Chapter 04—Basic Data Management
1. 创建新的变量
variable<-expression
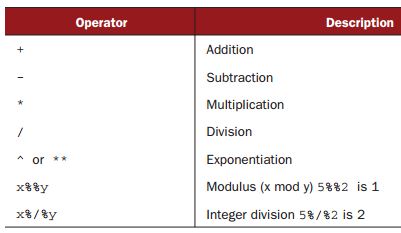
expression:包含一组大量的操作符和函数。常用的算术操作符如下表:
例1:根据已知变量,创建新变量的三种途径
> mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,2,8))
> mydata$sumx<-mydata$x1+mydata$x2
> mydata$meanx<-(mydata$x1+mydata$x2)/2
>
> attach(mydata)
> mydata$sumx<-x1+x2
> mydata$meanx<-(x1+x2)/2
> detach(mydata)
> mydata$sumx
[1] 5 6 8 12
> mydata$meanx
[1] 2.5 3.0 4.0 6.0
>
> mydata<-transform(mydata,sumx=x1+x2,meanx=(x1+x2)/2)
> mydata$sumx
[1] 5 6 8 12
> mydata$meanx
[1] 2.5 3.0 4.0 6.0 注意:要明确表明变量x1和x2都是来自数据框mydata的。
2. 记录变量
为了便于记录变量,可以使用R的逻辑操作符,主要的逻辑操作符如下表:

within()函数类似于with()函数,但是允许对数据帧(data frame)进行修改。
例2:within()的使用
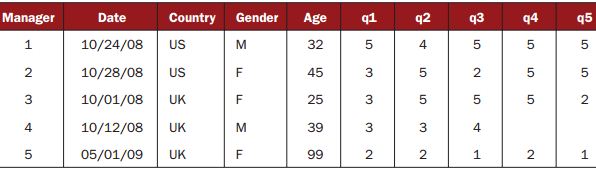
>
> manager<-c(1,2,3,4,5)
> date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
> country<-c("US","US","UK","UK","UK")
> gender<-c("M","F","F","M","F")
> age<-c(32,45,25,39,99)
> q1<-c(5,3,3,3,2)
> q2<-c(4,5,5,3,2)
> q3<-c(5,2,5,4,1)
> q4<-c(5,5,5,NA,2)
> q5<-c(5,5,2,NA,1)
> leadership<-data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringAsFactors=FALSE)
>
> leadership<-within(leadership,{agecat<-NA
+ agecat[age>75]<-"elder"
+ agecat[age>=55&age<=75]<-"middle age"
+ agecat[age<55]<-"young"})
>
3. 重命名变量
rename()函数:为变量选择名字。
rename(dataframe,c(oldname="newname",oldname="newname",...))
例03:使用fix()函数,对变量重命名。

例04:使用renames()函数,对变量重命名。
> install.packages("reshape")
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/reshape_0.8.4.zip'
Content type 'application/zip' length 124890 bytes (121 Kb)
opened URL
downloaded 121 Kb
package ‘reshape’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\seven-wang\AppData\Local\Temp\RtmpIPKmp5\downloaded_packages
> library(reshape)
载入需要的程辑包:plyr
载入程辑包:‘reshape’
下列对象被屏蔽了from ‘package:plyr’:
rename, round_any
> leadership<-rename(leadership,c(manager="managerID",date="testDate"))
> leadership
managerID testDate country gender age item1 item2 item3 item4 item5 stringAsFactors agecat
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE young
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE young
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE young
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE young
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE elder
注意:reshape包不在RStudio中,需使用install.packages()来自动安装。
例05:names()的使用:替换名字和显示名字。
> names(leadership)
[1] "managerID" "date" "country" "gender" "age" "q1"
[7] "q2" "q3" "q4" "q5" "stringAsFactors" "agecat"
> names(leadership)[2]<-"testDate"
> names(leadership)
[1] "managerID" "testDate" "country" "gender" "age"
[6] "q1" "q2" "q3" "q4" "q5"
[11] "stringAsFactors" "agecat"
> names(leadership)[6:10]<-c("item1","item2","item3","item4","item5")
> names(leadership)
[1] "managerID" "testDate" "country" "gender" "age"
[6] "item1" "item2" "item3" "item4" "item5"
[11] "stringAsFactors" "agecat"
>
4. 变量缺失
(1)is.na():工作于某个数据对象,返回一个同样大小的对象;值缺失位置的元素为TRUE,值未缺失的位置的元素为FALSE。
例06:is.na()函数的使用。
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE young
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE young
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE young
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE young
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE elder
> is.na(leadership[,6:10])
q1 q2 q3 q4 q5
1 FALSE FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE FALSE
3 FALSE FALSE FALSE FALSE FALSE
