TensorFlow学习笔记(三)MNIST数字识别问题
一、MNSIT数据处理
MNSIT是一个非常有名的手写体数字识别数据集。包含60000张训练图片,10000张测试图片。每张图片是28X28的数字。
TonserFlow提供了一个类来处理 MNSIT数据。这个类会自动下载并转化数据结构。

import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist_data = input_data.read_data_sets("mnist_set",one_hot=True)
# print training data size
print("training_data_size",mnist_data.train.num_examples)
# print validation data size
print("validating_data_size",mnist_data.validation.num_examples)
#print testing data size
print("testing data size",mnist_data.test.num_examples)
print("example train image :",mnist_data.train.images[0])
print("example train label :",mnist_data.train.labels[0])
为了方便使用随机梯度下降,
input_data.read_data_sets还提供train.next_batch函数
batch_size = 100
train_x ,train_y = mnist_data.train.next_batch(batch_size)
print("X_shape",train_x.shape)
print("Y_shape",train_y.shape) ##
#X_shape (100, 784)
#Y_shape (100, 10)
二、神经网络模型训练及不同模型效果的对比
1.TF训练神经网络
利用上一篇介绍的方法搭建网络。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("mnist_set",one_hot=True)
#数据集相关常数
INPUT_NODE = 784
OUTPU_NODE = 10
#配置神经网络参数
LAYER1_NODE = 500
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8 #基础学习率
LEARNING_RATE_DECAY = 0.99#学习衰减率
REGULARIZATION_RATE = 0.0001#正则的惩罚系数
MOVE_AVG_RATE = 0.99 #滑动平均衰减率
TRAIN_STEPS = 30000 def inference(input_tensor,weights1,biases1,weight2,biases2,avg_class=None):
#当没有提供滑动平均类时,直接使用当前值
if avg_class == None:
#计算隐藏层的前向传播结果,使用RELU激活函数
layer1 = tf.nn.relu(tf.matmul(input_tensor,weights1)+biases1)
#返回输出层的前向传播
return tf.matmul(layer1,weight2)+ biases2
else:
#前向传播之前,用avg——class计算出变量的滑动平均值
layer1 = tf.nn.relu(tf.matmul(input_tensor,avg_class.average(weights1))+avg_class.average(biases1))
return tf.matmul(layer1,avg_class.average(weight2))+ avg_class.average(biases2)
#模型的训练过程
def train(mnist):
x = tf.placeholder(tf.float32,[None,INPUT_NODE],name='x-input')
y_ = tf.placeholder(tf.float32,[None,OUTPU_NODE],name="y_input") #隐藏层参数
w1 = tf.Variable(tf.random_normal([INPUT_NODE,LAYER1_NODE],stddev=0.1))
b1 = tf.Variable(tf.constant(0.1,shape=[LAYER1_NODE]))
#输出层参数
w2 = tf.Variable(tf.random_normal([LAYER1_NODE,OUTPU_NODE],stddev=0.1))
b2 = tf.Variable(tf.constant(0.1,shape=[OUTPU_NODE]))
y = inference(x,w1,b1,w2,b2)
#定义存储训练轮数的变量,设为不可训练
global_step = tf.Variable(0,trainable=False)
#初始化滑动平均类
variable_averages = tf.train.ExponentialMovingAverage(MOVE_AVG_RATE,global_step)
#在神经网络的所有参数变量上使用滑动平均
variable_averages_op = variable_averages.apply(tf.trainable_variables())
averages_y = inference(x,w1,b1,w2,b2,avg_class=variable_averages)
#计算交叉熵损失
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
#计算交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
#计算L2正则的损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
regularization = regularizer(w1)+ regularizer(w2)
#总的损失
loss = cross_entropy_mean + regularization #设置指数衰减的学习率
training_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples/BATCH_SIZE,LEARNING_RATE_DECAY)
train_step = tf.train.GradientDescentOptimizer(training_rate).minimize(loss,global_step)
#更新滑动平均值
with tf.control_dependencies([train_step,variable_averages_op]):
