【原】Coursera—Andrew Ng机器学习—Week 6 习题—Advice for applying machine learning
【1】 诊断的作用

【2】过拟合

【3】

【4】

高偏差bias,欠拟合underfitting
高方差variance,过拟合overfitting
【5】参数λ
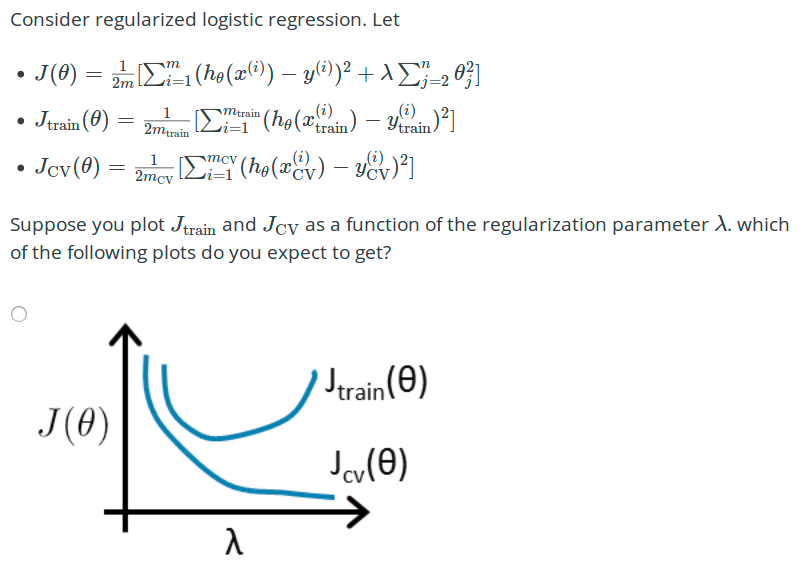

