Hibernate学习(四)———— 双向多对多映射关系
一、小疑问的解答
问题一:到这里,有很多学习者会感到困惑,因为他不知道使用hibernate是不是需要自己去创建表,还是hibernate全自动,如果需要自己创建表,那么主外键这种设置也是自己设置吗?这让人感到很困惑,现在就来解决一下这个小疑问(如果知道了的可以直接跳过看下面的多对多映射关系讲解)
解答:从实际开发的角度说:肯定是先创建表,并且表中自己会导入初始数据,然后在逆向生成实体类,并且各种映射关系看自己需要什么就生成什么。
在我们测试和学习阶段也可以如此,先创建好数据库和表还有一些初始化数据,也可以不用把数据库中各种表关系和表字段创建好,只需要将数据库手动建好,也就是说数据库中有没有表度没关系,关键是必须得有这个数据库。如果没有表,那么我们就得通过代码来创建表,比如new一个实体类,就相当于创建了一张表,如果没有表的情况下,你就直接去查询,那么肯定会报不存在表的错误,然后每个表中的字段和表之间的外键关系,度可以通过hibernate来帮我们完成,我们编写映射文件和实体类,就是来创建表之间的关系和表中的内容的。这取决于一个配置属性。
<prop key="hibernate.hbm2ddl.auto">value</prop>
value值可以为四种
create:表示启动的时候先drop,再create。 也就是说每次启动,会先将数据库中表给删除,然后在创建一个。开发人员测试用的比较多
create-drop: 也表示创建,只不过再系统关闭前执行一下drop。 每次关闭前就将表给删除掉,等用的时候在创建
update: 这个操作启动的时候会去检查schema是否一致,如果不一致会做scheme更新。就是检查hibernate中和数据库表中字段关系是否一致,不一致就会更新数据库
validate: 启动时验证现有schema与你配置的hibernate是否一致,如果不一致就抛出异常,并不做更新。
总结:只要我们数据库中存在表,我们就可以对他进行操作(改造表中字段,通过外键联合其他表等度可以独立完成),而不需要我们在去手动操作底层数据库。所以在大多数书上就是直接上操作hibernate的代码,而不关心数据库怎么样,他们的前提是数据库中有他们所操作的表就够了。
问题二:在xxx.hbm.xml中的主键生成策略,是否需要让数据库底层主键自动生成,这个需要搞清楚,不能够混淆。当你纠结主键生成策略与数据库主键到底该不该用AUTO_INCREMENT时,那你就需要去总结一下这两者的关系了。(我是个大好人TMD,帮你们总结一份)
<id name="id" column="id">
<!-- 主键生成策略 -->
<generator class="increment"></generator>
</id>
主键生成策略常用就六种,
1、increment:hibernate管理,自动让主键自动增长,而数据库中主键就可以不用在设置AUTO_INCREMENT了。
2、identity:底层数据库管理,也就是说数据库需要自己设置主键自动增长(AUTO_INCREMENT),不设置的话,就需要自己手动设置,不太好。
Mysql和sql server支持这个,但是Oracle不支持,也就是说Orable不支持底层自动增长,但是Oracle有另一种底层机制,那就是sequence
3、sequence:底层数据库管理,数据库自己来提供这个主键是多少,具体如何算我们不了解
Oracle就使用这个,Mysql就不支持这个,但mysql支持identity,也就是让数据库自动增长,这两个的区别就在这里,一个底层使用AUTO_INCREMENT,一个底层使用这个序列化增长的。
