sed原理及使用
前言
环境:centos6.5
sed版本:GNU sed version 4.2.1
本文的代码都是在这个环境下验证的。
一、简介
sed(Stream Editor)意为流编辑器,是Unix常见的命令行程序。是Bell实验室的 LeeE.McMahon 在1973年到1974年之间开发完成,目前可以在大多数操作系统中使用。
sed的出现是作为grep的一个继任者,因为grep只能简单的进行查找和替换,但是考虑还可能会有删除等各种需求,McMahon 开发了一个更具通用性的工具。sed著名的语法规则包括使用 / 进行模式匹配,以及 s/// 来进行替代。与同期存在的工具ed一起,sed的语法影响了后来发展的 ECMAScript 和 Perl。GNU sed 添加了很多特性,包括著名的 in-place editing。
二、处理流程
要说明sed的处理流程,需要先提它的命令语法:
sed [options] script filename
一般来说,sed是从stdin读取输入,并且将输出写出到stdout,但是filename被指定时,会从指定的文件中获取输入,输出可以重定向到另外的文件中。
options指的是sed的命令行参数,比较有限,这个后面会说明。
script是指需要对输入执行的一个或者多个操作指令,一般需要用单引号括起来,这样可以避免shell对特殊字符的处理。sed会依次读取输入文件的每一行到缓存中并应用script中指定的操作指令,因此而带来的变化并不会影响最初的文件(除非option加了-i参数)。
如果操作指令很多,为了不影响可读性,可以将其写入文件,并用-f参数指定该文件:
sed -f scriptfile filename
无论是将操作指令通过命令行指定,还是写入到文件中作为一个sed脚本,必须包含至少一个指令,否则用sed就没有意义了。
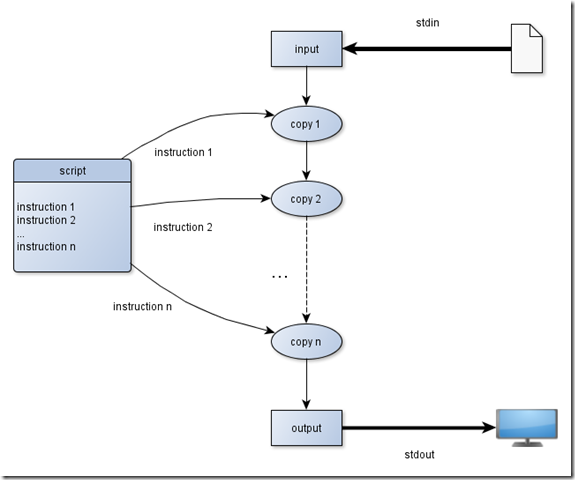
每条操作指令由pattern和procedure两部分组成,顾名思义,pattern是匹配的规则,一般为用'/'分隔的正则表达式(也有可能是行号,具体参见Sed命令地址匹配问题总结),而procedure则是一连串编辑命令(action)。 sed的处理流程,简化后是这样的:
- 读入新的一行内容到缓存空间;
- 从指定的操作指令中取出第一条指令,判断是否匹配pattern;
- 如果不匹配,则忽略后续的编辑命令,回到第2步继续取出下一条指令;
- 如果匹配,则针对缓存的行执行后续的编辑命令;完成后,回到第2步继续取出下一条指令;
- 当所有指令都应用之后,输出缓存行的内容;回到第1步继续读入下一行内容;
- 当所有行都处理完之后,结束;
具体流程如图所示:
三、命令选项options
根据上面提到的,我们知道sed一般有两种语法形式:
sed [options] script filename
sed -f scriptfile filename
options常用的只有几个:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
在这里,-e参数实际上很多时候会让人很迷惑。因为我们平时使用sed的时候一般都不会加-e参数,譬如:
seq 6 | sed -n '1,2p'
它和下面的写法是等价的:
seq 6 | sed -ne '1,2p'
所以很多文章在说到-e这个参数的时候说可以省略,实际上,这种说法是不严谨的。sed发展到现在,已经有各种各样的版本,在有些版本中,-e参数是不可以省略的,但是我们一般使用的都是GNU sed(gsed),所以在这种情况可以省略。-e参数最常用的场景是对同一文件作多次修改,如:
seq 6 | sed -e 's/1/10/' -e 's/2/20/'
但是实际上多重编辑还有更简洁的写法,就是在同一个script中,用分号分割两句指令:
seq 6 | sed -e 's/1/10/;s/2/20/'
在处理流程部分,我们提到,每条操作指令script一般由pattern和procedure两部分组成,接下来说说pattern和procedure。
四、pattern
1. 模式空间
回顾一下上面讲到的处理流程,我们可以知道,sed是以行的方式来处理数据的,每一行被读入到一块缓存空间,该空间名为模式空间(pattern space)。因此sed操作的都是最初行的拷贝,同时后续的编辑命令都是应用到前面的命令编辑后输出的结果,所以编辑命令之间的顺序就显得格外重要。
让我们来看一个非常简单的例子,将一段文本中的pig替换成cow,并且将cow替换成horse:
echo "pig and cow and horse" | sed 's/pig/cow/;s/cow/horse/'
初看起来好像没有问题,但是实际上是错误的,最后输出实际上是:
hores and cow and horse
原因是第一个替换命令将遇到的第一个pig替换成cow,紧接着的替换命令是基于前一个结果处理的,将第一个cow替换成horse。造成的结果是:第一个pig给换 成cow,然后又给换成了horse,这样违背了我们的初衷。在这种情况下,只需要调换下两个编辑命令的顺序:
echo "pig and cow and horse" | sed 's/cow/hores/;s/pig/cow/'
2. 模式空间的转换
sed只会缓存一行的内容在模式空间,这样的好处是sed可以处理大文件而不会有任何问题,不像一些编辑器因为要一次性载入文件的一大块内容到缓存中而导致内存不足。
例如,现在要把一段文本中的Unix System与UNIX System都要统一替换成The UNIX Operating System,因此我们用两句替换命令来完成这个目的:
echo "the Unix System" | sed 's/Unix/UNIX/;s/UNIX System/UNIX Operating System/'
==> the UNIX Operating System
过程简单来说如下:
1)读入一行内容到模式空间
2)应用第一条替换命令将Unix换成UNIX
3)模式空间的内容变为”the UNIX System”
4)应用第二条替换命令将UNIX System替换成UNIX Operating System
5)模式空间的内容变为”the UNIX Operating System”
6)所有编辑命令执行完毕,输出模式空间中的行
3. 地址匹配
地址匹配限制sed的编辑命令到底应用在哪些行上。默认情况下,sed是全局匹配的,即对所有输入行都应用指定的编辑命令,这是因为sed依次读入每一行,每一行都会成为当前行并被处理,所以s/apple/Pear/g会将所有输入行的apple替换成pear。
但如果通过指定地址范围,则只会替换范围内的行,譬如:
echo "Harry loves apple" | sed '/Mary/s/apple/pear/'
==> Harry loves apple
/Mary/是一个正则表达式,表示匹配包含Mary的行,因此”Harry loves apple”不会被替换.
sed命令中可以包含0个、1个或者2个地址(地址对)。地址可以为正则表达式(如/Mary/),行号或者特殊的行符号(如$表示最后一行):
- 如果没有指定地址,默认将编辑命令应用到所有行;
- 如果指定一个地址,只将编辑命令应用到匹配该地址的行;
- 如果指定一个地址对(addr1,addr2),则将编辑命令应用到地址对中的所有行(包括起始和结束);
- 如果地址后面有一个感叹号(!),则将编辑命令应用到不匹配该地址的所有行;
为了方便理解上述内容,我们以删除命令(d)为例来说明。
1)以行号指定地址
默认不指定地址将会删除所有行:
sed 'd' file
指定地址则删除匹配的行,如删除第一行:
sed '1d' file
或者删除最后一行,$符号在这里表示最后一行,这点要下正则表达式中的含义区别开来:
sed '$d' file
通过指定地址对可以删除该范围内的所有行,例如删除第3行到最后一行:
sed '2,$d' file
这里通过指定行号删除,行号是sed命令内部维护的一个计数变量,该变量只有一个,并且在多个文件输入的情况下也不会被重置。
2)通过正则表达式来指定地址
删除包含MA的行:
sed '/MA/d' file
删除从包含Alice的行开始到包含Hubert的行结束的所有行:
sed '/Alice/,/Hubert/d' file
当然,行号和地址对是可以混用的,删除第二行到包含Hubert的行结束的所有行:
sed '2,/Hubert/d' file
如果在地址后面指定感叹号(!),则会将命令应用到不匹配该地址的行:
sed '2,/Hubert/!d' file
以上介绍的都是最基本的地址匹配形式,GNU Sed基于此添加了几个扩展的形式,具体可以看man手册,或者可以看Sed 命令地址匹配问题总结。
上面说的内容都是对匹配的地址执行单个命令,如果要执行多个编辑命令要怎么办?sed中可以用{}来组合命令,就好比编程语言中的语句块,例如:
sed -n '1,4{s/ MA/, Massachusetts/;s/ PA/, Pennsylvania/;p}' file
五、procedure
对于sed编辑命令的语法有两种约定,分别是
[address]procedure # 第一种
[line-address]procedure # 第二种
第一种[address]是指可以为任意地址包括地址对,第二种[line-address]是指只能为单个地址。
以下是要介绍的全部基础命令:
|
名称 |
命令 |
语法 |
说明 |
|
替换 |
s |
[address]s/pattern/replacement/flags |
替换匹配的内容 |
|
删除 |
d |
[address]d |
删除匹配的行 |
|
插入 |
i |
[line-address]i\text |
在匹配行的前方插入文本 |
|
追加 |
a |
[line-address]a\text |
在匹配行的后方插入文本 |
|
行替换 |
c |
[address]c\text |
将匹配的行替换成文本text |
|
打印行 |
p |
[address]p |
打印在模式空间中的行 |
|
打印行号 |
= |
[address]= |
打印当前行行号 |
|
打印行 |
l |
[address]l |
打印在模式空间中的行,同时显示控制字符 |
|
转换字符 |
y |
[address]y/SET1/SET2/ |
将SET1中出现的字符替换成SET2中对应位置的字符 |
|
读取下一行 |
n |
[address]n |
将下一行的内容读取到模式空间 |
|
读文件 |
r |
[line-address]r file |
将指定的文件读取到匹配行之后 |
|
写文件 |
w |
[address]w file |
将匹配地址的所有行输出到指定的文件中 |
|
退出 |
q |
[line-address]q |
读取到匹配的行之后即退出 |
1. 替换命令: s
语法:
[address]s/pattern/replacement/flags
其中[address]是指地址,pattern是替换命令的匹配表达式,replacement则是对应的替换内容,flags是指替换的标志位,它可以包含以下一个或者多个值:
- n: 一个数字(取值范围1-512),表明仅替换前n个被pattern匹配的内容;
- g: 表示全局替换,替换所有被pattern匹配的内容;
- p: 仅当行被pattern匹配时,打印模式空间的内容;
- w file:仅当行被pattern匹配时,将模式空间的内容输出到文件file中;
常用语句:
# 直接替换tar_file中的org_str为dst_str
sed -i 's/org_str/dst_str/g' tar_file
如果flags为空,则默认替换第一次匹配,如:
echo "column1 column2 column3 column4" | sed 's/ /;/'
==> column1;column2 column3 column4
如果flags中包含g,则表示全局匹配:
echo "column1 column2 column3 column4" | sed 's/ /;/g'
==> column1;column2;column3;column4
如果flags中明确指定替换第n次的匹配,例如n=2:
echo "column1 column2 column3 column4" | sed 's/ /;/2'
==> column1 column2;column3 column4
当替换命令的pattern与地址部分是一样的时候,比如/regexp/s/regexp/replacement/可以省略替换命令中的pattern部分,这在单个编辑命令的情况下没多大用处,但是在组合命令的场景下还是能省不少功夫的。
譬如我们有一个文件prince,里面的内容是:
If someone loves a flower, of which just one single blossom grows in all the
millions and millions of stars, it is enough to make him happy just to look at
the stars. He can say to himself, "Somewhere, my flower is there…" But if the
sheep eats the flower, in one moment all his stars will be darkened… And you think that is not important
!