Answer: λ太大,则参数都被惩罚,导致欠拟合,两个J都大。 λ太小,则欠拟合,Jtrain 小,Jcv大。
【6】

Answer:过拟合的时候,增加训练集有用。
【7】

Answer:过拟合,增加 hidden 层数无用。
-------------------------------------- 下面是Lecture 11 的内容
【8】
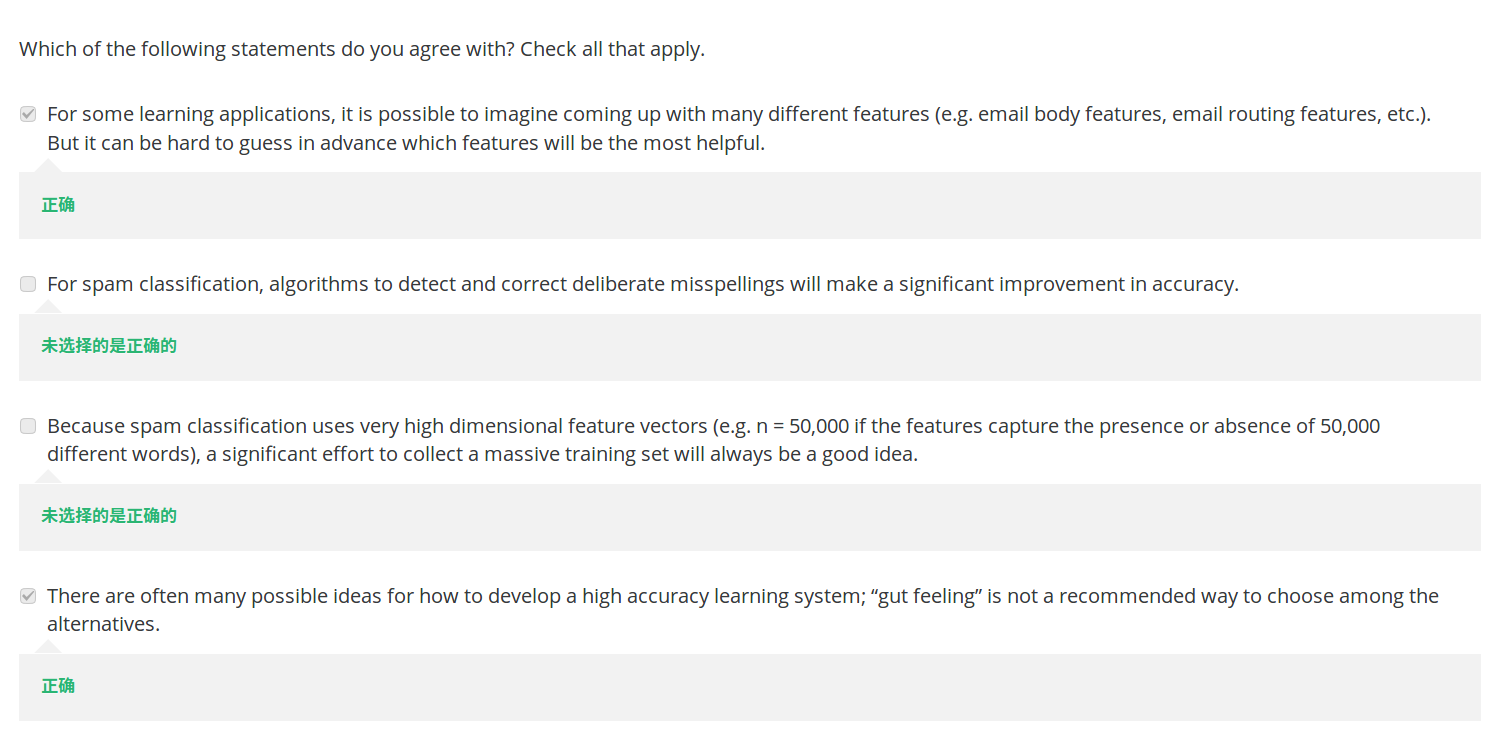
Answer:
A 正确。不容易猜测哪个feature是最有用的
B 错误。是一种方法,significant improve 不一定
C 错误。 是一种方法,always be good 不一定
D 正确。gut feeling直觉,不推荐只根据直觉判断。
【9】Jtest 和 Jcv

