MySQL中Checkpoint技术
个人读书笔记,详情参考《MySQL技术内幕 Innodb存储引擎》
1,checkpoint产生的背景
数据库在发生增删查改操作的时候,都是先在buffer pool中完成的,为了提高事物操作的效率,buffer pool中修改之后的数据,并没有立即写入到磁盘,这有可能会导致内存中数据与磁盘中的数据产生不一致的情况。
事物要求之一是持久性(Durability),buffer pool与磁盘数据的不一致性的情况下发生故障,可能会导致数据无法持久化。
为了防止在内存中修改但尚未写入到磁盘的数据,在发生故障重启数据之后产生事物未持久化的情况,是通过日志(redo log)先行的方式来保证的。
redo log可以在故障重启之后实现“重做”,保证了事物的持久化的特性,但是redo log空间不可能无限制扩大,对于内存中已修改但尚未提交到磁盘的数据,也即脏页,也需要写入磁盘。
对于内存中的脏页,什么时候,什么情况下,将多少脏页写入磁盘,是由多方面因素决定的。
checkpoint的工作之一,就是对于内存中的脏页,在一定条件下将脏页刷新到磁盘。
2,checkpoint的分类
按照checkpoint刷新的方式,MySQL中的checkpoint分为两种,也即sharp checkpoint和fuzzy checkpoint。
sharp checkpoint:在关闭数据库的时候,将buffer pool中的脏页全部刷新到磁盘中。
fuzzy checkpoint:数据库正常运行时,在不同的时机,将部分脏页写入磁盘,进刷新部分脏页到磁盘,也是为了避免一次刷新全部的脏页造成的性能问题。
3 ,checkpoint发生的时机
checkpoint都是将buffer pool中的脏页刷新到磁盘,但是在不同的情况下,checkpoint会被以不同的方式触发,同时写入到磁盘的脏页的数量也不同。
3.1, Master Thread checkpoint
在Master Thread中,会以每秒或者每10秒一次的频率,将部分脏页从内存中刷新到磁盘,这个过程是异步的。正常的用户线程对数据的操作不会被阻塞。
3.2 ,FLUSH_LRU_LIST checkpoint
FLUSH_LRU_LIST checkpoint是在单独的page cleaner线程中执行的。
MySQL对缓存的管理是通过buffer pool中的LRU列表实现的,LRU 空闲列表中要保留一定数量的空闲页面,来保证buffer pool中有足够的空闲页面来相应外界对数据库的请求。
当这个空间页面数量不足的时候,发生FLUSH_LRU_LIST checkpoint。
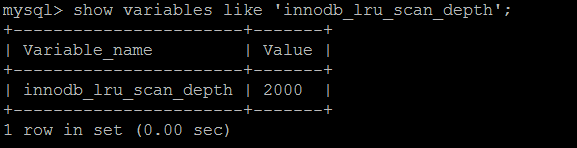
空闲页的数量由innodb_lru_scan_depth参数表来控制的,因此在空闲列表页面数量少于配置的值的时候,会发生checkpoint,剔除部分LRU列表尾端的页面。
3.3 ,Async/Sync Flush checkpoint
Async/Sync Flush checkpoint是在单独的page cleaner线程中执行的。
Async/Sync Flush checkpoint 发生在重做日志不可用的时候,将buffer pool中的一部分脏页刷新到磁盘中,在脏页写入磁盘之后,事物对应的重做日志也就可以释放了。
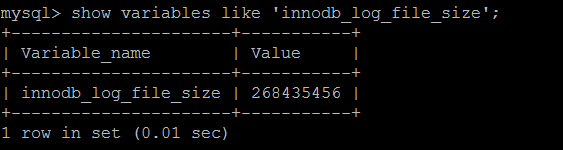
关于redo_log文件的的大小,可以通过innodb_log_file_size来配置。
对于是执行Async Flush checkpoint还是Sync Flush checkpoint,由checkpoint_age以及async_water_mark和sync_water_mark来决定。
定义:
checkpoint_age = redo_lsn-checkpoint_lsn,也即checkpoint_age等于最新的lsn减去已经刷新到磁盘的lsn的值
async_water_mark = 75%*innodb_log_file_size
