Django haystack+solr搜索引擎部署的坑.
跟着<<Django by Example>> 一路做下来,到了搭建搜索引擎的步骤
默认的思路是用
obj.objects.filter(body__icontains='framework')
然后把得到的QuerySet 返回到模板中使用
首先要确保你的java版本在 1.7或之上
使用 java -version 查看
http://archive.apache.org/dist/lucene/solr/ 然后到这个网站里下载 Solr 这里我使用的是4.10.4(不同版本之间的差异有点不一样,慎重选择.不然会被坑死)
然后进入example文件夹
java -jar start.jar //服务运行Solr;
打开你的浏览器,进入URL:http://127.0.0.1:8983/solr/ 你会看到类似这种界面
我们要为我们的应用创建一个core ,首先要创建目录树
blog$ tree
.
├── conf
│ ├── core.properties
│ ├── lang
│ │ └── stopwords_en.txt
│ ├── protwords.txt
│ ├── _rest_managed.json
│ ├── schema.xml
│ ├── solrconfig.xml
│ ├── stopwords.txt
│ └── synonyms.txt
└── data
└── index
├── segments_1
├── segments.gen
在solrconfig.xml文件中添加如下XML代码:
?xml version="1.0" encoding="utf-8" ?>
<config>
<luceneMatchVersion>LUCENE_36</luceneMatchVersion>
<requestHandler name="/select" class="solr.StandardRequestHandler" default="true" />
<requestHandler name="/update" class="solr.UpdateRequestHandler" />
<requestHandler name="/admin" class="solr.admin.AdminHandlers" />
<requestHandler name="/admin/ping" class="solr.PingRequestHandler">
<lst name="invariants">
<str name="qt">search</str>
<str name="q">*:*</str>
</lst>
</requestHandler>
</config>
这是一个最小的Solr配置。编辑schema.xml文件,加入如下XML代码:
<?xml version="1.0" ?>
<schema name="default" version="1.5">
</schema>
然后我们创建一个自己的架构
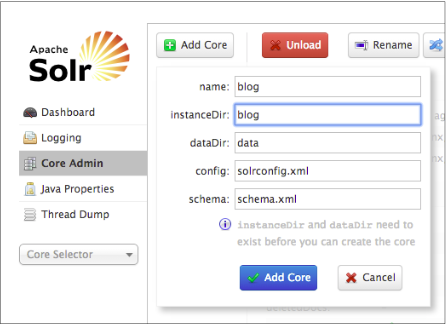
- name: blog
- instanceDir: blog
- dataDir: data
- config: solrconfig.xml
- schema: schema.xml
name字段是你想给这个core起的名字。instanceDir字段是你的core的目录。dataDir是索引数据将要存放的目录,它位于instanceDir目录下面。config字段是你的Solr XML配置文件名。schema字段是你的Solr XML 数据架构(schema)文件名。
为了在Django中使用Solr,我们还需要Haystack。使用下面的命令,通过pip渠道安装Haystack:
这里我们直接安装最新版的,书上有指定版本.跟着做坑了我一个早上,幸好各种google下来解决了问题,在此记录下,希望后面踩到坑的人也能顺利渡劫.
不过最好下之前看看自己的django版本haystack支持不支持...
附上github项目地址
https://github.com/django-haystack/django-haystack/issues
pip isntall django-haystack //Haystack能和一些搜索引擎后台交互。要使用Solr后端,你还需要安装pysolr模块。运行如下命令安装它: pip install pysolr 然后在setting 中添加它
INSTALLED_APPS = (
# ...
haystack',
) 再添加搜索引擎后端
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.solr_backend.SolrEngine',
'URL': 'http://127.0.0.1:8983/solr/blog'
},
}
在,我们必须将我们想要存储在搜索引擎中的模型进行注册。Haystack的惯例是在你的应用中创建一个search_indexes.py文件,然后在该文件中注册你的模型(models)。在你的blog应用目录下创建一个新的文件命名为search_indexes.py,添加如下代码:
from haystack import indexes
from .models import Post class PostIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
publish = indexes.DateTimeField(model_attr='publish') def get_model(self):
return Post def index_queryset(self, using=None):
return self.get_model().published.all()
这是一个Post模型(model)的自定义SearchIndex。通过这个索引(index),我们告诉Haystack这个模型(model)中的哪些数据必须被搜索引擎编入索引。这个索引(index)是通过继承indexes.SearchIndex和indexes.Indexable构建的。每一个SearchIndex都需要它的其中一个字段拥有document=True。按照惯例,这个字段命名为text。这个字段是一个主要的搜索字段。通过使用use_template=True,我们告诉Haystack这个字段将会被渲染成一个数据模板(template)来构建document,它会被搜索引擎编入索引(index)。publish字段是一个日期字段也会被编入索引。我们通过model_attr参数来表明这个字段对应Post模型(model)的publish字段。这个字段将用 被索引的Post对象的publish字段的内容 索引。
额外的字段,像这个为搜索提供额外的过滤器(filters),是非常有用的。get_model()方法必须返回将储存在这个索引中的documents的模型(model)。index_queryset()方法返回将会被编入索引的对象的查询集(QuerySet)。请注意,我们只包含了发布状态的帖子。
现在,在blog应用的模板(templates)目录下创建目录和文件search/indexes/blog/post_text.txt,然后添加如下代码:
{{ object.title }}
{{ object.tags.all|join:", " }}
{{ object.body }}
现在,我们已经有了一个自定义的搜索索引(index),我们需要创建合适的Solr架构(schema)。Solr的配置基于XML,所以我们必须为我们即将索引(index)的数据生成一个XML架构(schema)。非常幸运,haystack提供了一个基于我们的搜索索引(indexes),动态生成架构(schema)的方法。打开终端,运行以下命令:
python manage.py build_solr_schema

如果你看到的是这样的,那么恭喜你配置成功...