【10】错误度量
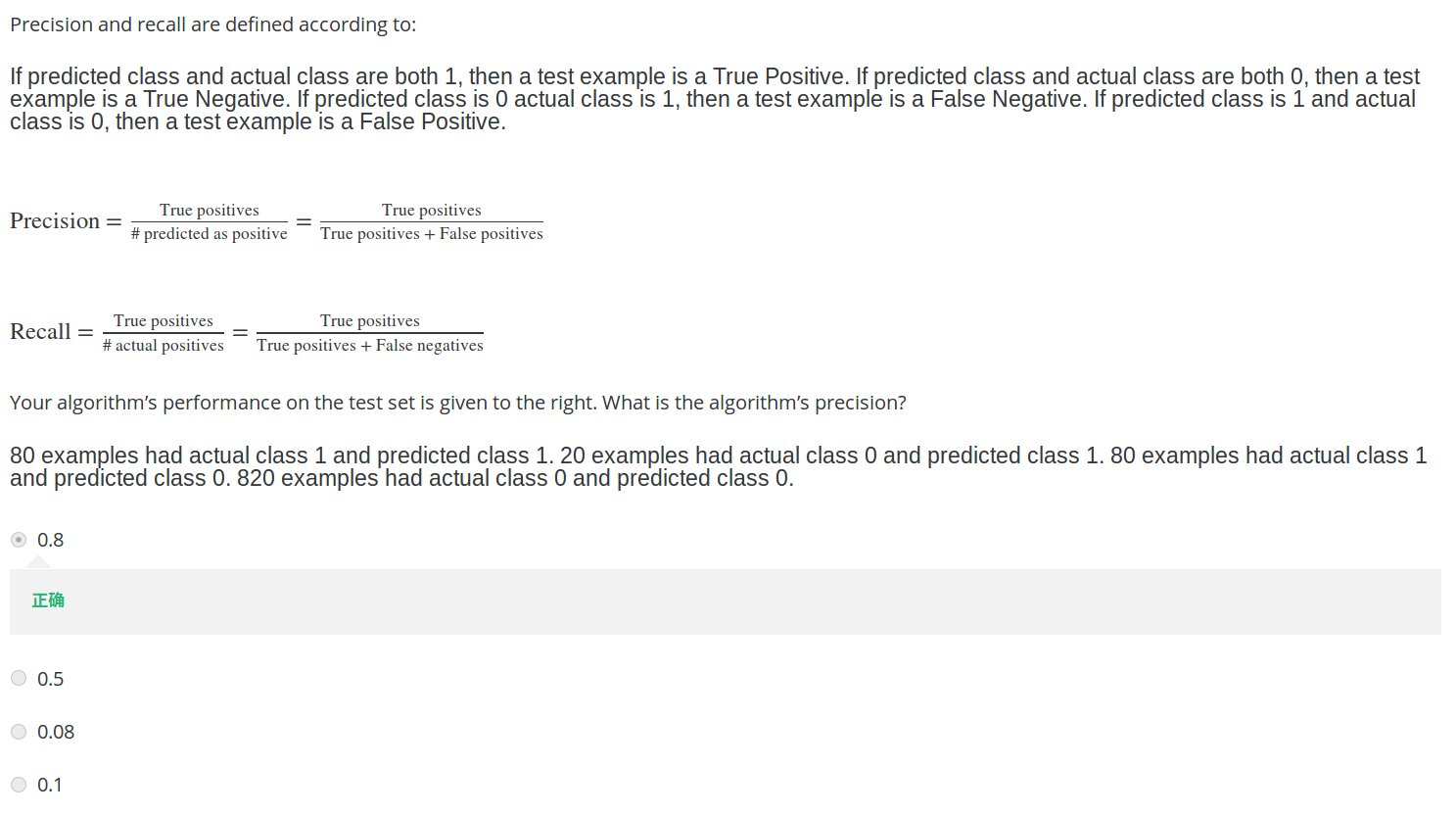
Answer: Precision = 80/(20+80) = 0.8, Recall = 80/(80+80) = 0.5
【11】 F1 score

