Hive练习
一、基础DDL练习
SHOW DATABASES; CREATE DATABASE IF NOT EXISTS db1 COMMENT 'Our database db1'; SHOW DATABASES; DESCRIBE DATABASE db1; CREATE TABLE db1.table1 (word STRING, count INT); SHOW TABLES in db1; DESCRIBE db1.table1; USE db1; SHOW TABLES; SELECT * FROM db1.table1; DROP TABLE table1; DROP DATABASE db1; USE default;
二、基础DML语句
创建表
create table if not exists user_dimension (
uid STRING,
name STRING,
gender STRING,
birth DATE,
province STRING
)ROW FORMAT DELIMITED //按行切分的意思
FIELDS TERMINATED BY ',' //按逗号分隔的
查看表信息
describe user_dimension; show create table user_dimension; 查看所有表
show tables; 载入本地数据
load data local inpath '/home/orco/tempdata/user.data' overwrite into table user_dimension; 载入HDFS上的数据
load data inpath '/user/orco/practice_1/user.data' overwrite into table user_dimension; 验证
select * from user_dimension; 查看hive在hdfs上的存储目录
hadoop fs -ls /warehouse/
hadoop fs -ls /warehouse/user_dimension
三、复杂数据类型
示例2:
CREATE TABLE IF NOT EXISTS employees (
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE; //最后这一行,是默认,可以不写 载入数据
load data local inpath ' /home/orco/tempdata/data/employees.txt' overwrite into table employees ; 查询数据
SELECT name, deductions['Federal Taxes'] FROM employees WHERE deductions['Federal Taxes'] > 0.2; SELECT name, deductions['Federal Taxes'] FROM employees WHERE deductions['Federal Taxes'] > cast( 0.2 as float); SELECT name FROM employees WHERE subordinates[] = 'Todd Jones'; SELECT name, address FROM employees WHERE address.street RLIKE '^.*(Ontario|Chicago).*$';
四、数据模型-分区
为减少不必要的暴力数据扫描,可以对表进行分区,为避免产生过多小文件,建议只对离散字段进行分区

建表
CREATE TABLE IF NOT EXISTS stocks (
ymd DATE,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT
)
PARTITIONED BY (exchanger STRING, symbol STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 载入数据
load data local inpath '/home/orco/resources/apache-hive-2.1.1-bin/hivedata/stocks/NASDAQ/AAPL/stocks.csv' overwrite into table stocks partition(exchanger="NASDAQ", symbol="AAPL"); show partitions stocks; load data local inpath '/home/orco/resources/apache-hive-2.1.1-bin/hivedata/stocks/NASDAQ/INTC/stocks.csv' overwrite into table stocks partition(exchanger="NASDAQ", symbol="INTC"); load data local inpath '/home/orco/resources/apache-hive-2.1.1-bin/hivedata/stocks/NYSE/GE/stocks.csv' overwrite into table stocks partition(exchanger="NYSE", symbol="GE"); show partitions stocks; 查询
SELECT * FROM stocks WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; SELECT ymd, price_close FROM stocks WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; 查看HDFS文件目录
hadoop fs -ls /warehouse/stocks/ hadoop fs -ls /warehouse/stocks/exchanger=NASDAQ hadoop fs -ls /warehouse/stocks/exchanger=NASDAQ/symbol=AAPL
六、外部表
external关键字,删除表时,外部表只删除元数据,不删除数据,更加安全
数据
hadoop fs -put stocks /user/orco/ 创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS stocks_external (
ymd DATE,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT
)
PARTITIONED BY (exchanger STRING, symbol STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION '/user/orco/stocks'; select * from stocks_external; 载入数据
alter table stocks_external add partition(exchanger="NASDAQ", symbol="AAPL") location '/user/orco/stocks/NASDAQ/AAPL/' show partitions stocks_external; select * from stocks_external limit 10; alter table stocks_external add partition(exchanger="NASDAQ", symbol="INTC") location '/user/orco/stocks/NASDAQ/INTC/'; alter table stocks_external add partition(exchanger="NYSE", symbol="IBM") location '/user/orco/stocks/NYSE/IBM/'; alter table stocks_external add partition(exchanger="NYSE", symbol="GE") location '/user/orco/stocks/NYSE/GE/'; show partitions stocks_external; 查询
SELECT * FROM stocks_external WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; SELECT ymd, price_close FROM stocks_external WHERE exchanger = 'NASDAQ' AND symbol = 'AAPL' LIMIT 10; select exchanger, symbol,count(*) from stocks_external group by exchanger, symbol; select exchanger, symbol, max(price_high) from stocks_external group by exchanger, symbol; 删除表
删除内部表stocks
drop table stocks; 查看HDFS上文件目录
hadoop fs -ls /warehouse/ 删除外部表stocks_external
drop table stocks_external; 查看HDFS上文件目录
hadoop fs -ls /user/orco hadoop fs -ls /user/stocks
七、列式存储
在Create/Alter表的时候,可以为表以及分区的文件指定不同的格式
• Storage Formats
• Row Formats
• SerDe
STORED AS file_format
– STORED AS PARQUET
– STORED AS ORC
– STORED AS SEQUENCEFILE
– STORED AS AVRO
– STORED AS TEXTFILE
列式存储格式ORC与Parquet:存储空间

