整理python小爬虫
编码使我快乐!!!
我也不知道为什么,遇到自己喜欢的事情,就越想做下去,可以一个月不出门,但是不能一天没有电脑
掌握程度:对python有了一个更清晰的认识,自动化运维,也许可以用python实现呢,加油
实现功能:
爬取响应的网页,并且存入本地文件和DB
本地文件:

DB:
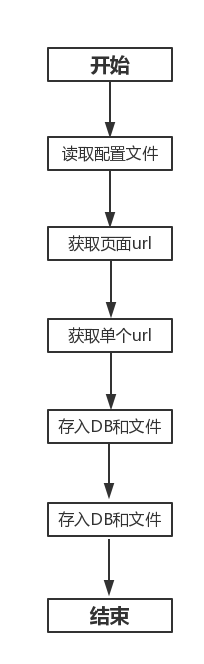
整体逻辑:
1.读取配置文件
def ReadLocalFiles() :
#定义字典用于存储conf中的变量与值
returndict={}
#定义变量用于存储行数
linenumber = 0
#以只读方式获取文件内容,因为文件需要放在crontab中,故需写全路径
localfiles = open(r'/root/python-script/geturl/main.conf')
#获取文件所有值,以list的方式存储在readfilelines中
readfilelines = localfiles.readlines()
#定义for用于循环list进行抓值
for line in readfilelines :
#使行数自增1,用于报错显示
linenumber = linenumber + 1
#利用rstrip进行去除多余的空格
line = line.rstrip()
#判断如果文件开头为#,则continue继续循环
if line.startswith('#') :
continue
#判断如果line的长度为0,则continue继续循环
elif len(line) == 0 :
continue
#如果依上条件均不满足
else:
#执行try语句,如果有异常,使之在控制范围内
try:
returndict[line.split('=')[0]] = line.split('=')[1]
#抛出异常
except:
#打印错误语句
print (time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+"line %d %s error,please check" % (linenumber,line))
#
localfiles.close()
#使程序异常退出
sys.exit(-1)
#返回字典
localfiles.close()
return returndict
2.清除已经下载的文件内容
def DeleteHisFiles(update_file):
#判断是否存在update_file这个文件
if os.path.isfile(update_file):
try:
#以可读可写方式打开文件
download_files = open(update_file,'r+')
#清除文件内容
download_files.truncate()
#关闭文件
download_files.close()
except:
#报错,清除失败
print (time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+"Truncate " + update_file + "error , please check it")
#如果文件在路径下不存在
else :
#新建文件
print (time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))+"Build New downfiles ok")
3.检测网址是否有更新
def DealwithURL(url):
#获取url的内容传入r
r = requests.get(url)
#定义需要查找的正则表达式的值
pattern = re.compile('<meta http-equiv="refresh" content="0.1;url=')
#在r.text中查找pattern的值
findurl=re.findall(pattern,r.text)
#如果有找到值
if findurl:
#定义需要查找正则表达式的值,此值为去url=后面的内容直至"结尾
pattern = re.compile('<meta http-equiv="refresh" content="0.1;url=(.*)"')
#在r.text中查找pattern的值,并将下标为0的值赋值给transferurl
transferurl = re.findall(pattern,r.text)[0]
#返回transferurl的值
return transferurl
else :
#否则返回true
return True
4.获取更新后的网址
def GetNewURL(url):
#获取url的内容传入r
r = requests.get(url)
#编码为utf-8
r.encoding='utf-8'
#定义需要查找的正则表达式的值,以alert开头,以">结尾的值
pattern = re.compile('alert(.*)">')
#在r.text中查找pattern的值
findurl=re.findall(pattern,r.text)
#将传入的值修改为str格式
findurl_str = (" ".join(findurl))
#1.返回findurl_str以空格分割后的下标为1的值
#2.返回第1步的下标为0的值
#3.返回第2步的下标为2的值至最后
return (findurl_str.split(' ',1)[0][2:])
5.存储新的网址进本地配置文件
def SaveLocalUrl(untreatedurl,treatedurl):
#如果两个值相等
if untreatedurl == treatedurl :
pass
else :
#执行try语句,如果有异常,使之在控制范围内
try:
#以只读的方式打开文件
fileconf = open(r'/root/python-script/geturl/main.conf','r')
#设置rewritestr为空
rewritestr = ""
#执行fileconf的for循环
for readline in fileconf:
#如果在readline中有搜索到untreatedurl
if re.search(untreatedurl,readline):
#在readline中将untreatedurl值替换为treatedurl值
readline = re.sub(untreatedurl,treatedurl,readline)
#试rewritestr加上新的readline
rewritestr = rewritestr + readline
else :
#否则的话,也使rewritestr加上新的readline
rewritestr = rewritestr + readline
#读入完毕将文件关闭
fileconf.close()
#以只写的方式打开文件
fileconf = open(r'/root/python-script/geturl/main.conf','w')
#将rewritestr写入文件
fileconf.write(rewritestr)
#关闭文件
fileconf.close()
except:
#打印异常
print ("get new url but open files ng write to logs,please check main.conf")
6.随机获取一个网页并且取得总页数
def GetTitleInfo(url,down_page,update_file,headers):
#定义title的值,随机从1——8中抽取一个出来
title = '/list/'+str(random.randint(1,8))