4、native:hibernate不管理,让数据库底层自己选择主键如何生成,也就是说,如果是mysql,那就默认使用identity,也就是我们自己需要设置AUTO_INCREMENT,如果是Oracle,那么就默认使用sequence,让数据库底层自己设计哪个序列化增长
5、uuid:这个大家很熟悉,也就是我们不需要在数据库中主键上设置什么,每次度会给主键生成一个随机的32位字符串
6、assigned:这个很简单,就是我们需要手动自己给主键设置值,hibernate和数据库度不主动帮我们设置。
就这六种,其实很好学,identity和sequence就是需要我们自己在数据库中设置自动增长或者序列化增长,increment就是hibernate帮我们管理主键。数据库底层不需要写任何东西,前提是数据库需要支持自动增长,比如Oracle就用不了这个,native也是需要我们自己在数据库中设置,但是比起identity和sequence更加灵活,更改底层数据库,这个就不需要改,uuid也很熟悉大家,assigned这个更简单,就是用来自己写主键值的嘛。
到这就结束了,正式开始我们的多对多映射关系把
二、多对多映射关系
已经清楚了一对多的关系后,那么就简单很多了,多对多其实也分单向多对多,和双向多对多,但是单向多对多比较简单,并且用的最多的就是双向多对多了,知道了双向多对多,单向多对多就非常简单,所以我们直接讲双向多对多
生活中有很多例子就是双向多对多的,最简单和贴近我们生活的,
1、学生和选课之间的关系了,学生可以选择多门课程,课程可以被多个学生选择,
2、在淘宝中购物,一件商品能被多个人选择,一个人能够选择多个商品
3、....很多这种多对多关系,就拿学生和选课这个例子来讲解把。
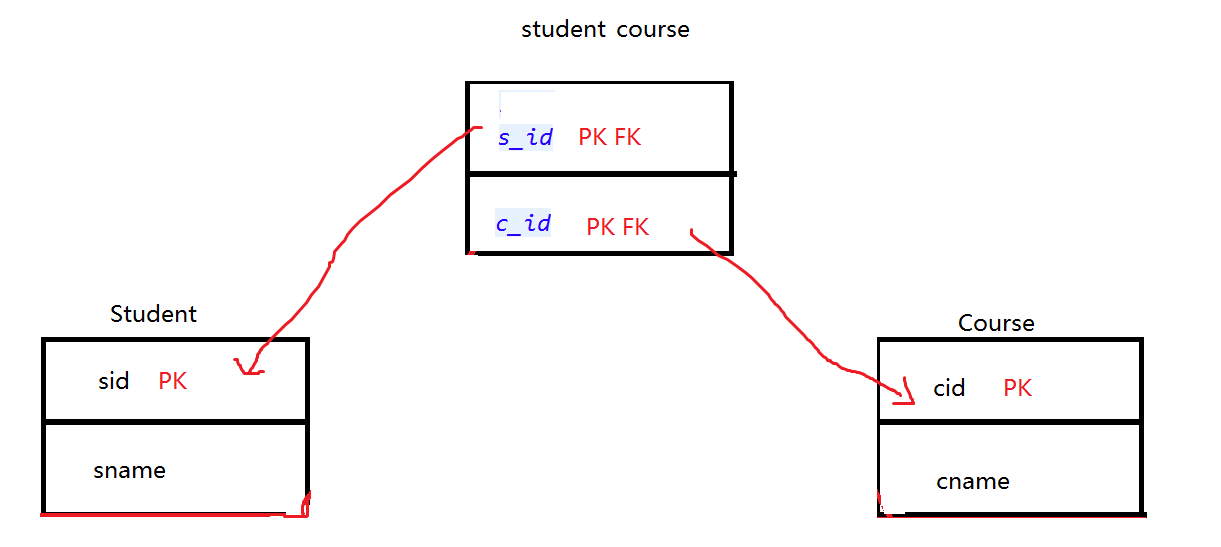
要保存多对多的关系,两张表是不够的,需要增加第三张表来表示这种关系,来看下面的数据库关系图。
这个图意思就是用student_course这个中间表来保存student和course这两张表的关系,并且student_course是联合主键。同时也是外键,指向student的sid和Course的cid。
有人肯定会觉得为什么还要用第三张表,不直接使用两个外键,你指向我,我指向你这样呢,这样会暴露出一个很大的问题,如果学过数据库就应该会知道,这样的两张表相互关联,那么这两张表的关系就固定在那里了,删哪个表就不能删,这个都市小事,当你在查询一个表中数据时,会造成死循环,你查了我,我又在查你,一直重复下去。那就GG了。
解析
为什么需要设置联合主键和两个外键:
student通过自己的主键在连接表中查询,因为是复合主键,所以查询到的记录有很多,而不是唯一的,这些记录中就记录了一个学生的所有课程,拿到这些记录后,由于连接表中的有course的外键,所以能够通过记录中的c_id,找到course表中对应的记录。反过来,course通过自己的主键在连接表中查询得到很多记录,由于连接表中也有student的外键,所以通过记录中的s_id也能找到student中对应的记录。所以,表的设计就是这样,需要联合主键,并且也都市外键,这些度是有用的。少一个就查不出对方了。
2、实体类和映射配置
Student持久化类和Student.hbm.xml
//Student实体类
public class Student {
private Integer sid;
private String sname;
//用set集合来保存选的多个课程
private Set<Course> courseSet = new HashSet<Course>(); set、get.....
