mybatis基础简介
1.mybatis的加载过程?
程序首先加载mybatis-config.xml文件,根据配置文件创建SQLSessionFactory对象;
然后通过SQLSessionFactory对象创建SQLSession对象,SQLSession接口中定义了执行SQL语句的方法;
之后通过SQLSession对象执行mapper.xml映射文件中定义的SQL语句;
最后通过SQLSession对象提交事务,关闭SQLSession对象
2.mybatis的整体架构?
架构分为三层:接口层(SqlSession),核心处理层,基础支持层。
3.xml常见解析方式
DOM(Document Object Model):树型解析,一个标签对应一个节点,标签中的文本是文本节点。好处:易于编程。缺点:当xml文件数据过大,会造成大量资源消耗
SAX(Simple API for XML):基于事件解析,只将部分XML文档加载到内存解析,不会记录文档中的数据,占用资源小。缺点:内存中不存储数据,只能开发人员自己负责维护业务逻辑涉及的多层节点之间的关系;另一方面,因为流式处理,只能从前到后单向进行,不能自由切换节点。采用“推模式”,即事件是由解析器产生并通过回调函数发送给程序的
StAX(Streaming API for XML):采用“拉模式”,应用程序通过调用解析器推进解析的过程。可以决定随时停止解析和处理多个XML文档。
==mybatis使用DOM解析方式解析xml映射文件,XPath是专为查询XML文档设计的语言。与DOM配合使用。==
4. 使用数据库连接池的好处?
实现数据库连接的重用
提高响应速度
防止数据库连接过多造成数据库假死
避免数据库连接泄露等
5.数据库连接池介绍?
数据库连接池在初始化时,一般创建一定数量的数据库连接添加的连接池备用。当程序需要连接时,直接在池中请求;不再使用该链接时,又返回到池中缓存,等待下次使用,不直接关闭。当然,也会控制==连接总数==的上限和==空闲连接数==的上限,如果连接总数达到上限且都被占用,则后续请求线程进入阻塞队列等待。如果连接池中的空闲连接数较多,达到上限,则后续返回的空闲连接直接关闭。注意:设置这两个数值大小要适当,不然当总连接数上限设置过大,可能数据库僵死,如果过小,无法发挥性能,浪费数据库资源。当空闲连接数上限过大,浪费系统资源来维护;如果过小,出现峰值请求时,系统的响应变弱。
6.在dao层只写了mapper接口,接口怎么实现的?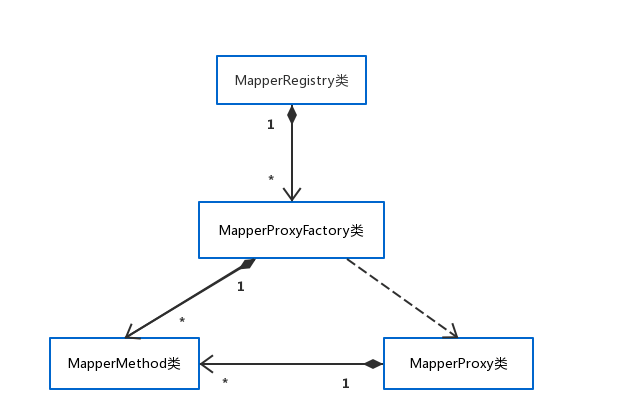
基础支持层中binding模块的问题,Binding模块有几个核心组件,
这里写图片描述
在Mybatis初始化过程中,读取映射文件以及mapper接口中的注释信息,并调用MapperRegistry.addMapper()方法填充MapperRegistry.knownMapper集合,该集合key值是Mapper接口对应的Class对象,value为MapperProxyFactory对象,为Mapper接口创建代理对象。要执行SQL语句时,调用MapperRegistry.getMapper()方法获取代理对象。MapperProxy实现Invocationhandler接口(代理对象的核心逻辑),MapperProxy.invoke()方法是执行的主要逻辑。MapperMethod中封装了Mapper接口中对应方法的信息,以及SQL语句信息,其中最主要的方法是execute()方法,根据SQL语句的类型调用SQLSession对应的犯法实现数据库操作。
7.mybatis中的缓存机制?
