基于PaddlePaddle的语义匹配模型DAM,让聊天机器人实现完美回复 |
来源商业新知网,原标题:让聊天机器人完美回复 | 基于PaddlePaddle的语义匹配模型DAM
语义匹配
语义匹配是NLP的一项重要应用。无论是问答系统、对话系统还是智能客服,都可以认为是问题和回复之间的语义匹配问题。这些NLP的应用,通常以聊天机器人的形式呈现在人们面前,目标是通过对话的上下文信息,去匹配最佳的回复。
因而,让聊天机器人完美回复问题,是语义匹配的关键目标。作为国内乃至国际上领先的NLP技术团队,百度在NLP领域积极创新、锐意进取,在聊天机器人的回复选择这个关键NLP任务上,提出了效果最优的深度注意力匹配神经网络DAM,并开源了基于PaddlePaddle的模型实现。
本文对该模型的相关原理和应用加以介绍。
DAM在PaddlePaddle项目的地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/deep_attention_matching_net
关键应用—聊天机器人多轮对话的回复选择
基于检索的聊天机器人最重要的一项任务是从给定的候选回复中,选取与问题最匹配的回复。
这一项研究的关键挑战是需要去捕获对话中不同粒度的语义依赖关系,如图1中的对话示例所示,对话的上下文和候选回复之间存在不同粒度上的两种关系:
1)直接的文本相关,比如单词”packages”和”package”,或者短语”debian package manager”和”debian package manager”,他们之间直接有重叠的词汇。
2)语段之间隐式相关关系,比如回复中的单词”it”指代的是上文中的”dpkg”,回复中的”its just reassurance”对应的是”what packages are installed on my system”。
早期研究已经表明,在多轮对话中,从不同的语义粒度上捕获语段对之间的关系是选出最佳回复的关键所在。然而现有的模型更多的要么是考虑文本的相关关系,从而对于隐式相关的关系提取的还不够好,要么是使用RNN模型,在捕获多粒度语义表示上,开销又太大。面对这些挑战,百度NLP团队提出了DAM模型,用以解决多轮对话的语义匹配问题。
 △ 图1 多轮对话的示例
△ 图1 多轮对话的示例
DAM模型概览(Deep Attention Matching Network)
DAM 是一个完全基于注意力机制的神经匹配网络。DAM的动机是为了在多轮对话中,捕获不同颗粒度的对话元素中的语义依赖,从而更好得在多轮对话的上下文语境中回复。
DAM受启发于机器翻译的Transformer模型,将Transformer关键的注意力机制从两个方面进行拓展,并将其引入到一个统一的网络之中。
自注意力机制(self-attention)
从单词级的嵌入中堆叠注意力机制,逐渐捕获不同粒度的语义表示。比如对一个句子使用注意力机制,可以捕获句子内部词级别的依赖关系。这些多粒度的语义表示有助于探索上下文和回复的语义依赖关系。
互注意力机制(cross-attention)
在上下文和回复之间应用注意力机制,可以捕获不同语段对之间隐式的依赖关系,从而为文本关系提供更多的补充信息从而为多轮对话选择更好的回复。