【12】大数据集

Answer:如果数据所含的信息很少,增大数据集也不能解决问题。
测验

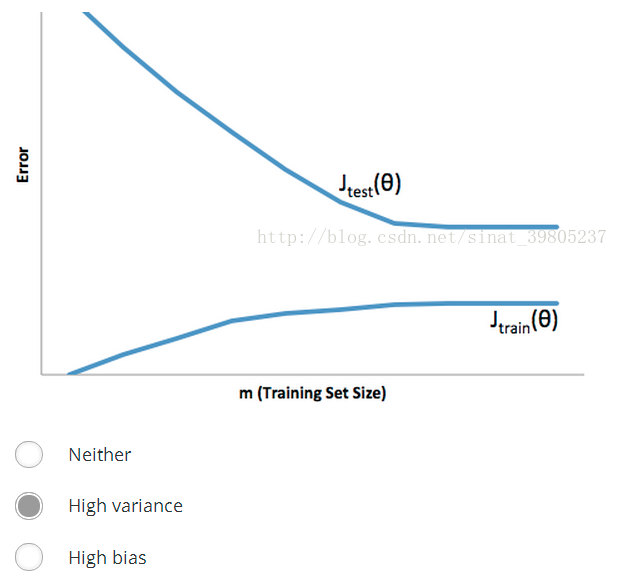
Answer:第一个欠拟合,两个误差都大。第二个过拟合,train小,cv大。

Answer:BC,过拟合:使用小的特征集, 增大λ。
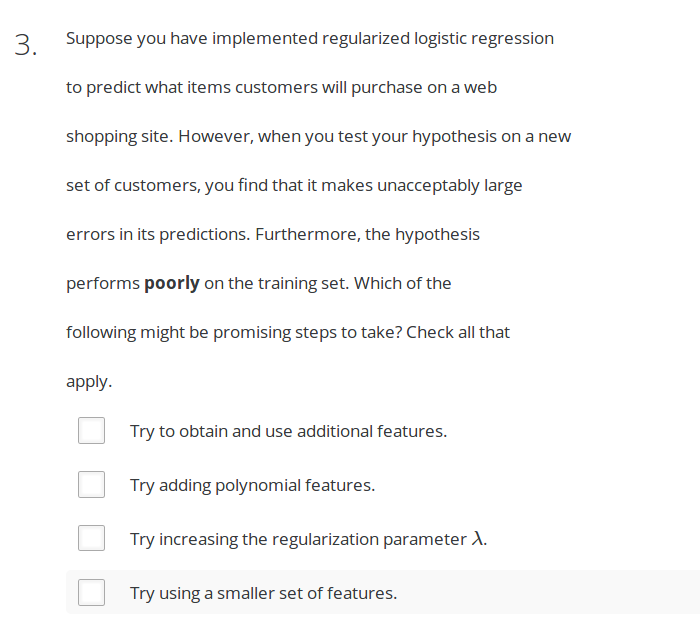
Answer:AB,欠拟合:增大特征集, 增加多项式次数,减小λ。