现在要在flower后面增加(“s”),同时在被修改的行前面增加+号,以下是使用的sed命令:
sed '/flower/{s//&("s")/;s/^/+ /}' prince
这里我们用到了组合命令,并且地址匹配的部分和第一个替换命令的匹配部分是一样的,所以后者我们省略了,在replacement部分用到了&这个元字符,它代表之前匹配的内容,这点我们在后面介绍。执行后的结果为:
+
If someone loves a flower
("s"),
of which just one single blossom grows in all the
millions and millions of stars, it is enough to make him happy just to look at
+
the stars. He can say to himself, "Somewhere, my flower
("s")
is there…" But if the
+
sheep eats the flower
("s")
, in one moment all his stars will be darkened… And you think that is not important!
替换命令的一个技巧是中间的分隔符是可以更改的,这个技巧在有些地方非常有用,比如路径替换,下面是采用默认的分隔符和使用感叹号作为分隔符的对比:
find /usr/local -maxdepth 2 -type d | sed 's//usr/local/man//usr/share/man/'
find /usr/local -maxdepth 2 -type d | sed 's!/usr/local/man!/usr/share/man!'
替换命令中还有一个很重要的部分——replacement(替换内容),即将匹配的部分替换成replacement。在replacemnt部分中也有几个特殊的元字符,它们分别是:
- &: 被pattern匹配的内容;
- \num: 被pattern匹配的第num个分组(正则表达式中的概念,\(..\)括起来的部分称为分组;
- \: 转义符号,用来转义&,\, 回车等符号
2. 删除命令: d
语法:
[address]d
删除命令可以用于删除多行内容,例如1,3d会删除1到3行。删除命令会将模式空间中的内容全部删除,并且导致后续命令不会执行并且读入新行,因为当前模式空间的内容已经为空。我们可以试试:
sed '2,${d;=}' prince
==> If someone loves a flower, of which just one single blossom grows in all the
以上命令尝试在删除第2行到最后一行之后,打印当前行号(=),但是事实上并没有执行该命令。
3. 插入行/追加行/替换行命令: i/a/c
语法:
# Append 追加
[line-address]a\text
# Insert 插入
[line-address]i\text
# Change 行替换
[address]c\text
以上三个命令,行替换命令(c)允许地址为多个地址,其余两个都只允许单个地址(注:在ArchLinux上测试表明,追加和插入命令都允许多个地址,sed版本为GNU sed version 4.2.1)
追加命令是指在匹配的行后面插入文本text;相反地,插入命令是指匹配的行前面插入文本text;最后,行替换命令会将匹配的行替换成文本text。文本text并没有被添加到模式空间,而是直接输出到屏幕,因此后续的命令也不会应用到添加的文本上。注意,即使使用-n参数也无法抑制添加的文本的输出。
我们用实际的例子来简单介绍下这三个命令的用法,用上面的文本prince:
现在,我们要在第2行后面添加'------':
sed '2a\
-------------------------\
' prince
输出:
If someone loves a flower, of which just one single blossom grows in all the
millions and millions of stars, it is enough to make him happy just to look at
-------------------------
the stars. He can say to himself, "Somewhere, my flower is there…" But if the
sheep eats the flower, in one moment all his stars will be darkened… And you think that is not important!
或者可以在第3行之前插入:
sed '3i\
--------------------------\
' prince
输出:
If someone loves a flower, of which just one single blossom grows in all the
millions and millions of stars, it is enough to make him happy just to look at
--------------------------
the stars. He can say to himself, "Somewhere, my flower is there…" But if the
sheep eats the flower, in one moment all his stars will be darkened… And you think that is not important!
我们来测试下文本是否确实没有添加到模式空间,因为模式空间中的内容默认是会打印到屏幕的:
sed -n '2a\
---------------------------\
' prince
输出:
---------------------------
通过-n参数来抑制输出后发现插入的内容依然被输出,所以可以判定插入的内容没有被添加到模式空间。
使用行替换命令将第2行到最后一行的内容全部替换成'----':
sed '2,$c\
---------------------------\
' prince
输出:
If someone loves a flower, of which just one single blossom grows in all the
---------------------------
4. 打印命令: p/l/=
这里纯粹的打印命令应该是指p,但是因为后两者(l和=)和p差不多,并且相对都比较简单,所以这里放到一起介绍。
[address]p
[address]=
[address]l
p命令用于打印模式空间的内容,例如打印文件的第一行:
sed -n '1p' prince
==> If someone loves a flower, of which just one single blossom grows in all the
l命令类似p命令,不过会显示控制字符,这个命令和vim的list命令相似,例如:
echo "column1 column2 column3^M" | sed -n 'l'
==> column1tcolumn2tcolumn3r$
=命令显示当前行行号,例如:
sed '=' prince
==>
1
If someone loves a flower, of which just one single blossom grows in all the
2
millions and millions of stars, it is enough to make him happy just to look at
3
the stars. He can say to himself, "Somewhere, my flower is there…" But if the
4
sheep eats the flower, in one moment all his stars will be darkened… And you think that is not important!