如果不是这样的,请去官网看看支持的版本和看看自己的版本对应不对应了...
在你的浏览器中打开 http://127.0.0.1:8983/solr/ 然后点击Core Admin菜单栏,再点击blog core,然后再点击Reload按钮:
索引数据(Indexing data) 让我们blog中的帖子编辑索引(index)到Solr中。打开终端,执行以下命令: python manage.py rebuild_index
y下一步
在浏览器中打开 http://127.0.0.1:8983/solr/#/blog 。在*Statistics下方,你会看到被编入索引(indexed)documents的数量,如下所示:
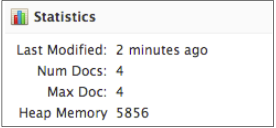
现在,在浏览器中打开 http://127.0.0.1:8983/solr/#/blog/query 。这是一个Solr提供的查询接口。点击Execute query按钮。默认的查询会请求你的core中所有被编入索引(indexde)的documents。你会看到一串带有这个查询结果的JSON输出。输出的documents如下所示:
{
"id": "blog.post.1",
"text": "Who was Django Reinhardt?\njazz, music\nThe Django web framework was named after the amazing jazz guitarist Django Reinhardt.",
"django_id": "1",
"publish": "2015-09-20T12:49:52Z",
"django_ct": "blog.post"
},这是每个帖子在搜索索引(index)中存储的数据。text字段包含了标题,通过逗号分隔的标签(tags),还有帖子的内容,这个字段是在我们之前定义的模板(template)上构建的。
你已经使用过python manage.py rebuild_index来删除索引(index)中的所有信息然后再次对documents进行索引(index)。为了不删除所有对象而更新你的索引(index),你可以使用python manage.py update_index。另外,你可以使用参数--age=<num_hours>来更新少量的对象。为了保证你的Solr索引更新,你可以为这个操作设置一个定时任务(Cron job)
创建一个搜索视图(view) 现在,我们要开始创建一个自定义视图(view)来允许我们的用户搜索帖子。首先,我们需要一个搜索表单(form)。编辑blog应用下的forms.py文件,加入以下表单: class SearchForm(forms.Form):
query = forms.CharField()
我们会使用query字段来让用户引入搜索条件(terms)。编辑blog应用下的views.py文件,加入以下代码:
def post_search(request):
form = SearchForm()
if 'query' in request.GET:
form = SearchForm(request.GET)
if form.is_valid():
cd = form.cleaned_data
results = SearchQuerySet().models(Post).filter(content=cd['query']).load_all()
# return HttpResponse(results.count())
# count total results
total_results = results.count() return render(request,'blog/post/search.html',
{'form':form,
'cd':cd,
'results':results,
'total_results':total_results}) return render(request,'blog/post/search.html',{'form':form})
搜索视图(view)已经准备好了。我们还需要创建一个模板(template)来展示表单(form)和用户执行搜索后返回的结果。在templates/blog/post/目录下创建一个新的文件命名为search.html,添加如下代码:
{% extends "blog/base.html" %}
{% block title %}Search{% endblock %}
{% block content %}
{% if "query" in request.GET %}
<h1>Posts containing "{{ cd.query }}"</h1>
<h3>Found {{ total_results }} result{{ total_results|pluralize }}</h3>
{% for result in results %}
{% with post=result.object %}
<h4><a href="{{ post.get_absolute_url }}">{{ post.title }}</a></h4>
{{ post.body|truncatewords:5 }}
{% endwith %}
{% empty %}
<p>There are no results for your query.</p>
{% endfor %}
<p><a href="{% url "blog:post_search" %}">Search again</a></p>
{% else %}
<h1>Search for posts</h1>
<form action="." method="get">
{{ form.as_p }}
<input type="submit" value="Search">
</form>
{% endif %}
{% endblock %}
添加视图
url(r'^search/$', views.post_search, name='post_search'),
现在,在浏览器中打开 http://127.0.0.1:8000/blog/search/。你会看到如下图所示的搜索表单(form):


Django haystack+solr搜索引擎部署的坑.的更多相关文章
- Django Haystack 全文检索与关键词高亮
Django Haystack 简介 django-haystack 是一个专门提供搜索功能的 django 第三方应用,它支持 Solr.Elasticsearch.Whoosh.Xapian 等多 ...
