目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik
该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当时性能最好的算法高30%。算法主要结合了两个key insights:
(1)可以将高容量的卷积神经网络应用到自底向上的Region proposals(候选区域)上,以定位和分割目标
(2)当带标签的训练数据稀少时,可以先使用辅助数据集进行有监督的预训练,然后再使用训练集对网络的特定范围进行微调,这样可以显著提升性能
该算法之所以被称为R-CNN,是因为结合了region proposal和CNNs,下图为目标检测系统的概述:
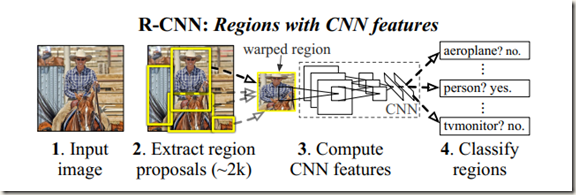
论文研究的是如何将CNN在ImageNet数据集上的分类(Classification)模型应用到PASCAL VOC数据集上的目标检测(Object Detection)任务中。
为此,论文首先说明了CNN可以将PASCAL VOC数据集上的目标检测性能大幅提升,并提供了方案。这主要是因为作者解决了两个问题:
- 深度网络的目标定位问题。不同于图像分类,目标检测需要在图像内定位目标。比较普通的是方法是框定位置并进行回归,可是事实证明效果并不理想。另一种选择是滑窗法。虽然CNNs使用滑窗法已经有几十年,但是通常用于有限的检测对象类别,比如人脸和行人。同时为了保证较高的空间分辨率,使用滑窗法的CNNs一般只有两个卷积池化层。而作者方案中的网络有高达5个卷积层,并且网络高层在输入图像上有非常大的感受野(195*195 pixels)和步长(strides,32*32),如果采用滑窗法的话会给精确定位带来挑战。 作者最终采用了‘recognition using region’的方法来解决CNN定位问题,资料表明,该方法在目标检测和语义分割上都有成功应用。具体过程是:先从一幅输入图像中提取大概2000个类别独立的候选区域(Region Proposals),然后再用一个CNN网络从每个候选区域(如上图所示,事先对候选区域进行了仿射图像变换,使尺寸符合CNN的输入层)中提取一个固定长度的特征向量(卷积网络作为feature extarctor),最后用指定类别的线性SVMs对特征向量进行分类。
- 带标签数据不足或目前可用的数量不足以训练一个大型CNN。 针对这个问题,传统的方法是使用无监督的预训练,然后进行有监督的微调。论文中使用的方法是:在一个大的辅助数据集上进行有监督预训练(判别式训练),然后在一个小的数据集上对指定的范围进行微调。实验证明,在数据不足时,这是一种高效的学习高容量的CNNs的方法。
后来。作者在经过分析后证明,一个简单的边界框回归(Bounding-box regression method)可以极大地提升定位的精度。同时,作者也提醒读者因为R-CNN在区域上进行操作,所以它也可以被拓展到语义分割任务中。
接下来这部分内容介绍的是用于目标检测任务中的R-CNN:
总的来说,作者实现的目标检测系统分为三部分:
- 产生类别独立的区域候选框
- 一个较大的卷积神经网络,用来从每个经过仿射图像变换的候选框中提取固定长度的特征。CNN作为一个blackbox feature extractor存在
- 若干个指定类别的线性SVMs
2.1 模型设计:
- 区域候选框:方法有objectness, selective search, category-independent object proposals, constrained parametric min-cus, multi-scale combinatorial grouping, Ciresan等,作者选择的是selective search的fast mode
- 特征提取: 作者使用Caffe中Krizhevsky描述的CNN从每个候选框中提取一个4096维的特征向量。CNN包含五个卷积层和两个全连接层。输入CNN的是减去均值的227*227 RGB图像。
另外,为了从候选框中计算出特征,需要将候选框转换成与CNN(网络结构需要输入为固定尺寸227*227)兼容的形式。在众多将任意形状的图像进行转换的方法中,作者推荐最简单的。
论文中给出了三种object proposal转换为合法CNN输入的方法:
- tightest square with context:各向同性缩放,先扩充后裁剪。先将原始object proposal使用最紧的正方形框起来,然后将正方形框各向同性缩放(origional image不变,仅方形框进行缩放)至框尺寸为227*227,最后裁剪即为所得。如果方形框在缩放的过程中超出原始图像的边界,那么就用缩放后的object proposal的均值进行填充(该均值会在传入网络时减去)。如下图中(B)所示:
- tightest square without context:各向同性缩放,先裁剪后扩充。先在原始图像中裁剪出Object proposal,然后使用object proposal的像素均值填充成正方形。如果填充后尺寸大于227*227,这时需要缩放至227*227。不同的是,该方式只用均值进行填充,而tightest square with context在没有超出原始图像边界的情况下使用原始图像的内容(context)进行填充。如下图(C)所示:
- wrap: 各向异性缩放。即变形拉伸,不固定图像长宽比,直接将图像的长宽缩放到227*227,这样的结果就是图像会扭曲变形(wrap),具体如下图(D)所示:
此外,作者还尝试在上述三种转换过程中先在原始object proposals周围pad额外的Image context,再进行转换。填充的image context 的数量被定义为原始proposals的边框宽度(border size)。比如,作者在论文中选择的填充宽度p=16,并且实验证实p=16时对mAP的提升很大。
论文中作者经过尝试最终采用wrap转换方式,且P取值为16

2.2 测试时间检测:
线性SVMs会利用CNN提取到的特征给相应的候选框打分。在给一幅图像中的所有候选框打分完成后,会对每一类单独使用贪婪非极大值抑制以筛除一个区域(如果IoU超过设定的阈值)。关于贪婪非极大值抑制可以参考这里。
- 实时性分析:论文中说有两个因素使得检测效率比较高(其实还是慢)。一是所有类上共享CNN的所有参数;二是与其他方法计算得来的特征向量相比,CNN计算的特征向量维数低
2.3 训练:
- 有监督预训练(CNN有监督预训练):作者先在辅助数据集ILSVRC2012 classification上对CNN进行分类预训练,不过仅使用图像的标注(image-level annotations),也就是说使用的是没有边界框标签的数据。预训练使用的是Caffe中的CNN库。
- 指定范围内微调(CNN有监督微调):为了使CNN适应新的任务(detection)和扭曲的候选框,论文中继续使用随机梯度下降法(SGD)在经过转换的候选框为输入的情况下训练CNN的参数。
除了将原先CNN中ImageNet指定的1000-way分类层替换为(N+1)-way分类层以外,CNN结构的其它地方并没有被改变。
注:此处与下面介绍的SVMs训练中提到的IoU阈值不同
在对CNN进行微调时,进行的必然是有监督学习,所以首先需要的就是对提取到的region proposals分类(N+1 classes)。数据集中的训练图片已经被人工标记出边界框和类别,这些人工标记的bounding-box被称为ground-truth boxes。分类根据的是提取到的候选框与ground_truth boxes的IoU值,如果>=0.5 IoU,那么该候选框被视为该ground-truth box所在类的正窗口,其余的被视为负窗口(negative windows),即判断是否属于同类。至于那些不属于任何ground-truth box的负窗口会被划分为背景窗口(background windows)。
SGD训练时,学习率初值选取为0.001,是预训练时的1/10。在迭代时,在所有类别上选择32个正窗口、96个背景窗口一共128个窗口作为一个mini-batch。将采样偏向正窗口,因为与背景相比它们非常稀少。
- 对象类别分类(SVMs训练): 同样使用IoU重叠阈值来判断候选框。低于阈值0.3的被标记为负,每个类的ground-truth boxes被定义为正例(positive examples),介于二者之间的proposals会被忽略。论文中选择的阈值是通过在验证集上进行网络搜索最终选择的。作者发现,阈值的选择很重要,过高或者过低都会使mAP降低。此处易混淆,SVMs训练使用的仍然是VOC数据集,需要使用IoU值重新对region proposals分类,再进行训练。
一旦通过CNN提取到特征并且得知训练标签,我们就开始优化每一类的linear SVM。因为训练数据太大,计算得到的特征太多,无法装入内存, 作者采用 standard hard negative mining method解决,该方法能使收敛更快。关于hard negative mining method,解释如下:
Bootstrapping methods train a model with an initial subset of negative examples, and then collect negative examples that are incorrectly classified by this initial model to form a set of hard negatives. A new model is trained with the hard negative examples, and the process may be repeated a few times.
