【Python】IO编程
学习廖老师的py官网的笔记
1、stream的概念。数据交换通常需要建立两根“水管”。
2、同步IO和异步IO。异步性能高,但是编程模型复杂。
3、操作IO的功能是操作系统提供的!不论是Java还是Pyton都只是将低级接口封装起来供开发者使用。
【文件读写】
读文件
1、简单的
>>> f = open('ask.txt', 'r')
>>> f.read()
'我想你最近一定很忙。'
>>>
但是要记得关掉(文件对象会占操作系统的资源)
>>> f.close()
但是有时候读文件可能会抛出错误,例如:文件不存在。为了保证最后一定会把文件关掉,必须使用一定会执行的finally语句。
try:
f = open('ask.txt', 'r')
print(f.read())
finally:
if f:
f.close()
有一种等价写法:
with open('ask.txt') as f:
print(f.read())
2、逐行读取。
with open('ask.txt', 'r') as f:
for line in f.readlines():
print(line.strip()) #print自带换行的效果,这里的strip把'\n'去掉。
file-like Object:有read方法的对象。
读取二进制:
# -*- coding: utf-8 -*-
# read byte
# 默认情况下都是读取文本文件
# 如果要读取图片等文件
with open('a.png', 'rb') as f:
print(f.read())
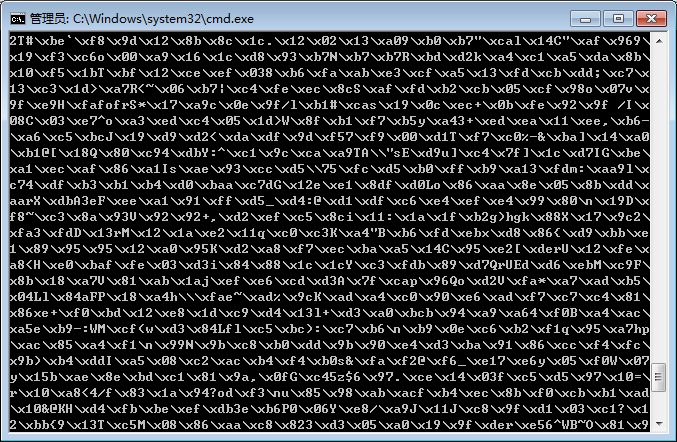
读取非UTF-8编码的文件:

errrors参数表示遇到编码错误直接忽略。
写文件
类比读文件就可以了。
简单的例子
>>> with open('ask.txt', 'w') as f:
... f.write('所以你只要看前三个字就好')
...
12
>>> with open('ask.txt', 'w', errors='ignore') as f:
... f.write('所以你只要看前三个字就好')
...
12
不知道为什么会有返回值。
【StringIO和BytesIO】
在内存中读写。
StringIO
>>> from io import StringIO
>>> f = StringIO()
>>> f.write('床前明月光')
5
>>> f.write(' 疑是地上霜')
6
>>> f.getvalue()
'床前明月光 疑是地上霜'
可以理解为在内存中的一个“文件”,因为操作StringIO和操作file没有太大区别:
>>> f = StringIO('i\nmiss\nyou!')
>>> while True:
... s = f.readline() # 读取掉一行
... if s == '': # 如果已经读完
... break
... print(s.strip())
...
i
miss
you!
BytesIO
>>> from io import BytesIO
>>> f = BytesIO('abc123')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: a bytes-like object is required, not 'str'
>>> f = BytesIO(b'abc123')
>>> f.read()
b'abc123'
【操作文件和目录】
os模板是操作系统相关的。
>>> import os
>>> os.name
'nt'
环境变量
>>> os.environ
environ({'SYSTEMDRIVE': 'C:', 'ALLUSERSPROFILE': 'C:\\ProgramData', 'PUBLIC': 'C:\\Users\\Public', 'LOCALAPPDATA': 'C:\\Users\\mdzz\\AppData\\Local', 'USERDOMAIN': 'LAPTOP-QGECNCGO', 'SYSTEMROOT': 'C:\\WINDOWS', 'PSMODULEPATH': 'C:\\Program Files\\WindowsPowerShell\\Modules;C:\\WINDOWS\\system32\\WindowsPowerShell\\v1.0\\Modules', 'TMP': 'C:\\Users\\mdzz\\AppData\\Local\\Temp', 'COMSPEC': 'C:\\WINDOWS\\system32\\cmd.exe', 'NUMBER_OF_PROCESSORS': '', 'PROCESSOR_IDENTIFIER': 'Intel64 Family 6 Model 94 Stepping 3, GenuineIntel', 'PATH': 'C:\\ProgramData\\Oracle\\Java\\javapath;C:\\Program Files (x86)\\Intel\\iCLS Client\\;C:\\Program Files\\Intel\\iCLS Client\\;C:\\windows\\system32;C:\\windows;C:\\windows\\System32\\Wbem;C:\\windows\\System32\\WindowsPowerShell\\v1.0\\;C:\\Program Files (x86)\\Intel\\Intel(R) Management Engine Components\\DAL;C:\\Program Files\\Intel\\Intel(R) Management Engine Components\\DAL;C:\\Program Files (x86)\\Intel\\Intel(R) Management Engine Components\\IPT;C:\\Program Files\\Intel\\Intel(R) Management Engine Components\\IPT;C:\\Program Files (x86)\\NVIDIA Corporation\\PhysX\\Common;C:\\Program Files\\Intel\\WiFi\\bin\\;C:\\Program Files\\Common Files\\Intel\\WirelessCommon\\;C:\\Program Files\\MySQL\\MySQL Server 5.5\\bin;C:\\maven\\apache-maven-3.3.9\\bin;C:\\WINDOWS\\system32;C:\\WINDOWS;C:\\WINDOWS\\System32\\Wbem;C:\\WINDOWS\\System32\\WindowsPowerShell\\v1.0\\;C:\\MinGW\\bin;C:\\Program Files\\Java\\jdk1.8.0_101\\bin;C:\\Users\\mdzz\\AppData\\Local\\Programs\\Python\\Python35\\Scripts\\;C:\\Users\\mdzz\\AppData\\Local\\Programs\\Python\\Python35\\;C:\\Users\\mdzz\\AppData\\Local\\Microsoft\\WindowsApps;C:\\Users\\mdzz\\AppData\\Roaming\\npm;C:\\Users\\mdzz\\AppData\\Local\\atom\\bin', 'LOGONSERVER': '\\\\LAPTOP-QGECNCGO', 'MOZ_PLUGIN_PATH': 'C:\\Program Files (x86)\\Foxit Software\\Foxit Reader\\plugins\\', 'PROGRAMFILES': 'C:\\Program Files', 'ONLINESERVICES': 'Online Services', 'USERNAME': 'mdzz', 'PROCESSOR_LEVEL': '', 'PROMPT': '$P$G', 'HOMEPATH': '\\Users\\mdzz', 'PATHEXT': '.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC', 'PROGRAMFILES(X86)': 'C:\\Program Files (x86)', 'COMPUTERNAME': 'LAPTOP-QGECNCGO', 'WINDIR': 'C:\\WINDOWS', 'ONEDRIVE': 'C:\\Users\\mdzz\\OneDrive', 'USERDOMAIN_ROAMINGPROFILE': 'LAPTOP-QGECNCGO', 'COMMONPROGRAMFILES': 'C:\\Program Files\\Common Files', 'MAVEN_HOME': 'C:\\maven\\apache-maven-3.3.9', 'PROGRAMW6432': 'C:\\Program Files', 'TEMP': 'C:\\Users\\mdzz\\AppData\\Local\\Temp', 'VS140COMNTOOLS': 'C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\Common7\\Tools\\', 'JAVA_HOME': 'C:\\Program Files\\Java\\jdk1.8.0_101', 'PROGRAMDATA': 'C:\\ProgramData', 'COMMONPROGRAMW6432': 'C:\\Program Files\\Common Files', 'CLASSPATH': '.;C:\\Program Files\\Java\\jdk1.8.0_101lib;C:\\Program Files\\Java\\jdk1.8.0_101lib\\tools.jar', 'USERPROFILE': 'C:\\Users\\mdzz', 'REGIONCODE': 'APJ', 'PLATFORMCODE': 'KV', 'HOMEDRIVE': 'C:', 'PROCESSOR_REVISION': '5e03', 'APPDATA': 'C:\\Users\\mdzz\\AppData\\Roaming', 'OS': 'Windows_NT', 'PROCESSOR_ARCHITECTURE': 'AMD64', 'COMMONPROGRAMFILES(X86)': 'C:\\Program Files (x86)\\Common Files'})
获取某个具体环境变量的值:
>>> os.environ.get('PATH')
操作文件和目录
操作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中。
操作文件和目录基本可以映射为在命令行下操作文件和目录:
>>> import os
>>> os.path.abspath('.')
