AWK编程
1、awk的概述
文本处理工具,由于功能的强大,也可以当做是一种数据操作语言,非常适合结构化数据的处理和格式化报表的生成,awk可以进行样式装入、流控制、数学运算符、甚至于内置的变量和函数。它具备了一个完整的语言所应具有的几乎所有精美特性。
为什么叫awk?
三个人(Alfred Aho、 Peter Weinberger 、Brian Kernighan。)一起创造了这款工具,awk分别是他们名字的缩写
从网上找到以下数据提供练习:包含名字,电话号码和过去三个月(1月份、2月份、3月份)里的捐款,文件名称命名为data.txt
|
Mike Harrington:[510] 548-1278:250:100:175 Christian Dobbins:[408] 538-2358:155:90:201 Susan Dalsass:[206] 654-6279:250:60:50 Archie McNichol:[206] 548-1348:250:100:175 Jody Savage:[206] 548-1278:15:188:150 Guy Quigley:[916] 343-6410:250:100:175 Dan Savage:[406] 298-7744:450:300:275 Nancy McNeil:[206] 548-1278:250:80:75 John Goldenrod:[916] 348-4278:250:100:175 Chet Main:[510] 548-5258:50:95:135 |
1.1、一些名词定义
- 数据行(Record) : awk从数据文件上读取数据的基本单位,一次读取一行数据
- 字段(Field) : 数据行上被分隔开的子字符串
1.2、内置变量
| 变量 | 描述 |
| $0 | 一字符串, 其内容为目前 awk 所读入的数据行 |
| $n | $1为$0上第一个字段的数据,$2为$0 上第二个字段的数据 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS |
字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 同NR,但相对于当前文件 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 当前记录中的字段数 |
| NR | 当前记录数 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符(默认值是一个空格) |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是\034) |
2、AWK语法
基本语法:awk -[vFf] Pattern { Action }
-[vFf]为参数;Pattern 为模式;Action 为操作
2.1、awk工作流程
- 自动从指定的数据文件中读取一个数据行.
- 自动更新(Update)相关的内建变量之值. 如 : NF, NR, $0...
- 依次执行程序中 所有 的 Pattern { Actions } 指令.
- 当执行完程序中所有 Pattern { Actions } 时, 若数据文件中还有未读取的数据, 则反复执行步骤1到步骤3
两者是可选的,如果没有模式,则action应用到全部记录,如果没有action,则输出匹配全部记录。默认情况下,每一个输入行都是一条记录,但用户可通过RS变量指定不同的分隔符进行分隔。
2.2、参数
- -v 定义变量,例如:awk -v a=test '{print a}' data.txt
如果有两个变量,在后面再加多一个-v参数再赋予一个变量值
- -F 分隔符 awk -F: '{print $1}' data.txt
- -f 指定awk脚本
2.3、模式
- 关系表达式 :使用像 " A 关系运算符 B" 的表达式当成 Pattern
| 运算符 | 描述 |
| = += -= *= /= %= ^= **= | 赋值,注:=是赋值,==是判断符,即关系运算符 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ ~! | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加减 |
| * / & | 乘除与求余 |
| + - ! | 一元加减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
- 正则表达式 : 在两个斜杠中(//)使用正则表达式
- 模式的组合
- BEGIN 和 END 模式
2.4、操作
操作由一人或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内。主要有四部份:
- 变量或数组赋值
- 输出命令:print或者printf命令
- 内置函数
- 控制流命令
3、正则表达式
在两个斜杠中(//)使用正则表达式
写法如下:
awk -F: '$1 ~/^Mike/{print $0}' data.txt
4、模式的组合
模式:指定一个行的范围。
/begin/,/end/
包含字符串 begin (第一次出现)的数据行以及和包含字符串 end (第一次出现)之间的所有记录(包含包括字符串 end 的记录)匹配。
例如:打印出Mike和Dan之间的的信息
awk -F: '/^Mike/,/^Dan/{print NR,$0}' data.txt

