(转)zero copy原理
转自:
http://blog.csdn.net/zzz_781111/article/details/7534649
Date transfer: The traditional approach
考虑一下这个场景,通过网络把一个文件传输给另一个程序。这个操作的核心代码就是下面的两个函数:
Listing 1. Copying bytes from a file to a socket
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
尽管看起来很简单,但是在OS的内部,这个copy操作要经历四次user mode和kernel mode之间的上下文切换,甚至连数据都被拷贝了四次!Figure 1描述了data是怎么移动的。
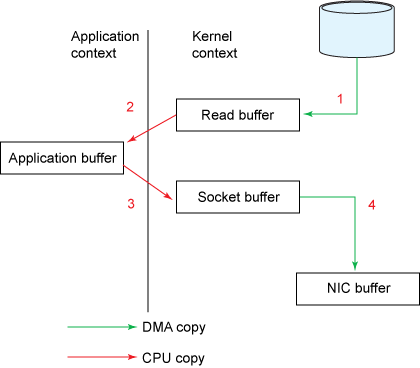
Figure 2 描述了上下文切换
Figure 2. Traditional context switches
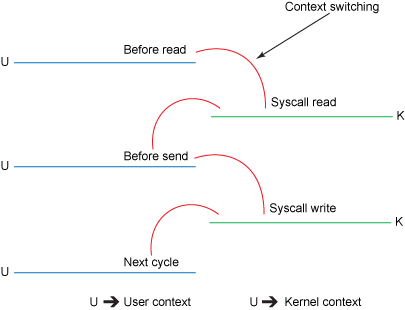
其中的步骤如下:
read() 引入了一次从user mode到kernel mode的上下文切换。实际上调用了sys_read() 来从文件中读取data。第一次copy由DMA完成,将文件内容从disk读出,存储在kernel的buffer中。
然后data被copy到user buffer中,此时read()成功返回。这是触发了第二次context switch: 从kernel到user。至此,数据存储在user的buffer中。
send() socket call 带来了第三次context switch,这次是从user mode到kernel mode。同时,也发生了第三次copy:把data放到了kernel adress space中。当然,这次的kernel buffer和第一步的buffer是不同的两个buffer。
最终 send() system call 返回了,同时也造成了第四次context switch。同时第四次copy发生,DMA将data从kernel buffer拷贝到protocol engine中。第四次copy是独立而且异步的。
使用kernel buffer做中介(而不是直接把data传到user buffer中)看起来比较低效(多了一次copy)。然而实际上kernel buffer是用来提高性能的。在进行读操作的时候,kernel buffer起到了预读cache的作用。当写请求的data size比kernel buffer的size小的时候,这能够显著的提升性能。在进行写操作时,kernel buffer的存在可以使得写请求完全异步。
悲剧的是,当请求的data size远大于kernel buffer size的时候,这个方法本身变成了性能的瓶颈。因为data需要在disk,kernel buffer,user buffer之间拷贝很多次(每次写满整个buffer)。
而Zero copy正是通过消除这些多余的data copy来提升性能。
Data Transfer:The Zero Copy Approach
如果重新检查一遍traditional approach,你会注意到实际上第二次和第三次copy是毫无意义的。应用程序仅仅缓存了一下data就原封不动的把它发回给socket buffer。实际上,data应该直接在read buffer和socket buffer之间传输。transferTo()方法正是做了这样的操作。Listing 2是transferTo()的函数原型:
public void transferTo(long position, long count, WritableByteChannel target);
transferTo()方法把data从file channel传输到指定的writable byte channel。它需要底层的操作系统支持zero copy。在UNIX和各种Linux中,会执行List 3中的系统调用sendfile(),该命令把data从一个文件描述符传输到另一个文件描述符(Linux中万物皆文件):
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
在List 1中的file.read()和socket.send()可以用一句transferTo()替代,如List 4:
transferTo(position, count, writableChannel);
Figure 3 展示了在使用transferTo()之后的数据流向
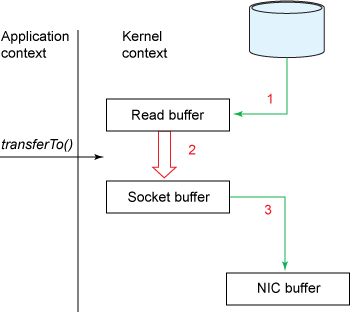
Figure 4 展示了在使用transferTo()之后的上下文切换

在像Listing 4那样使用transferTo()之后,整个过程如下:
