结合docker做flask+kafka数据接口与压力测试
一、需求
需要做实时数据接入的接口、数据最终要写入库,要做到高并发,数据的完整,不丢失数据。
二、技术选型
1.因为只是做简单的接口,不需要复杂功能,所以决定用flask这个简单的python框架(因为做运维的作者只会python所以只能在python框架里找);
2.要做到数据的实时性,考虑到数据落地入库可能io会延时比较大,所以决定数据通过接口先写入消息队列中间件kafka
(为什么用kafka因为kafka数据是顺序写文件,效率还可以,主要是的写入文件可以保证自定义时间内的数据不丢失;kafka可以做集群提高性能;kafka支持同一个group下多个消费程序对同一个topic处理;如果听不懂请自己学习kafka相关知识)
3.因为考虑到后期的快速部署与迁移问题,所以决定结合docker来做。(主要是为了装逼,再有就是回顾一下docker知识)
三、原理图
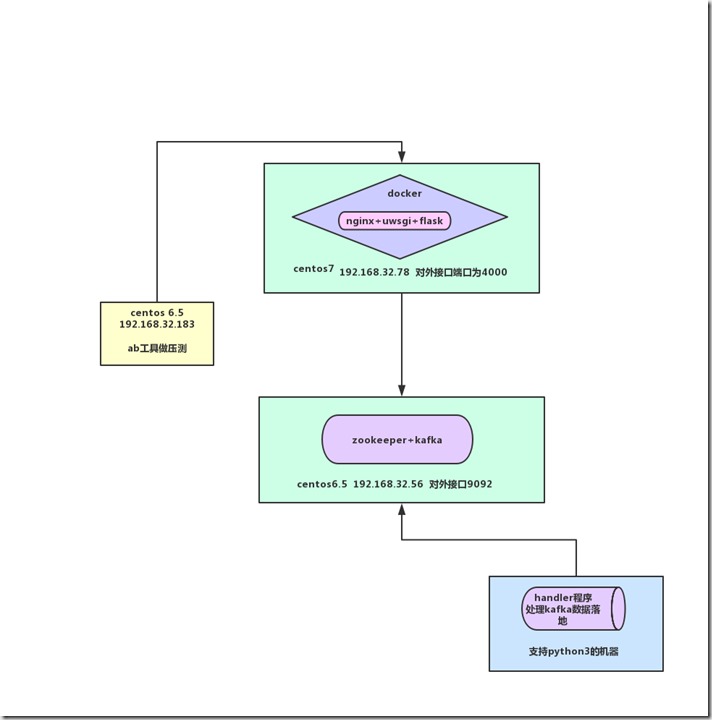
(条件可以的话,zookeeper+kafka也可以做成docker镜像,这里这样做是作者的服务器资源有限;也方便后面压力测试,所以各个程序都独立开)
四、操作过程
1.安装配置kafka
(1)、在服务器上先安装java环境yum install java-1.8.0-openjdk* –y
(2)、下载kafka包kafka_2.11-2.1.1.tgz;解压到指定目录下;
cd /data/kafka_2.11-2.1.1/目录
bin/zookeeper-server-start.sh –daemon config/zookeeper.properties &
配置kafka配置文件 config/server.properties开启listeners=PLAINTEXT://:9092(kafka监听0.0.0.0:9092端口不开启默认是localhost:9092);添加delete.topic.enable=true(允许指定删除topic;默认为flase;kafka_2.11-2.1.1/bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic xxxx);log.retention.hours=168(数据保留时间默认为168小时);log.segment.bytes=1073741824(最大segment数据文件大小为1G;单位字节);
开启kafka服务
bin/kafka-server-start.sh config/server.properties &
如果安装了nohup可以用nohup bin/kafka-server-start.sh config/server.properties & 开启不会在退出终端时退出程序。
(3)、netstat –tpln看到9092和2181都已经监听起来就OK再检查selinux是否关闭,iptables是否放通
2.制做nginx+uwsgi+flask的docker镜像
(1)、下载centos6.6的docker基础境像到docker;运行后安装nginx和python3(安装python3下载python3的tar包到服务器解压;创建目录/usr/local/python3;进入python3解压目录./configure --prefix=/usr/local/python3;make && make install ; ln –s /usr/local/python3/bin/python3 /usr/bin;ln –s /usr/local/python3/bin/pip3 /usr/bin)
(2)、安装uwsgi;pip3 install uwsgi;ln –s /usr/local/python3/bin/uwsgi /usr/bin;
(3)、安装flask;pip3 install flask;
(4)、安装python3 kafka相关包(pip3 install kakfa-python;pip3 install kafka [这个包方便在运行kafka-python下KafkaProducer方法时有错误话有报错输出,不然有问题是没有报错的 坑死了])
(5)、创建目录/data/webapi
(6)、在/etc/hosts下加上kafka服务器的hostname的解析;不然服务器是无法发消息到kafka的大坑原因:是从zookeeper获取broker的meta信息时候返回的不是IP而是hostname
(7)、配置启动nginx和uwsgi脚本startnguw.sh如下:
#!/bin/bash
sh /root/nginx_ops.sh start
nohup uwsgi /data/webapi/app.ini &
tail -f /dev/null
(注意nginx作者是脚本安装的,安装好就有nginx_ops.sh的启动脚本;app.ini是uwsgi的配置文件;tail –f /dev/null这个是方便用docker-compose启动加的不加用docker-compose启动的话就会有直重启docker)
(8).配置/usr/local/nginx/config/vhosts/webapi.conf如下:
server {
listen 4000;
server_name 0.0.0.0;
location / {
include uwsgi_params;
uwsgi_pass unix:/data/webapi/webapi.sock;
}
}
(这里指定端口是4000;uwsgi是用的webapi.sock套接字,也可以用ip加端口具体看app.ini的uwsgi的配置文件是怎么配置的;)
以上配置好就可以通过docker commit –p 原docker名字 新docker名字保存为新的包含新安装内容的docker镜像;如果有阿里cr.console.aliyun.com或hub.docker账号的可以命名为自己账号下的仓库名加版本号上传。
作者已经做好了;地址为 registry.cn-shenzhen.aliyuncs.com/wuxiaozy/nguwsgi:v0.2
3.在centos7服务器上配置docker-compose.yml通过docker-compose运行容器
(1)、在centos7上安装docker-compose
(2)、创建目录/usr/local/nguwsgi
(3)、创建文件docker-compose.yml内容如下:
version: '2'
services:
nguw:
image: registry.cn-shenzhen.aliyuncs.com/wuxiaozy/nguwsgi:v0.2
container_name: nguwsgi01
restart: always
dns_search: .
cap_add:
- ALL
volumes:
- /data/webapi:/data/webapi
ports:
- 4000:4000
networks:
- luntan
command:
- /bin/bash
- -c
- |
/bin/bash /root/startnguw.sh
networks:
luntan:
external: false
(注意:volumes为把centos7下的/data/webapi目录映射到nguwsgi01这个docker容器的/data/webapi目录前提是容器要有/data/webapi这个目录;port表示把docker容器的4000端口映射成本机的4000端口)
(4)、在centos7的/data/webapi目录下上传flask项目和app.ini uwsgi的配置文件
uwsgi配置文件如下:
[uwsgi]
base_dir = /data/webapi
chdir = /data/webapi
wsgi-file = myflask.py
callable = app socket = %(base_dir)/webapi.sock
chmod-socket = 666 processes = 4
threads = 10 master = true
daemonize = %(base_dir)/chat.log
pidfile = %(base_dir)/chat.pid
(注意myflask.py是flask的主启动文件;socker这个配置和nginx下webapi.conf配置的 uwsgi_pass有关,这里配置是webapi.sock话nginx配置也是webapi.sock;process和threads表示uwsgi开多少个进程,每个进程开多少个线程和uwgi的性能配置有关)
flask内容如下:
#from gevent import monkey
#monkey.patch_all() from flask import Flask,render_template,request
from kafka import KafkaProducer
import json #from gevent.pywsgi import WSGIServer app = Flask(__name__) @app.route('/')
def hello_world():
return 'Hello World!' @app.route('/hello')
@app.route('/hello/<name>')
def hello(name=None):
return render_template('hello.html',name=name) @app.route('/user/<username>')
def show_user_profile(username):
return "hello Mr %s"%(username) @app.route('/financial_pro',methods=['GET','POST'])
def financial_pro():
if request.method == 'POST':
data = request.form
producer = KafkaProducer(bootstrap_servers=['192.168.32.56:9092'],value_serializer=lambda v: json.dumps(v).encode("utf-8"))
response = producer.send('financial_pro',data)
producer.flush()
print(response)
return "OK"
else:
return "Methods Error" if __name__ == '__main__':
app.run(host="0.0.0.0",port=4000,threaded=True)
#http_server = WSGIServer(('0.0.0.0',4000),app)
#http_server.serve_forever()
(注意:/;/hello;/user/name;这些是测试网页;financial_pro是接口;在安装了flask的python3环境下python3 myflask.py是可以开启web服务的只是性能差高并发下会的数据丢失;也可以用gevent+flask开启性能也没有nginx+uwsgi高)
(5)、开启nguwsgi01这个docker容器
cd /usr/local/nguwsgi目录下动行 docker-compose up –d(如果docker-compose.yml文件名字不叫这个就要用docker-compose –f xxxx.yml up –d)
4.编写handler程序从kafka读取数据实现数据的落地;
内容如下:(python3编写需要pip3 install kafka-python)
from kafka import KafkaConsumer
import json
from multiprocessing import Pool
import time
import threading ##定义参数
#程序处理的接口
handler_API = ["identity_pro","financial_pro","internet_pro","social_pro","trip_pro","communication_pro"]
#不同接口处理程序group_id
gids = {"identity_pro":"ide_g","financial_pro":"fin_g","internet_pro":"int_g","social_pro":"soc_g","trip_pro":"tri_g","communication_pro":"com_g"}
#不同group_id下消费程序的数量
xf = {"identity_pro":1,"financial_pro":1,"internet_pro":1,"social_pro":1,"trip_pro":1,"communication_pro":1}