Answer:AD



Answer:ABCF
A 高偏差,欠拟合说明模型不好,应该增加feature
C 参数过多,更容易过拟合
D 错误。增加 hidden 数,不能解决过拟合
E 错误。欠拟合,通过增加feature可以优化
F 过拟合,通过增加训练集可以优化
--------------- 下面是Lecture11 的内容
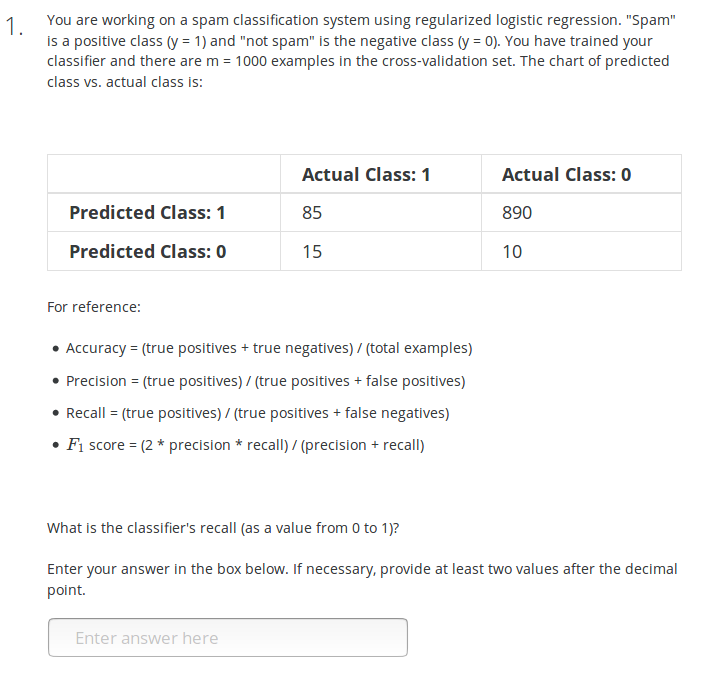
Answer: recall=85/(85+15)=0.85
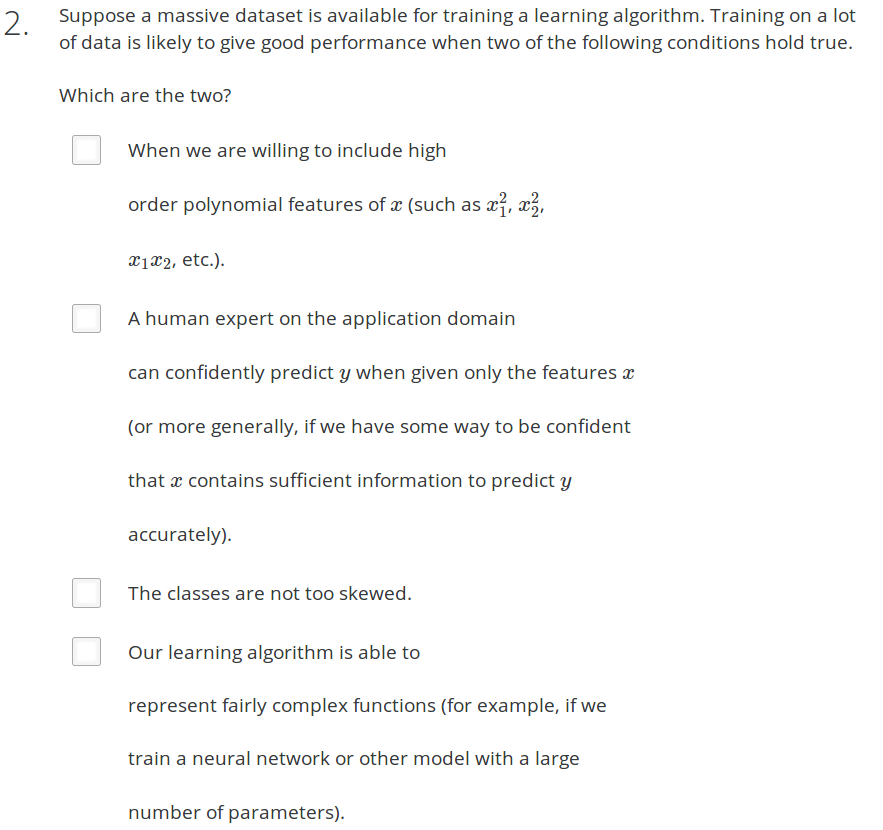
Answer: BD
A 错误。如果features太少,多加入polynomial features 也不能够完全模拟出训练样本的特征。就像预测房价,只用房子面积这一个特征,再加上面积1次方,2次方组成的polynomial,就算训练样本再多,也不能预测出正确的房价
B 正确 给专家一个x feature就可以准确的预测出y. 即所选的特征x含有足够的信息来准确预测y
C
D 正确。我们的学习算法能够表示相当复杂的功能(例如,训练神经网络或其他具有大量参数的模型)。模型复杂,表示复杂的函数,此时的特征多项式可能比较多,能够很好的拟合训练集中的数据,使用大量的数据能够很好的训练模型。

Answer:D
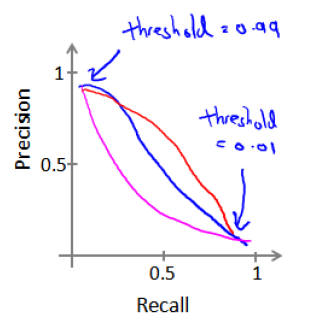
threshould 设定越低,查准率precision越低、查全率recall越高,因为更多负例被判断为正例。
threshould 设定越高,查准率precision越高、查全率recall越低,因为有更多正例被漏掉。