sync_water_mark = 90%*innodb_log_file_size
1)当checkpoint_age<sync_water_mark的时候,无需执行Flush checkpoint。也就说,redo log剩余空间超过25%的时候,无需执行Async/Sync Flush checkpoint。
2)当async_water_mark<checkpoint_age<sync_water_mark的时候,执行Async Flush checkpoint,也就说,redo log剩余空间不足25%,但是大于10%的时候,执行Async Flush checkpoint,刷新到满足条件1
3)当checkpoint_age>sync_water_mark的时候,执行sync Flush checkpoint。也就说,redo log剩余空间不足10%的时候,执行Sync Flush checkpoint,刷新到满足条件1。
在mysql 5.6之后,不管是Async Flush checkpoint还是Sync Flush checkpoint,都不会阻塞用户的查询进程。
个人认为:
由于磁盘是一种相对较慢的存储设备,内存与磁盘的交互是一个相对较慢的过程
由于innodb_log_file_size定义的是一个相对较大的值,正常情况下,由前面两种checkpoint刷新脏页到磁盘,在前面两种checkpoint刷新脏页到磁盘之后,脏页对应的redo log空间随即释放,一般不会发生Async/Sync Flush checkpoint。同时也要意识到,为了避免频繁低发生Async/Sync Flush checkpoint,也应该将innodb_log_file_size配置的相对较大一些。
3.4, Dirty Page too much Checkpoint
Dirty Page too much Checkpoint是在Master Thread 线程中每秒一次的频率实现的。
Dirty Page too much 意味着buffer pool中的脏页过多,执行checkpoint脏页刷入磁盘,保证buffer pool中有足够的可用页面。
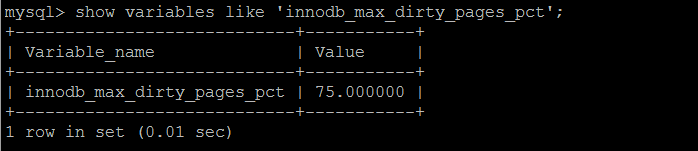
Dirty Page 由innodb_max_dirty_pages_pct配置,innodb_max_dirty_pages_pct的默认值在innodb 1.0之前是90%,之后是75%。
总结:
MySQL数据库(当然其他关系数据也有类似的机制),为了提高事物操作的效率,在事物提交之后并不会立即将修改后的数据写入磁盘,而是通过日志先行(write log ahead)的方式保证事物的持久性。
对于将事物修改的数据页面,也即脏页,通过异步的方式刷新到磁盘中,checkpoint正是实现这种异步刷新脏页到磁盘的实施者。
不同的情况下,会发生不同的checkpoint,将不同数量的脏页刷新到磁盘,从而到达管理内存(第1,2,4种checkpoint)和redo log可用空间(第3种checkpoint)的目的。
MySQL中Checkpoint技术的更多相关文章
- 携程二面:讲讲 MySQL 中的 WAL 策略和 CheckPoint 技术
前段时间我在准备暑期实习嘛,这是当时面携程的时候二面的一道问题,我一脸懵逼,赶紧道歉,不好意思不知道没了解过,面试官又解释说 redo log,我寻思着 redo log 我知道啊,WAL 是啥?给面 ...
- 分享MYSQL中的各种高可用技术(源自姜承尧大牛)
分享MYSQL中的各种高可用技术(源自姜承尧大牛) 图片和资料来源于MYSQL大牛姜承尧老师(MYSQL技术内幕作者) 姜承尧: 网易杭州研究院 技术经理 主导INNOSQL的开发 mysql高可用各 ...
- 分享MYSQL中的各种高可用技术
分享MYSQL中的各种高可用技术 图片和资料来源于姜承尧老师(MYSQL技术内幕作者) mysql高可用各个技术的比较 数据库的可靠指的是数据可靠 数据库可用指的是数据库服务可用 可靠的是数据:例如工 ...