transferTo()方法使得文件内容被DMA engine直接copy到一个read buffer中。然后数据被kernel再次拷贝到和output socket相关联的那个kernel buffer中去。
第三次拷贝由DMA engine完成,它把kernel buffer中的data拷贝到protocol engine中。
这是一个很明显的进步:我们把context switch的次数从4次减少到了2次,同时也把data copy的次数从4次降低到了3次(而且其中只有一次占用了CPU,另外两次由DMA完成)。但是,要做到zero copy,这还差得远。如果网卡支持 gather operation,我们可以通过kernel进一步减少数据的拷贝操作。在2.4及以上版本的linux内核中,开发者修改了socket buffer descriptor来适应这一需求。这个方法不仅减少了context switch,还消除了和CPU有关的数据拷贝。user层面的使用方法没有变,但是内部原理却发生了变化:
transferTo()方法使得文件内容被copy到了kernel buffer,这一动作由DMA engine完成。
没有data被copy到socket buffer。取而代之的是socket buffer被追加了一些descriptor的信息,包括data的位置和长度。然后DMA engine直接把data从kernel buffer传输到protocol engine,这样就消除了唯一的一次需要占用CPU的拷贝操作。
Figure 5描述了新的transferTo()方法中的data copy: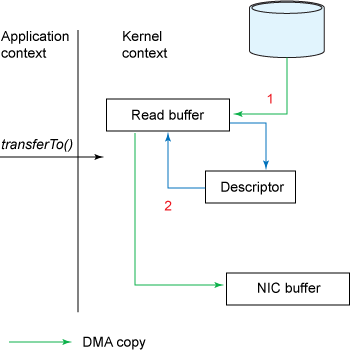
许多web应用都会向用户提供大量的静态内容,这意味着有很多data从硬盘读出之后,会原封不动的通过socket传输给用户。这种操作看起来可能不会怎么消耗CPU,但是实际上它是低效的:kernal把数据从disk读出来,然后把它传输给user级的application,然后application再次把同样的内容再传回给处于kernal级的socket。这种场景下,application实际上只是作为一种低效的中间介质,用来把disk file的data传给socket。
data每次穿过user-kernel boundary,都会被copy,这会消耗cpu,并且占用RAM的带宽。幸运的是,你可以用一种叫做Zero-Copy的技术来去掉这些无谓的copy。应用程序用zero copy来请求kernel直接把disk的data传输给socket,而不是通过应用程序传输。Zero copy大大提高了应用程序的性能,并且减少了kernel和user模式的上下文切换。
Java的libaries在linux和unix中支持zero copy,一个关键的api是java.nio.channel.FileChannel的transferTo()方法。我们可以用transferTo()来把bytes直接从调用它的channel传输到另一个writable byte channel,中间不会使data经过应用程序。本文首先描述传统的copy是怎样坑爹的,然后再展示zero-copy技术在性能上是多么的给力以及为什么给力。
Date transfer: The traditional approach
考虑一下这个场景,通过网络把一个文件传输给另一个程序。这个操作的核心代码就是下面的两个函数:
Listing 1. Copying bytes from a file to a socket
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
尽管看起来很简单,但是在OS的内部,这个copy操作要经历四次user mode和kernel mode之间的上下文切换,甚至连数据都被拷贝了四次!Figure 1描述了data是怎么移动的。
Figure 2 描述了上下文切换
Figure 2. Traditional context switches
其中的步骤如下:
read() 引入了一次从user mode到kernel mode的上下文切换。实际上调用了sys_read() 来从文件中读取data。第一次copy由DMA完成,将文件内容从disk读出,存储在kernel的buffer中。
然后data被copy到user buffer中,此时read()成功返回。这是触发了第二次context switch: 从kernel到user。至此,数据存储在user的buffer中。
send() socket call 带来了第三次context switch,这次是从user mode到kernel mode。同时,也发生了第三次copy:把data放到了kernel adress space中。当然,这次的kernel buffer和第一步的buffer是不同的两个buffer。