列式存储格式ORC与Parquet:性能
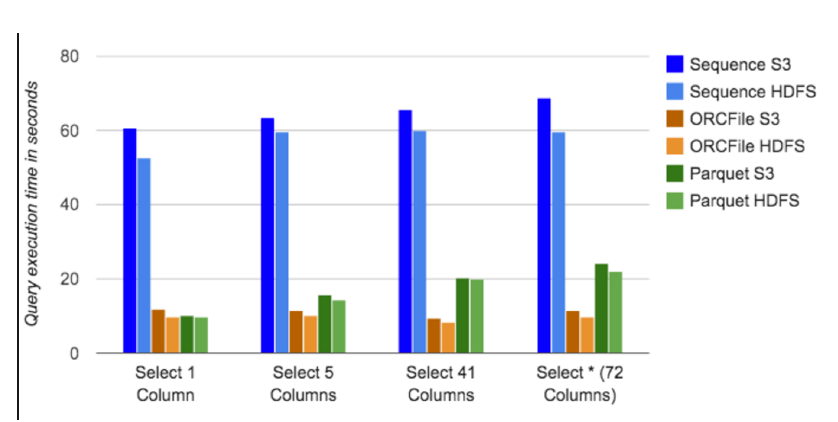
如何创建ORC表

create table if not exists record_orc (
rid STRING,
uid STRING,
bid STRING,
price INT,
source_province STRING,
target_province STRING,
site STRING,
express_number STRING,
express_company STRING,
trancation_date DATE
)
stored as orc; show create table record_orc; 载入数据
select * from record_orc limit 10; insert into table record_orc select * from record; select * from record_orc limit 10;
八、Lateral View,行转多列

CREATE TABLE IF NOT EXISTS employees (
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE; 查询
select name,subordinate from employees LATERAL VIEW explode(subordinates) subordinates_table AS subordinate;
九、explain
Hive练习的更多相关文章
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- HIVE教程
完整PDF下载:<HIVE简明教程> 前言 Hive是对于数据仓库进行管理和分析的工具.但是不要被“数据仓库”这个词所吓倒,数据仓库是很复杂的东西,但是如果你会SQL,就会发现Hive是那 ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
- hive
Hive Documentation https://cwiki.apache.org/confluence/display/Hive/Home 2016-12-22 14:52:41 ANTLR ...
- 深入浅出数据仓库中SQL性能优化之Hive篇
转自:http://www.csdn.net/article/2015-01-13/2823530 一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,R ...
- Hive读取外表数据时跳过文件行首和行尾
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 有时候用hive读取外表数据时,比如csv这种类型的,需要跳过行首或者行尾一些和数据无关的或者自 ...
- Hive索引功能测试
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 从Hive的官方wiki来看,Hive0.7以后增加了一个对表建立index的功能,想试下性能是 ...
- 轻量级OLAP(二):Hive + Elasticsearch
1. 引言 在做OLAP数据分析时,常常会遇到过滤分析需求,比如:除去只有性别.常驻地标签的用户,计算广告媒体上的覆盖UV.OLAP解决方案Kylin不支持复杂数据类型(array.struct.ma ...
随机推荐
- Leetcode: Anagrams(颠倒字母而成的字)
题目 Given an array of strings, return all groups of strings that are anagrams. Note: All inputs will ...
- logback中MDC使用
今天在项目发现别人写了很多MDC.put("taskid", "testThread/heart/main_heart");或者MDC.put("ta ...
- poj_2486 动态规划
题目大意 N个节点构成一棵树,每个节点上有一个权重val[i], 从根节点root出发在树上行走,行走的时候只能沿着树枝行进.最多在树上走k步,每第一次到达某个节点j,可以获得val[j]的收益,求从 ...
- 160401、关于cronExpression的介绍
关于cronExpression的介绍: 每一个字段都有一套可以指定有效值,如 Seconds (秒):可以用数字0-59 表示, Minutes(分) :可以用数字0-59 表 ...
- Linux 磁盘管理的命令
Linux 磁盘管理 磁盘分区及挂载: 先查询系统的使用情况: 使用fdisk -l语句 查询结果: 进行磁盘的新建:***添加磁盘时系统必须处于关机状态** 在进行对系统磁盘的使用情况的查询 查 ...
- 直接IO 零拷贝 DAM 自缓存应用程序
直接IO 零拷贝 DAM 自缓存应用程序
- Convolution Matrix
w褶积矩阵.二值化旧图经核矩阵得到新图. https://docs.gimp.org/en/plug-in-convmatrix.html 8.2. Convolution Matrix 8.2.1. ...
- Google发布机器学习术语表 (包括简体中文)
Google 工程教育团队已经发布了多语种的 Google 机器学习术语表,该术语表中列出了一般的机器学习术语和 TensorFlow 专用术语的定义.语言版本包括西班牙语,法语,韩语和简体中文. 查 ...
- 浅析Android View(二)
深入理解Android View(一) View的位置參数信息 二.View的绘制过程 View的绘制过程一共分为三个部分: - measure(測量View的大小) - layout(确定View的 ...
- window下的开发环境:常用软件
window下的开发环境:常用软件 Visio 2010 - 产品设计 xmind -产品设计 Axure -产品设计 Edraw max 7.3(破解版) -产品设计 ...