强化学习一:Introduction Of Reinforcement Learning
引言:
最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了。也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流。
一、强化学习是什么?
定义
首先先看一段定义:Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal。感觉看英文的定义很容易可以了解什么叫强化学习。
首先,我们思考一下学习本身,当一个婴儿在玩耍时可能会挥舞双手,左看右看,没有人来指导他的行为,但是他和外界直接通过了感官进行连接。感知给他传递了外界的各种信息,包括知识等。学习的过程贯穿着我们人类的一生,当我们开车或者说话时,都观察了环境,并执行一系列动作来影响环境。强化学习描述的是一个与环境交互的学习过程。
那么强化学习是如何描述这一学习过程的呢?以人开车为例,将人和车作为一个整体(agent),外界红绿灯、车道线等信息构成了环境(environment),然后人通过控制车辆向左、向右转弯或者直行的动作(action),影响了这个环境的状态(state),比如说前方有车,向右转弯后车道前没有车辆,这就说明车辆的动作影响了环境的状态。
但是,仅仅有了agent、environment、state和action还不够,需要有一个奖惩来指导agent的行动,这就是reward,比如车辆闯红灯会收到罚单。那么说到这里,大家一定很好奇:reward是如何指导强化学习的呢?首先我们要从强化学习的特性说起。
应用领域
再来看看强化学习在整个科学领域的应用范围。
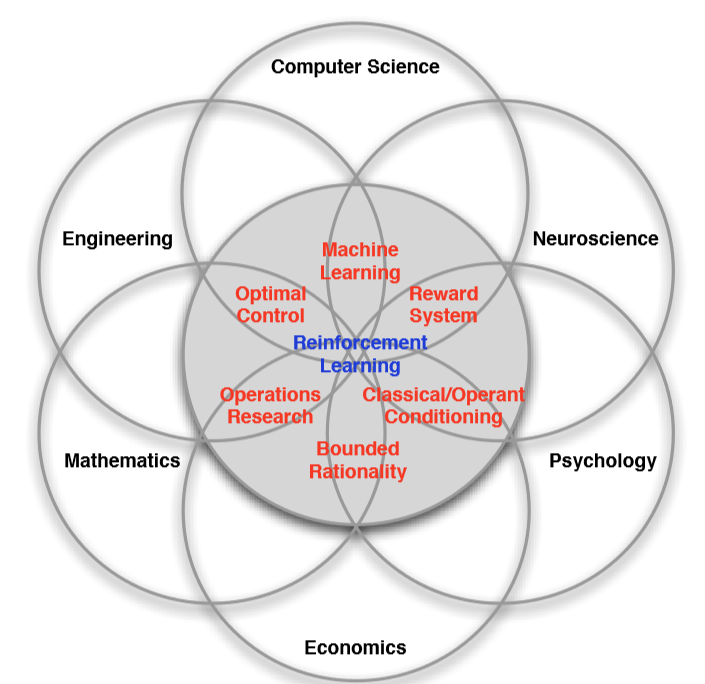
从图中可以看出,众多学科都与强化学习有关,增强学习本质上是一门决策学科,通过理解最佳的方式来制定决策。决策科学在计算机科学领域,体现为机器学习,尤其是强化学习;在工程领域,最优控制的实现与强化学习有关联;神经科学领域最主要的是研究人类大脑如何做出决策,提出多巴胺系统(前段时间谷歌开源了一个强化学习的框架就叫多巴胺),在强化学习中的运用体现为奖励系统;在心理学领域,也存在类似于神经科学领域的东西,传统的条件作用以及条件反射实验探究动物面对事物是如何做出反应,以及为什么会做出这种反应;在数学方面,可以用一个等价的公式来表示强化学习,可用于研究最优控制,也被称为运筹学;在经济学中,博弈论,效用理论以及有限性理的运用,也都是研究人类如何以及为什么做出决定,并使这些决定的效用最大化。这些都涉及到上述的强化学习的本质。
二、强化学习特性
强化学习作为机器学习的一种,免不了要被拿来和监督学习以及无监督学习比较。
首先,监督学习的特点是学习的数据都有标签(labels),即我们在学习之前就以及告知了模型什么样的state下采用什么样的action是正确的,简单说就是有个专门的老师(或者监督者)告诉算法,什么是对什么是错,通常用于回归,分类问题。无监督学习则恰恰相反,其所用于学习是数据没有label的,而是通过学习无标签的数据来探索数据的特性,通常用于聚类。
上文说到,强化学习是与环境实时交互并且会通过动作影响环境的,我们所采用的数据是没有一个正确的label明确告诉我们哪种action是好哪种是坏。但是我们提到了用一种特殊的奖惩机制来引导action,那就是reward。 reward并不向label一样,是在学习前就已存在与数据中,而是在当前时刻 t 的状态 stst 下,执行了相应的动作 atat, 才会在下一时刻(t+1时刻)获得一个对 t 时刻的reward Rt+1Rt+1,细心的你一定发现了这好像存在延迟,对啦,reward 本来就是一种延迟奖励的机制,另外,有些action通过对环境state的影响,可以影响到好多步之后的reward, 因此强化学习的目标为最大化reward之和,而不是单步reward。
说了那么多,现在可以总结一下强化学习的特性啦!强化学习有如下特点:
- 没有监督者,只有一系列的reward
- 反馈不是及时的,而是延时的
- 算法接受的数据是有时间顺序的
- agent的动作可以对环境产生持续影响
对第三点而言,需要额外解释一下,在监督学习中,通常假设数据是通过独立同分布采样的,即假设所有的样本数据都是通过在同一个分布下(如高斯分布)独立采样获得,而这一点对于强化学习来说,明显是不大可能,因为强化学习是一种与环境交互的学习问题,这意味着state和action的时序性是很重要的,他所获得的一系列state很大程度上是有联系的,并不是独立存在的。比如用强化学习下棋的例子中,当前落子位置会影响后面的落子。
三、强化学习问题
强化学习定义的是一类问题,即强化学习问题,用于解决该类问题的方法我们称之为强化学习方法。第一节中,我们说到强化学习的几个组成部分:reward、agent、environment、state、action。第二节中,我们明确了强化学习的目的为选择action用以最大化所有未来的reward(reward之和),下面我们将分别介绍其他几个部分是如何影响强化学习工作的。
3.1 agent and environment
agent与environment的交互过程如下图所示,其中大脑表示agent,地球表示environment。