5、BEGIN和END模式
5.1 BEGIN
BEGIN模块后紧跟着动作块,这个动作块在awk处理任何输入文件之前执行。所以它可以在没有任何输入的情况下进行测试。它通常用来改变内建变量的值,如OFS,RS和FS等,以及打印标题
例如:输出每个人第一个月的捐款,冒号分隔符
awk 'BEGIN{FS=":"}{print $1":"$3}' data.txt
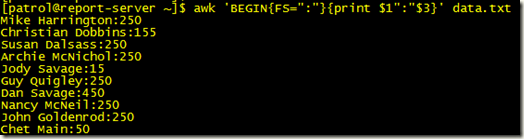
这里使用BEGIN在处理这个字符之前改变内建变量FS,如果要改变多个内置变量,使用”;”分隔符
例如:输出每个人第一个月的捐款,冒号分隔符,
awk 'BEGIN{FS=":";OFS=":"}{print $1":"$3}' data.txt
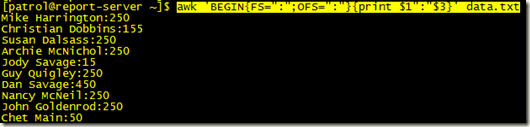
FS:字段分隔符(默认空格)
OFS:输出字段分隔符(默认空格)
5.2 END
END不匹配任何的输入文件,但是执行动作块中的所有动作,它在整个输入文件处理完成后被执行。
重点理解在”在整个输入文件处理完成后被执行“这句话,也即是在处理完后才处理动作快中的动作,没有加这个END的时候,在处理完每一条记录,都会执行action中的动作,加了END后,只有处理完后才执行action中的动作。
做个对比:
|
awk -F":" '{print "number is:"NR}' data.txt
|
awk -F":" 'END{print "number is:"NR}' data.txt
执行完最后一行才输出,此时NR变量是10 |


6、条件语句(控制流命令)
6.1 if语句
语法:
{if (expression){
statement; statement; ...
}
}
例如:
awk '{if(100>50){print "A>B"}}' data.txt
6.2 if/else语句
{if (expression){
statement; statement; ...
}
else{
statement; statement; ...
}
}
例如:
awk '{if(100>150){print "A>B"}else{print "B<A"}}' data.txt
6.3 if/else else if语句
{if (expression){
statement; statement; ...
}
else if (expression){
statement; statement; ...
}
else if (expression){
statement; statement; ...
}
else {
statement; statement; ...
}
}
6.4 while循环
例如,输出第一行每个字段的值
awk 'NR==1{print $0}' data.txt |awk -F: '{i=1;while(i<=NF){print i,$i;i++}}'

6.5 for循环
例如,输出第一行每个字段的值
awk 'NR==1{print $0}' data.txt |awk -F: '{for(i=1;i<=NF;i++){print i,$i}}'

break与continue语句
break用于在满足条件的情况下跳出循环;continue用于在满足条件的情况下忽略后面的action语句,继续往下循环
测试数据源data2.txt:
| 100 200 -100 300 -200 |
例如:只输出第一个负数值
awk '{for(i=1;i<=NF;i++)if($i<0){print $i;break}}' data2.txt
7、printf函数
printf是一个格式化的函数,使得输出的格式更美观、整齐,先来看一个用法
awk -F[:] '{printf("%-19s,%-20s,%-5d,%-5d,%-5d\n",$1,$2,$3,$4,$5)}' data.txt

语法如下:
printf("格式化字符串",参量表 )
参量表是需要输出的一系列参数, 其个数必须与格式化字符串所说明的输出参数个数一样多, 各参数之间用","分开, 且顺序一一对应, 否则将会出现意想不到的错误。
例如上面:awk -F[:] '{printf("%-19s,%-20s,%-5d,%-5d,%-5d\n",$1,$2,$3,$4,$5)}' data.txt
这里对5个字段做了格式化,参量表就必须有5个参数,就是这里的$1,$2,$3,$4,$5
格式化字符串又分为如下的修饰符和格式说明符
7.1 修饰符
| 字符 | 定义 |
| - | 左对齐修饰符,常用 |
| # |
显示8 进制整数时在前面加个0 |
| + | 显示使用d 、e 、f 和g 转换的整数时,加上正负号+或- |
| 0 | 用0而不是空白符来填充所显示的值 |
7.2 格式说明符
| 格式说明符 | 功能 |
| %d | 十进制有符号整数 |
| %u | 十进制无符号整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %c | 单个字符 |
| %p | 指针的值 |
| %e | 指数形式的浮点数 |
| %x | %X 无符号以十六进制表示的整数 |
| %0 | 无符号以八进制表示的整数 |
| %g | 自动选择合适的表示法 |
| \n | 换行 |
| \f | 清屏并换页 |
| \r | 回车 |
| \t | Tab符 |
| \xhh | 表示一个ASCII码用16进表示,其中hh是1到2个16进制数 |
说明:
(1). 可以在"%"和字母之间插进数字表示最大场宽。
例如:
- %3d 表示输出3位整型数, 不够3位右对齐。
- %9.2f 表示输出场宽为9的浮点数, 其中小数位为2, 整数位为6,小数点占一位, 不够9位右对齐。
- %8s 表示输出8个字符的字符串, 不够8个字符右对齐。
如果字符串的长度、或整型数位数超过说明的场宽, 将按其实际长度输出.但对浮点数, 若整数部分位数超过了说明的整数位宽度, 将按实际整数位输出;若小数部分位数超过了说明的小数位宽度, 则按说明的宽度以四舍五入输出.
(2).另外, 若想在输出值前加一些0, 就应在场宽项前加个0。
例如: %04d 表示在输出一个小于4位的数值时, 将在前面补0使其总宽度为4位。
如果用浮点数表示字符或整型量的输出格式, 小数点后的数字代表最大宽度,小数点前的数字代表最小宽度。
例如: %6.9s 表示显示一个长度不小于6且不大于9的字符串。若大于9, 则第9个字符以后的内容将被删除。
(3). 可以在"%"和字母之间加小写字母l, 表示输出的是长型数。
例如: %ld 表示输出long整数
%lf 表示输出double浮点数
(4). 可以控制输出左对齐或右对齐, 即在"%"和字母之间加入一个"-" 号可说明输出为左对齐, 否则为右对齐。
例如: %-7d 表示输出7位整数左对齐
%-10s 表示输出10个字符左对齐
8、数组
用变量作为数组下标,数组name中的下标是一个自定义变量x,awk初始化x的值为0,在每次使用后增加1。第二个域的值被赋给name数组的各个元素。在END模块中,for循环被用于循环整个数组,从下标为0的元素开始,打印那些存储在数组中的值。因为下标是关健字,所以它不一定从0开始,可以从任何值开始。
awk 'BEGIN{FS=":"}{name[x++]=$1}END{for(i=0;i<NR;i++)print i,name[i]}' data.txt

