Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机,增加更多的slave只需重复slave部分的内容即可。
系统版本:
- master:Ubuntu 12.04
- slave:Ubuntu 12.04
- hadoop:hadoop 2.2.0
- 安装ssh服务:sudo apt-get install ssh
- 有时也要更新一下vim:sudo apt-get install vim #刚安装的系统会出现vi 命令上下键变成AB的情况
1. 为master和slave机器安装JDK环境
下载jdk,如果安装版本“1.7.0_60”,官方下载地址为:java下载
解压jdk: tar -xvf jdk-7u60-linux-i586.tar.gz
在/usr/local/下新建java文件夹:mkdir /usr/local/java
将解压文件移动到创建的java/文件夹下:sudo mv jdk1.7.0_60 /usr/local/java
修改/etc/profile文件:sudo vi /etc/profile
在文件末尾添加jdk路径:

输入 source /etc/profile 使java生效
测试java是否完全安装:java -version #若出现版本信息则说明安装成功
2. 修改namenode(master)和子节点(slave)机器名:
sudo vi /etc/hostname
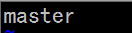

修改后需重启才生效:sudo reboot
3. 修改namenode(master)节点映射ip
sudo vi /etc/hosts #添加slave和master的机器名及其对应ip
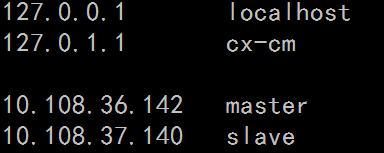
PS:master、slave分别是namenode和datanode机器名,即hostname的名字
4. 为master和slave分别创建hadoop用户及用户组,并赋予sudo权限
sudo addgroup hadoop
sudo adduser -ingroup hadoop hadoop #第一个hadoop是用户组,第二个hadoop是用户名
下面为hadoop用户赋予sudo权限:修改 /etc/sudoers 文件
sudo vi /etc/sudoers
添加hadoop ALL=(ALL:ALL) ALL
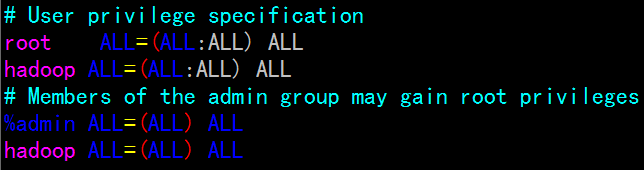
PS:该操作需要在所有master和slave主机上进行
5. 建立ssh无密码登陆环境
以hadoop身份登录系统:su hadoop
生成密钥,建立namenode与datanode的信任关系,ssh生成密钥有rsa和dsa方式,默认采用rsa方式:
在/home/hadoop目录下输入: ssh-keygen -t rsa -P ""
确认信息按回车,会在/home/hadoop/.ssh下生成文件:
将id_rsa.pub追加到authorized_keys授权文件中: cat id_rsa.pub >> authorized_keys

在各个子节点也生成密钥:ssh-keygen -t rsa -P ""
将master上的authorized_keys发送到各个子节点:
scp ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/
下面测试ssh互信: ssh hadoop@slave1
如果不需要输入密码就可以登录成功则表示ssh互信成功建立
6. 安装hadoop(只需配置master主机,slave主机可以直接复制)
下载hadoop到/usr/local下:下载地址
解压hadoop-2.2.0.tar.gz:sudo tar -zxf hadoop-2.2.0.tar.gz
将解压出来的文件夹重命名为hadoop: sudo mv hadoop-2.2.0 hadoop
将hadoop文件夹的属主用户设为hadoop:sudo chown -R hadoop:hadoop hadoop
6.1 配置etc/hadoop/hadoop-env.sh文件
sudo vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到“export JAVA_HOME=”部分,修改为本机jdk路径

6.2 配置etc/hadoop/core-site.xml文件
sudo vi /usr/local/hadoop/etc/hadoop/core-site.xml
在<configuration></configuration>中间添加如下内容:

PS:master为namenode主机名,即/etc/hosts文件里的名字
6.3 配置etc/hadoop/mapred-site.xml文件,若路径下没有此文件,则将mapred-site.xml.template重命名
sudo vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
在<configuration></configuration>中间添加如下内容:

PS:master为namenode主机名,即/etc/hosts文件里的名字
6.4 配置hdfs-site.xml文件,若路径下没有此文件,则将hdfs-site.xml.template重命名
sudo vi hdfs-site.xml
在<configuration></configuration>中间添加如下内容:

PS:若有多个slave节点,则将<value>间的内容可改为:
- <value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2,...</value>
- <value>/usr/local/hadoop/data1,/usr/local/hadoop/data2,...</value>
- <value></value>中间的数字表示slave节点数
6.5 向slaves文件中添加slave主机名,一行一个
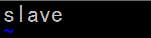
7.向slave节点分发配置文件
将配置文件发送到所有slave子节点上,先将文件复制到子节点/home/hadoop/下面(子节点也用hadoop用户登录:su hadoop)
sudo scp /etc/hosts hadoop@slave1:/home/hadoop
scp -r /usr/local/hadoop hadoop@slave1:/home/hadoop
PS:slave1为slave子节点名,若有多个slave节点,应全部分发
在datanode机器上(slave节点)将文件移动到与master相同的路径下
sudo mv /home/hadoop/hosts /etc/hosts (在子节点上执行)
sudo mv /home/local/hadoop /usr/local/ (在子节点上执行)
PS:若提示mv文件夹,则加上-r 参数
加入所属用户: sudo chown -R hadoop:hadoop hadoop (在子节点上执行)
PS:子节点datanode机器要把复制过来的hadoop里面的data1,data2和logs删除掉!
配置完成
PS:可以将hadoop命令路径写入/etc/profile文件,这样我们就可以自如使用hadoop、hdfs命令了,否则在使用命令时都要加入/bin/hadoop这样的路径:
sudo vi /etc/profile