4 FALSE FALSE FALSE TRUE TRUE
5 FALSE FALSE FALSE FALSE FALSE
>
(2)na.rm=TRUE选项先除去缺失的值,再使函数计算剩余的存在的值。
例07:na.rm=TRUE的使用例子
> x<-c(1,2,NA,3)
> y<-x[1]+x[2]+x[3]+x[4]
> z<-sum(x)
> x
[1] 1 2 NA 3
> y
[1] NA
> z
[1] NA
> > x<-c(1,2,NA,3)
> y<-sum(x,na.rm=TRUE)
> x
[1] 1 2 NA 3
> y
[1] 6
>
(3)na.omit()函数去除含缺失值的那一行的所有的值。
例08:na.omit()的使用
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE young
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE young
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE young
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE young
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE elder
> > newdata<-na.omit(leadership)
> newdata
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE young
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE young
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE young
5 5 5/1/09 UK F 99 2 2 1 2 1 FALSE elder
>
(4)设定缺失值:
例09:年龄99岁是意味着年龄的缺失。
>
> leadership$age[leadership$age==99]<-NA
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 10/24/08 US M 32 5 4 5 5 5 FALSE young
2 2 10/28/08 US F 45 3 5 2 5 5 FALSE young
3 3 10/1/08 UK F 25 3 5 5 5 2 FALSE young
4 4 10/12/08 UK M 39 3 3 4 NA NA FALSE young
5 5 5/1/09 UK F NA 2 2 1 2 1 FALSE elder
>
5. 时间值
(1)as.Data()函数:进行时间转换。
as.Date(x,"input_format")
x是字符数据,input_format给出读日期时恰当的格式。

例10:as.Date()函数的使用。
> myformat<-"%m/%d/%y"
> leadership$date<-as.Date(leadership$date,myformat)
> leadership$date
[1] "2008-10-24" "2008-10-28" "2008-10-01" "2008-10-12" "2009-05-01"
>
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
(2)Sys.Date()函数:返回今天的日期;
date()函数:返回当前日期和时间。
例11:Sys.Date()函数与date()函数的使用的小例子。
> Sys.Date()
[1] "2013-07-31"
> date()
[1] "Wed Jul 31 15:34:03 2013"
(3)format(x,format="output_format")函数:以指定的格式输入日期,然后选择日期的一部分。
例12:format()函数的使用
> today<-Sys.Date()
> format(today,format="%B %d %Y")
[1] "七月 31 2013"
> format(today,format="%A")
[1] "星期三"
>
(4)R存储了从1970年1月1日开始的日期,则可以对他们进行算术运算。
例13:计算两个日期间的天数
> startdate<-as.Date("2004-02-13")
> enddate<-as.Date("2011-01-22")
> days<-enddate-startdate
> days
Time difference of 2535 days
(5)difftime()函数:计算一个时间间隔,并用秒,分钟,小时,日,周来表示。
例14:difftime()函数的使用
> today<-Sys.Date()
> dob<-as.Date("1956-10-12")
> difftime(today,dob,units="weeks")
Time difference of 2963.714 weeks
(6)as.character()函数:把日期值的表示转换为字符值。
6. 类型转换

例15:
> a<-c(1,2,3)
> a
[1] 1 2 3
> is.numeric(a)
[1] TRUE
> is.vector(a)
[1] TRUE
> > a<-as.character(a)
> a
[1] "1" "2" "3"
> is.numeric(a)
[1] FALSE
> is.vector(a)
[1] TRUE
> is.character(a)
[1] TRUE
>
7. 数据排序
order()函数:缺省时,按升序排列;变量前面加一个负号,则按降序排列。
例16:order()函数使用(1)
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
> newdata<-leadership[order(leadership$age),]
> newdata
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
>
例16:order()函数使用(2):按升序排列
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
> attach(leadership)
下列对象被屏蔽了_by_ .GlobalEnv: age, country, date, gender, q1, q2, q3, q4, q5
> newdata<-leadership[order(gender,age),]
> newdata
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
> detach(leadership)
例16:order()函数使用(3):按降序排列
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
> attach(leadership)
下列对象被屏蔽了_by_ .GlobalEnv: age, country, date, gender, q1, q2, q3, q4, q5
> newdata<-leadership[order(gender,-age),]
> newdata
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
> detach(leadership)
8. 合并数据集(datasets)
(1)添加列
merge()函数:垂直的合并两个数据集(dataset)或数据帧(data frame).