train_op = tf.no_op(name='train') #验证前向传播结果是否正确
correct_prediction = tf.equal(tf.argmax(averages_y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #初始会话,开始训练
with tf.Session() as sess:
tf.global_variables_initializer().run()
#准备验证数据和测试数据
validate_feed = {x:mnist.validation.images,y_: mnist.validation.labels}
test_feed = {x:mnist.test.images,y_: mnist.test.labels}
#迭代训练神经网络
for i in range(TRAIN_STEPS):
if i % 1000 == 0:
validate_acc = sess.run(accuracy,feed_dict=validate_feed)
print("After %s training steps ,validation accuracy is %s"%(i,validate_acc))
xs,ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op,feed_dict={x:xs,y_:ys})
#训练结束后,在测试集上验证准确率
test_acc = sess.run(accuracy,test_feed)
print("After %s training steps ,test accuracy is %s"%(TRAIN_STEPS,test_acc)) def main(argv=None):
mnist = input_data.read_data_sets("mnist_set",one_hot=True)
train(mnist)
if __name__ == '__main__':
#TF 提供了一个主程序入口,tf.app.run会自动调用上面的main()
tf.app.run()
2.使用验证数据集判断模型效果
为了评判不同网络在不同参数下的效果,一般从训练数据中抽取一部分作为验证数据,使用验证数据可以评判不同参数下模型的表现。除了使用验证数据,还可以使用交叉验证的方式。
三、变量管理
TensorFlow提供了一个通过变量名称来创建或者获取变量的机制。通过这个机制可以,在不同的函数中可以通过变量的名字来使用变量。通过变量名称来获取变量的函数是
tf.get_variable和tf.variable_scope.
tf.get_variable除了获取变量,还具有与tf.Variable相似的功能。均可用来创建变量。
#下面两个定义是等价的
v = tf.Variable(tf.constant(1.0,shape=[1]),name="v")
v = tf.get_variable(name="v",shape=[1],initializer=tf.constant_initializer(1.0))
TF提供了7中不同的初始化函数
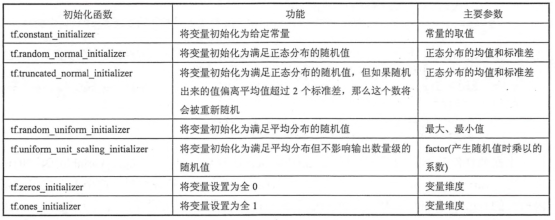
tf.get_variable和tf.Variable最大的区别在于指定变量名称的参数,tf.Variable的变量名称是可选参数,tf.get_variable的变量名称是必填参数。
如果需要通过tf.get_variable获取一个已经创建的变量,需要通过tf.variable_scope来创建一个上下文管理器,
with tf.variable_scope("foo"):
v = tf.get_variable("v",[1],initializer=tf.constant_initializer(1.0))
#如果命名空间foo中已经存在了v,这会报错
#ValueError: Variable foo/v already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope?
#在声明上下文管理器的时候,直接将reuse设为True,tf。get_variable则会直接获取已经存在的变量,但设为true的时候tf。get_variable不能创建变量
with tf.variable_scope("foo",reuse=True):
v1 = tf.get_variable("v",[1])
TensorFlow中tf.variable_scope函数可以嵌套。
with tf.variable_scope("root",reuse=True):
print(tf.get_variable_scope().reuse) #True
with tf.variable_scope("bar",reuse=False):
print(tf.get_variable_scope().reuse) #True 与外层的保持一致
with tf.variable_scope("foo",reuse=False):
print(tf.get_variable_scope().reuse) #即使指定了reuse,也会保持与外层一致
print(tf.get_variable_scope().reuse)
print(tf.get_variable_scope().reuse)
with tf.variable_scope("root"):
print(tf.get_variable_scope().reuse) #false
with tf.variable_scope("bar",reuse=True):
print(tf.get_variable_scope().reuse) #true
with tf.variable_scope("foo"):
print(tf.get_variable_scope().reuse) #true
print(tf.get_variable_scope().reuse) #true
print(tf.get_variable_scope().reuse) #false
利用tf.get_variable和tf.variable_scope来改进我们MNIST的程序
def inference(input_tensor,avg_class=None,reuse = False):
#当没有提供滑动平均类时,直接使用当前值
if avg_class == None:
#计算隐藏层的前向传播结果,使用RELU激活函数
with tf.variable_scope("layer1",reuse=reuse):
weight = tf.get_variable("weight",shape=[INPUT_NODE,LAYER1_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases",shape=[LAYER1_NODE],initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor,weight)+biases)