mybatis作为ORM框架,提供了两层缓存结果。
* 一级缓存是会话级别的缓存,在mybatis中没创建一个SQLSession对象,就表示开启一次数据库会话。在一次会话中可能会反复执行完全相同的查询语句,如果没有缓存,会造成数据库资源浪费。mybatis的SQLSession通过Executor对象完成数据库的操作,所以在Executor对象中建立了一个简单的缓存,即一级缓存。它每次将查询结果对象缓存起来,在执行查询操作时,先找缓存中是否存在一样的查询语句,找到的话直接取出相应结果对象返回。第二个功能,如果一级缓存中缓存了嵌套查询的结果对象,则可以直接加载结果对象;如果一级缓存中记录的嵌套查询结果对象并未完全加载,在可以通过DeferredLoad(BaseExcutor内部类)实现类似延迟加载的功能。
一级缓存的生命周期与SQLSession相同,其实就是与Executor对象生命周期相同。当Excutor对象调用close()方法时,一级缓存就不可用了。一级缓存默认开启。
* 二级缓存是应用级别的缓存,它的生命周期与应用程序相同。CachingExcutor是Excutor接口的装饰器,为Excutor对象增加了二级缓存功能。二级缓存配置有三个。
配置:(1) 在mybatis-config.xml配置中CacheEnabled配置,它是二级缓存总开关,只有它为true时,后2个配置才有效;
<settings>
<setting name="cacheEnabled" value="true" />
...
</settings>

(2)映射配置文件中可以配置和节点,配置任何一个节点都表示二级缓存开启。
(3)在节点中的useCache属性,该属性表示查询操作产生的对象是否要保存的二级缓存中。默认值为true。
当执行查询时,先查询二级缓存,再查询一级缓存,二级缓存中的结果对象被所有命名空间namespace共享。
一级缓存是直接将查询结果写入;
二级缓存是要在事务提交的时候才将TransactionalCache.entriesTAddOnCommit集合中缓存的数据写入。
8. mybatis的分页插件?
mybatis本身可以通过RowRounds方式进行分页,但是它并没有转换成分页相关的SQL语句,而是通过调用ResultSet.absolute()方法或循环调用ResultSet.next()方法定位到指定的记录行。当表中数据较大时,这种分页仍然会查询全表数据,性能不行。
@Intercepts({@Signature(type = Excutor.class, method="query", args= {
MappedStatment.class, Object.class, RowBounds.class, Resulthandler.class})})
public class PageInterceptor implements Interceptor{...}
一个常用的插件PageInterceptor插件类,它还依赖了Dialect接口(Dialect是策略模式实现)。
PageInterceptor中通过@Intercepts注解信息和Singnature注解信息,拦截Excutor.query(MappedStatmen,Object,RowBounds,ResultHandler)方法进行分页。如果要拦截其他方法,可自行定义修改@Signature注解。
-- mysql 的分页是limit实现的 offset,length offset代表从那儿开始,length代表查询几个
select * from t_user limit 10,10
-- Oracle 的分页是通过RowNum 实现的
select * from (
select u.* ,RowNum row from (select * from t_user) u where RowNum <= 20
) where rn > 10

正是因为不同数据库的分页方式不同,所以才为PageInterceptor添加Dialect策略。
注意:当mysql分页时,limit offset,length 中的offset值特别大时,查询性能会很差。例如:
select * from t_user limit 1000000,100;
意思是扫描满足条件的1000100行,扔掉前面的1000000,只要后面的100行。
-- 通过索引进行优化。本例中user_id为user主键,存储引擎为InnoDB,所以user_id自带聚集索引。
select * from t_user where user_id>=(select user_id from t_user limit 1000000,1) limit 100;

10.#{}和${}的区别?
${}是==properties文件中的变量占位符==,它可以用于标签属性值和sql内部,属于静态文本替换。它在这里应用,如下:
执行SQL:select * from user where user_name = ${userName}
参数:employeeName传入值为:Smith
解析后执行的SQL:Select * from emp where name =Smith
这样的话,就很容易被注入攻击,如userName=“or 1=1” ,就可以随意访问了。
#{}是==sql的参数占位符==,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值。如下:
如上,不管输入什么参数,打印出的SQL都是这样的。这是因为MyBatis启用了==预编译==功能,在SQL执行前,会先将上面的SQL发送给数据库进行编译;执行时,直接使用编译好的SQL,替换占位符“?”就可以了。因为SQL注入只能对编译过程起作用,所以这样的方式就很好地避免了SQL注入的问题。
11.mybatis是怎么实现预编译的?
其实在框架底层,是JDBC中的PreparedStatement类在起作用,PreparedStatement是我们很熟悉的Statement的子类,它的对象包含了编译好的SQL语句。这种“准备好”的方式不仅能提高安全性,而且在多次执行同一个SQL时,能够提高效率。原因是SQL已编译好,再次执行时无需再编译。
mybatis基础简介的更多相关文章
- mybatis基础系列(一)——mybatis入门
好久不发博客了,写博文的一个好处是能让心静下来,整理下之前学习过的一些知识一起分享,大神路过~ mybatis简介 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射. ...
- 现代3D图形编程学习-基础简介(2) (译)
本书系列 现代3D图形编程学习 基础简介(2) 图形和渲染 接下去的内容对渲染的过程进行粗略介绍.遇到的部分内容不是很明白也没有关系,在接下去的章节中,会被具体阐述. 你在电脑屏幕上看到的任何东西,包 ...
- 现代3D图形编程学习-基础简介(1) (译)
本书系列 现代3D图形编程学习 基础简介 并不像本书的其他章节,这章内容没有相关的源代码或是项目.本章,我们将讨论向量,图形渲染理论,以及OpenGL. 向量 在阅读这本书的时候,你需要熟悉代数和几何 ...
- myBatis 基础测试 表关联关系配置 集合 测试
myBatis 基础测试 表关联关系配置 集合 测试 测试myelipse项目源码 sql 下载 http://download.csdn.net/detail/liangrui1988/599388 ...
- MyBatis基础:MyBatis缓存(5)
1. MyBatis缓存简介 MyBatis提供支持一级缓存及二级缓存. 一级缓存: 2.MyBatis一级缓存
- JAVA之Mybatis基础入门--框架搭建与简单查询
JAVA中,操作数据库有JDBC.hibernate.Mybatis等技术,今天整理了下,来讲一讲下Mybatis.也为自己整理下文档: hibernate是一个完全的ORM框架,是完全面向对象的.但 ...
- MyBatis基础入门《二十》动态SQL(foreach)
MyBatis基础入门<二十>动态SQL(foreach) 1. 迭代一个集合,通常用于in条件 2. 属性 > item > index > collection : ...
- mybatis基础系列(四)——关联查询、延迟加载、一级缓存与二级缓存
关本文是Mybatis基础系列的第四篇文章,点击下面链接可以查看前面的文章: mybatis基础系列(三)——动态sql mybatis基础系列(二)——基础语法.别名.输入映射.输出映射 mybat ...
- mybatis基础系列(三)——动态sql
本文是Mybatis基础系列的第三篇文章,点击下面链接可以查看前面的文章: mybatis基础系列(二)--基础语法.别名.输入映射.输出映射 mybatis基础系列(一)--mybatis入门 动态 ...
随机推荐
- nu.xom:Serializer
Serializer: 机翻 /* 使用用于控制空格,规范化,缩进,换行和基本URI的各种选项以特定编码输出Document对象 */ Serializer(OutputStream out) :创建 ...
- Spark第一周
Why Scala 在数据集不是很大的时候,开发人员可以使用python.R.MATLAB等语言在单机上处理数据集.但是在大数据时代,数据集少说都是TB.PB级别,此时便需要分布式地处理.相较于上述语 ...
- SpringBoot快速入门01--环境搭建
SpringBoot快速入门--环境搭建 1.创建web工程 1.1 创建新的工程. 1.2 选择maven工程,点击下一步. 1.3 填写groupid(maven的项目名称)和artifacti ...
- Dock学习(一):容器介绍
一.什么是容器 1.容器是一种轻量级.可移植.自包含的软件打包技术,使应用程序可以在几乎任何地方以相同的方式运行.开发人员在自己的笔记本上创建并测试好的容器,无需任何修改就能够在生产系统的虚拟机.或物 ...
- 个人永久性免费-Excel催化剂功能第22波-Excel文件类型、密码批量修改,补齐PowerQuery短板
Excel的多工作薄.多工作表批量合并功能,Excel用户很多这方面的使用场景,也促使了各大Excel各大插件们都在此功能上有所开发,体验程度不一,但总体能够满足大多数的应用场景,本人之前也开发个单独 ...
- Git命令行之快速入门
从头开始创建一个版本库,添加一些内容,然后管理一些修订版本. 有两种建立 Git版本库 的基础技术.第一:从头开始创建,用现有的内容填充它.第二:可以克隆一个已有的版本库.这里选择从一个空的版本库开始 ...
- C#2.0新增功能01 分布类与分部方法
连载目录 [已更新最新开发文章,点击查看详细] 分部类型 拆分一个类.一个结构.一个接口或一个方法的定义到两个或更多的文件中, 每个源文件包含类型或方法定义的一部分,编译应用程序时将把所有部分组 ...
- [PTA] 1002. 写出这个数 (Basic)
import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Sc ...
- ES6 symbol 以及symbol的简单应用
前置 1.ES6 引入了一种新的原始数据类型Symbol,表示独一无二的值. 2.Symbol 值通过Symbol函数生成. 3.Symbol 函数可以接受一个字符串作为参数,表示对 Symbol 实 ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...