在实践中,DAM将上下文和回复中的每句话的每一个单词当做一个语段的中心语义对待,通过堆叠注意力机制,从不同级别上丰富其语义表示,进而围绕该中心单词,生成更多高级的语段的语义表示。这样上下文和回复中的每句话都是在考虑了文本相关和依赖关系的情况下,且基于不同粒度进行匹配的。
DAM首先捕获从词级到句级的上下文和回复之间的匹配信息,然后通过卷积和最大池化操作提取最匹配的特征,最后通过单层的感知网络得到一个匹配得分。
DAM技术详解
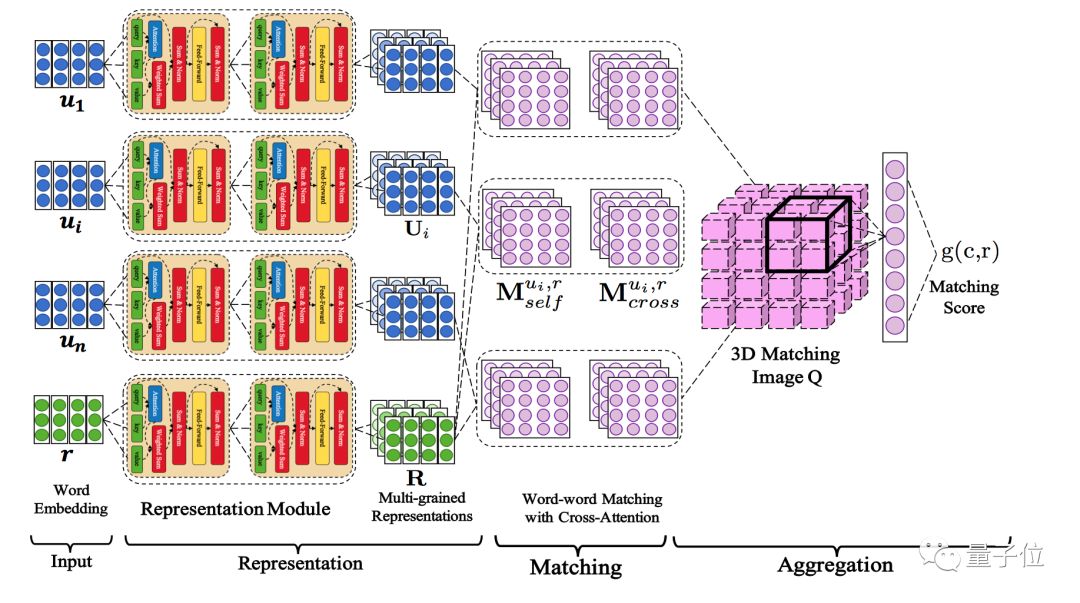 △ 图2 DAM模型网络结构
△ 图2 DAM模型网络结构
DAM模型的网络结构如图2所示。它包括表示-匹配-聚合三个主要部分,输入是对话的数据集,由上下文的文本每一句话u和回复r所对应的词嵌入组成,输出是得到一个对话中上下文与回复之间的匹配分数。
表示模块能够对输入的上下文u和回复r构建不同粒度的语义表示。通过堆叠多层相同的自注意力模块,将输入的语义词嵌入构建为更加高级的语义表示。得到语义表示之后,上下文与回复以语段-语段相似矩阵的形式互相匹配。
匹配有两种,自注意力匹配和互注意力匹配,分别可以衡量上下文与回复之间的文本关系和依赖关系。
这些匹配的分数会形成一个3D的匹配图Q,它的维度分别代表上下文中的每一句话、每句话中的每个单词以及回复中的每个单词。接着,语段对之间的匹配信息通过卷积和最大池化提取,进一步得通过单层感知网络聚合,得到匹配的分数,代表候选回复与上下文之间的匹配程度。
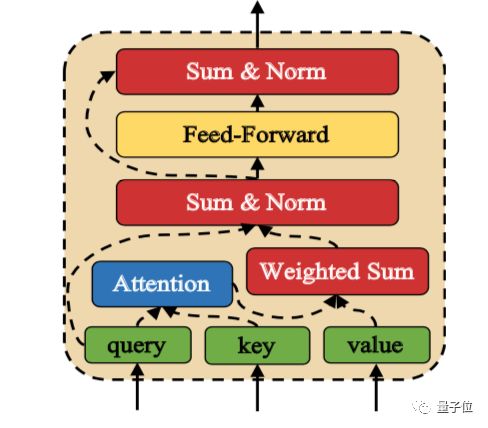
△ 图3 注意力模块
DAM网络中使用了注意力模块实现自注意力和互注意力机制,它的结构如图3所示。

该结构借鉴了Transformer模型中的注意力机制的实现。它的输入有三个部分,query语句、key语句和value语句,分别以Q、K和V表示。注意力模块会首先对query语句和key语句的每个单词进行标量点积注意力(Scaled Dot Product Attention)计算,具体计算如公式(1)和(2)所示。
算出的Vatt存储了语义信息,代表了query语句和value语句之间的相互关系。Vatt与query语句输入会相加一起,组成了一个能够代表它们联合含义的语义表示。然后通过一层标准化(Normalization)的操作,可以避免梯度消失或者爆炸。
再接着,使用Relu激活函数的前馈神经网络FFN进一步处理聚合的词嵌入,操作如公式(3)所示。
公式(3)中,x代表的是一个与query语句一样形状的2Dtensor,W1,W2,b1和b2都是要学习的参数。最后的输出还会经过一次标准化操作,从而得到最后的结果。整个注意力模块的结果由公式(4)表示。
整个注意力模块可以捕获query语句和key语句的依赖关系,利用依赖信息可以得到语义表示,再进一步的构建多粒度的语义表示。
公式(5)和(6)就是利用了注意力模块,得到了上下文和回复的多粒度语义表示信息。公式(7)得到了自注意力的匹配矩阵。公式(8)和(9)通过注意力模块得到上下文与回复之间的语义表示信息,进一步的组成互注意力的匹配矩阵。