#返回输出层的前向传播
with tf.variable_scope("layer2",reuse=reuse):
weight = tf.get_variable("weight",shape=[LAYER1_NODE,OUTPU_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases",shape=[OUTPU_NODE],initializer=tf.constant_initializer(0.0))
layer2 = tf.nn.relu(tf.matmul(layer1,weight)+biases)
return layer2
else:
#前向传播之前,用avg——class计算出变量的滑动平均值
with tf.variable_scope("layer1",reuse=reuse):
weight = tf.get_variable("weight",shape=[INPUT_NODE,LAYER1_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases",shape=[LAYER1_NODE],initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor,avg_class.average(weight))+avg_class.average(biases))
#返回输出层的前向传播
with tf.variable_scope("layer2",reuse=reuse):
weight = tf.get_variable("weight",shape=[LAYER1_NODE,OUTPU_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases",shape=[OUTPU_NODE],initializer=tf.constant_initializer(0.0))
layer2 = tf.nn.relu(tf.matmul(layer1,avg_class.average(weight))+avg_class.average(biases))
return layer2
四、模型的持久化
之前给出的样例代码在训练完成之后就直接退出,并没有将训练得到的模型保存下来。TF提供了模型的持久化,还可以从持久化的模型文件中还原被保存的模型。
1、模型持久化的代码实现
TensorFlow提供了一个简单的API(tf.train.Saver)来保存模型。
v1 = tf.Variable(tf.constant(1.0,shape=[1],name="v1"))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name="v2"))
result = v1 + v2
init_op = tf.global_variables_initializer()
#声明tf.train.Saver类用于保存模型
saver = tf.train.Saver() with tf.Session() as sess:
sess.run(init_op)
#将模型保存到model。ckpt文件中
saver.save(sess,"Model/model.ckpt")
加载保存的模型
v1 = tf.Variable(tf.constant(1.0,shape=[1],name="v1"))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name="v2"))
result = v1 + v2
# init_op = tf.global_variables_initializer()
#声明tf.train.Saver类用于保存模型
saver = tf.train.Saver() with tf.Session() as sess:
# sess.run(init_op)
#将模型保存到model。ckpt文件中
saver.restore(sess,"Model/model.ckpt")
print(sess.run(result))
这里加载模型的代码和保存模型的代码基本一致,也需要先定义计算图模型的运算只是没有运行变量初始化。如果不希望重复定义图上的运算,也可以直接加载已经持久化的图。TensorFlow提供了这样的方法tf.train.import_meta_graph
#直接加载持久化计算图
saver = tf.train.import_meta_graph("Model/model.ckpt.meta") with tf.Session() as sess: saver.restore(sess,"Model/model.ckpt")
#通过张量的名称来获取张量
print(sess.run(tf.get_default_graph().get_tensor_by_name("add:0")))
上面的程序,默认保存或加载了TF计算图中的全部变量。但有时只需要保存或加载部分变量。在声明tf.train.Saver类时可以提供一个列表来制定需要保存或加载的变量。例如
tf.train.Saver([v1]).
除了选择需要加载的变量,tf.train.Saver还支持在保存或加载时给变量重命名。
#保存模型 v1 = tf.Variable(tf.constant(1.0,shape=[1],name="outer_v1"))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name="outer_v2"))
result = v1 + v2
init_op = tf.global_variables_initializer()
#声明tf.train.Saver类用于保存模型
saver = tf.train.Saver([v1,v2])
with tf.Session() as sess:
sess.run(init_op)
saver.save(sess,"Model/model.ckpt") #加载模型
v1 = tf.Variable(tf.constant(1.0,shape=[1],name="outer_v1"))
v2 = tf.Variable(tf.constant(2.0,shape=[1],name="outer_v2"))
saver = tf.train.Saver({"v1":v1,"v2":v2})
TensorFlow学习笔记(三)MNIST数字识别问题的更多相关文章
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- tensorflow学习笔记三:实例数据下载与读取
一.mnist数据 深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集. tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们 ...
- TensorFlow学习笔记(MNIST报错修正 适用Tensorflow1.3)
在Tensorflow实战Google框架下的深度学习这本书的MNIST的图像识别例子中,每次都要报错 错误如下: Only call `sparse_softmax_cross_entropy_ ...
- tensorflow学习笔记————分类MNIST数据集
在使用tensorflow分类MNIST数据集中,最容易遇到的问题是下载MNIST样本的问题. 一般是通过使用tensorflow内置的函数进行下载和加载, from tensorflow.examp ...
- python3学习笔记三(数字类型,字符串)
数字(Number)类型 有四种类型:整数.布尔型.浮点数和复数 int整数 bool布尔,如True float浮点数,1.23 complex复数,1+2j.1.2+2.3j 内置的 type() ...
- tensorflow学习笔记(10) mnist格式数据转换为TFrecords
本程序 (1)mnist的图片转换成TFrecords格式 (2) 读取TFrecords格式 # coding:utf-8 # 将MNIST输入数据转化为TFRecord的格式 # http://b ...
- tensorflow学习笔记(三):实现自编码器
黄文坚的tensorflow实战一书中的第四章,讲述了tensorflow实现多层感知机.Hiton早年提出过自编码器的非监督学习算法,书中的代码给出了一个隐藏层的神经网络,本人扩展到了多层,改进了代 ...
- tensorflow学习笔记三----------基本操作
tensorflow中的一些操作和numpy中的很像,下面列出几个比较常见的操作 import tensorflow as tf #定义三行四列的零矩阵 tf.zeros([3,4]) #定义两行三列 ...
- tensorflow学习笔记(三十四):Saver(保存与加载模型)
Savertensorflow 中的 Saver 对象是用于 参数保存和恢复的.如何使用呢? 这里介绍了一些基本的用法. 官网中给出了这么一个例子: v1 = tf.Variable(..., nam ...
随机推荐
- 模拟HttpContext单元测试
众所周知 ASP.NET MVC 的一个显著优势即可以很方便的实现单元测试,但在我们测试过程中经常要用到HttpContext,而默认情况下单元测试框架是不提供HttpContext的模拟的,本文通过 ...
- Android Studio 工具栏添加图标
本文中 Android Studio 的版本为 Android Studio 2.2 ,操作系统为 Windows,如有操作不同,可能是版本差异.在工具栏中添加一些常用的图标有利于我们开发,举例说明: ...
- 百家搜索:在站点中加入Google、百度等搜索引擎
来源:http://www.ido321.com/1143.html 看到一些站点上加入了各种搜索引擎. 如Google.百度.360.有道等.就有点好奇.这个怎么实现?研究了一各个搜索引擎怎么传送k ...
- html转pdf工具:wkhtmltopdf.exe
百度云下载:http://pan.baidu.com/s/1dEX0h93
- apacheserver全局配置具体解释
server标识相关指令: ServerName ServerAdmin ServerSignature ServerTokens UseCanonicalName UseCanonicalPhysi ...
- ItcastOA_整体说明_准备环境
1. 整体说明 1.1. 项目说明 1.1.1. OA概述 OA是Office Automation的缩写,本意为利用技术的手段提高办公的效率,进而实现办公的自动化处理.实现信息化.无纸化办公,可方便 ...
- Android 数据存储(XML解析)
在androd手机中处理xml数据时很常见的事情,通常在不同平台传输数据的时候,我们就可能使用xml,xml是与平台无关的特性,被广泛运用于数据通信中,那么在android中如何解析xml文件数据 ...
- 以打字形式展示placeholder的插件
http://weber.pub/以打字形式展示placeholder的插件/197.html
- 【BZOJ2565】最长双回文串 Manacher
[BZOJ2565]最长双回文串 Description 顺序和逆序读起来完全一样的串叫做回文串.比如acbca是回文串,而abc不是(abc的顺序为“abc”,逆序为“cba”,不相同).输入长度为 ...
- nginx简单的nginx.conf配置
nginx.conf配置如下: #user nobody;worker_processes 1; #error_log logs/error.log;#error_log logs/error.log ...