requests+lxml+xpath爬取电影天堂
1.导入相应的包
import requests
from lxml import etree
2.原始ur
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
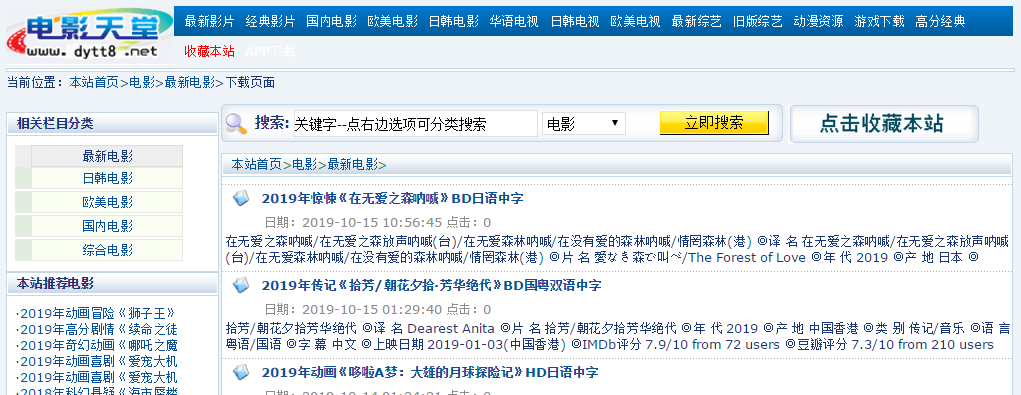
我们要爬取的是最新电影,在该界面中,我们发现,具体的信息存储在每个名字的链接中,因此我们要获取所有电影的链接才能得到电影的信息。同时我们观察url,发现
list_23_1,最后的1是页面位于第几页。右键点击其中一个电影的名字-检查。

我们发现,其部分连接位于具有class="tbspan"的table的<b>中,首先建立一个函数,用来得到所有的链接:
#用于补全url
base_url="https://www.dytt8.net"
def get_domain_urls(url):
response=requests.get(url=url,headers=headers)
text=response.text
html=etree.HTML(text)
#找到具有class="tbspan"的table下的所有a下面的href里面的值
detail_urls=html.xpath("//table[@class='tbspan']//a/@href")
#将url进行补全
detail_urls=map(lambda url:base_url+url,detail_urls)
return detail_urls
我们输出第1页中的所有url结果:
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
for i in get_domain_urls(url):
print(i)
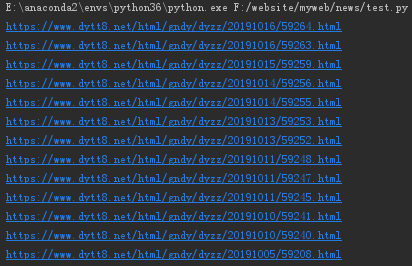
我们随便进入第一个链接:

