hive分区表

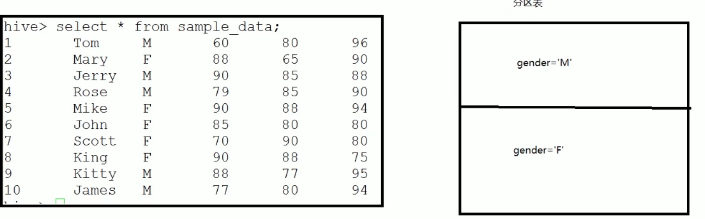
分区表创建
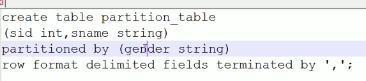

row format delimited fields terminated by ',';指明以逗号作为分隔符

依靠插入表创建分区表 从表sample_table选择 满足分区条件的 列插入到分区表中
insert into table partition_table partition(gender='M') select id,name from sample_table where gender='M';
insert into table partition_table partition(gender='F') select id,name from sample_table where gender='F';
explain可以查看执行计划
$ explain select *from sample_table where gender = 'M';
$ explain select *from partition_table where gender = 'M';
hive分区表的更多相关文章
- 解决Spark读取Hive分区表出现Input path does not exist的问题
假设这里出错的表为test表. 现象 Hive读取正常,不会报错,Spark读取就会出现: org.apache.hadoop.mapred.InvalidInputException: Input ...
- Hadoop: the definitive guide 第三版 拾遗 第十二章 之Hive分区表、桶
Hive分区表 在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作.有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念.分区表指的是在创建表时指 ...
- Hive分区表的导入与导出
最近在做一个小任务,将一个CDH平台中Hive的部分数据同步到另一个平台中.毕竟我也刚开始工作,在正式开始做之前,首先进行了一段时间的练习,下面的内容就是练习时写的文档中的内容.如果哪里有错误或者疏漏 ...
- Hive分区表新增字段及修改表名,列名,列注释,表注释,增加列,调整列顺序,属性名等操作
一.Hive分区表新增字段 参考博客:https://blog.csdn.net/yeweiouyang/article/details/44851459 二.Hive修改表名,列名,列注释,表注释, ...
- spark 将dataframe数据写入Hive分区表
从spark1.2 到spark1.3,spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API.Da ...
- 如何每日增量加载数据到Hive分区表
如何每日增量加载数据到Hive分区表 hadoop hive shell crontab 加载数据 数据加载到Hive分区表(两个分区,日期(20160316)和小时(10))中 每日加载前一天的日志 ...
- Hive分区表创建,增加及删除
1.创建Hive分区表,按字段分区 CREATE TABLE test1 ( id bigint , create_time timestamp , user_id string) partition ...
- hive中导入json格式的数据(hive分区表)
hive中建立外部分区表,外部数据格式是json的如何导入呢? json格式的数据表不必含有分区字段,只需要在hdfs目录结构中体现出分区就可以了 This is all according to t ...
- Hive分区表动态添加字段
场景描述: 公司埋点项目,数据从接口服务写入kafka集群,再从kafka集群消费写入HDFS文件系统,最后通过Hive进行查询输出.这其中存在一个问题就是:埋点接口中的数据字段是变化,后续会有少量字 ...
- hive 分区表
hive中创建分区表没有什么复杂的分区类型(范围分区.列表分区.hash分区.混合分区等).分区列也不是表中的一个实际的字段,而是一个或者多个伪列.意思是说在表的数据文件中实际上并不保存分区列的信息与 ...
随机推荐
- vue指令相关的
阅读目录 1.v-text 2.v-html 3.v-show 4.v-if 5.v-if vs v-show 6.v-else 7.v-for 8.v-on 9.v-bind 和 v-model 1 ...
- 在windows端使用jupyter notebook,服务器充当后台计算云端 简化描述
在CentOS7服务器端启动jupyter notebook服务,在windows端使用jupyter notebook,服务器充当后台计算云端 简化描述 CentOS7服务器端 jupyter no ...
- ASP.NET Log4net 记录日志
1.安装方式一(官网下载) 2.安装方式二(NuGet安装log4net) 3.使用步骤 4.自定义属性:UserIP UserName ActionsClick Message 概述:Log4net ...
- fragment The specified child already has a parent. You must call removeView()
在切换Fragment的时候出现:The specified child already has a parent. You must call removeView()异常. 错误主要出在Fragm ...
- 开发板测试-Wi-Fi
一,下载STM32程序 1,方式一,串口下载(其他下载方式在最后补充) ①调整拨动开关位置 → 短接BOOT0和3.3V → 复位STM32 ②打开下载软件,下载程序 去掉短接 ③测试 {data:s ...
- maven 插
一.maven插件元素 <?xml version="1.0" encoding="utf-8"?> <plugin> <!--插 ...
- day81
昨日回顾: 昨日回顾: auth组件: -验证:authenticat(request,username=') -登录:login(request,user) -注销:logout(request), ...
- eclipse的快捷键【转载】
原文地址http://www.open-open.com/bbs/view/1320934157953/ Eclipse中10个最有用的快捷键组合 一个Eclipse骨灰级开发者总结了他认为最有用但 ...
- 3.《想成为黑客,不知道这些命令行可不行》(Learn Enough Command Line to Be Dangerous)——检查文件
上面我们已经学过如何创建及操作文件,现在我们再来学习检查内容.当文件太长以至于屏幕一页显示不完时,这显得尤其重要.特殊情形下,如我们在第2.1章节开始部分中使用cat命令将内容展示到屏幕上,但这对于长 ...
- Luogu P1330 封锁阳光大学
这是一道神坑题! 刚开始看了题还以为是Tarjan(我也不知道Tarjan有什么用). 然后发现这是染色问题的模板题! 找到没有染色的点,然后将它涂成1(一共只有1,2两种颜色) 与它相连的点进行广搜 ...