cbind()函数 : 把两个矩阵或数据帧垂直合并在一起,并且不需要指定一个共同的值。
(2)添加行
rbind()函数 : 水平的合并两个数据集(dataset)或数据帧(data frame).
9. 子集的数据集
(1)选择变量
例17:使用数据帧的列标号以及行标号:dataframe[row indices,column indices];
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
> newdata<-leadership[,c(6:10)]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1 例17(变1):使用列标号,选择需要的列;行标号缺省,代表选择相应列的所有的行。
> myvars<-c("q1","q2","q3","q4","q5")
> myvars
[1] "q1" "q2" "q3" "q4" "q5"
> newdata<-leadership[myvars]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1 例17(变2):用paste()函数创建具有相同的字符的向量。
> myvars<-paste("q",1:5,sep="")
> myvars
[1] "q1" "q2" "q3" "q4" "q5"
> newdata<-leadership[myvars]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1
注意:paste()函数的使用,在第5章中还会详讲。
(2)剔除变量
例18:剔除leadership中q3,q4两列的变量。
> leadership
managerID date country gender age q1 q2 q3 q4 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 FALSE young
2 2 2008-10-28 US F 45 3 5 2 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 5 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 4 NA NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 2 1 FALSE elder
> myvars<-names(leadership)%in%c("q3","q4")
> myvars
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE
> newdata<-leadership[!myvars]
> newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
A) 了解leadership中的变量集合
> names(leadership)
[1] "managerID" "date" "country" "gender" "age"
[6] "q1" "q2" "q3" "q4" "q5"
[11] "stringAsFactors" "agecat"
B)names(leadership) %in% c("q3","q4"):返回一组逻辑值组成的向量,即leadership中与q3,q4相匹配的为TRUE,否则,为FALSE。
C)leadership[!myvars]:选择逻辑值为TRUE的列,并忽略掉逻辑值为FALSE的列。
例18(变形1):在leadership中,q3和q4是第8,9个量,则可以如下
> newdata<-leadership[c(-8,-9)]
> newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
例18(变形2):设置q3和q4两列分别为NULL,即未定义的。
> leadership$q3<-leadership$q4<-NULL
> leadership
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
注意:NULL与NA是不一样的。 (3)选择观测量(observations)
例19:按照行选择观测量
> newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
> newdata<-leadership[1:3,]
> newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
例19(变1):
> newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
> attach(leadership)
下列对象被屏蔽了_by_ .GlobalEnv: age, country, date, gender, q1, q2, q5
> newdata<-leadership[which(gender=='M'&age>30),]
> newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
> detach(leadership)
>
A)gender=='M':会产生向量c(TRUE,FALSE,FASLE,TRUE,FALSE).
B)age>30:会产生向量c(TRUE,TRUE,FALSE,TRUE,TRUE).
C)gender=='M'&age>30:产生向量:c(TRUE,FALSE,FALSE,TRUE,FALSE),也即产生向量c(1,4).