} //Student.hbm.xml
<class name="domain.Student" table="student">
<id name="sid" column="sid">
<!-- 主键生成策略 -->
<generator class="increment"></generator>
</id>
<!-- 一些常规属性 -->
<property name="sname"></property> <!-- 关键的地方就在这里了。一定要搞清楚两个column分别指的是什么意思 脑袋中要有哪个数据库关系图--> <!--要查询到所有的course,就需要通过连接表,所以申明连接表的名称-->
<set name="courseSet" table="student_course">
<!-- 本实体类在连接表中的外键名称,过程我们上面分析的很清楚了,为什么需要这个呢?让hibernate知道连接表中有一个外键名为s_id的指向本实体类 -->
<key column="s_id"></key>
<!-- 多对多映射关系,映射类和其映射类在连接表中的外键名称 这个的意思跟上面的一样,也是声明让hibernate知道,这样一来,hibernate就知道如何查询了-->
<many-to-many class="domain.Course" column="c_id"></many-to-many>
</set>
</class>
Course和Course.hbm.xml
//Course实体类
public class Course {
private int cid;
private String cname;
private Set<Student> studentSet = new HashSet<Student>();
...
} //Course.hbm.xml 有了上面的分析,这个就简单了,内容和意义跟上面的一模一样。
<class name="domain.Course" table="course">
<id name="cid" column="cid">
<!-- 主键生成策略 -->
<generator class="increment"></generator>
</id>
<!-- 一些常规属性 -->
<property name="cname"></property>
<set name="studentSet" table="student_course">
<!-- 本类在连接表中外键的名称, -->
<key column="c_id"></key>
<!--多对多映射关系,映射类和其映射类在连接表中的外键名称-->
<many-to-many class="domain.Student" column="s_id"></many-to-many>
</set>
</class>
3、测试类
//其他的就省略了,只写重要的代码。由于刚建立起来的关系,数据库中还没有任何数据,那么就添加初始数据了。这里会出现一个问题。如果把注释的这一行给放开的话,
报一个org.hibernate.exception.ConstraintViolationException错误,为什么会这样呢?其实从我们上面对数据库设计图的分析我们可以知道(只是那个分析是用查询来当例子,增加数据跟那个过程差不多),
在course的StudentSet中添加一个学生,这个过程是怎样的呢?因为要对StudentSet进行操作,那么就会找到连接表,添加一个学生,那么就会在连接表中,添加一条course的cid对应student的sid的记录,然后如果
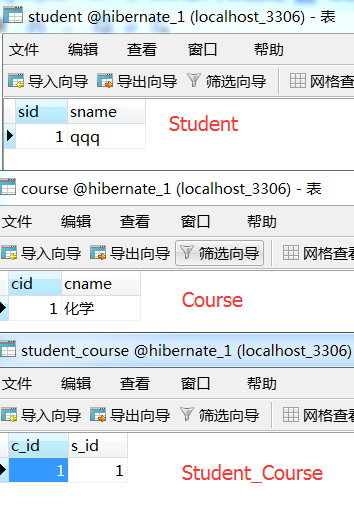
你在用student.getCourseSet().add(course)的话,又往连接表中增加了一条一模一样的记录,这个时候肯定会报错啊,因为是联合主键,两条记录一样,怎么会插的进去呢。所以就会出现违反约束异常(违反主键约束)了。 Course course = new Course();
course.setCname("化学"); Student student = new Student();
student.setSname("qqq"); course.getStudentSet().add(student);
// student.getCourseSet().add(course); session.save(course);
session.save(student);
4、效果图
五、总结
双向多对多理解了之后就会发现很简单,但是在开始学的时候,会觉得里面很绕,所以一定清楚每一步是什么,重要的是理解为什么连接表需要设置成那样。理解了你就会很轻松的学会了这个双向多对多映射关系,你一定动手自己去实现一下,其中隐藏了很多BUG,需要自己去解决。如果不动手写,那么你看懂了,过几天还是要靠抓别人的代码,而不是自己动手写。
Hibernate学习(四)———— 双向多对多映射关系的更多相关文章
- hibernate(四) 双向多对多映射关系
序言 莫名长了几颗痘,真TM疼,可能是现在运动太少了,天天对着电脑,决定了,今天下午花两小时去跑步了, 现在继上一章节的一对多的映射关系讲解后,今天来讲讲多对多的映射关系把,明白了一对多,多对多个人感 ...