自注意力矩阵和互注意力矩阵聚合成了一个3D匹配图Q。再通过带最大池化的3D卷积,得到匹配特征,最后通过单层感知层进行匹配分数的计算。
DAM模型在Ubuntu和豆瓣对话两个语料库上测试了多轮对话任务,如表1所示,相比其他模型获得了最优的效果。
Ubuntu语料库是英文的关于Ubuntu系统troubleshooting的多轮对话数据。它的训练集包括50万个多轮对话的上下文文本,每个对话文本带有1个人类积极回答的正例回复和1个随机采样的负例回复。
它的验证集和测试集各自包括5万个上下文文本,每个上下文文本各有1个正例回复和9个负例回复。豆瓣对话语料库是中文的关于一些开放领域的对话数据集。
它的验证集包括5万个对话实例,每个实例各有1个正例和负例回复,测试集有1万个实例,每个实例有10个候选回复。
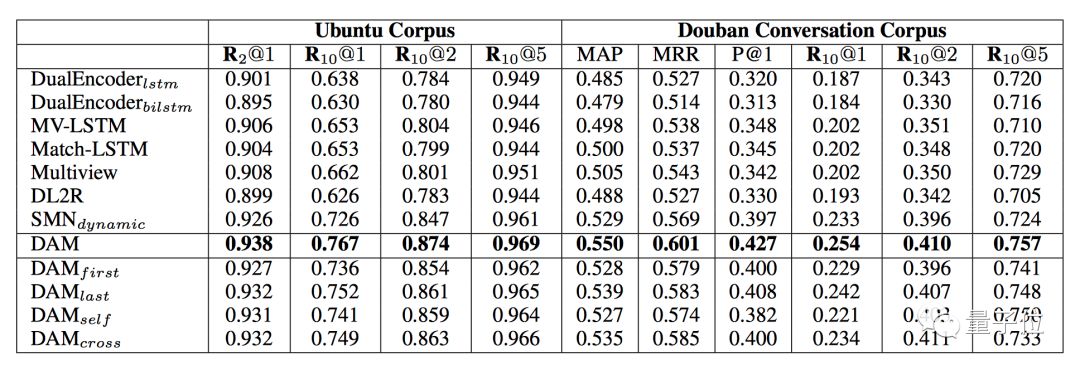 △ 表1:DAM模型的效果对比
△ 表1:DAM模型的效果对比
DAM模型PaddlePaddle实战
环境准备:首先根据项目文档要求,下载最新版本的PaddlePaddle。Python的版本要求>=2.7.3
项目的代码目录及简要说明如下:
.
├── README.md # 文档├── model.py # 模型├── train_and_evaluate.py # 训练和评估脚本├── test_and_evaluate.py # 测试和评估脚本├── ubuntu # 使用Ubuntu语料库的脚本├── Douban # 使用Douban语料库的脚本└── utils # 通用函数
下载项目以后,接下来以Ubuntu语料库应用为例:
1.进入ubuntu目录
cd ubuntu
2.下载预处理好的数据用于训练。项目提供了下载数据的脚本
sh download_data.sh
3.执行训练和评估的脚本
sh train.sh
使用如下脚本,可以了解更多关于arguments的使用说明。
python ../train_and_evaluate.py —help
默认情况下,训练是在单个的GPU上执行的,用户也可以转到多GPU模式运行。只需要将train.sh脚本中的可见设备重置一下即可。比如
export CUDA_VISIBLE_DEVICES=0,1,2,3
4.执行测试脚本
sh test.sh
类似的,用户可以很容易的利用Douban对话语料库进行实验。
传送门:
PaddlePaddle Github项目地址:
https://github.com/PaddlePaddle
DAM模型项目地址:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/deep_attention_matching_net
基于PaddlePaddle的语义匹配模型DAM,让聊天机器人实现完美回复 |的更多相关文章
- DSSM:深度语义匹配模型(及其变体CLSM、LSTM-DSSM)
导语 在NLP领域,语义相似度的计算一直是个难题:搜索场景下Query和Doc的语义相似度.feeds场景下Doc和Doc的语义相似度.机器翻译场景下A句子和B句子的语义相似度等等.本文通过介绍DSS ...