在进行目标检测时得到的训练样本中一般正例(positive examples)较少。这样在训练时一个batch中的正负样例比例不协调,导致分类结果出现很多fasle positive examples。这时为了加强分类器的判别能力可以把这些false positive examples(Hard negative examples)放进下一轮的训练中继续训练,直到满足停止条件。
作者在 Appendix B中讨论了为何在CNN微调和SVMs训练时正负定义不同,同时也讨论了为何不直接使用微调后的CNN的softmax而是使用SVMs。大致如下:
- 在对CNN进行微调时使用的IoU交并比阈值为0.5,对于各类均低于该值的proposal被标记为back-ground,而训练SVMs时使用的阈值是0.3,低于该值则别标记为negative examples,only ground-truth boxes被标记为positive examples,落在grey zone的proposals被忽略。作者起初训练SVMs时选择与微调时相同的正负例划分阈值,但是发现效果相比之下要差很多。作者给出的猜想是:对CNN进行微调时数据有限,虽然将IoU不低于0.5的region proposals也标记为positive examples增加了大约30倍的正样本数,有效地避免了过拟合。但是,使用这些’jittered’ examples训练模型取得的结果是次优的,因为根据这些数据网络不能准确定位proposals
- 作者使用微调后CNN的softmax层进行分类时发现在VOC 2007数据集上的mAP从54.2%降到了50.9%,于是就猜想该现象是由以下几个因素造成的:在微调时对positive examples的划分没有考虑到定位的准确性;softmax classifier是使用随机选取的negative examples训练的,而不是SVM进行训练时使用的’hard negatives‘的子集
3. 可视化、ablation和误差模式
3.1 可视化学习到的特征:作者采用的可视化方法并不是反卷积法,而是提出了一种简单的无参数方法,能够直接说明网络学到的内容
具体是:先在网络中挑出一个特定的神经元并将其视为所在位置的object detector,然后我们在一个大的region proposals集合中计算该神经元的激活值(activations),接着按照激活值的高低对region proposals进行排序并运用非极大值抑制,最后显示若干个得分最高的region proposals。作者之所以采用这种可视化方法主要是因为传入CNN的是region proposals,而不是一般CNN那样传入整幅图像。region proposals已经对图像中的目标进行了分割,包含的特征种类也不多。下图为论文中提供的图,展示的是得分最高的前16个region proposals:

3.2 Ablation studies
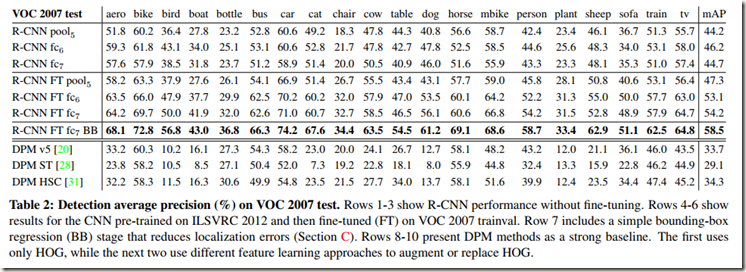
- Performance layer-by-layer, without fine-tuning 进行判别式预训练后,尚未进行微调,对CNN全连接层逐层测试
为了确定预训练后的CNN网络的哪一层对检测的性能影响最大,作者在VOC 2007数据集上对CNN最后三层的测试结果进行了分析。结果见Table 2中的rows 1-3。
实验发现CNN的表征能力大部分来自于卷积层,而不是来自于大得多的紧密连接层(Densely connected layer)。因此,仅使用CNN的卷积层,就可以计算任意大小图像的dense feature map.
RCNN结构中,CNN作为featrue extractor存在,SVMs作为分类器对提取到的特征进行分类。在一般的网络结构中也是如此,卷积层部分作为特征提取器,后面的全连接层等部分作为分类器对特征进行分类。
- Performance layer-by-layer, with fine-tuning 进行判别式预训练后,对进行微调CNN,对比微调前后网络的性能差异
比较发现,微调后CNN的性能提升显著,如Table 2中rows 4-6所示。微调给fc6,fc7层带来的提升比pool5大,说明pool5层从ImageNet学习到的特征更具有代表性,对网络更有益。
- Comparison to recent feature learning methods 与最近的特征学习方法比较
作者将CNN与当时最近的其他特征提取方法进行对比,发现CNN都完胜、
3.3 网络结构
该论文使用的网络结构来自于Alex Krizhevsky的文章《ImageNet Classification with Deep Convolutional Neural Networks》(2012)。作者也发现CNN网络结构的选择对R-CNN的性能影响很大。在下面的Table 3中,作者就使用了另外一种深度网络(O-Net)进行了对比测试,效果见下表:

后面作者也指出,虽然更换CNN网络后R-CNN的性能得到大幅提升,不过随之而来的缺点是计算耗时太长。以表中的O-Net为例,它的前向传播时间大概比T-Net长7倍。
3.4 边界框回归(Bounding-box regression)
基于误差分析,作者使用了一种简单的方法来降低定位误差。受到DPM中bounding-box regression的启发,论文根据pool5输出的特征和对应的region proposal训练一个线性回归来预测一个新的detection window。
5. Semantic segmentation
后面语义分割部分先不介绍,日后学习时再做补充。
下面是部分补充:
- selective search: 可以参考论文《Selective Search for Object Recognition》 J. R. R. Uijlings , K. E. A. van de Sande , T. Gevers , A. W. M. Smeulders
简单说就是先把一幅图片分成很多小区域,然后通过计算小区域间的颜色相似度、纹理相似度、大小相似度和吻合相似度,最后综合四个相似度进行合并,合并的结果就是selective search的结果,算法如下:


- Hard negative mining method
目标检测中会事先标记出ground-truth box,然后利用算法生成一系列region proposal,接着会根据ground-truth box和region proposals的重合度(IOU)对region proposals的正负进行判断,最后放进网络中训练。但是由于正样本的数量远远小于负样本,使得训练出来的分类器的效果比较差,会出现许多false positive examples。这时可以把得分较高的false positive examples当做所谓的Hard negative examples,然后把这些Hard negative examples放进网络再训练一次,从而加强分类器的判别能力.