#定义titleurl的值,为url+title+.html
titleurl = url + title + '.html'
#获取当前的url内容并返回给r
r = requests.get(titleurl)
#设置r的编码为当前页面的编码
r.encoding = chardet.detect(r.content)['encoding']
##定义需要查找的正则表达式的值,以' 当前:.*'开头,以'页 '结尾的值
pattern = re.compile(' 当前:.*/(.*)页 ')
#在r.text中查找符合pattern的值
getpagenumber = re.findall(pattern,r.text)
#将getpagenumber值转换为str格式
getpagenumber = (" ".join(getpagenumber))
GetListURLinfo(url , title , int(getpagenumber) , int(down_page),update_file,headers)
7.Download详细URL
def GetListURLinfo(sourceurl , title , getpagenumber , total,update_file,headers):
#将total的值控制在范围内
if total >= 100:
total = 100
if total <= 1:
total = 2
#将total的值赋值给getpagenumber
getpagenumber = total
#定义for循环,循环次数为total的总数
for number in range(0,total) :
try:
#定义信号值
signal.signal(signal.SIGALRM,handler)
#设置alarm为3,若超过3秒,则被抛送异常
signal.alarm(3)
#定义url的值为小于getpagenumber的随机页面
url = sourceurl + title + '-' + str(random.randint(1,getpagenumber)) + '.html'
#获取url的内容,并且传值给r
r = requests.get(url)
#定义需要查找的正则表达式的值,以<div class="info"><h2>开头,以</a><em></em></h2>结尾的值
pattern = re.compile('<div class="info"><h2>(.*)</a><em></em></h2>')
#设置编码为页面编码
r.encoding = chardet.detect(r.content)['encoding']
#在r.text中查找符合pattern的值
allurl = re.findall(pattern,r.text)
#为allurl定义for循环
for lineurl in allurl:
try:
#定义信号值
signal.signal(signal.SIGALRM,handler)
#设置alarm为3,若超过3秒,则被抛送异常
signal.alarm(3)
#定义需要查找的正则表达式的值,以<a href="开头,以" title结尾的值
pattern = re.compile('<a href="(.*)" title')
#在r.text中查找符合pattern的值并且赋值给titleurl
titleurl = re.findall(pattern,lineurl)
#定义需要查找的正则表达式的值,以<a href="开头,以” target=结尾的值
pattern = re.compile('title="(.*)" target=')
#在r.text中查找符合pattern的值并且赋值给titlename
titlename = re.findall(pattern,lineurl)
signal.alarm(0)
#超时抛出异常
except AssertionError:
print (lineurl,titlename , "Timeout Error: the cmd 10s have not finished")
continue
except AssertionError:
print ("GetlistURL Error Continue")
continue
8.获取每个url的ed2k地址
def GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers):
#将downurlstr,downnamestr转换str类型
downurlstr = (" ".join(titleurl))
downnamestr = (" ".join(titlename))
#获取url的内容,并且传值给r
r = requests.get((sourceurl+downurlstr))
#定义需要查找的正则表达式的值,以autocomplete="on">开头,以/</textarea></div>结尾的值
pattern = re.compile('autocomplete="on">(.*)/</textarea></div>')
#在r.text中查找符合pattern的值并且赋值给downurled2k
downurled2k = re.findall(pattern,r.text)
#将downurled2k的值修改为str并且赋值给downurled2kstr
downurled2kstr = (" ".join(downurled2k))
WriteLocalDownloadURL(update_file , downurled2kstr,titlename)
#输出downnamestr 和 downurled2kstr
print (downnamestr , downurled2kstr)
#定义savedburl为sourceurl + downurlstr的值
savedburl = sourceurl + downurlstr
SaveDB(time.strftime('%Y-%m-%d %H:%M',time.localtime(time.time())),titlename[0],downurled2kstr,savedburl)
# print (time.strftime('%Y-%m-%d %H:%M',time.localtime(time.time())))
9.将文件内容写进本地
def WriteLocalDownloadURL(downfile,listfile):
#以追加的方式打开downfile文件
urlfile = open(downfile,'a+')
#定义循环语句
for line in listfile :
urlfile.write(line+'\n')
#关闭文件
urlfile.close()
10.将文件内容写进DB
def SaveDB(nowdate,tilename,downurl,savedburl):
#获取游标
cursor = db.cursor()
#定义select查询语句
sql = "select count(nurl) from downurl where nurl = '%s';" % (downurl)
cursor.execute(sql)
#获取执行的结果
data = cursor.fetchone()
#判断结果是否为‘0’
' == str(data[0]):
#定义insert插入语句
sql = "insert into downurl values ('%s','%s','%s','%s');" % (nowdate,tilename,savedburl,downurl)
#定义try语句
