git clone -b 分支名仓库地址
克隆指定的分支:git clone -b 分支名仓库地址 git clone -b 分支名 仓库地址 -b 是在克隆的时候制定一个分支
- Nginx里的root/index/alias/proxy_pass的意思
1.[alias] 别名配置,用于访问文件系统,在匹配到location配置的URL路径后,指向[alias]配置的路径.如: location /test/ { alias /home/sftp/i ...
- [WCF] - 使用 [DataMember] 标记的数据契约需要声明 Set 方法
WCF 数据结构中返回的只读属性 TotalCount 也需要声明 Set 方法. [DataContract]public class BookShelfDataModel{ public B ...
- Java中的事务及使用
什么是事务? 事务(Transaction),一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit).事务通常由高级数据库操纵语言或编程语言(如S ...
- 18 COUNTIF函数
求大于小于等于某个数字的数字有多少 格式:=COUNTIF(数据区,"条件") 注意条件需要用英文双引号引起来. 举个例子: =COUNTIF(A2:D5,">20 ...
- PAT甲级题分类汇编——图
本文为PAT甲级分类汇编系列文章. 图,就是层序遍历和Dijkstra这一套,#include<queue> 是必须的. 题号 标题 分数 大意 时间 1072 Gas Station 3 ...
- Linux下磁盘分区,格式化以及挂载
测试环境:VMware Workstation / centos7 1.磁盘分区 (1)易于管理和使用: 比如说我们把磁盘分了sda1.sda2.sda3.sda4盘,我们假设sda1盘为系统盘,其他 ...
- 记录MindSphere On Cloud Foundry的一次尝试过程
试验背景: 开始时间:2019年12月11日 结束时间:2019年12月13日 自己编写一个后台程序,尝试推送到Cloud Foundry上,并开放从MindSphere以外访问的权限. 程序实现以下 ...