具体参见论文:《Object Detection with Discriminatively Trained Part Based Models》
- R-CNN的显著缺点:
Training is a multi-stage pipeline 训练分为多个阶段:首先使用log loss在object proposals上对一个卷积网络进行微调。然后,利用ConvNet输出的feature训练SVMs。取代softmax classifier的SVMs相当于目标检测器(object detectors)。第三步是学习bounding-box regression
Training is expensive in space and time 训练耗时且需要很大的存储空间: 在SVMs和bounding-box regressor训练时,需要从每幅图像的每个object proposal提取特征并将提取到的特征写入硬盘。当使用的卷积网络很深时,训练会非常耗时,保存特征也会消耗巨大的存储空间
Object detection is slow 目标检测的速率非常慢:这是因为每个object proposal在经过卷积神经网络时都要计算一遍,没有共享计算
- https://www.sohu.com/a/130299172_680233
目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)的更多相关文章
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解
论文地址:https://arxiv.org/pdf/1311.2524.pdf 翻译请移步: https://www.cnblogs.com/xiaotongtt/p/6691103.html ht ...
- Rich feature hierarchies for accurate object detection and semantic segmentation(理解)
0 - 背景 该论文是2014年CVPR的经典论文,其提出的模型称为R-CNN(Regions with Convolutional Neural Network Features),曾经是物体检测领 ...
随机推荐
- Mac NVM 配置
1.NVM 简介 NVM(node version manager)是一个可以让你在同一台机器上安装和切换不同版本 node 的工具. GitHub 地址 2.NVM 环境配置 2.1 安装 NVM ...
- HDU 5095--Linearization of the kernel functions in SVM【模拟】
Linearization of the kernel functions in SVM Time Limit: 2000/1000 MS (Java/Others) Memory Limit: ...
- linux通用技巧集合
1.将程序置为后台进程运行,关闭终端程序继续运行 nohup ./test.sh & 2.列出当前后台运行的进程列表包括进程id jobs -l 3.根据进程id杀掉该进程 kill - pi ...
- python3 使用ldap3来作为django认证后台
首先先使用ldap3测试ldap服务是否正常 我们先要拿到dc的数据,以及连接ldap的密码,还有搜索的字段(search_filter), 一般来说search_filter 这个是从负责ldap运 ...
- 目前我对ReactNative的了解
1.什么是React? 一个js组件库,不同于angular的是一个完整的framework,React需要像jQuery一样写事件监听逻辑,最大特点是Virtual DOM. 官网:https:// ...
- java如何对List集合中的元素进行排序(请收藏)
在java开发中有时候我们需要对List集合中的元素按照一定的规则进行排序,比如说有个Person的集合,我们要根据Person的age属性进行排序输出,这就需要用到Java中提供的对集合进行操作的工 ...
- fiddler 使用记录
fiddler 工作原理 Fiddler 启动后将自己变成一个代理服务器,这个代理服务器默认监听 127.0.0.1:8888. Filddler 启动后浏览器的代理会被自动更改为 127.0.0.1 ...
- appium定位h5
1.手机安装Chrome浏览器 2.开启USB调试模式,并使用安装的Chrome浏览器打开待测H5页面 3.在电脑端的Chrome浏览器输入chrome://inspect ...
- iOS - 解决 Cocoapods 第三方库下载不下来
Cocoapods 第三方库下载不下来问题:一些第三方的库由于网的原因下载不下里 (解决思路:(原理) cocoapods 下载的时候 会先从缓存中拿 缓存中没有再去下载 所以可以把下载不下来的放到缓 ...
- 【Python】安装error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools"
pip install Scrapy --> error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft ...