Django之model模块创建表完整过程
Django中,与数据库相关的模块是model模块,它提供了一种简单易操作的API方式与数据库交互,它是通过ORM映射的方式来操作数据库,一个类对应数据库一张表,一个类属性,对应该表的一个字段,一个实例化的类对象就是一个表中的一行数据信息。在开发的阶段,工程师只需要python语言本身进行代码设计,而不用太过于分散注意力去操作SQL原生操作语句,这样的方法既有它的优点,同样也有不足之处。
它们优缺点的大致如下:
优点:
1、实现了代码与数据库的解耦合
2、开发者不需要操作太多的原生SQL,可以提高开发效率
3、防止SQL注入,通过对象操作的方式,默认就是防止SQL注入
缺点:
1、牺牲性能,对象转换到SQL会存在一定的消耗
2、当需要操作较复杂的语句时,用ORM对象操作的方式很难实现
ORM与数据库的映射关系如下:
表名--------》类名
字段--------》属性
表记录-----》类实例化对象
ORM的两大主要功能:
操作表:
--创建表
--修改表
--删除表
操作表数据行:增、删、改、查
Django自带的数据库为sqlite3,如果需要使用其他数据库,需要其他的准备工作,并且,使用其他数据库,需要自己提前建好数据库,然后通过Django去连接,Django并不会创建数据库。
本次使用Django自带数据库进行练习。使用的是Django2.0版本,python3,pycharm2018.2.4版。
完整过程:
一、编写模型类
在Django项目的APP应用下的models.py文件中编写类,每一个类就是一个最终都会被映射为一个数据表。在写类之前有个准备工作,在settings.py文件中的“INSTALLED_APPS”要先加入自己的APP应用,告诉Django有这个应用。如图:

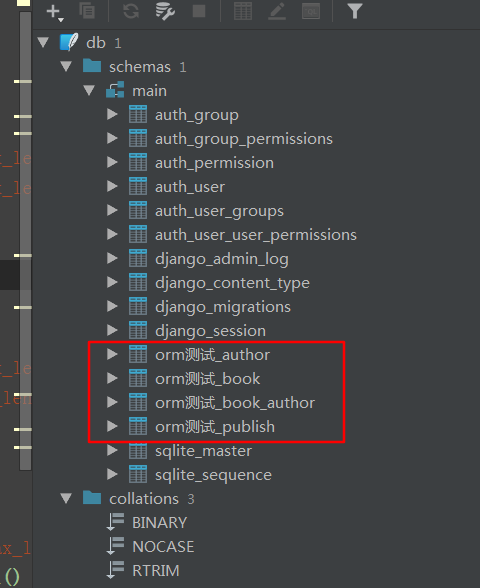
表分为单表,一对一表,一对多表,多对多表,就是表一般不会独立存在,总会与其他表存在联系。我创建了三个表,一个表为Publish(出版社),一个表为Author(作者),还有一个表Book(书籍),其中表书籍与表出版社是外键关系,与作者是多对多的关系。
class Publish(models.Model):
name = models.CharField(max_length=64)
city = models.CharField(max_length=63,null=True)
def __str__(self):
return self.name class Author(models.Model):
name = models.CharField(max_length=30)
sex = models.CharField(max_length=20)
def __str__(self):
return self.name class Book(models.Model):
title = models.CharField(max_length=64)
price = models.IntegerField()
color = models.CharField(max_length=64)
page_num = models.IntegerField(null=True)
publisher = models.ForeignKey("Publish",on_delete=models.CASCADE,null=True) #一对多的关系。2.0django中,当有主外键和其他对应关系时,需要设置。
author = models.ManyToManyField("Author")
def __str__(self):
return self.title
创建类
二、生成数据表
创建类的代码已经,写好,此时需要两句代码将类转换成对应的数据表:
python manage.py makemigrations #将类转换成数据表结构 python manage.py migrate #根据上一句代码生成数据表
生成数据表
上面两句代码先后执行,不出意外,就会在数据库里面生成对应的数据表。其中,第一句执行完,会在app应用下的migrations的文件夹下生成操作的记录文件“0001_initial.py”:
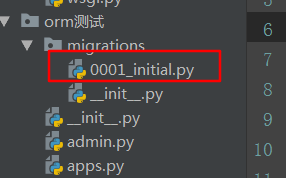
这个是记录models里面改动的执行记录。
最终生成的数据表如下:
三、给表插入数据
现在生成的数据表只是一个空表,接下的工作就是要给表插入数据。
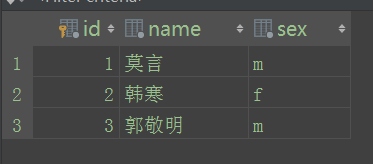
给表Author插入数据,这个表有两个字段:
from orm测试.models import Author #引入app下models模块下的Author类 a=Author.objects() #创建对象 a.create(name="莫言”,sex="m") #下面三句是分别插入数据