按下F12,发现这些信息基本上都在div id="Zoom"中,接下来我们就可以对该界面进行解析。

def parse_detail_page(url):
movie={}
response=requests.get(url,headers=headers)
text=response.content.decode("GBK")
html=etree.HTML(text)
zoom=html.xpath("//div[@id='Zoom']")[0]
infos=zoom.xpath("//text()")
def parse_info(info,rule):
return info.replace(rule,"").lstrip()
for k,v in enumerate(infos):
if v.startswith("◎译 名"):
v=parse_info(v,"◎译 名").split("/")[0]
movie["name"]=v
elif v.startswith("◎产 地"):
v=parse_info(v,"◎产 地")
movie["country"]=v
elif v.startswith("◎类 别"):
v=parse_info(v,"◎类 别")
movie["category"]=v
elif v.startswith("◎豆瓣评分"):
v=parse_info(v,"◎豆瓣评分").split("/")[0]
movie["douban"]=v
elif v.startswith("◎导 演"):
v=parse_info(v,"◎导 演")
movie["director"]=v
elif v.startswith("◎主 演"):
v=parse_info(v,"◎主 演")
actors=[v]
for x in range(k+1,len(infos)):
actor=infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie["actors"]=actors
elif v.startswith("◎简 介"):
profile=""
for x in range(k+1,len(infos)):
tmp=infos[x].strip()
if tmp.startswith("【下载地址】"):
break
else:
profile=profile+tmp
movie["profile"]=profile
down_url=html.xpath("//td[@bgcolor='#fdfddf']/a/@href")
movie["down_url"]=down_url
return movie
最后将这两个整合进一个爬虫中:
def spider():
domain_url="https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html"
movies=[]
for i in range(1,2):
page=str(i)
url=domain_url.format(page)
detail_urls=get_domain_urls(url)
for detail_url in detail_urls:
movie = parse_detail_page(detail_url)
movies.append(movie)
print(movies)
运行爬虫,得到以下结果(在Json查看器中进行格式化):
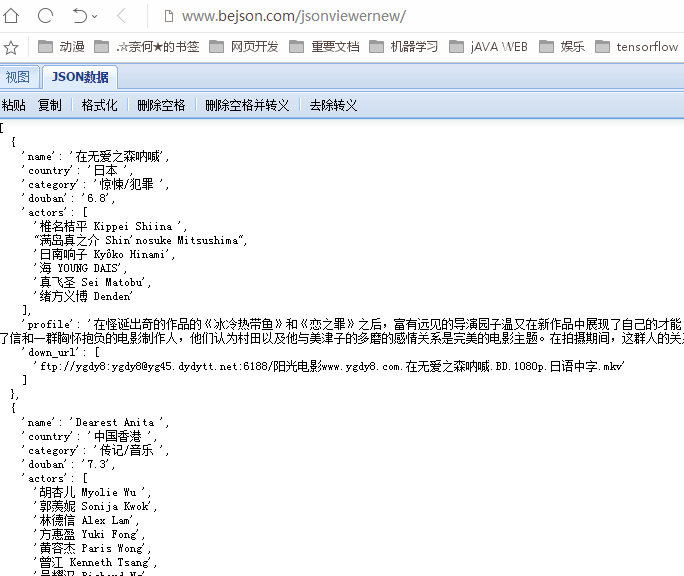
至此,一个简单的电影爬虫就完成了。
requests+lxml+xpath爬取电影天堂的更多相关文章
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- scrapy框架用CrawlSpider类爬取电影天堂.
本文使用CrawlSpider方法爬取电影天堂网站内国内电影分类下的所有电影的名称和下载地址 CrawlSpider其实就是Spider的一个子类. CrawlSpider功能更加强大(链接提取器,规 ...
- Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求 一位高人曾经说过,想爬取数据,要先分析网站 今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了. 这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽 ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- requests+BeautifulSoup | 爬取电影天堂全站电影资源
import requests import urllib.request as ur from bs4 import BeautifulSoup import csv import threadin ...
随机推荐
- Spring boot 官网学习笔记 - Spring Boot CLI 入门案例
安装CLI https://repo.spring.io/release/org/springframework/boot/spring-boot-cli/2.1.1.RELEASE/spring-b ...
- python自动化测试三部曲之untitest框架
终于等到十一,有时间写博客了,准备利用十一这几天的假期把这个系列的博客写完 该系列文章本人准备写三篇博客 第一篇:介绍python自动化测试框架unittest 第二篇:介绍django框架+requ ...
- Flask基础(03)-->创建第一个Flask程序
# 导入Flask from flask import Flask # 创建Flask的应用程序 # 参数__name__指的是Flask所对应的模块,其决定静态文件从哪个地方开始寻找 app = F ...
- Web调用Linux客户端remmina运维
相信你遇到过这样的场景,在浏览器网页中点击QQ图标咨询,就能唤起本机的装的qq或tim,下载百度网盘的资源的时候,点击链接浏览器会启动本地百度云进行下载. 最近因为项目需要,也要实现类似的操作,不 ...
- Angular.js 入门(一)
最近在学习angular.js,为此方便加深对angular.js前端框架的理解,因此写下这篇angular.js入门 首先介绍下什么是angular.js? AngularJS 是一个 JavaSc ...
- .NET Core使用gRPC打造服务间通信基础设施
一.什么是RPC rpc(远程过程调用)是一个古老而新颖的名词,他几乎与http协议同时或更早诞生,也是互联网数据传输过程中非常重要的传输机制. 利用这种传输机制,不同进程(或服务)间像调用本地进程中 ...
- 安装高可用Hadoop生态 (四) 安装Spark
4. 安装Spark 4.1. 准备目录 -bin-without-hadoop.tgz -C /opt/cloud/packages/ -bin-without-hadoop /opt/clo ...
- 2.1实现简单基础的vector
2.1实现简单基础的vector 1.设计API 我们参考下C++ <std> 库中的vector, vector中的api很多,所以我们把里面用的频率很高的函数实现; 1.1 new&a ...
- Map集合(双列集合)
Map集合(双列集合)Map集合是键值对集合. 它的元素是由两个值组成的,元素的格式是:key=value. Map集合形式:{key1=value1 , key2=value2 , key3=val ...
- LRU算法实现,HashMap与LinkedHashMap源码的部分总结
关于HashMap与LinkedHashMap源码的一些总结 JDK1.8之后的HashMap底层结构中,在数组(Node<K,V> table)长度大于64的时候且链表(依然是Node) ...