try:
#执行sql语句
cursor.execute(sql)
#执行commit语句
db.commit()
except:
#否则执行rollback语句
db.rollback()
代码综合:
root@Linux:~/python-script/geturl # cat main.py
#!/usr/bin/python3
import requests
import re
import chardet
import random
import signal
import time
import os
import sys
import pymysql
def DealwithURL(url):
r = requests.get(url)
pattern = re.compile('<meta http-equiv="refresh" content="0.1;url=')
findurl=re.findall(pattern,r.text)
if findurl:
pattern = re.compile('<meta http-equiv="refresh" content="0.1;url=(.*)"')
transferurl = re.findall(pattern,r.text)[0]
return transferurl
else :
return True
def GetNewURL(url):
r = requests.get(url)
r.encoding='utf-8'
pattern = re.compile('alert(.*)">')
findurl=re.findall(pattern,r.text)
findurl_str = (" ".join(findurl))
return (findurl_str.split(' ',1)[0][2:])
def gettrueurl(url):
if DealwithURL(url)==True:
return url
else :
return GetNewURL(DealwithURL(url))
def SaveLocalUrl(untreatedurl,treatedurl):
if untreatedurl == treatedurl :
pass
else :
try:
fileconf = open(r'/root/python-script/geturl/main.conf','r')
rewritestr = ""
for readline in fileconf:
if re.search(untreatedurl,readline):
readline = re.sub(untreatedurl,treatedurl,readline)
rewritestr = rewritestr + readline
else :
rewritestr = rewritestr + readline
fileconf.close()
fileconf = open(r'/root/python-script/geturl/main.conf','w')
fileconf.write(rewritestr)
fileconf.close()
except:
print ("get new url but open files ng write to logs")
def handler(signum,frame):
raise AssertionError
def SaveDB(nowdate,tilename,downurl,savedburl):
cursor = db.cursor()
sql = "select count(nurl) from downurl where nurl = '%s';" % (downurl)
cursor.execute(sql)
data = cursor.fetchone()
' == str(data[0]):
sql = "insert into downurl values ('%s','%s','%s','%s');" % (nowdate,tilename,savedburl,downurl)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
def WriteLocalDownloadURL(downfile,listfile):
urlfile = open(downfile,'a+')
for line in listfile :
urlfile.write(line+'\n')
urlfile.close()
def GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers,enabledb):
downurlstr = (" ".join(titleurl))
downnamestr = (" ".join(titlename))
r = requests.get((sourceurl+downurlstr))
pattern = re.compile('autocomplete="on">(.*)/</textarea></div>')
downurled2k = re.findall(pattern,r.text)
downurled2kstr = (" ".join(downurled2k))
print (downnamestr , downurled2kstr)
if 1 == enabledb :
savedburl = sourceurl + downurlstr
SaveDB(time.strftime('%Y-%m-%d %H:%M',time.localtime(time.time())),titlename[0],downurled2kstr,savedburl)
returnstr = titlename[0]+" "+downurled2kstr
return returnstr
def ReadLocalFiles() :
returndict={}
linenumber = 0
localfiles = open(r'/root/python-script/geturl/main.conf')
readfilelines = localfiles.readlines()
for line in readfilelines :
linenumber = linenumber + 1
line = line.rstrip()
if line.startswith('#') :
continue
elif len(line) == 0 :
continue
else:
try:
returndict[line.split('=')[0]] = line.split('=')[1]
except:
print ("line %d %s error,please check" % (linenumber,line))
sys.exit(-1)
return returndict
def GetListURLinfo(sourceurl , title , getpagenumber , total,update_file,headers,enablewritefile,enabledb):
returnwriteurl = []
if total >= 100:
total = 100
if total <= 1:
total = 2
getpagenumber = total
for number in range(0,total) :
try:
signal.signal(signal.SIGALRM,handler)
signal.alarm(3)