Answer:ACDFG
- Accuracy = (true positives + true negatives) / (total examples)
- Precision = (true positives) / (true positives + false positives)
- Recall = (true positives) / (true positives + false negatives)
- F1 score = (2 * precision * recall) / (precision + recall)
A 正确。好的模型应该同时具有较高的precision和recall
B 错误。表现应该类似
C 正确。如果都判断为非垃圾邮件,recall=0/(0+99)=0,precision=0/(0+1)=0,accurancy=(0+99)/100 = 0.99
D 正确。交叉验证集合和训练集来源相同,表现应该类似。
E 错误。如果都判断为垃圾邮件,recall=1/(1+0)=1,precision=1/(99+1)=0.01
F 正确。同C
G 正确。同E
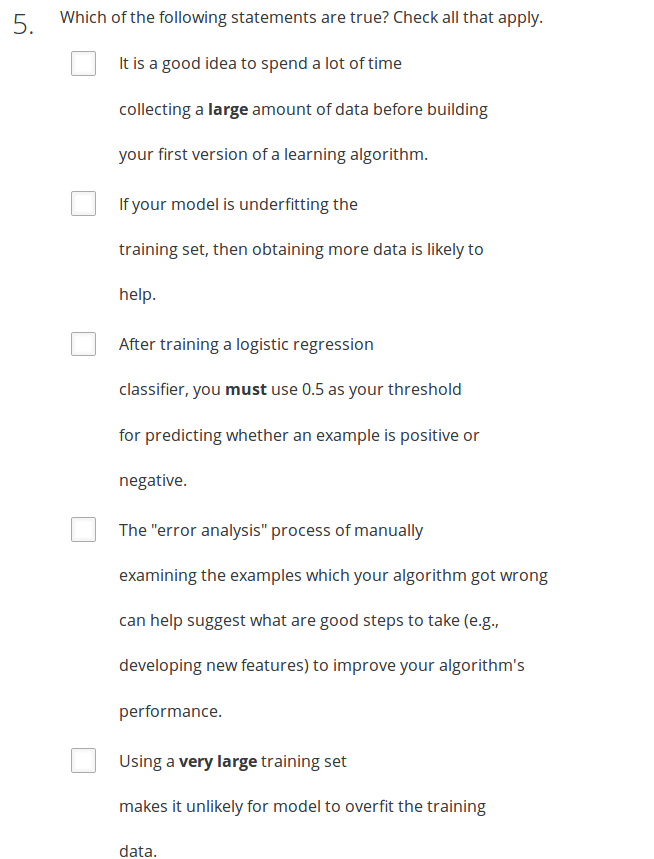