#kafka服务器地址和端口
kafka_servers=["192.168.32.56:9092"]
#各接口数据字段数
check_data = {"identity_pro":7,"financial_pro":4,"internet_pro":5,"social_pro":3,"trip_pro":3,"communication_pro":4} class Handler(object):
def __init__(self,handler_API,gids,xf,kafka_servers,check_data):
self.hanapi = handler_API
self.gids = gids
self.xf = xf
self.kafka_servers = kafka_servers
self.check_data = check_data def conumers(self,api_name,kfksers):
gid = self.gids[api_name]
# eraliest为从最早的偏移量开始
#con = KafkaConsumer(api_name,bootstrap_servers=[kfksers],auto_offset_reset="earliest",value_deserializer=json.loads)
#auto_offset_reset默认为latest
con = KafkaConsumer(api_name, bootstrap_servers=[kfksers], auto_offset_reset="latest",value_deserializer=json.loads)
Tm = time.strftime("%Y-%m-%d %H:%M:%S")
for message in con:
print("[%s] %s:%d:%d:key:%s"%(Tm,message.topic,message.partition,message.offset,message.key))
data = message.value
if int(self.check_data[api_name]) == len(data.keys()):
print(data)
with open("d:/%s.txt"%api_name,"a") as F:
F.write("[%s]--%s\n"%(Tm,data))
F.close()
else:
print("%s--数据字段不符合要求!!!"%data)
with open("d:/%s.txt"%api_name,"a") as F:
F.write("[%s]--%s--%s"%(Tm,data,"数据字段数不符合要求!!!\n"))
F.close() def conumers_thread_num(self,api_name,kfksers):
thread_num = int(self.xf[api_name])
for i in range(thread_num):
t = threading.Thread(target=conumers_wrapper,args=(self,api_name,kfksers))
t.setDaemon(True)
t.start()
t.join() def multirun(self):
p = Pool(5)
for i in range(int(len(self.hanapi))):
api_name = self.hanapi[i]
kfksers = ",".join(self.kafka_servers)
print("开启子进程%s"%i)
p.apply_async(conumers_thread_num_wrapper,args=(self,api_name,kfksers))
print('等待所有添加的进程运行完毕。。。')
p.close()
p.join() def conumers_wrapper(cls_instance,api_name,kfksers):
return cls_instance.conumers(api_name,kfksers) def conumers_thread_num_wrapper(cls_instance,api_name,kfksers):
return cls_instance.conumers_thread_num(api_name,kfksers) if __name__ == "__main__":
Hd = Handler(handler_API,gids,xf,kafka_servers,check_data)
Hd.multirun()
(注意:脚本通过修改参数可以支持kafka集群和kafka 同一goup_id下多consumer消费进程;)
5.在服务器centos6.5 ip:192.168.32.183上ab压测
安装httpd-ab;yum install httpd-ab
压测命令:
time ab -c 100 -n 10000 -T 'application/x-www-form-urlencoded' -p /tmp/wx20191010.txt http://192.168.32.78:4000/financial_pro
/tmp/wx20191010.txt内容为test01=111&test02=222&test03=ccc&test04=ddd
(-c 100是100个并发; –n 10000是10000次请求;-T http头;-p是post数据文件)
测试结果:
python3 myflask.py的情况下 100个并发10000次请求;cpu 70%;耗时1m49秒;有大约500~600个数据丢失;
nginx+uwsgi+flask下(四个进程processes=4;4线程threads=4);cpu 30%;耗时1m30秒;没有数据丢失;
nginx+uwsgi+flask下(四个进程processes=4;4线程threads=10);cpu 60%;耗时49秒;没有数据丢失;
结合docker做flask+kafka数据接口与压力测试的更多相关文章
- 使用COSBench工具对ceph s3接口进行压力测试--续
之前写的使用COSBench工具对ceph s3接口进行压力测试是入门,在实际使用是,配置内容各不一样,下面列出 压力脚本是xml格式的,套用UserGuide文档说明,如下 有很多模板的例子,在co ...