url = sourceurl + title + '-' + str(random.randint(1,getpagenumber)) + '.html'
r = requests.get(url)
pattern = re.compile('<div class="info"><h2>(.*)</a><em></em></h2>')
r.encoding = chardet.detect(r.content)['encoding']
allurl = re.findall(pattern,r.text)
for lineurl in allurl:
try:
signal.signal(signal.SIGALRM,handler)
signal.alarm(3)
pattern = re.compile('<a href="(.*)" title')
titleurl = re.findall(pattern,lineurl)
pattern = re.compile('title="(.*)" target=')
titlename = re.findall(pattern,lineurl)
returnwriteurl.append(GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers,enabledb))
signal.alarm(0)
except AssertionError:
print (lineurl,titlename , "Timeout Error: the cmd 10s have not finished")
continue
except AssertionError:
print ("GetlistURL Error Continue")
continue
if 1 == enablewritefile:
WriteLocalDownloadURL(update_file,returnwriteurl)
def GetTitleInfo(url,down_page,update_file,headers,savelocalfileenable,savedbenable):
title = '/list/'+str(random.randint(1,8))
titleurl = url + title + '.html'
r = requests.get(titleurl)
r.encoding = chardet.detect(r.content)['encoding']
pattern = re.compile(' 当前:.*/(.*)页 ')
getpagenumber = re.findall(pattern,r.text)
getpagenumber = (" ".join(getpagenumber))
GetListURLinfo(url , title , getpagenumber , down_page,update_file,headers,int(savelocalfileenable),int(savedbenable))
def write_logs(time,logs):
loginfo = str(time)+logs
try:
logfile = open(r'logs','a+')
logfile.write(loginfo)
logfile.close()
except:
print ("Write logs error,code:154")
def DeleteHisFiles(update_file):
if os.path.isfile(update_file):
try:
download_files = open(update_file,'r+')
download_files.truncate()
download_files.close()
except:
print ("Delete " + update_file + "Error --code:166")
else :
print ("Build New downfiles")
def main():
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome","Accept": "text/html,application/xhtml+xml,application/xml; q=0.9,image/webp,*/*;q=0.8"}
readconf = ReadLocalFiles()
try:
file_url = readconf['url']
down_page = readconf['download_page']
savelocalfileenable = readconf['savelocalfileenable']
savedbenable = readconf['savedbenable']
if 1 == int(savelocalfileenable) :
update_file = readconf['download_local_files']
if 1 == int(savedbenable) :
dbhost = readconf['dbhost']
dbport = readconf['dbport']
dbuser = readconf['dbuser']
dbpasswd = readconf['dbpasswd']
dbschema = readconf['dbschema']
dbcharset = readconf['dbcharset']
except:
print ("Get local conf error,please check url or down_page conf")
sys.exit(-1)
if 1 == int(savelocalfileenable) :
DeleteHisFiles(update_file)
untreatedurl = file_url
treatedurl = gettrueurl(untreatedurl)
SaveLocalUrl(untreatedurl,treatedurl)
url = treatedurl
if 1 == int(savedbenable):
global db
# dbconnect ='''
# host='localhost',port=3306,user='root',passwd='flzx3QC#',db='downpage',charset='utf8'
# '''
db = pymysql.connect(host='localhost',port=3306,user='root',passwd='flzx3QC#',db='downpage',charset='utf8')
# print (dbconnect)
# db = pymysql.connect(dbconnect)
else:
db = ''
if 1 == int(savelocalfileenable) or 0 == int(savelocalfileenable):
GetTitleInfo(url,int(down_page),update_file,headers,int(savelocalfileenable),int(savedbenable))
db.close()
if __name__=="__main__":
main()
root@Linux:~/python-script/geturl #
End
整理python小爬虫的更多相关文章
- python小爬虫练手
一个人无聊,写了个小爬虫爬取不可描述图片.... 代码太短,就暂时先往这里贴一下做备份吧. 注:这是很严肃的技术研究,当然爬下来的图片我会带着批判性的眼光审查一遍的.... :) #! /usr/ ...