把$1的值分别赋给name[0],name[1],name[2]·········
上面每行一次输出的是name[0],name[1]····
延伸:这里x的初始值是0,可以更改这个初始值吗,可以的,如下,设置x的初始值为2
awk 'BEGIN{FS=":";x=2}{name[x++]=$1":"$3}END{print name[2]}' data.txt

8.1 关于数组的几道题
数据data1.txt:第一个字段为姓名,第二、三、四字段为课程
|
xiaoming Chinese English Mathematics |
题目:求出参加Chinese English Mathematics课程的修课人数
awk '{for(i=2;i<=NF;i++)num[$i]++}END{for(course in num)printf("%-10s %d\n",course,num[course])}' data1.txt

9、内置函数
9.1 sub(reg,string,target)
将原字串中第一个(最左边)合乎所指定的正则表达式的子字串改以新字串取代. 第二个参数"将替換的新字串"中可用"&"来代表"合於条件的子字串"
例如:把Dan字符替换成aaaaa字符
awk '{sub(/Dan/,"aaaaa",$0);print $0}' data.txt
9.2 gsub(reg,string,target)
这个函数与 sub()一样,同样是进行字串取代的函数. 唯一不同点 gsub()会取代所有合条件的子字串. gsub()会返回被取代的子字串个数
9.3 length(string)
返回该字串的长度
例如:
awk -F: '{print length($1)}' data.txt
9.4 substr函数
返回从位置1开始的子字符串,如果指定长度超过实际长度,就返回整个字符串。格式如下
返回字段1的第一个字符到第三个字符,如果超过字段1的实际长度,返回整个字段1
awk -F: '{ print substr( $1, 1,3 )}' data.txt
9.5 toupper和tolower函数
toupper和tolower函数可用于字符串大小间的转换,该功能只在gawk中有效
awk -F: '{ print toupper($1), tolower($1) }' data.txt
9.6 split(string,store,delim)
awk将依所指定的分隔字符(field separator)来分隔原字串成一个个的栏位(field),并以指定的数组(下标从1开始)记录各个被分隔的栏位.
例如:以:号为分隔符,对$2进行分割,并存到name[]数组中
awk -F: '{split($2,name," "); print name[1] }' data.txt