5
5. 转换命令: y
转换命令的语法是:
[address]y/SET1/SET2/
它的作用是在匹配的行上,将SET1中出现的字符替换成SET2中对应位置的字符,例如1,3y/abc/xyz/会将1到3行中出现的a替换成x,b替换成y,c替换成z。是不是觉得这个功能很熟悉,其实这一点和tr命令是一样的。可以通过y命令将小写字符替换成大写字符,不过命令比较长:
echo "hello, world" | sed 'y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/'
==> HELLO, WORLD
6. 取下一行命令: n
语法:
[address]n
n命令为将下一行的内容提前读入,并且将之前读入的行(在模式空间中的行)输出到屏幕,然后后续的命令会应用到新读入的行上。因此n命令也会同d命令一样改变sed的控制流程。
cat text
==>
.H1 "On Egypt"
Napoleon, pointing to the Pyramids, said to his troops:
"Soldiers, forty centuries have their eyes upon you."
现在要将.H1后面的空行删除:
sed '/.H1/{n;/^$/d}' text
==>
.H1 "On Egypt"
Napoleon, pointing to the Pyramids, said to his troops:
"Soldiers, forty centuries have their eyes upon you."
7. 读写文件命令: r/w
语法是:
[line-address]r file
[address]w file
读命令将指定的文件读取到匹配行之后,并且输出到屏幕,这点类似追加命令(a)。我们以书中的例子来讲解读文件命令。假设有一个文件text:
cat text
==>
For service, contact any of the following companies:
[Company-list]
Thank you.
同时我们有一个包含公司名称列表的文件company.list:
cat company.list
==>
Allied
Mayflower
United
现在我们要将company.list的内容读取到[Company-list]之后:
sed '/^[Company-list]/r company.list' text
=>
For service, contact any of the following companies:
[Company-list]
Allied
Mayflower
United
Thank you.
写命令将匹配地址的所有行输出到指定的文件中。假设有一个文件内容如下,前半部分是人名,后半部分是区域名称:
cat text
==>
Adams, Henrietta Northeast
Banks, Freda South
Dennis, Jim Midwest
Garvey, Bill Northeast
Jeffries, Jane West
Madison, Sylvia Midwest
Sommes, Tom South
现在我们要将不同区域的人名字写到不同的文件中:
sed '/Northeast$/w region.northeast
/South$/w region.south
/Midwest$/w region.midwest
/West$/w region.west' text
==>
Adams, Henrietta Northeast
Banks, Freda South
Dennis, Jim Midwest
Garvey, Bill Northeast
Jeffries, Jane West
Madison, Sylvia Midwest
Sommes, Tom South
8. 退出命令: q
语法:
[line-address]q
当sed读取到匹配的行之后即退出,不会再读入新的行,并且将当前模式空间的内容输出到屏幕。例如打印前3行内容:
sed '3q' prince
==>
If someone loves a flower, of which just one single blossom grows in all the
millions and millions of stars, it is enough to make him happy just to look at
the stars. He can say to himself, "Somewhere, my flower is there…" But if the
打印前3行也可以用p命令:
sed -n '3p' prince
但是对于大文件来说,前者比后者效率更高,因为前者读取到第N行之后就退出了。后者虽然打印了前N行,但是后续的行还是要继续读入,只不会不作处理。
到此为止,sed基础命令的部分就介绍完了。
六、小结
Linux系统工具众多,功能也互相重复,这些重复部分的语法还各不相同,比如 grep awk sed 都有正则表达式匹配的功能,但是三者的正则表达式语法就不相同。每个工具还分 GNU 版和不是 GNU 版,之间的差别也很大,即使都是 GNU 版,那么版本号的细微差别也会带来很多差别。
在普通的行处理任务方面,用sed很好,因为命令很简洁。
七、参考
(完)