- 【现学现卖】python小爬虫
1.给小表弟汇总一个院校列表,想来想去可以写一个小爬虫爬下来方便些,所以就看了看怎么用python写,到了基本能用的程度,没有什么特别的技巧,大多都是百度搜的,遇事不决问百度啦 2.基本流程就是: 用 ...
- Python 小爬虫流程总结
接触Python3一个月了,在此分享一下知识点,也算是温故而知新了. 接触python之前是做前端的.一直希望接触面能深一点.因工作需求开始学python,几乎做的都是爬虫..第一个demo就是爬取X ...
- Python小爬虫-自动下载三亿文库文档
新手学python,写了一个抓取网页后自动下载文档的脚本,和大家分享. 首先我们打开三亿文库下载栏目的网址,比如专业资料(IT/计算机/互联网)http://3y.uu456.com/bl-197?o ...
- 第一个Python小爬虫
这个爬虫是参考http://python.jobbole.com/81353/这篇文章写的 这篇文章可能年代过于久远,所以有些代码会报错,然后我自己稍微修改了一下,增加了一个getContentAll ...
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
- python小爬虫【1】
爬取百度贴吧的图片 分析贴吧源代码,图片所在位置是:<img class="BDE_Image" src=“........jpg” pic_ext..... 所以正则匹配是 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- Python小爬虫练习
# coding: utf-8 __author__ = 'zhangcx' from urllib3 import PoolManager import codecs import json cla ...
随机推荐
- postgresql数据库备份
一.工具备份数据 打开windows下的命令窗口:开始->cmd->安装数据库的目录->进入bin目录: 导出命令:pg_dump –h localhost –U postgres ...
- LVM逻辑卷疑问?
创建完逻辑卷后,删除以/dev/vdb1和/dev/vdb2为基础的分区后,逻辑卷依然生效???
- 4-29 c语言之栈,队列,双向链表
今天学习了数据结构中栈,队列的知识 相对于单链表来说,栈和队列就是添加的方式不同,队列就相当于排队,先排队的先出来(FIFO),而栈就相当于弹夹,先压进去的子弹后出来(FILO). 首先看一下栈(St ...
- CentOS(十二)--crontab命令的使用方法
crontab命令常见于Unix和Linux的操作系统之中,用于设置周期性被执行的指令.该命令从标准输入设备读取指令,并将其存放于"crontab"文件中,以供之后读取和执行. 在 ...
- EF 6.x实现dynamic动态查询
利用SqlQuery实现动态查询 public static IEnumerable<dynamic> SqlQueryDynamic(this DbContext db, string ...
- Nginx隐藏标识以及其版本号
1.隐藏版本号 curl Nginx服务器时,有这么一行Server: nginx,说明我用的是 Nginx 服务器,但并没有具体的版本号.由于某些 Nginx 漏洞只存在于特定的版本,隐藏版本号可以 ...
- spring mvc返回json格式和json字符串
首先有必要说一下,json和json字符串是不一样的,后者是一个字符串.而json是一个对象 当然如果调用位置是后台程序这几乎没有区别,因为在后台,无论什么格式数据,都是从响应流中读取字符串. 但是在 ...
- 在chrome console添加jQuery支持
有时候想在chrome console使用jq,那么下面这段代码就可以完美解决问题了. var script = document.createElement('script');script.src ...
- 吴裕雄 python深度学习与实践(12)
import tensorflow as tf q = tf.FIFOQueue(,"float32") counter = tf.Variable(0.0) add_op = t ...
- Github(远程仓库) 2
远程仓库之前就添加好了 今天弄了简单的查看远程库,提取远程库,在线修改以及本地更新修改,推送到远程仓库,删除远程仓库,参考http://www.runoob.com/git/git-remote-re ...