10、awk练习题
10.1 复习
- 输出文本,在文本前面输出文本所在的数据行
- 打印Mike和Dan的电话号码
- 打印出文本中Dan往下全部人的信息
- 显示Mike的捐款,每个值前面加上$符号
- 分别显示每个人这个季度捐款总额
- 显示全部人的捐款总额
- 统计某个文件夹下的文件占用的字节数
参考答案:
- awk '{print NR,$0}' data.txt
- awk -F: '$1 ~/^Mike/||$1 ~/^Dan/{print NR,$0}' data.txt
- awk 'BEGIN{a=1000000000000}{if($1 ~/^Dan/){a=NR;print NR,$0}else if(NR>=a){print NR,$0}}' data.txt
- awk -F: '$1 ~/^Mike/{print $1,"$"$3,"$"$4,$5}' data.txt
- awk -F: 'sum=$3+$4+5{print $1,sum}' data.txt
- awk -F: 'sum=$3+$4+$5{total=total+sum}END{print total}' data.txt
- ls -al |awk '$1 ~/^-/{total=total+$5}END{print total}'
10.2 打印出使用率大于60的文件系统
文本数据:
|
Filesystem Size Used Available Capacity Mounted on |
10.3 制作一张报表
- 制作报表:显示每个人1、2、3月份的捐款
- 在第一行加上报头
参考答案:
- awk -F: '{printf("%-20s 1月份捐款:%-5d 2月份捐款:%-5d 3月份捐款:%-5d\n"),$1,$3,$4,$5}' data.txt
- awk 'BEGIN{FS=":";printf("%-20s %-10s %-10s %-5s\n"),"姓名","1月份捐款","2月份捐款","3月份捐款"}{printf("%-20s %-10d %-10d %-5d\n"),$1,$3,$4,$5}' data.txt
AWK编程的更多相关文章
- 第4章 awk编程
1 awk编程模型 2 awk用法 调用awk有三种方法(与sed类似): 在Shell命令行输入命令调用awk,格式为: awk [-F 域分隔符] 'awk程序段' 输入文件 将awk ...
- shell编程练习-打印九九乘法表(附:awk编程)
小练习,仅供参考 shell编写 #!/bin/bash for i in {1..9}do for j in {1..9} do if [ $j -le $i ] ;then echo -ne &q ...
- awk编程基础
一.awk介绍 awk(名字来源于三个创始人姓氏首字母)是linux系统下文本编辑工具,是一门编程语言,有自己的基本语法和流程控制.函数.awk简单高效. 二.awk的运行方法 例子:使用冒号:分 ...
- awk编程的基本用法
awk也是用来处理文本的,awk语言可以从文件或字符串中基于指定规则浏览和抽取信息,可以实现数据查找.抽取文件中的数据.创建管道流命令等功能. awk模式匹配 第一种方法打印空白行将空白行打印出来,并 ...
- 『忘了再学』Shell基础 — 27、AWK编程的介绍和基本使用
目录 1.AWK介绍 (1)AWK概述 (2)printf格式化输出 (3)printf命令说明 2.AWK的基本使用 (1)AWK命令说明 (2)AWK命令使用 1.AWK介绍 (1)AWK概述 A ...
- Linux Shell编程第4章——sed和awk
目录 sed命令基本用法 sed命令实例 命令选项 文本定位 编辑命令 awk编程模型 awk编程实例 1.awk模式匹配 2.记录和域 3.关系和布尔运算符 4.表达式 5.系统变量 6.格式化输出 ...
- Linux Shell编程 awk命令
概述 awk是一种编程语言,用于在linux/unix下对文本和数据进行处理.数据可以来自标准输入(stdin).一个或多个文件,或其它命令的输出.它支持用户自定义函数和动态正则表达式等先进功能,是l ...
- awk命令简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各 ...
- 【Linux】AWK入门
什么是AWK AWK是一种用于处理文本的编程语言工具,一个模式匹配程序.一个典型的示例是将数据转换成格式化的报告. 在命令行输入如下awk命令: awk -F":" '{ prin ...
随机推荐
- .NET Core+NLog+存储配置 日志存入到数据库
nlog-config.xml 配置文件: <?xml version="1.0" encoding="utf-8" ?> <nlog xml ...
- 性能测试工具--SIEGE安装及使用简介 siege压力测试
官方网站http://www.joedog.org/ 概述 Siege是一个多线程http负载测试和基准测试工具.它有3种操作模式: 1) Regression (when invoked by bo ...
- Linux下用gSOAP开发Web Service服务端和客户端程序
网上本有一篇流传甚广的C版本的,我参考来实现,发现有不少问题,现在根据自己的开发经验将其修改,使用无误:另外,补充同样功能的C++版本,我想这个应该更有用,因为能用C++,当然好过受限于C. 1.gS ...
- top-N 抽样
1, 使用hive标记random:(如果是mr,就自己标记random值) use ps; set mapred.job.priority=VERY_HIGH; set mapred.job ...
- MySQL 批量写入数据报错:mysql_query:Lost connection to MySQL server during query
场景: 批量往mysql replace写入数据时,报错. 解决方法: 1.增大mysql 数据库配置中 max_allowed_packet 的值 max_allowed_packet = 1G ( ...
- 新内容转入github
所有新内容已经转入 https://github.com/honggzb/Study-General https://github.com/honggzb/Study2016
- go对json对象的生成和解析
https://blog.csdn.net/benben_2015/article/details/78917374
- 【QT】QPixmap在Label中自适应大小铺满
KeepAspectRatio:设置pixmap缩放的尺寸保持宽高比. setScaledContents:设置label的属性scaledContents,这个属性的作用是允许(禁止)label缩放 ...
- JAVA ftp连接池功能实现
抽象类: package com.echo.store; import java.util.Enumeration; import java.util.Hashtable; abstract clas ...
- sanchi
修炼之路阶段1能简单处理html+css+js前端页面,可实现管理后台前端页面 熟练安装php的web运行环境,并调整配置,会自行安装php扩展 熟练数据库操作,清楚为何使用pdo而不使用mysql等 ...