- 单机Web后端接口服务压力测试
单机Web后端接口服务压力测试 工具:Apache jmeter 环境:Window 10 语言:Kotlin + java 架构:SpringBoot + + Mysql + redis + Spr ...
- python学习笔记(threading接口性能压力测试)
又是新的一周 延续上周的进度 关于多进程的学习 今天实践下 初步设计的接口性能压力测试代码如下: #!/usr/bin/env python # -*- coding: utf_8 -*- impor ...
- AI-序列化-做五个数据接口
#url.py url(r'^customer/$', views.CustomerView.as_view()), #查询所有数据.添加数据接口url url(r'^customer/(\d+)', ...
- kafka性能参数和压力测试揭秘
转自:http://blog.csdn.net/stark_summer/article/details/50203133 上一篇文章介绍了Kafka在设计上是如何来保证高时效.大吞吐量的,主要的内容 ...
- 使用 WRK 压力测试工具对 ASP.NET Core 的接口进行压力测试
0. 简要介绍 WRK 是一款轻量且易用的 HTTP 压力测试工具,通过该工具我们可以方便地对我们所开发的 WebAPI 项目进行压力测试,并且针对测试的情况返回结果. PS:Wrk 并不能针对测试的 ...
- JMeter工具接口性能压力测试分析与优化
最近公司做的项目,要求对相关接口做性能压力测试,在这里记录一下分析解决过程. 压力测试过程中,如果因为资源使用瓶颈等问题引发最直接性能问题是业务交易响应时间偏大,TPS逐渐降低等.而问题定位分析通常情 ...
- Jmter接口网站压力测试工具使用记录
1.首先下载Jmeter 官方地址:http://jmeter.apache.org/ 2.安装Jmeter 把下载的文件进行解压,产生如下目录: 打开bin文件夹下的jmeter.bat文件及进入程 ...
- 使用COSBench工具对ceph s3接口进行压力测试
一.COSBench安装 COSBench是Intel团队基于java开发,对云存储的测试工具,全称是Cloud object Storage Bench 吐槽下,貌似这套工具是intel上海团队开发 ...
随机推荐
- 3622 假期(DP+单调队列优化)
3622 假期 时间限制: 1 s 空间限制: 64000 KB 题目等级 : 黄金 Gold 题目描述 Description 经过几个月辛勤的工作,FJ决定让奶牛放假.假期可以在1-N天内任意选择 ...
- java源码学习(一)String
String表示字符串,Java中所有字符串的字面值都是String类的实例,例如"ABC".字符串是常量,在定义之后不能被改变,字符串缓冲区支持可变的字符串.因为 String ...
- mac重启nginx时报nginx.pid不存在的解决办法
在安装nginx后,重启时发现报 nginx: [error] open() "/usr/local/var/run/nginx.pid" failed (2: No such f ...
- jQuery文档操作之克隆操作
语法: $(selector).clone(); 解释:克隆匹配的DOM元素 $("button").click(function(event) { //1.clone():克隆匹 ...
- Ubuntu安装之pycharm安装
什么??公司要用Ubuntu(乌班图)?不会用??怎么进行python开发??? 乌班图操作系统下载地址:http://releases.ubuntu.com/18.04/ubuntu-18.04.1 ...
- 关于lower_bound()和upper_bound()
关于lower_bound()和upper_bound(): 参考:关于lower_bound( )和upper_bound( )的常见用法 注意:查找的数组必须要是排好序的.因为,它们查找的方式也是 ...
- 输出变量的界值(int、float、long.....)
//整型.浮点型变量表示的关键字,并给出它们各自的界值 #include<iostream> #include<climits> //包含整型数据范围的头文件 #include ...
- anaconda环境管理
创建新环境 conda create -n rcnn python=3.6 删除环境 conda remove -n rcnn --all 重命名环境 参考SO:https://stackoverfl ...
- ELK- elasticsearch 讲解,安装,插件head,bigdesk ,kopf,cerebro(kopf升级版)安装
ElasticSearch:简称es ,分布式全文搜索引擎,使用java语言开发,面向文档型数据库,一条数据就是一个文档,数据用json序列化后存储. 默认端口:9200 借助redis来理解 red ...
- Python中异常和JSON读写数据
异常可以防止出现一些不友好的信息返回给用户,有助于提升程序的可用性,在java中通过try ... catch ... finally来处理异常,在Python中通过try ... except .. ...