Answer:DEF
A 错误。不应该开始就花大量时间去收集大量数据,而应该有重点地收集有用数据
B 错误。模型欠拟合,多收集数据没有帮助。如果模型太简单、特征太少,则应该增加多项式特征,而不是收集数据
C 错误。因为可能存在偏斜数据集,最终阈值不一定是0.5
D 正确。手动检查分类错误的数据会有帮助
E 正确。使用特别大的数据集合能避免过拟合
F 正确。在很偏斜的数据集上,应该使用F1 值,而不是使用accuracy
【原】Coursera—Andrew Ng机器学习—Week 6 习题—Advice for applying machine learning的更多相关文章
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 【原】Coursera—Andrew Ng机器学习—Week 11 习题—Photo OCR
[1]机器学习管道 [2]滑动窗口 Answer:C ((200-20)/4)2 = 2025 [3]人工数据 [4]标记数据 Answer:B (10000-1000)*10 /(8*60*60) ...
- 【原】Coursera—Andrew Ng机器学习—Week 5 习题—Neural Networks learning
课上习题 [1]代价函数 [2]代价函数计算 [3] [4]矩阵的向量化 [5]梯度校验 Answer:(1.013 -0.993) / 0.02 = 3.001 [6]梯度校验 Answer:学习的 ...
- 【原】Coursera—Andrew Ng机器学习—Week 3 习题—Logistic Regression 逻辑回归
课上习题 [1]线性回归 Answer: D A 特征缩放不起作用,B for all 不对,C zero error不对 [2]概率 Answer:A [3]预测图形 Answer:A 5 - x1 ...
- 【原】Coursera—Andrew Ng机器学习—Week 10 习题—大规模机器学习
[1]大规模数据 [2]随机梯度下降 [3]小批量梯度下降 [4]随机梯度下降的收敛 Answer:BD A 错误.学习率太小,算法容易很慢 B 正确.学习率小,效果更好 C 错误.应该是确定阈值吧 ...
- 【原】Coursera—Andrew Ng机器学习—Week 9 习题—异常检测
[1]异常检测 [2]高斯分布 [3]高斯分布 [4] 异常检测 [5]特征选择 [6] [7]多变量高斯分布 Answer: ACD B 错误.需要矩阵Σ可逆,则要求m>n 测验1 Answ ...
- 【原】Coursera—Andrew Ng机器学习—Week 8 习题—聚类 和 降维
[1]无监督算法 [2]聚类 [3]代价函数 [4] [5]K的选择 [6]降维 Answer:本来是 n 维,降维之后变成 k 维(k ≤ n) [7] [8] Answer: 斜率-1 [9] A ...
- 【原】Coursera—Andrew Ng机器学习—Week 7 习题—支持向量机SVM
[1] [2] Answer: B. 即 x1=3这条垂直线. [3] Answer: B 因为要尽可能小.对B,右侧红叉,有1/2 * 2 = 1 ≥ 1,左侧圆圈,有1/2 * -2 = -1 ...
- 【原】Coursera—Andrew Ng机器学习—Week 1 习题—Linear Regression with One Variable 单变量线性回归
Question 1 Consider the problem of predicting how well a student does in her second year of college/ ...
随机推荐
- iOS中scrollview自动滚动的实现
http://bbs.csdn.net/topics/390347330 原问题是,我要展现给用户的内容放在scrollview中,让内容从上到底自动滚动,我最开始用的是DDAutoscrollvie ...
- Core Animation1-简介
一.Core Animation简介 * Core Animation,中文翻译为核心动画,它是一组非常强大的动画处理API,使用它能做出非常炫丽的动画效果,而且往往是事半功倍.也就是说,使用少量的代 ...
- tidb 集群扩容
1. tidb 新增节点 a. 编辑 inventory.ini [tidb_servers] 10.0.230.14 10.0.230.15 10.10.230.20 b. 初始化新增节点 ansi ...
- lapis 集成openresty最新版本cjson 问题的解决
备注: 为了解决安装了lapis.同时又希望使用新版nginx 以及openresty 的特性(stream ...) 1. 解决方法 参考: https://github.com/leaf ...
- linux 磁盘挂载操作
1. fdisk -l 查看磁盘 2. fisk /dev/vdb 进行分区 依次输入 n p 1 两次回车 wq 3. fdisk -l 查看分 ...
- MQTT的知识点
问题一:单片机缓存有限,处理能力有限的情况下,消息不可能一次发出,这种情况下要怎样通过MQTT发布消息? 先组装publish协议的头,里面写好payload的长度,通过tcp发出去,然后一点一点发p ...
- Django模板输出Dict所有Value的效率问题
一次跑偏之旅! 对于一个惯用C++的人来说,使用Python这种语言的一大障碍就是许多集合类型的操作效率并不如传统的经典数据结构那样直观可见,以及许多实际上涉及到内存分配.对象复制之类的耗时操作被 ...
- Hibernate学习11——配置Hibernate二级缓存
一.缓存的概念: 以空间换时间: 二.Hibernate缓存的分类: 前面我们讲的缓存都是session缓存:也叫一级缓存:get,load等缓存都是内置的,一级缓存: SessionFactor ...
- appium+python自动化28-name定位
前言 appium1.5以下老的版本是可以通过name定位的,新版本从1.5以后都不支持name定位了 name定位报错 1.最新版appium V1.7用name定位,报错: selenium.co ...
- CodeForces - 963B Destruction of a Tree (dfs+思维题)
B. Destruction of a Tree time limit per test 1 second memory limit per test 256 megabytes input stan ...