每 t 时刻, agent完成以下过程:
执行action AtAt,影响环境
观测到观测量observation OtOt
收到环境反馈的reward RtRt
environment完成以下工作:
接收action AtAt
更新observation Ot+1Ot+1
产生reward RtRt
需要注意agent和environment 之间的界限问题,并不是严格的物理界限,比如一个机器人和外界这样的关系,当我们考虑机器人如何决策时(如决定往哪前进),机器人的决策部分作为一个agent,而他的控制系统则可以看做是environment的一部分。如何界定agent和environment:
The agent-environment boundary represents the limit of the agent’s absolute control, not of its knowledge.
3.2 state
通过观察上图,发现state还没出现,接下来我们讨论一下上图中的observation是如何转变为我们常用state的。
首先,假设我们执行上述强化学习过程一段时间并将其存储下来,那么这些信息就构成了历史数据(history),即由一系列的observation、reward、action组成。 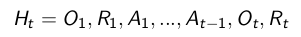
那么这些历史数据可以用来干啥呢?我们有了历史数据,就可以用于让agent选择action,让environment选择observation和reward。而根据state的定义,state是用来决定下一步做什么的信息量,那么既然历史有这样的作用,可以将state看做是history 的函数:

state可以分为environment state 、agent state 和information state,前两者顾名思义,environment state为环境的内部状态,即environment采用哪些信息来选择下一步的observation和reward(通常对agent不可见,如果可见常常包括冗余信息),agent state 为agent内部状态,即哪些信息用于选择下一步的动作,这是强化学习算法直接采用的信息,可以表示为历史的任意函数Sat=f(Ht)Sta=f(Ht)。

而information state包括了历史数据中所有有用的信息,当state满足马尔科夫条件(见下图),则下一时刻的状态完全由当前时刻决定,可以将其他历史信息扔掉啦!

定义了这三个state,我们可以将环境分为可完全观测环境(Fully Observation Environment)和部分可观测环境(Partially Observation Environment)。
当环境完全可观测时,有如下特点:

四、agent组成要素
上一节阐述了agent和environment的交互过程,环境主要在于提供reward和observation,那么构建一个agent需要哪些要素呢?
一个强化学习的agent主要包括以下一个或多个要素:
- Policy:agent’s behaviour function
- Value function:how good is each state and/ or action
- Model:agent’s representation of the environment
4.1 policy
策略,简言之就是agent的行为准则,对应着action和state之间的关系。
- 通常分为确定性策略(deterministic policy):a=π(s)a=π(s) ,即一个action为state的函数。
- 随机策略(stochastic policy):π(a|s)=P[At=a|St=s]π(a|s)=P[At=a|St=s],对应action相对state的条件概率。
4.2 Value function
强化学习的目标为最大化reward之和,但不是每一个学习过程都有终止状态,那么reward之和不能简单计算,所以需要用一个价值函数来估计未来的reward。具体表达说到强化学习的具体表示时再讨论。
4.3 模型