'D:\\labs'
创建目录:
>>> os.path.join('D:\\labs', 'TestDir') # 这个时候没有真的创建
'D:\\labs\\TestDir'
>>> os.mkdir('D:\\labs\\TestDir') # 真的创建了
>>> os.rmdir('D:\\labs\\TestDir') # 删掉!
之所以使用os.path.join()函数,是因为在不同操作系统上文件分隔符是不同的,这样可以正确处理。
同样,要拆分文件路径,也需要使用特殊的函数os.path.split(),os.path.splitext()可以直接获得文件拓展名。
# 对文件重命名:
>>> os.rename('test.txt', 'test.py')
# 删掉文件:
>>> os.remove('test.py')
列出当前路径下的所有文件:
>>> [x for x in os.listdir('.')]
['2.cpp', '4.cpp', '5.cpp', 'a.exe', 'a.png', 'ask.txt', 'c++task', 'cpppojects3月六日', 'cpppojects3月 六日.rar', 'Dada', 'Employee', 'input.txt', 'javaDocTest', 'MyTest', 'MyTest.class', 'MyTest.java', 'output.txt', 'pictest', 'picture1.jpg', 'prog1.cpp', 'Sales_data.h', 'separatecp', 'student.sql', 'sum_test.py', 'sum_test.py.bak', 'test.py', 'test.py.bak', '__pycache__']
筛选出文件夹:
>>> [x for x in os.listdir('.') if os.path.isdir(x)]
['c++task', 'cpppojects3月六日', 'Dada', 'Employee', 'javaDocTest', 'MyTest', 'pictest', 'separatecp', '__pycache__']
筛选出所有py文件:
>>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
['sum_test.py', 'test.py']
【序列化】
序列化:变量从内存中变成可存储或传输的过程。
被叫做pickling、serialization、marshalling、flattening等。
把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据.
尝试:
>>> import pickle
>>> d = dict(name = 'xkfx', age = )
>>> pickle.dumps(d)
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00xkfxq\x02X\x03\x00\x00\x00ageq\x03K\x13u.'
>>> f = open('dump.txt', 'wb')
>>> pickle.dump(d, f)
>>> f.close()
>>> f= open('dump.txt', 'rb')
>>> d = pickle.load(f)
>>> f.close()
>>> d
{'name': 'xkfx', 'age': }
JSON是什么?
-----JSON 是 JS 对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串。
JSON是干嘛的?
为什么是JSON?

JSON与Python
要在不同的语言中传递数据,就必须把数据序列化成标准格式。例如在Python和Java中交互数据。
JSON比XML好一些。
JSON表示的对象就是标准的JavaScript语言的对象.
对应关系:

Python内置的json模块提供了非常完善的Python对象到JSON格式的转换。JSON标准规定JSON编码是UTF-8。
尝试:
>>> import json
>>> i = dict(name = 'xkfx', age = 19)
>>> json.dumps(d)
'{"name": "xkfx", "age": 19}' # 这个str是标准的JSON
>>> str = '{"name": "xkfx", "age": 19}'
>>> json.loads(str)
{'name': 'xkfx', 'age': 19}
对象的dumps()和loads()。
1、尝试直接dumps()一个对象:
import json class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score s = Student('xkfx', 19, 20)
print(json.dumps(s))
抛出错误:
s = Student('xkfx', 19, 20)
print(json.dumps(s))
2、失败的原因是dumps()不懂得如何将s引用的对象序列化。这样的话,只需要告诉dumps如何将对象序列化就可以了。
def student2dict(std):
return {
'name' : std.name,
'age' : std.age,
'score' : std.score
} s = Student('xkfx', 19, 20)
print(json.dumps(s, default=student2dict))
$ python test.py
{"age": 19, "score": 20, "name": "xkfx"}
3、但是,如果对于每个类都要写对应的序列化方法也未免太麻烦了。所以有一种偷懒的方法:
print(json.dumps(s, default=lambda obj: obj.__dict__))
每个对象自带有dict,通过.dict访问
print(s.__dict__)
print(json.dumps(s, default=lambda obj: obj.__dict__))
python test.py
{'score': 20, 'age': 19, 'name': 'xkfx'} # 原始dict
{"score": 20, "age": 19, "name": "xkfx"} # 序列化成JSON
4、反序列化也是同样的道理,loads不知道如何反序列化,必须传入一个方法告诉它怎么做,不同的是反序列化无法偷懒!:
def dict2student(d):
return Student(d['name'], d['age'], d['score']) json_data = '{"age": 19, "score": 20, "name": "xkfx"}'
print(json.loads(json_data, object_hook=dict2student))
<__main__.Student object at 0x0000022226F0B630>
【Python】IO编程的更多相关文章
- Python IO编程
IO在计算机中指Input/Output,也就是输入和输出 一.文件读写 1.读文件 >>> f = open('/Users/michael/test.txt', 'r') --- ...
