跟我学算法聚类(kmeans)
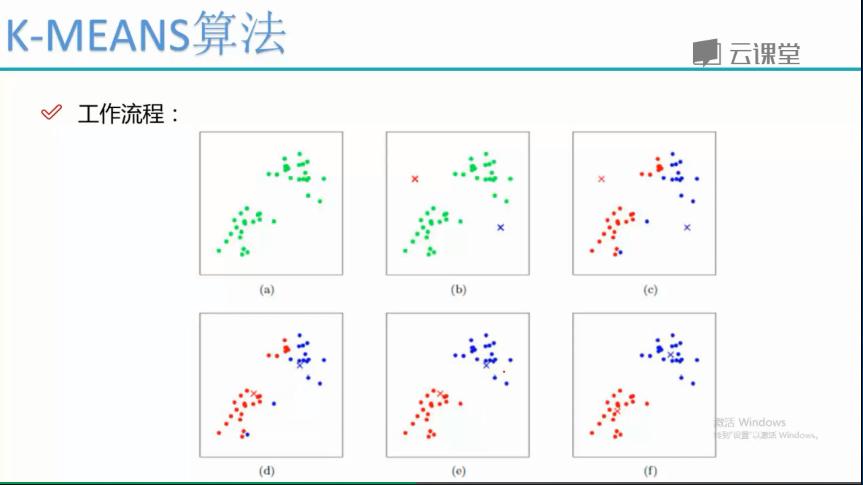
kmeans是一种无监督的聚类问题,在使用前一般要进行数据标准化, 一般都是使用欧式距离来进行区分,主要是通过迭代质心的位置
来进行分类,直到数据点不发生类别变化就停止,
一次分类别,一次变换质心,就这样不断的迭代下去
优势:使用方便
劣势:1.K值难确定
2. 复杂度与样本数量呈线性关系
3.很难发现形状任意的簇
4.容易受初始点的影响
python中使用 sklearn.cluster 模块,使用的时候需要指定参数
第一步:导入数据,提取数据中的变量保存为X
import pandas as pd
beer = pd.read_csv('data.txt', sep=' ') X = beer[["calories","sodium","alcohol","cost"]]
第二步:进行kmans聚类分析
from sklearn.cluster import KMeans km = KMeans(n_clusters=3).fit(X) #聚成三蔟
km2 = KMeans(n_clusters=2).fit(X) #聚成两蔟 beer['cluster'] = km.labels_ #返回聚类的标签结果
beer['cluster2'] = km2.labels_ beer.sort_values('cluster') #根据'cluster'进行排序
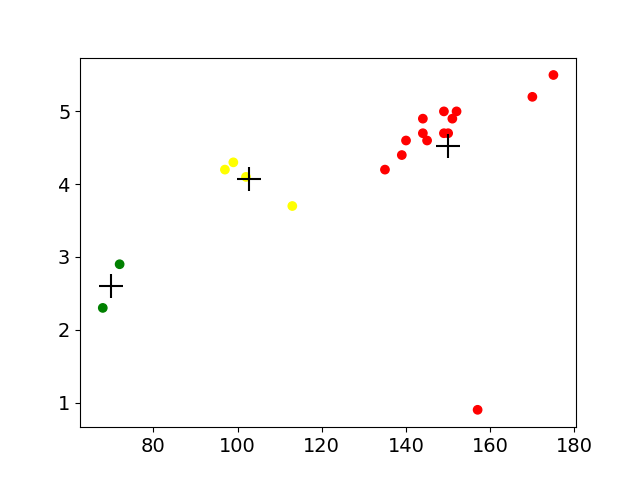
第三步:根据分类结果画出带颜色的散点图,及其混淆矩阵
from pandas.tools.plotting import scatter_matrix
cluster_center = km.cluster_centers_
cluster_center_2 = km2.cluster_centers_
# print(beer.groupby('cluster').mean()) #groupby进行快速分组,mean求平均
#
# print(beer.groupby('cluster2').mean())
centers = beer.groupby("cluster").mean().reset_index() #reset_index()重新添加了序号
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14 #rcParams 用于修改字体的大小
import numpy as np
color = np.array(['red', 'green', 'yellow', 'blue'])
plt.scatter(beer['calories'], beer['alcohol'], c=color[beer['cluster']])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')
scatter_matrix(beer[["calories","sodium","alcohol","cost"]], s=100,alpha = 1 ,c=color[beer['cluster']],\
figsize=(10, 10)) #alpha 代表不透明的意思
plt.suptitle("With 3 centroids initialized")
plt.show()

第四步:对数据进行标准化,再进行kmeans聚类
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaler = scaler.fit_transform(X) #进行转换
new_X_scaler = pd.DataFrame(X_scaler, columns=["calories","sodium","alcohol","cost"]) km = KMeans(n_clusters=3).fit(X_scaler) beer['scaler_cluster'] = km.labels_ beer.sort_values('scaler_cluster') print(beer.groupby('scaler_cluster').mean()) scatter_matrix(new_X_scaler, alpha = 1 ,c=color[beer.scaler_cluster]) plt.show()
第五步:为了比较处理前后的效果,我们引入了轮廓系数 metrics.silhouette_score,发现未标准化的分类结果要好于标准化
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaler_cluster)
score = metrics.silhouette_score(X,beer.cluster)
print(score_scaled, score)
第六步: 我们使用轮廓系数(b(i)-a(i))/max(b(i), a(i)), b(i)一个点到自己蔟的距离,a(i)表示一个点到其他蔟的距离,来挑选蔟的参数n_clusters
scores = []
for i in range(2, 15): print(metrics.silhouette_score(X,KMeans(n_clusters=i).fit(X).labels_)) #X变量,KMeans(n_clusters=i).fit(X).labels_分类得到的标签
scores.append(metrics.silhouette_score(X,KMeans(n_clusters=i).fit(X).labels_)) plt.plot(list(range(2, 15)), scores) plt.xlabel('迭代次数') plt.ylabel('轮廓系数') plt.show()

跟我学算法聚类(kmeans)的更多相关文章
- 推荐算法-聚类-K-MEANS
对于大型的推荐系统,直接上协同过滤或者矩阵分解的话可能存在计算复杂度过高的问题,这个时候可以考虑用聚类做处理,其实聚类本身在机器学习中也常用,属于是非监督学习的应用,我们有的只是一组组数据,最终我们要 ...