最终 send() system call 返回了,同时也造成了第四次context switch。同时第四次copy发生,DMA将data从kernel buffer拷贝到protocol engine中。第四次copy是独立而且异步的。
使用kernel buffer做中介(而不是直接把data传到user buffer中)看起来比较低效(多了一次copy)。然而实际上kernel buffer是用来提高性能的。在进行读操作的时候,kernel buffer起到了预读cache的作用。当写请求的data size比kernel buffer的size小的时候,这能够显著的提升性能。在进行写操作时,kernel buffer的存在可以使得写请求完全异步。
悲剧的是,当请求的data size远大于kernel buffer size的时候,这个方法本身变成了性能的瓶颈。因为data需要在disk,kernel buffer,user buffer之间拷贝很多次(每次写满整个buffer)。
而Zero copy正是通过消除这些多余的data copy来提升性能。
Data Transfer:The Zero Copy Approach
如果重新检查一遍traditional approach,你会注意到实际上第二次和第三次copy是毫无意义的。应用程序仅仅缓存了一下data就原封不动的把它发回给socket buffer。实际上,data应该直接在read buffer和socket buffer之间传输。transferTo()方法正是做了这样的操作。Listing 2是transferTo()的函数原型:
public void transferTo(long position, long count, WritableByteChannel target);
transferTo()方法把data从file channel传输到指定的writable byte channel。它需要底层的操作系统支持zero copy。在UNIX和各种Linux中,会执行List 3中的系统调用sendfile(),该命令把data从一个文件描述符传输到另一个文件描述符(Linux中万物皆文件):
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
在List 1中的file.read()和socket.send()可以用一句transferTo()替代,如List 4:
transferTo(position, count, writableChannel);
Figure 3 展示了在使用transferTo()之后的数据流向
Figure 4 展示了在使用transferTo()之后的上下文切换
在像Listing 4那样使用transferTo()之后,整个过程如下:
transferTo()方法使得文件内容被DMA engine直接copy到一个read buffer中。然后数据被kernel再次拷贝到和output socket相关联的那个kernel buffer中去。
第三次拷贝由DMA engine完成,它把kernel buffer中的data拷贝到protocol engine中。
这是一个很明显的进步:我们把context switch的次数从4次减少到了2次,同时也把data copy的次数从4次降低到了3次(而且其中只有一次占用了CPU,另外两次由DMA完成)。但是,要做到zero copy,这还差得远。如果网卡支持 gather operation,我们可以通过kernel进一步减少数据的拷贝操作。在2.4及以上版本的linux内核中,开发者修改了socket buffer descriptor来适应这一需求。这个方法不仅减少了context switch,还消除了和CPU有关的数据拷贝。user层面的使用方法没有变,但是内部原理却发生了变化:
transferTo()方法使得文件内容被copy到了kernel buffer,这一动作由DMA engine完成。
没有data被copy到socket buffer。取而代之的是socket buffer被追加了一些descriptor的信息,包括data的位置和长度。然后DMA engine直接把data从kernel buffer传输到protocol engine,这样就消除了唯一的一次需要占用CPU的拷贝操作。
Figure 5描述了新的transferTo()方法中的data copy:
(转)zero copy原理的更多相关文章
- OC加强-day06
#program mark - 08 NSMutableDictionary的使用 [掌握] "/08 NSMutableDictionary的使用/1_练习 "练习 1.小明的身 ...
- 2017/6Summary
字符串转换为JSON 1.var json = eval('(' + str + ')'); 2.var json = (new Function("return " + str) ...
- Python_oldboy_自动化运维之路_全栈考试(七)
1. 计算100-300之间所有能被3和7整除的所有数之和 # -*- coding: UTF-8 -*- #blog:http://www.cnblogs.com/linux-chenyang/ c ...
- 【原创】go语言学习(十三)struct介绍2
目录: 方法的定义 函数和方法的区别 值类型和指针类型 面向对象和继承 结构体和json序列化 方法的定义 1.和其他语言不一样,Go的方法采⽤用另外一种方式实现. package main impo ...
- flume面试题
1 你是如何实现Flume数据传输的监控的使用第三方框架Ganglia实时监控Flume. 2 Flume的Source,Sink,Channel的作用?你们Source是什么类型?1.作用 (1)S ...
- HEC-ResSim原文档
HEC-ResSim Reservoir System Simulation User's Manual Version 3.1 May 201 ...
- MongoDB Wiredtiger存储引擎实现原理——Copy on write的方式管理修改操作,Btree cache
转自:http://www.mongoing.com/archives/2540 传统数据库引擎的数据组织方式,一般存储引擎都是采用 btree 或者 lsm tree 来实现索引,但是索引的最小单位 ...
- cglib、orika、spring等bean copy工具性能测试和原理分析
简介 在实际项目中,考虑到不同的数据使用者,我们经常要处理 VO.DTO.Entity.DO 等对象的转换,如果手动编写 setter/getter 方法一个个赋值,将非常繁琐且难维护.通常情况下,这 ...
- OC基础:内存(进阶):retain.copy.assign的实现原理 分类: ios学习 OC 2015-06-26 17:36 58人阅读 评论(0) 收藏
遍历构造器的内存管理 a.遍历构造器方法内部使用autorelease释放对象 b.通过遍历构造器生成的对象.不用释放. 内存的管理总结 1.想占用某个对象的时候,要让它的引用计数器+1(retain ...
随机推荐
- 【划分树+二分】HDU 4417 Super Mario
第一次 耍划分树.. . 模板是找第k小的 #include <stdio.h> #include <string.h> #include <stdlib.h> # ...
- mysql GROUP_CONCAT 函数 将相同的键的多个单元格合并到一个单元格
mysql GROUP_CONCAT 函数 将相同的键的多个单元格合并到一个单元格 MemberID MemberName FruitName -------------- ------------- ...
- Android软件开发之EditText 详解
EditText在API中的结构 java.lang.Objectandroid.view.Viewandroid.widget.TextView android.widget.Edit ...
- 把一个一中的字段更新另一个表中的t-sql
UPDATE dbo.CommDescr SET Descr=(SELECT ba.content FROM dbo.blog_article ba WHERE ba.id=3) WHERE Comm ...
- 缺省模板参数(借助标准模板容器实现Stack模板)、成员模板、关键字typename
一.缺省模板参数 回顾前面的文章,都是自己管理stack的内存,无论是链栈还是数组栈,能否借助标准模板容器管理呢?答案是肯定的,只需要多传一个模板参数即可,而且模板参数还可以是缺省的,如下: temp ...
- C++ 多线程(两个线程卖火车票)
#include <windows.h> #include <iostream.h> DWORD WINAPI Fun1Proc(LPVOID lpParameter);//t ...
- fft分析前后频谱数据
正弦信号输入 input 输入的原始信号 short [128] fir 滤波后的输出信号 SHORT [128] fft 傅里叶变换后的freq数据 float [128] rmroise 去除底 ...
- html增加锚点定位
第一种方法,也是最简单的方法是锚点用<a>标签,在href属性中写入DIV的id.如下: <!DOCTYPE html><html><head>< ...
- 漫谈Linux下的音频问题(转)
转自 http://www.kunli.info/2009/03/24/linux-sound-issue/ 现今的互联网,比较Linux和Windows的战争贴基本都成月经贴了.一群群激进的用户不断 ...
- jinja2问题集锦
用jinja2写模板的时候遇到了一些问题,记录一下 抽出base.html作为模板 之前的小项目写得都很不规范,模板都是能用就行,基本上只用到if语句,for语句和变量.导航栏都是复制粘贴,没有把共同 ...