- Hibernate学习之单向多对一映射
© 版权声明:本文为博主原创文章,转载请注明出处 说明:该实例是通过映射文件和注解两种方式实现的.可根据自己的需要选择合适的方式 实例: 1.项目结构 2.pom.xml <project xm ...
- Hibernate框架之双向多对多关系映射
昨天跟大家分享了Hibernate中单向的一对多.单向多对一.双向一对多的映射关系,今天跟大家分享下在Hibernate中双向的多对多的映射关系 这次我们以项目和员工举个栗子,因为大家可以想象得到,在 ...
- Hibernate学习之双向一对多映射(双向多对一映射)
© 版权声明:本文为博主原创文章,转载请注明出处 1.双向映射与单向映射 - 一对多单向映射:由一方(教室)维护映射关系,可以通过教室查询该教室下的学生信息,但是不能通过学生查询该学生所在教室信息: ...
- hibernate笔记--单(双)向的多对多映射关系
在讲单向的多对多的映射关系的案例时,我们假设我们有两张表,一张角色表Role,一张权限表Function,我们知道一个角色或者说一个用户,可能有多个操作权限,而一种操作权限同时被多个用户所拥有,假如我 ...
- hibernate annotation注解方式来处理映射关系
在hibernate中,通常配置对象关系映射关系有两种,一种是基于xml的方式,另一种是基于annotation的注解方式,熟话说,萝卜青菜,可有所爱,每个人都有自己喜欢的配置方式,我在试了这两种方式 ...
- Hibernate学习笔记(五) — 多对多关系映射
多对多关系映射 多对多建立关系相当于在第三张表中插入一行数据 多对多解除关系相当于在第三张表中删除一行数据 多对多改动关系相当于在第三张表中先删除后添加 多对多谁维护效率都一样.看需求 在实际开发过程 ...
- Hibernate第四篇【集合映射、一对多和多对一】
前言 前面的我们使用的是一个表的操作,但我们实际的开发中不可能只使用一个表的-因此,本博文主要讲解关联映射 集合映射 需求分析:当用户购买商品,用户可能有多个地址. 数据库表 我们一般如下图一样设计数 ...
- 一口一口吃掉Hibernate(四)——多对一单向关联映射
hibernate对于数据库的操作,全部利用面向对象的思维来理解和实现的.一般的单独表的映射,相信大家都没有问题,但是对于一些表之间的特殊关系,Hibernate提供了一些独特的方式去简化它. 今天就 ...
随机推荐
- javaScrpit 开端
JavaScript 代码可以直接嵌在网页的任何地方,不过我们通常把JavaScrpit放到<head>中: <html> <head> <script> ...
- Python select模块学习
select 是常用的异步socket 处理方法 一般用法: # iwtd,owtd,ewtd 分别为需要异步处理的读socket队列, 写socket队列(一般不用), 和错误socket队列, 返 ...
- jquery如何在元素后面添加一个元素
jQuery添加插入元素技巧: jquery添加分为在指定元素的里面添加和外面添加两种: 里面添加使用(append 和prepend) 里面添加又分为在里面的前面添加和后面添加 里面的前面添加使用 ...
- 原生js获取元素的子元素
//使用firstChild //但是下面这种因为有空格,也算其子元素 <lable> <span id="onlinePerson" name="pe ...
- 前端基于easyui的mvc扩展
背景 由于MVC的前端是基于jquery.validate和jquery.validate.unobtrusive来实现的,但是当我们要使用其他的ui组件且组件本身就带有完整的验证功能的话,那么要让它 ...
- 桌面应用开发之WPF页面导航
先看效果图 Get Start 为了项目解耦,使用mvvmlight框架.MVVM设计模式请自行了解. 1 新建项目 新建一个MvvmLight(WPF)项目,删除其中无关文件夹:Design ...
- 深入理解linux关闭文件和删除文件
背景介绍 最近看了linux系统编程(linux system programming)一书,结合深入理解linux内核(understanding the linux kernel)一书,深入理解了 ...
- noip第15课资料
- Linux基础理论
本节内容 1. Linux的安装及相关配置 2. UNIX和Linux操作系统概述 3. Linux命令及帮助 4. 目录结构 6. 用户.群组和权限 7. 用户.群组和权限的深入讨论 1 ...
- 实现一个简单的C++协程库
之前看协程相关的东西时,曾一念而过想着怎么自己来实现一个给 C++ 用,但在保存现场恢复现场之类的细节上被自己的想法吓住,也没有深入去研究,后面一丢开就忘了.近来微博上看人在讨论怎么实现一个 user ...