a.create(name="韩寒”,sex="f")
a.create(name="郭敬明”,sex="m") #以上是插入数据的一种方法,还有一种方法时save,这种方法没有create方法效率高。
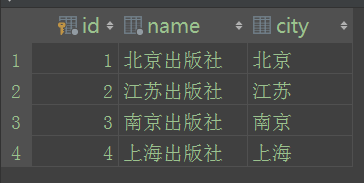
接下来给表Publish插入数据,注意这个表和Book这个表存在主外键关系。
from orm测试.models import Publish #导入表Publish p=Publish.objects p.create(name="北京出版社", city="北京")
p.create(name="江苏出版社", city="江苏")
p.create(name="南京出版社", city="南京")
p.create(name="上海出版社", city="上海")
给表Book插入数据,因为里面字段publisher和表Author存在主外键关系,插入时这个字段的值为Author表的ID(也可以指定其他字段,默认时ID最好)。
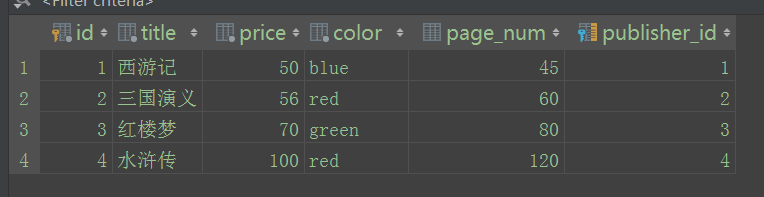
from orm测试.models import Book b=Book.objects() b.create(title="西游记", price=50, color="blue" , page_num=45, publisher_id=1)
b.create(title="三国演义", price=56, color="red" , page_num=60, publisher_id=2)
b.create(title="红楼梦", price=70, color="green" , page_num=80, publisher_id=3)
b.create(title="水浒传", price=100, color="red" , page_num=120, publisher_id=4) #最后一个字段,在models类中,定义的是publisher,但是在最终生成表时,Django自动会加上"_id",因为这个字段时一个存在主外键的字段。
表Book的字段publisher插入数据还有一种情况,就是不通过赋值id,直接把表publish中某一个对象赋给类属性publisher。下面是具体操作。
#给表Book的字段publsiher插入外键的另一种方式,直接给字段publisher赋值,这个值就是#表Publish的某一个对象。 p=Publish.objects.filter(id=3)[0] #拿到一个具体的对象 b.filter(id=4).update(publisher=p) #将这个对象赋给类属性publisher
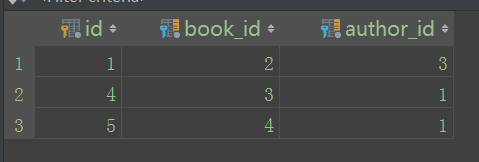
还有最后一个表需要插入数据,这个表就是表书籍和表出版社因为多对多关系生成的一张表,这个表也可以自己创建,这里用了自动生成的那种方式。Django把这个表取名为“book_author”。
#多对多的这种关系,思路就是分别取两个表的对象,把其中的一个对象加入到另一个对象中,#实现两个表的多对多的关系,用到的方法也只有一个"add()"。如果移除,用到remove()方#法。 方法一:
---正向查询。在表Book中,字段“author”是定义多对多的关系的关键,所以在下面建立的关系的时候,对象可以可以直接引用这个属性,所以为正向查询。 book = models.Book.objects.filter(id=2)[0] #拿到id=2这个数据行的书对象
authors = models.Author.objects.filter(id_gt=2) #拿到id大于2的所有集合
book.author.add(*authors) #这句就是建立两个表的关系
#book.author.remove(*authors) #取消两个表的关系 方法二:
---反向查询。因为在表Author中,没有定义与表Book相关的字段,使用_set方法。
author = models.objects.filter(id=3)[0]
books = models.Book.filter(id_gt=2)
author.book_set.add(*books)
#author.book_set.remove(*books)
到这里,一个完整的创建数据表,并给数据表添加数据的过程就完成了,过程中其实还有许多细节需要说明,这个在后面的学习中再慢慢补充。
Django之model模块创建表完整过程的更多相关文章
- Django的model中创建表
类中的class Meta字段的作用: 第一个作用可以给这个类起名字 在后台的admin中显示这个类名字 class CourseCategory(models.Model): "" ...
- MySQL数据库 存储引擎,创建表完整的语法,字段类型,约束条件
1.存储引擎 - 存储引擎是用于根据不同的机制处理不同的数据. - 查看mysql中所有引擎: - show engines; - myisam: 5.5以前老的版本使用的存储引擎 - blackho ...
- 误删Django的model中的表解决办法
误删Django的model中的表解决办法 1.model里面的表格实际的操作都在migrations文件夹中,里面记录了操作过程,当在database和model中删除表格时要注意初始化数据库时会报 ...
- postgres创建表的过程以及部分源码分析
背景:修改pg内核,在创建表时,表名不能和当前的用户名同名. 首先我们知道DefineRelation此函数是最终创建表结构的函数,最主要的参数是CreateStmt这个结构,该结构如下 typede ...
- Django之model.form创建select标签
前言 之前我们学习了form表单验证用户输入格式和自动创建HTML,那么如果用户创建select标签时怎么办呢,先来看下这个东西: models.py 数据格式: class UserInfo(mod ...
- mysql用sql创建表完整实例
create table user_login_latest( id int(11) unsigned NOT NULL AUTO_INCREMENT, user_id int(11) not nul ...
- django使用model创建数据库表使用的字段
Django通过model层不可以创建数据库,但可以创建数据库表,以下是创建表的字段以及表字段的参数.一.字段1.models.AutoField 自增列= int(11) 如果没有的话,默认会生成一 ...
- django之models模块使用
定义模型 将数据库表定义成类,集成models.Model from django.db import models # Create your models here. class Author(m ...
- Django之Model (ORM)
传统操作数据库 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去调用数据访问层 ...
随机推荐
- js学习笔记----JavaScript中DOM扩展的那些事
什么都不说,先上总结的图~ Selectors API(选择符API) querySelector()方法 接收一个css选择符,返回与该模式匹配的第一个元素,如果没有找到匹配的元素,返回null ...
- fidder显示 请求响应时间
在顶部的工具栏找到 Rules->CustomRules,第一次打开会弹出提示要安装Fiddler Script 工具,选择 [否], 就会打开 CustomRules.js 文件. 在 cla ...
- docker的安装与启动
安装docker Docker官方建议在Ubuntu中安装,因为Docker是基于Ubuntu发布的,而且一般Docker出现的问题Ubuntu是最先更新或者打补丁的.在很多版本的CentOS中是不支 ...
- OpenStack 单元测试
OpenStack 单元测试 OpenStack开发——单元测试 本文将介绍OpenStack单元测试的部分.本文将重点讲述Python和OpenStack中的单元测试的生态环境. openstack ...
- 与LINQ有关的语言特性
在说LINQ之前必须先说说几个重要的C#语言特性 一:与LINQ有关的语言特性 1.隐式类型 (1)源起 在隐式类型出现之前, 我们在声明一个变量的时候, 总是要为一个变量指定他的类型 甚至在fore ...
- 在centos上使用yum安装rabbitmq-server
rabbitmq及其依赖环境 rabbitmq安装之前需要安装socat,否则直接安装rabbitmq可能会报错 如果没有找到,则先安装epel源 yum -y install epel-releas ...
- MyBatis 分页之拦截器实现
分页是WEB程序中常见的功能,mybatis分页实现与hibernate不同,相比hibernate,mybatis实现分页更为麻烦.mybatis实现分页需要自己编写(非逻辑分页RowBounds) ...
- AD预测论文研读系列2
EARLY PREDICTION OF ALZHEIMER'S DISEASE DEMENTIA BASED ON BASELINE HIPPOCAMPAL MRI AND 1-YEAR FOLLOW ...
- Jenkins持续集成学习-Windows环境进行.Net开发1
目录 Jenkins持续集成学习-Windows环境进行.Net开发 目录 前言 目标 使用Jenkins 安装 添加.net环境配置 部署 结语 参考文档 Jenkins持续集成学习-Windows ...
- C# DataGrid 用法---极速入门测试
目标: 新手编程,只求DataGrid能运行起来,更多功能留在后面探讨. 步骤: 1.新建WPF文档 插入DataGrid控件. <Window x:Class="OASevl.Mai ...