- Lucene/Solr搜索引擎开发笔记 - 第2章 Solr安装与部署(Tomcat篇)
一.安装环境 图1-1 Tomcat和Solr的版本 我本机目前使用的Java版本为JDK 1.8,因为Solr 4.9要求Java版本为1.7+,请注意. 二.Solr部署到Tomcat流程 图1- ...
- Solr 7 部署与使用踩坑全记录
前言 Solr 是一种可供企业使用的.基于 Lucene 的搜索服务器,它支持层面搜索.命中醒目显示和多种输出格式.在这篇文章中,我将介绍 Solr 的部署和使用的基本操作,希望能让初次使用的朋友们少 ...
- Lucene/Solr搜索引擎开发笔记 - 第1章 Solr安装与部署(Jetty篇)
一.为何开博客写<Lucene/Solr搜索引擎开发笔记> 本人毕业于2011年,2011-2014的三年时间里,在深圳前50强企业工作,从事工业控制领域的机器视觉方向,主要使用语言为C/ ...
- django 项目开发及部署遇到的坑
1.django 连接oracle数据库遇到的坑 需求:通过plsql建立的oracle数据表,想要django操作这几个表 python manage.py inspectdb table_name ...
- django项目上线环境部署
django项目上线环境部署 第一步 安装python虚拟环境 1 安装虚拟环境virtualenv 2 安装virtualenvwrapper工具 3 确认virtualenvwrapper.sh脚 ...
- Solr搜索引擎 — 通过mysql配置数据源
一,准备数据库数据表结构 CREATE TABLE `app` ( `id` int(11) NOT NULL AUTO_INCREMENT, `app_name` varchar(255) NOT ...
- django haystack报错: ModuleNotFoundError: No module named 'blog.whoosh_cn_backend'
在配置django haystack时报错: 解决方案: 将ENGINE的值 改为 这样就可以了.
- django+nginx+uwsgi_cent0s7.4 部署
django+nginx+uwsgi_cent0s7.4 部署 几条命令 # 查看是否有 uwsgi 相关的进程 ps -aux|grep "uwsgi" # 杀死有关 uwsgi ...
随机推荐
- __slots__用法
class Test(object): __slots__ = ("name","age") t = Test() t.name = "老王" ...
- 前端-JavaScript1-2——JavaScript建立认知
关于首篇的“ Hello world ! ”这事儿吧,挺有意思,就是学习任何的语言,我们都喜欢在屏幕上直接输出一点什么,当做最简单.最基本的案例.输出什么大家随意,但是很多人都习惯输出“hello w ...
- Python 爬58同城 城市租房信息
爬取完会自动生成csv电子表格文件,含有房价.押付.链接等信息 环境 py2.7 pip install lxml pip install cssselect #coding:utf-8 impo ...
- Ubuntu16.04下修改MySQL数据的默认存储位置
由于在Linux下MySQL默认是存储在/var/lib/mysql目录下,mysql的数据会非常大,由于/var所划分的空间不够大,所以我们需要将mysql数据存放路径修改一下,放到大分区里面,以便 ...
- JVM内容梳理
- 《算法导论》——重复元素的随机化快排Optimization For RandomizedQuickSort
昨天讨论的随机化快排对有重复元素的数组会陷入无限循环.今天带来对其的优化,使其支持重复元素. 只需修改partition函数即可: int partition(int *numArray,int he ...
- MATLAB——矩阵排序详解
<span style="font-size:18px;">(1)B=sort(A) 对一维或二维数组进行升序排序,并返回排序后的数组,当A为二维时,对数组每一列进行排 ...
- Java中的反射总结
反射是获取运行时类信息,即常量区中的Class信息. 要获取类信息,必然需要依据,不然系统怎么指定你要获取那个类信息, 类信息在java中就是Class类的一个对象,它是一个java类抽象,换句话说它 ...
- jQuery之动画
动画相关方法: .hide()..show()..toggle() 参数:null 或 (duration, easing, callblack) .fadeIn..fadeout ..fadeTog ...
- Halcom学习笔记1——Halcon知识点
文件: 1.浏览HDevelop示例程序 2.程序另存在:Ctrl+Shift+S 3.导出:Ctrl+Shift+O X 编辑: 1.快捷键: F3 激活 F4 注销 重复查找:C ...