根据包不包含Policy 和value function可以将强化学习方法进行分类: 
根据是否建立了模型,可以将强化学习方法分类:

五、Exploration and Exploitation
在讨论Exploration and Exploitation之前。思考一件事情,假如你要去吃饭了,是选择你已经知道的餐馆中最符合你胃口的(Exploitation),这样保证你会满意。还是尝试一个你从未去过的餐馆(Exploration),可能你会有更好的用餐体验?当然也可能会很糟糕。
强化学习作为一种探索试错学习,agent需要发现一个好的策略,为了发现这个好的策略,他需要平衡这两者间的关系:
Exploration:不断探索新的环境信息,换言之,就是要不断扩大state的地图,不断搜索以前没遇到的state,并挑战不同的action
Exploitation: 对已经探索到的环境信息选择可以获得最大reward的action。
强化学习一:Introduction Of Reinforcement Learning的更多相关文章
- 深度强化学习:入门(Deep Reinforcement Learning: Scratching the surface)
RL的方案 两个主要对象:Agent和Environment Agent观察Environment,做出Action,这个Action会对Environment造成一定影响和改变,继而Agent会从新 ...
- Ⅰ Introduction to Reinforcement Learning
Dictum: To spark, often burst in hard stone. -- William Liebknecht 强化学习(Reinforcement Learning)是模仿人 ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- AI之强化学习、无监督学习、半监督学习和对抗学习
1.强化学习 @ 目录 1.强化学习 1.1 强化学习原理 1.2 强化学习与监督学习 2.无监督学习 3.半监督学习 4.对抗学习 强化学习(英语:Reinforcement Learning,简称 ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
随机推荐
- docker项目——搭建飞机大战小游戏
项目2:搭建打飞机小游戏,验证数据持久化(最底下有链接) 第一步:拉取镜像 [root@localhost docker-image]# docker load < httpd_img.tar. ...
- SpringBoot 源码解析 (三)----- Spring Boot 精髓:启动时初始化数据
在我们用 springboot 搭建项目的时候,有时候会碰到在项目启动时初始化一些操作的需求 ,针对这种需求 spring boot为我们提供了以下几种方案供我们选择: ApplicationRunn ...
- pat 1084 Broken Keyboard(20 分)
1084 Broken Keyboard(20 分) On a broken keyboard, some of the keys are worn out. So when you type som ...
- nyoj 168-房间安排 (贪心)
168-房间安排 内存限制:64MB 时间限制:3000ms 特判: No 通过数:33 提交数:71 难度:2 题目描述: 2010年上海世界博览会(Expo2010),是第41届世界博览会.于20 ...
- 理解MySQL数据库事务-隔离性
Transaction事务是指一个逻辑单元,执行一系列操作的SQL语句. 事务中一组的SQL语句,要么全部执行,要么全部回退.在Oracle数据库中有个名字,叫做transaction ID 在关系型 ...
- ZeroC Ice发送大数据
继上文,我们使用ZeroC Ice传递大块数据时,通常有两种做法,一种是一次请求,另一种就是分多次请求(,这种做法在官方文档有例子).选哪一种根据需要而定. 当分多次请求来完成一大块数据,到底选择每次 ...
- vue中自定义html文件的模板
如果默认生成的 HTML 文件不适合需求,可以创建/使用自定义模板. 一是通过 inject 选项,然后传递给定制的 HTML 文件.html-webpack-plugin 将会自动注入所有需要的 C ...
- 20191031-5 beta week 1/2 Scrum立会报告+燃尽图 03
此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/9913 一.小组情况 队名:扛把子 组长:孙晓宇 组员:宋晓丽 梁梦瑶 韩昊 ...
- C++学习第二天(打卡)
C++ new 可以很方便的 分配一段内存. 比如 int *test= new int ; int n; cin>>n; int * test =new int [n]; 可以实现动态分 ...
- 2019-11-28:ssrf基础学习,笔记
ssrf服务端请求伪造ssrf是一种由恶意访问者构造形成由服务端发起请求的一个安全漏洞,一般情况下,ssrf访问的目标是从外网无法访问的内部系统,正式因为它是由服务端发起的,所以它能请求到它相连而外网 ...