sed原理及使用的更多相关文章
- sed原理及sed命令格式 ,缓存区,模式空间
4.1 Sed工作原理 sed是一个非交互式的流编辑器.所谓非交互式,是指使用sed只能在命令行下输入编辑命令来编辑文本,然后在屏幕上查看输出:而所谓流编辑器,是指sed每次只从 ...
- sed 增删改查详解以及 sed -i原理
我为什么要详细记录sed命令: sed 擅长取行.工作中三剑客使用频率最高,本篇文章将对sed命令常用的 增,删,改,查 进行详细讲解,以备以后工作中遗忘了查询,sed命令是作为运维人员来说, ...
- Linux的sed命令
一.初识sed 在部署openstack的过程中,会接触到大量的sed命令,比如 # Bind MySQL service to all network interfaces.sed -i 's/12 ...
- linux sed命令
一.初识sed 在部署openstack的过程中,会接触到大量的sed命令,比如 # Bind MySQL service to all network interfaces. sed -i 's/1 ...
- sed正则表达式
sed的正则匹配如何实现非贪婪? sed的正则用的是BREs/EREs,不支持非贪婪模式.当然有一些方法可以实现非贪婪,比如: $ echo abcOabcdOabc | sed 's/.*O//' ...
- 【转】sed正则表达式
1 正则表达式简介 正则表达式(Regular Expression) 是一种描述文本(或字符串)模式的工具.正则表达式常用于查找文本的场合.想想一下我们日常生活中的例子,假如你想从电话本里找一个联系 ...
- sed从入门到深入的使用心得
本人已经此系列的sed文章整理到pdf中,欢迎下载:玩透sed:探究sed原理 sed系列文章: sed修炼系列(一):花拳绣腿之入门篇sed修炼系列(二):武功心法(info sed翻译+注解)se ...
- 文本处理三剑客之 Sed ——一般编辑命令
sed简介 sed (stream editor for filtering and transforming text) 是Linux上的文本处理三剑客之一,另外两个是grep和awk. sed又称 ...
- Linux和Shell回炉复习系列文章总目录
本页内容都是本人回炉Linux时整理出来的.这些文章中,绝大多数命令类内容都是翻译.整理man或info文档总结出来的,所以相对都比较完整. 本人的写作方式.风格也可能会让朋友一看就恶心到直接右上角叉 ...
随机推荐
- django基础 -- 8.cookie 和 session
一. cookie 1.cookie 的原理 工作原理是:浏览器访问服务端,带着一个空的cookie,然后由服务器产生内容, 浏览器收到相应后保存在本地:当浏览器再次访问时,浏览器会自动带上Cooki ...
- rsync的daemon模式
官方文档:https://download.samba.org/pub/rsync/rsyncd.conf.html 1:daemon模式配置文件 rsync以daemon方式运行 ...
- 【转】使用VisualStudio完成自动化C++代码生成和编译工作(GacUI)
使用VisualStudio完成自动化C++代码生成和编译工作(GacUI) GacUI终于进入制作dll的阶段了.昨天上传了一个新的工程,在Vczh Library++3.0(E:\Code ...
- 【java】this用法
this代表当前类的引用对象:哪个对象调用方法,该方法内部的this就代表那个对象this关键字主要有两三个应用: (1)this调用本类中的属性,也就是类中的成员变量: class People { ...
- NAP(Network Access Protection)
- Quartz的API简介及Jobs和Trigger介绍
Quartz的API: 主要api: The key interfaces of the Quartz API are: Scheduler - the main API for interactin ...
- Vue2.0学习笔记
环境搭建 vue-cli@3 vue-cli@2.X npm i -g @vue/cli 模板语法 文本 <span>Message: {{ msg }}</span> ...
- 四、Html列表、块、布局
- 201. Spring Boot JNDI:Spring Boot中怎么玩JNDI
[视频&交流平台] àSpringBoot视频:http://t.cn/R3QepWG à SpringCloud视频:http://t.cn/R3QeRZc à Spring Boot源 ...
- Open SuSE中自定义的环境变量
针对与其它发行版本的Linux,网络上给出的添加环境变量的位置都是在/etc/profile文件中添加.在Open SuSE中也有/etc/profile文件,不过从该文件的前几行注释可以看出,官方建 ...