输入:source /etc/profile
8. 运行wordcount示例
首先进入/usr/local/hadoop/目录,重启hadoop
cd /usr/local/hadoop/sbin
./stop-all.sh
cd /usr/local/hadoop/bin
./hdfs namenode -format # 格式化集群
cd /usr/local/hadoop/sbin
./start-all.sh
可以在namenode上查看连接情况
hdfs dfsadmin -report #下面是我的机器的结果

假设有测试文件test1.txt和test2.txt,首先创建目录/input
hadoop dfs -mkdir /input
将测试文件上传至hadoop:
hadoop dfs -put test1.txt /input/
hadoop dfs -put test2.txt /input/
子节点离开安全模式,否则可能会导致无法读取input的文件:
hdfs dfsadmin –safemode leave
运行wordcount程序:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input/ /output
查看结果
hadoop dfs -cat /output/part-r-00000
PS:再次运行时需要删除output文件夹 :hadoop dfs -rmr /output
本文为原创博客,若转载请注明出处。
Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)的更多相关文章
- Ubuntu 16.04下使用docker部署ceph集群
ceph集群docker部署 通过docker可以快速部署小规模Ceph集群的流程,可用于开发测试. 以下的安装流程是通过linux shell来执行的:假设你只有一台机器,装了linux(如Ubun ...
- Hadoop 2.2.0集群搭建
一.环境说明 1.虚拟机平台:VMware10 2.Linux版本号:ubuntu-12.04.3-desktop-i386 3.JDK:jdk1.7.0_51 4.Hadoop版本号:2.2.0 5 ...
- Hadoop 2.6.0集群搭建
yum install gcc yum install gcc-c++ yum install make yum install autoconfautomake libtool cmake yum ...
- Ubuntu 12.04下GAMIT10.40安装说明
转载于:http://www.itxuexiwang.com/a/liunxjishu/2016/0225/164.html?1456481297 Ubuntu 12.04下GAMIT10.40安装步 ...
- Angularjs学习---angularjs环境搭建,ubuntu 12.04下安装nodejs、npm和karma
1.下载angularjs 进入其官网下载:https://angularjs.org/,建议下载最新版的:https://ajax.googleapis.com/ajax/libs/angular ...
- [转]ubuntu(12.04)下, 命令 ,内核 源代码的获取
[转]ubuntu(12.04)下, 命令 ,内核 源代码的获取 http://blog.chinaunix.net/uid-18905703-id-3446099.html 1.命令:例如:要查看l ...
- Ubuntu 12.04 下安装 Eclipse
方法一:(缺点是安装时附加openjdk等大量程序并无法去除,优点是安装简单) $ sudo apt-get install eclipse 方法二:(优点是安装内容清爽,缺点是配置麻烦)1.安装JD ...
- 在Ubuntu 12.04下创建eclipse的桌面链接
在Ubuntu 12.04下创建eclipse的桌面链接 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在Ubuntu 12.04上安装Hadoop并 ...
- 升级Ubuntu 12.04下的gcc到4.7
我们知道C++11标准开始支持类内初始化(in-class initializer),Qt creator编译出现error,不支持这个特性,原因在于,Ubuntu12.04默认的是使用gcc4.6, ...
随机推荐
- 【leetcode 简单】第十八题 爬楼梯
假设你正在爬楼梯.需要 n 阶你才能到达楼顶. 每次你可以爬 1 或 2 个台阶.你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数. 示例 1: 输入: 2 输出: 2 解释: 有两 ...
- ASP.NET EF 使用LinqPad 快速学习Linq
使用LinqPad这个工具可以很快学习并掌握linq[Language Integrated Query] linqPad官方下载地址:http://www.linqpad.net/ linqPad4 ...
- JS 检测客户端断网情况
常用方法 1 navigator.onLine 2 window.addEventListener() 3 获取网络资源 4 ajax请求 1. navigator.onLine 只会在机器未连上路由 ...
- docker使用现有容器生成新的镜像
/*运行docker run后 --则进入该容器里了 我们做一些变更,比如安装一些东西 ,然后针对这个容器进行创建新的镜像 */ 基本形式: docker commit -m "change ...
- 离散化&&逆序数对
题目:http://www.fjutacm.com/Problem.jsp?pid=3087 #include<stdio.h> #include<string.h> #inc ...
- 转: oracle中schema指的是什么?
看来有的人还是对schema的真正含义不太理解,现在我再次整理了一下,希望对大家有所帮助. 我们先来看一下他们的定义:A schema is a collection of database obje ...
- 2018 黑盾杯部分writeup
这次比赛拿了三十多名.呵呵.或许这就是菜吧. 比赛经验教训: 1.赛前一定要调整好情绪. 2.比赛尽量不要紧张,每一题都认认真真的看过去! 3.站在出题者的角度去思考问题 4.刷题 5.还是情绪吧.其 ...
- gpk-update-icon占用CPU及清除【原创】
发现服务器有个gpk-update-icon一直占用CPU进程 网上查看相关信息比较少. gpk-update-icon是gnome的更新图标进程 俩种处理方法: 1.杀掉gpk-update-ico ...
- caffe Python API 之图片预处理
# 设定图片的shape格式为网络data层格式 transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) ...
- Jmeter命令行选项
示例:jmeter.bat -n -j %tmp%\%date:~0,4%%date:~5,2%%date:~8,2%_%time:~0,2%%time:~3,2%%time:~6,2%%time:~ ...