Elastic 技术栈之快速入门
Elastic 技术栈之快速入门
概念
ELK 是什么
ELK 是 elastic 公司旗下三款产品 ElasticSearch 、Logstash 、Kibana 的首字母组合。
ElasticSearch 是一个基于 Lucene 构建的开源,分布式,RESTful 搜索引擎。
Logstash 传输和处理你的日志、事务或其他数据。
Kibana 将 Elasticsearch 的数据分析并渲染为可视化的报表。
为什么使用 ELK ?
对于有一定规模的公司来说,通常会很多个应用,并部署在大量的服务器上。运维和开发人员常常需要通过查看日志来定位问题。如果应用是集群化部署,试想如果登录一台台服务器去查看日志,是多么费时费力。
而通过 ELK 这套解决方案,可以同时实现日志收集、日志搜索和日志分析的功能。
ELK 架构
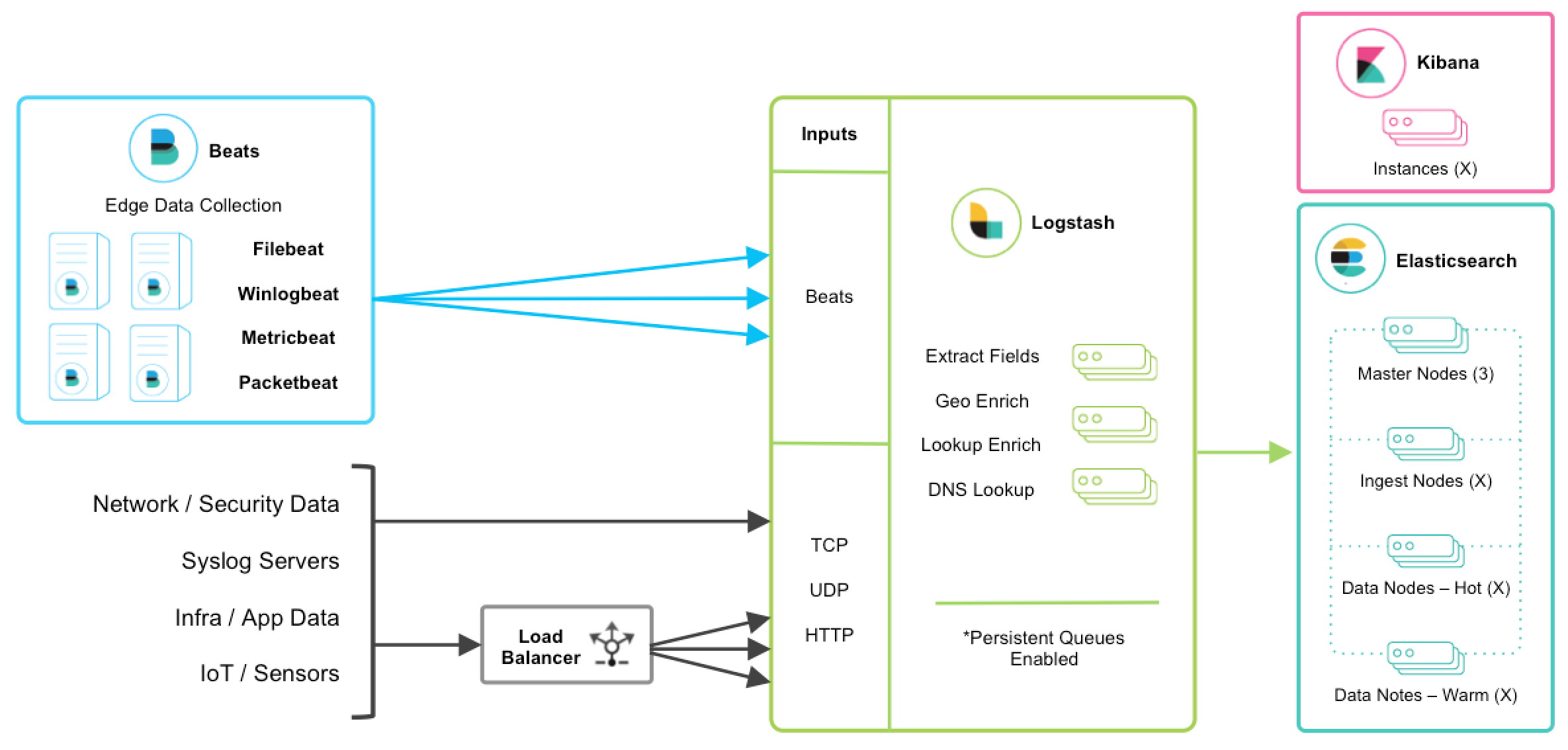
说明
以上是 ELK 技术栈的一个架构图。从图中可以清楚的看到数据流向。
Beats 是单一用途的数据传输平台,它可以将多台机器的数据发送到 Logstash 或 ElasticSearch。但 Beats 并不是不可或缺的一环,所以本文中暂不介绍。
Logstash 是一个动态数据收集管道。支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),并对数据做进一步丰富或提取字段处理。
ElasticSearch 是一个基于 JSON 的分布式的搜索和分析引擎。作为 ELK 的核心,它集中存储数据。
Kibana 是 ELK 的用户界面。它将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面。
安装
准备
ELK 要求本地环境中安装了 JDK 。如果不确定是否已安装,可使用下面的命令检查:
java -version
注意
本文使用的 ELK 是 6.0.0,要求 jdk 版本不低于 JDK8。
友情提示:安装 ELK 时,三个应用请选择统一的版本,避免出现一些莫名其妙的问题。例如:由于版本不统一,导致三个应用间的通讯异常。
Elasticsearch
安装步骤如下:
- elasticsearch 官方下载地址下载所需版本包并解压到本地。
- 运行
bin/elasticsearch(Windows 上运行bin\elasticsearch.bat) - 验证运行成功:linux 上可以执行
curl http://localhost:9200/;windows 上可以用访问 REST 接口的方式来访问 http://localhost:9200/
说明
Linux 上可以执行下面的命令来下载压缩包:
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
Mac 上可以执行以下命令来进行安装:
brew install elasticsearch
Windows 上可以选择 MSI 可执行安装程序,将应用安装到本地。
Logstash
安装步骤如下:
在 logstash 官方下载地址下载所需版本包并解压到本地。
添加一个
logstash.conf文件,指定要使用的插件以及每个插件的设置。举个简单的例子:input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
运行
bin/logstash -f logstash.conf(Windows 上运行bin/logstash.bat -f logstash.conf)
Kibana
安装步骤如下:
- 在 kibana 官方下载地址下载所需版本包并解压到本地。
- 修改
config/kibana.yml配置文件,设置elasticsearch.url指向 Elasticsearch 实例。 - 运行
bin/kibana(Windows 上运行bin\kibana.bat) - 在浏览器上访问 http://localhost:5601
安装 FAQ
elasticsearch 不允许以 root 权限来运行
问题:在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。
如果以 root 身份运行 elasticsearch,会提示这样的错误:
can not run elasticsearch as root
解决方法:使用非 root 权限账号运行 elasticsearch
# 创建用户组
groupadd elk
# 创建新用户,-g elk 设置其用户组为 elk,-p elk 设置其密码为 elk
useradd elk -g elk -p elk
# 更改 /opt 文件夹及内部文件的所属用户及组为 elk:elk
chown -R elk:elk /opt # 假设你的 elasticsearch 安装在 opt 目录下
# 切换账号
su elk
vm.max_map_count 不低于 262144
问题:vm.max_map_count 表示虚拟内存大小,它是一个内核参数。elasticsearch 默认要求 vm.max_map_count 不低于 262144。
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:
你可以执行以下命令,设置 vm.max_map_count ,但是重启后又会恢复为原值。
sysctl -w vm.max_map_count=262144
持久性的做法是在 /etc/sysctl.conf 文件中修改 vm.max_map_count 参数:
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p
注意
如果运行环境为 docker 容器,可能会限制执行 sysctl 来修改内核参数。
这种情况下,你只能选择直接修改宿主机上的参数了。
nofile 不低于 65536
问题: nofile 表示进程允许打开的最大文件数。elasticsearch 进程要求可以打开的最大文件数不低于 65536。
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决方法:
在 /etc/security/limits.conf 文件中修改 nofile 参数:
echo "* soft nofile 65536" > /etc/security/limits.conf
echo "* hard nofile 131072" > /etc/security/limits.conf
nproc 不低于 2048
问题: nproc 表示最大线程数。elasticsearch 要求最大线程数不低于 2048。
max number of threads [1024] for user [user] is too low, increase to at least [2048]
解决方法:
在 /etc/security/limits.conf 文件中修改 nproc 参数:
echo "* soft nproc 2048" > /etc/security/limits.conf
echo "* hard nproc 4096" > /etc/security/limits.conf
Kibana No Default Index Pattern Warning
问题:安装 ELK 后,访问 kibana 页面时,提示以下错误信息:
Warning No default index pattern. You must select or create one to continue.
...
Unable to fetch mapping. Do you have indices matching the pattern?
这就说明 logstash 没有把日志写入到 elasticsearch。
解决方法:
检查 logstash 与 elasticsearch 之间的通讯是否有问题,一般问题就出在这。
使用
本人使用的 Java 日志方案为 slf4j + logback,所以这里以 logback 来讲解。
Java 应用输出日志到 ELK
修改 logstash.conf 配置
首先,我们需要修改一下 logstash 服务端 logstash.conf 中的配置
input {
# stdin { }
tcp {
# host:port就是上面appender中的 destination,
# 这里其实把logstash作为服务,开启9250端口接收logback发出的消息
host => "127.0.0.1" port => 9250 mode => "server" tags => ["tags"] codec => json_lines
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
说明
这个 input 中的配置其实是 logstash 服务端监听 9250 端口,接收传递来的日志数据。
然后,在 Java 应用的 pom.xml 中引入 jar 包:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.11</version>
</dependency>
接着,在 logback.xml 中添加 appender
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--
destination 是 logstash 服务的 host:port,
相当于和 logstash 建立了管道,将日志数据定向传输到 logstash
-->
<destination>127.0.0.1:9250</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<logger name="io.github.dunwu.spring" level="TRACE" additivity="false">
<appender-ref ref="LOGSTASH" />
</logger>
大功告成,此后,io.github.dunwu.spring 包中的 TRACE 及以上级别的日志信息都会被定向输出到 logstash 服务。

资料
Elastic 技术栈之快速入门的更多相关文章
- Elastic 技术栈之 Logstash 基础
title: Elastic 技术栈之 Logstash 基础 date: 2017-12-26 categories: javatool tags: java javatool log elasti ...
- Elastic 技术栈之 Filebeat
Elastic 技术栈之 Filebeat 简介 Beats 是安装在服务器上的数据中转代理. Beats 可以将数据直接传输到 Elasticsearch 或传输到 Logstash . Beats ...
- 使用 Elastic 技术栈构建 Kubernetes全栈监控
以下我们描述如何使用 Elastic 技术栈来为 Kubernetes 构建监控环境.可观测性的目标是为生产环境提供运维工具来检测服务不可用的情况(比如服务宕机.错误或者响应变慢等),并且保留一些可以 ...
- 学习Mysql过程中拓展的其他技术栈:Docker入门介绍
一.Docker的介绍和安装 1. Docker是什么 百度百科的介绍: Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linu ...
- 使用 Elastic 技术栈构建 K8S 全栈监控 -4: 使用 Elastic APM 实时监控应用性能
文章转载自:https://www.qikqiak.com/post/k8s-monitor-use-elastic-stack-4/ 操作步骤 apm-servver连接es使用上一步创建的secr ...
- 使用 Elastic 技术栈构建 K8S 全栈监控 -3: 使用 Filebeat 采集 Kubernetes 集群日志
文章转载自:https://www.qikqiak.com/post/k8s-monitor-use-elastic-stack-3/ 操作步骤 filebeat连接es使用上一步创建的secret: ...
- 使用 Elastic 技术栈构建 K8S 全栈监控 -2: 用 Metricbeat 对 Kubernetes 集群进行监控
文章转载自:https://www.qikqiak.com/post/k8s-monitor-use-elastic-stack-2/ 操作步骤 git clone https://github.co ...
- 使用 Elastic 技术栈构建 K8S 全栈监控 -1:搭建 ElasticSearch 集群环境
文章转载自:https://www.qikqiak.com/post/k8s-monitor-use-elastic-stack-1/ 操作步骤 kubectl create ns elastic k ...
- 快速了解Scala技术栈
http://www.infoq.com/cn/articles/scala-technology/ 我无可救药地成为了Scala的超级粉丝.在我使用Scala开发项目以及编写框架后,它就仿佛凝聚成为 ...
随机推荐
- React Native中Mobx的使用
从今天开始我们来搞搞状态管理可否,这几天没怎么写博客,因为被病魔战胜了,tmd,突然的降温让我不知所措,大家最近注意安全,毕竟年底了,查的严,呸,大家注意保暖 特别声明:写该文只是写一下用MobX的思 ...
- [VUE ERROR] Invalid options in vue.config.js: "publicPath" is not allowed
项目在build的时候报的这个错误: 具体原因是因为版本支持的问题,publicPath 属性到 vue-cli 3.2.0 之后才支持,所以将 publicPaht 改成 baseUrl 即可,或者 ...
- Fiddler抓包使用教程-过滤
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/72929800 本文出自[赵彦军的博客] Fiddler抓包可以完成我们移动开发者的 ...
- C语言程序试题
一个无向连通图G点上的哈密尔顿(Hamiltion)回路是指从图G上的某个顶点出发,经过图上所有其他顶点一次且仅一次,最后回到该顶点的路劲.一种求解无向图上哈密尔顿回路算法的基础实现如下: 假设图G存 ...
- 请问在EXECUTE IMMEDIATE中如何使用带有引号
转自:http://bbs.csdn.net/topics/300191423 从第一引号向后,如果遇到第二个引号,则看这个引号后面时候有紧挨着的引号,如果有则第二个引号被转义,即该保留该引号后面紧跟 ...
- Linux自制编译内核
今天我们来自己学习编译内核并使用它.自制内核是个人定制版,定制自己专属的内核环境. 我们先看看编译步骤有哪些: 步骤: 1.# tar xf linux-3.10.37.tar.xz -C /usr/ ...
- python学习--Django虚拟环境搭建
一 . 为什么选择搭建虚拟环境 搭建一个只对本次项目有用的虚拟环境,而不影响主环境 二 . 安装前准备 # 1. 安装 python # 2. 安装virtualenvwrapper # ...
- C++中如何按照map中的value来进行排序
sort函数无法对map进行排序,网上的方法一般是通过将map转为vector后,再来使用sort进行排序. 如下, 比较函数 bool cmp(const pair<int,int> & ...
- JDBC lesson 1
https://www.mkyong.com/tutorials/jdbc-tutorials/ 1.jdbc基本概念 Java Database Connectivity (JDBC)是一套提供数据 ...
- 【BZOJ4310】跳蚤
[BZOJ4310]跳蚤 Description 很久很久以前,森林里住着一群跳蚤.一天,跳蚤国王得到了一个神秘的字符串,它想进行研究. 首先,他会把串分成不超过 k 个子串,然后对于每个子串 S,他 ...