- Django中MySQL读写分离技术
最近需要用到Django的MySQL读写分离技术,查了一些资料,把方法整理了下来. 在Django里实现对MySQL的读写分离,实际上就是将不同的读写请求按一定的规则路由到不同的数据库上(可以是不同类 ...
- 【MySQL】MySQL中针对大数据量常用技术_创建索引+缓存配置+分库分表+子查询优化(转载)
原文地址:http://blog.csdn.net/zwan0518/article/details/11972853 目录(?)[-] 一查询优化 1创建索引 2缓存的配置 3slow_query_ ...
- MySQL中的 redo 日志文件
MySQL中的 redo 日志文件 MySQL中有三种日志文件,redo log.bin log.undo log.redo log 是 存储引擎层(innodb)生成的日志,主要为了保证数据的可靠性 ...
- 转!!MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
MySQL中的存储引擎: 1.存储引擎的概念 2.查看MySQL所支持的存储引擎 3.MySQL中几种常用存储引擎的特点 4.存储引擎之间的相互转化 一.存储引擎: 1.存储引擎其实就是如何实现存储数 ...
- 【MySQL】漫谈MySQL中的事务及其实现
最近一直在做订单类的项目,使用了事务.我们的数据库选用的是MySQL,存储引擎选用innoDB,innoDB对事务有着良好的支持.这篇文章我们一起来扒一扒事务相关的知识. 为什么要有事务? 事务广泛的 ...
- MySQL表分区技术
MySQL表分区技术 MySQL有4种分区类型: 1.RANGE 分区 - 连续区间的分区 - 基于属于一个给定连续区间的列值,把多行分配给分区: 2.LIST 分区 - 离散区间的分区 - 类似于按 ...
随机推荐
- java实现四则运算应用(基于控制台)
项目地址:https://gitee.com/wxrqforever/object_oriented_exp1.git 一.需求分析: 一个基于控制台的四则运算系统,要能实现生成并计算含有真,假分数, ...
- kali安装Google浏览器之后的问题
kali中,在安装完Google浏览器后会出现点击图标却打不开的问题,解决方式如下: 2019-04-10 09:46:00
- 百度地图 JavaScript API
最近有点懒 项目结尾了 完了好长时间 没有去总结项目中的问题 想了下还是写写吧 这是一个关于百度地图的 网页展示 <!DOCTYPE html><html><head ...
- python调用mediainfo工具批量提取视频信息
写了2个脚本,分别是v1版本和v2版本 都是python调用mediainfo工具提取视频元数据信息 v1版本是使用pycharm中测试运行的,指定了视频路径 v2版本是最终交付给运营运行的,会把v2 ...
- nginx 代理flask应用的uwsgi配置
socket代理配置: 关于uwsgi的用法,请自行百度,这里只针对socket文件和端口的不同,进行单一的记录. 这种方式启动的flask应用,由于是通过socket与nginx通信的,所以必须制定 ...
- sql server 作业收缩数据库
USE[master] GO ALTER DATABASE PayFlow2 SET RECOVERY SIMPLE WITH NO_WAIT GO ALTER DATABASE PayFlow2 S ...
- python文件打开方式详解——a、a+、r+、w+区别
出处: http://blog.csdn.net/ztf312/ 第一步 排除文件打开方式错误: r只读,r+读写,不创建 w新建只写,w+新建读写,二者都会将文件内容清零 (以w方式打开,不能读出. ...
- js window.location用法
<script> //设置或获取 href 属性中跟在问号后面的部分. console.log(window.location.search)//设置或获取对象指定的文件名或路径conso ...
- Linux(CentOS-7) 下载 解压 安装 redis 操作的一些基本命令
使用xshell 连接到虚拟机,并且创建 一个redis目录:创建文件命令:mkdir 文件名ls:查看当前文件里面的所有文件 使用xftp 将下载的linux版本 reids上传动新建的redis目 ...
- mysql 5.7 修改字符编码
在my.ini文件中添加 [mysqld]character-set-server = utf8 [client]default-character-set = utf8