- 跟我学算法聚类(DBSCAN)
DBSCAN 是一种基于密度的分类方法 若一个点的密度达到算法设定的阖值则其为核心点(即R领域内点的数量不小于minPts) 所以对于DBSCAN需要设定的参数为两个半径和minPts 我们以一个啤酒 ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- [数据挖掘] - 聚类算法:K-means算法理解及SparkCore实现
聚类算法是机器学习中的一大重要算法,也是我们掌握机器学习的必须算法,下面对聚类算法中的K-means算法做一个简单的描述: 一.概述 K-means算法属于聚类算法中的直接聚类算法.给定一个对象(或记 ...
- 浅谈聚类算法(K-means)
聚类算法(K-means)目的是将n个对象根据它们各自属性分成k个不同的簇,使得簇内各个对象的相似度尽可能高,而各簇之间的相似度尽量小. 而如何评测相似度呢,采用的准则函数是误差平方和(因此也叫K-均 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 机器学习-聚类-k-Means算法笔记
聚类的定义: 聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,它是无监督学习. 聚类的基本思想: 给定一个有N个对象的数据集 ...
- 机器学习聚类算法之K-means
一.概念 K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法. K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心. 缺点: 1.循环计算点到质心的距离 ...
随机推荐
- LOJ2324. 「清华集训 2017」小 Y 和二叉树【贪心】【DP】【思维】【好】
LINK 思路 首先贪新的思路是处理出以一个节点为根所有儿子的子树中中序遍历起始节点最小是多少 然后这个可以两次dfs来DP处理 然后就试图确定中序遍历的第一个节点 一定是siz<=2的编号最小 ...
- BZOJ4245 ONTAK2015 OR-XOR 【位运算+贪心】*
BZOJ4245 ONTAK2015 OR-XOR Description 给定一个长度为n的序列a[1],a[2],…,a[n],请将它划分为m段连续的区间,设第i段的费用c[i]为该段内所有数字的 ...
- BZOJ3887 [Usaco2015 Jan] Grass Cownoisseur 【tarjan】【DP】*
BZOJ3887 [Usaco2015 Jan] Grass Cownoisseur Description In an effort to better manage the grazing pat ...
- BZOJ4033 HAOI2015 树上染色 【树上背包】
BZOJ4033 HAOI2015 树上染色 Description 有一棵点数为N的树,树边有边权.给你一个在0~N之内的正整数K,你要在这棵树中选择K个点,将其染成黑色,并将其他的N-K个点染成白 ...
- webdriver元素定位
#1 通过id定位 driver.find_element_by_id("pop_setting_save").click() #2 通过name定位 driver.find_el ...
- springboot 填坑一 springboot java.sql.SQLException: Access denied for user ''@'localhost' (using password: NO)
这里有个很不明显的错误 初次搭建很容易犯这个错
- 读取设置config.ini配置
class CSenseIni { /************************************************************************/ /*写操作 * ...
- JDBC 流程
转载地址:https://blog.csdn.net/suwu150/article/details/52744952 JDBC编程的六个步骤: 准备工作中导入ojdbc文件,然后右键选中添加路 ...
- RK3288 通过指令查看当前显示内容(framebuffer)
$ adb shell root@xxx:/ # cd /dev/graphics cd /dev/graphics root@xxx:/dev/graphics # ls ls fb0 fb1 fb ...
- iso网络模型
tcp/ip知识 1.iOS七层模型 应用层 表示层 应用层 ssh httpssl tls ftp mime html snmp 会话层 传输层 传输层 tcp udp 网络层 网络层 ipv6 i ...