- Mianbot:基于向量匹配的情境式聊天机器人
Mianbot是采用样板与检索式模型搭建的聊天机器人,目前有两种产生回覆的方式,专案仍在开发中:) 其一(左图)是以词向量进行短语分类,针对分类的目标模组实现特征抽取与记忆回覆功能,以进行多轮对话,匹 ...
- 深度学习项目——基于循环神经网络(RNN)的智能聊天机器人系统
基于循环神经网络(RNN)的智能聊天机器人系统 本设计研究智能聊天机器人技术,基于循环神经网络构建了一套智能聊天机器人系统,系统将由以下几个部分构成:制作问答聊天数据集.RNN神经网络搭建.seq2s ...
- 深度语义匹配模型-DSSM 及其变种
转自:http://ju.outofmemory.cn/entry/316660 感谢分享~ DSSM这篇paper发表在cikm2013,短小但是精炼,值得记录一下 ps:后来跟了几篇dssm的pa ...
- 基于海明距离的加权平均值人职匹配模型(Sqlserver2014/16内存表实现)
最近给某大学网站制作一个功能,需要给全校所有的学生提供就业单位发布职位的自动匹配,学生登陆就业网,就可以查看适合自己的职位,进而可以在线投递. 全校有几万名学生,注册企业发布的职位也有上万,如何在很短 ...
- ACM MM | 中山大学等提出HSE:基于层次语义嵌入模型的精细化物体分类
细粒度识别一般需要模型识别非常精细的子类别,它基本上就是同时使用图像全局信息和局部信息的分类任务.在本论文中,研究者们提出了一种新型层次语义框架,其自顶向下地由全局图像关注局部特征或更具判别性的区域. ...
- 提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件 11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解 ...
- 详解Linux2.6内核中基于platform机制的驱动模型 (经典)
[摘要]本文以Linux 2.6.25 内核为例,分析了基于platform总线的驱动模型.首先介绍了Platform总线的基本概念,接着介绍了platform device和platform dri ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
随机推荐
- Spell checker using hash table
Problem description Given a text file, show the spell errors from it. (https://www.andrew.cmu.edu/c ...
- Git源码安装 Linux指定安装目录
1.安装依赖包 $ yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel 2.下载最新版源码包https: ...
- 《DSP using MATLAB》Problem 7.13
代码: %% ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ %% Output In ...
- 使用Blend设计出符合效果的WPF界面
之前不会用blend,感觉好难的,但美工给出的效果自己有没办法实现,所以研究了一下blend,感觉没有想象中的那么难 废话不多说,开始界面设计 今天拿到美工给的一个界面效果图 这个界面说实话,还可以吧 ...
- kali 2018.2版本运行破解版burpsuite时候的问题。
最近重装了kali虚拟机,装完之后把burp拷到里面发现运行不了了,折腾了下才解决,问题主要是由于java环境造成的. 系统默认是以java10运行burp的,但是java10好像是不支持 -X ...
- 在 sql 语句出现 warning 之后,立刻执行 `show warnings;` 就可以看到 warning 提示信息
在 sql 语句出现 warning 之后,立刻执行 show warnings; 就可以看到 warning 提示信息
- JavaBasic_正则表达式
就是符合一定规则的字符串 规则字符在java.util.regex.Pattern类中 字符转义\. 匹配.字符\* 匹配*字符\\ 匹配\字符\n 新行(换行)符 ('\u000A') \r 回车符 ...
- 【C++】vector用法详解
转自:https://blog.csdn.net/fanyun_01/article/details/56842637#commentBox 一.简介 C++ vector类为内置数组提供了一种替代表 ...
- oracle user_tables没有新创建的表的问题
oracle 新创建表后,在user_tables没有,在user_tab_columns也没有,暂时未找到办法
- TensorFlow 安装报错的解决办法(安装1.5版本)
1.安装Anaconda 百度下载windows版本,一路点下一步,安装好了Anaconda,自带python3.6.6. 2.安装TensorFlow (1)打开Anaconda Prompt,输入 ...