Dleadership[c(1,4)]:从数据帧中选择第一行和第四行的观测量。 例20:使数据分析限制在某个日期段内
> leadership
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
> leadership$date<-as.Date(leadership$date,"%m/%d/%y")
> startdate<-as.Date("2009-01-01")
> enddate<-as.Date("2009-10-31")
> newdate<-leadership[which(leadership$date>=startdate&leadership$date<=enddate),]
> newdate
managerID date country gender age q1 q2 q5 stringAsFactors agecat
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
(4)subset()函数
例21:subset(),select()函数的使用
newdata
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
> newdata<-subset(leadership,age>=35|age<24,select=c(q1,q2))
> newdata
q1 q2
2 3 5
4 3 3
> newdata<-subset(leadership,gender=='M'&age>25,select=gender:q1)
> newdata
gender age q1
1 M 32 5
4 M 39 3
(5)随机取样(random sample)
sample()函数:随意找一个例子。
例22:sample()函数的使用
> leadership
managerID date country gender age q1 q2 q5 stringAsFactors agecat
1 1 2008-10-24 US M 32 5 4 5 FALSE young
2 2 2008-10-28 US F 45 3 5 5 FALSE young
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
4 4 2008-10-12 UK M 39 3 3 NA FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
> mysample<-leadership[sample(1:nrow(leadership),3,replace=FALSE),]
> mysample
managerID date country gender age q1 q2 q5 stringAsFactors agecat
3 3 2008-10-01 UK F 25 3 5 2 FALSE young
5 5 2009-05-01 UK F NA 2 2 1 FALSE elder
2 2 2008-10-28 US F 45 3 5 5 FALSE young
10. 使用SQL操作数据帧
例23:
> install.packages("sqldf")
also installing the dependencies ‘DBI’, ‘gsubfn’, ‘proto’, ‘chron’, ‘RSQLite’, ‘RSQLite.extfuns’
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/DBI_0.2-7.zip'
Content type 'application/zip' length 270970 bytes (264 Kb)
opened URL
downloaded 264 Kb
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/gsubfn_0.6-5.zip'
Content type 'application/zip' length 662152 bytes (646 Kb)
opened URL
downloaded 646 Kb
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/proto_0.3-10.zip'
Content type 'application/zip' length 458271 bytes (447 Kb)
opened URL
downloaded 447 Kb
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/chron_2.3-43.zip'
Content type 'application/zip' length 105387 bytes (102 Kb)
opened URL
downloaded 102 Kb
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/RSQLite_0.11.4.zip'
Content type 'application/zip' length 1145037 bytes (1.1 Mb)
opened URL
downloaded 1.1 Mb
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/RSQLite.extfuns_0.0.1.zip'
Content type 'application/zip' length 50877 bytes (49 Kb)
opened URL
downloaded 49 Kb
trying URL 'http://cran.rstudio.com/bin/windows/contrib/3.0/sqldf_0.4-6.4.zip'
Content type 'application/zip' length 70613 bytes (68 Kb)
opened URL
downloaded 68 Kb
package ‘DBI’ successfully unpacked and MD5 sums checked
package ‘gsubfn’ successfully unpacked and MD5 sums checked
package ‘proto’ successfully unpacked and MD5 sums checked
package ‘chron’ successfully unpacked and MD5 sums checked
package ‘RSQLite’ successfully unpacked and MD5 sums checked
package ‘RSQLite.extfuns’ successfully unpacked and MD5 sums checked
package ‘sqldf’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\seven-wang\AppData\Local\Temp\RtmpCY3Fbh\downloaded_packages
> library(sqldf)
载入需要的程辑包:DBI
载入需要的程辑包:gsubfn
载入需要的程辑包:proto
载入需要的名字空间:tcltk
载入需要的程辑包:chron
载入需要的程辑包:RSQLite
载入需要的程辑包:RSQLite.extfuns
> newdf<-sqldf("select * from mtcars where carb=1 order by mpg",row.names=TRUE)
Loading required package: tcltk
> newdf
mpg cyl disp hp drat wt qsec vs am gear carb
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
> sqldf("select avg(mpg) as avg_mpg,avg(disp) as avg_disp,gear from mtcars where cyl in (4,6) group by gear")
avg_mpg avg_disp gear
1 20.33333 201.0333 3
2 24.53333 123.0167 4
3 25.36667 120.1333 5
Chapter 04—Basic Data Management的更多相关文章
- Chapter 05—Advanced data management(Part 1)
一. R的数学函数,统计函数及字符处理函数 例01:一道实际应用题 一组学生其数学,科学和英语的成绩如下表: 任务:根据成绩,决定对每个学生的单独指导: 前20%的学生的成绩为A,次之为B,以此类推: ...