- Python IO编程-读写文件
1.1给出规格化得地址字符串,这些字符串是经过转义的能直接在代码里使用的字符串 需要导入os模块 import os >>>os.path.join('user','bin','sp ...
- python IO编程-序列化
原文链接:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143192607 ...
- python IO编程-StringIO和BytesIO
链接:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014319187857 ...
- Python IO编程-组织文件
对于日常中遇到的批量任务,有些可以通过请求python完成自动化,我非常渴望拥有这些能力,在去年学习了python读写文件之后,我马上迫不及待的开始学习‘组织文件’,经过学习,我发现python组织文 ...
- python 网络编程 IO多路复用之epoll
python网络编程——IO多路复用之epoll 1.内核EPOLL模型讲解 此部分参考http://blog.csdn.net/mango_song/article/details/4264 ...
- Python之IO编程——文件读写、StringIO/BytesIO、操作文件和目录、序列化
IO编程 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口.从 ...
- python网络编程基础(线程与进程、并行与并发、同步与异步、阻塞与非阻塞、CPU密集型与IO密集型)
python网络编程基础(线程与进程.并行与并发.同步与异步.阻塞与非阻塞.CPU密集型与IO密集型) 目录 线程与进程 并行与并发 同步与异步 阻塞与非阻塞 CPU密集型与IO密集型 线程与进程 进 ...
- Python并发编程二(多线程、协程、IO模型)
1.python并发编程之多线程(理论) 1.1线程概念 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于 ...
- python安装与IO编程
<python爬虫开发与项目实战>基础篇(一) 一.python安装 1.python IDLE 下载官网:www.python.org 注:在选择安装组件时勾选所有组件,特别注意勾选pi ...
随机推荐
- MY97默认只能选择昨天的时间
<input type="text" id="startTime" class="Wdate" style="width: ...
- js让程序暂停运行的方法
//自己写的暂停毫秒数的函数 function pauseTime(millTime) { var start=Date.now(); while(true){ var nowTime=Date.no ...
- python裁剪base64编码的图片
简介 今天遇到需要裁剪base64字符串的PNG图片,并返回base64格式字符串的任务,捣鼓半天. 裁剪代码如下: def deal_inspect_img(base64_str): "& ...
- 160513、nginx+tomcat集群+session共享(linux)
第一步:linux中多个tomcat安装和jdk安装(略) 第二步:nginx安装,linux中安装nginx和windows上有点不同也容易出错,需要编译,这里做介绍 一.安装依赖 gcc open ...
- Load Balancing with NGINX 负载均衡算法
Using nginx as HTTP load balancer Using nginx as HTTP load balancer http://nginx.org/en/docs/http/lo ...
- python基础-第六篇-6.1生成器与迭代器
迭代器 特点: 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容 不能随机访问集合中的某个值 ,只能从头到尾依次访问 访问到一半时不能往回退 便于循环比较大的数据集合,节省 ...
- 【c++】生成浮点随机数
c++11:std::uniform_real_distribution<>直接求(尖括号不填默认生成double) 随机10个在1-2之间的浮点数 #include <random ...
- JavaWeb-Servlet-通过servlet生成验证码图片
BufferedImage类 创建一个BufferImage servlet,用来生成验证码图片: package com.fpc; import java.awt.Color; import jav ...
- 创建Java不可变类
不可变(immutable)类的意思是创建该类的实例后,该实例的Field是不可改变的,Java提供的8个包装类和java.lang.String类都是不可变类. 如果需要创建自定义的不可变类,可遵守 ...
- Java中的高精度整数和高精度小数
在实际编码中,会遇到很多高精度的事例,比如,在计算金钱的时候就需要保留高精度小数,这样计算才不会有太大误差: 在下面的代码中,我们验证了,当两个float型的数字相加,得到的结果和我们的预期结果是有误 ...