- Chapter 05—Advanced data management(Part 2)
二. 控制流 statement:一个单独的R语句或者是一个复合的R语句: cond:条件表达式,为TRUE或FALSE: expr:数字或字符表达式: seq:数字或字符串的顺序. 1.循环语句:f ...
- 场景3 Data Management
场景3 Data Management 数据管理 性能优化 OLTP OLAP 物化视图 :表的快照 传输表空间 :异构平台的数据迁移 星型转换 :事实表 OLTP : 在线事务处理 1. trans ...
- MySQL vs. MongoDB: Choosing a Data Management Solution
原文地址:http://www.javacodegeeks.com/2015/07/mysql-vs-mongodb.html 1. Introduction It would be fair to ...
- hdu-5929 Basic Data Structure(双端队列+模拟)
题目链接: Basic Data Structure Time Limit: 7000/3500 MS (Java/Others) Memory Limit: 65536/65536 K (Ja ...
- HDU 5929 Basic Data Structure 模拟
Basic Data Structure Time Limit: 7000/3500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Oth ...
- HDU 5929 Basic Data Structure 【模拟】 (2016CCPC东北地区大学生程序设计竞赛)
Basic Data Structure Time Limit: 7000/3500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Oth ...
- Basic Data Structure
Basic Data Structure Time Limit: 7000/3500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Oth ...
- [Windows Azure] Data Management and Business Analytics
http://www.windowsazure.com/en-us/develop/net/fundamentals/cloud-storage/ Managing and analyzing dat ...
随机推荐
- Security整合spring boot
Security整合spring boot 1.基础概念 Spring Security是一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架.它提供了一组可以在Spri ...
- 五、docker-compose开锋(docker 三剑客)
前言 终于写到docker-compose了,其实我最开始接触docker的时候,是因为一个开源项目需要用docker 环境和docke-compose 所以我最先接触的是docker-compse ...
- MySQL系统变量auto_increment_increment与auto_increment_offset学习总结
在MySQL中,系统变量auto_increment_increment与auto_increment_offset是与自增列相关的两个参数变量.在官方文档中,将其划分为Replication Mas ...
- Codeforces 1183F - Topforces Strikes Back
Div. 3的题,竟然卡了好久,自闭.jpg 好像我的思路不太一样呢QAQ 首先注意到,如果一个数是另一个的因子,那它肯定不会出现在答案中. 我们先把所有数排序,然后对每个数,我们要往前再找两个数(或 ...
- CSPS模拟 69
$C_n^0=1$ $C_n^0=1$ $C_n^0=1$ 我怎么又双叒叕犯这种错误了啊 (咳檀) T1 WA0,大神题,不会做! T2 就是要找一个最长区间,满足左端点是区间最小值,右端点是区间最大 ...
- permu 莫队 总结
由于每次询问静态区间里完整值域段的最大大小 貌似很好用莫队转移,所以考虑怎么转移 当给它扩展一个数时,就是给值域添加了一个值 这个值可能已经存在,也可能是新的 有的神仙做法是维护了一个并查集,然而我这 ...
- CF600E Lomsat gelral——线段树合并/dsu on tree
题目描述 一棵树有$n$个结点,每个结点都是一种颜色,每个颜色有一个编号,求树中每个子树的最多的颜色编号的和. 这个题意是真的窒息...具体意思是说,每个节点有一个颜色,你要找的是每个子树中颜色的众数 ...
- m76 赛后总结
这次没有炸的太厉害,只是T3崩了,而且..... 这次的心态并没有因为loj的大吉而崩,反而在经受过上一轮的打击之后变得坚强了,心态也平了,没什么可挂念的,因为我什么都没有,所以发扬光脚的不怕穿鞋的精 ...
- unittest使用数据驱动ddt
简介 ddt(data driven test)数据驱动测试:由外部数据集合来驱动测试用例,适用于测试方法不变,但需要大量变化的数据进行测试的情况,目的就是为了数据和测试步骤的分离 由于unittes ...
- Linux PXE自动化安装centos6,centos7系统
1.PXE是什么? pxe是Preboot Excution Environment的缩写,是intel公司研发,基于client/server的网络模式,支持远程主机通过网络从远端服务器下载镜,并由 ...