Node.js爬虫实战 - 爬你喜欢的
前言
今天没有什么前言,就是想分享些关于爬虫的技术,任性。来吧,各位客官,里边请...
开篇第一问:爬虫是什么嘞?
首先咱们说哈,爬虫不是“虫子”,姑凉们不要害怕。
爬虫 - 一种通过一定方式按照一定规则抓取数据的操作或方法。
开篇第二问:爬虫能做什么嘞?
来来来,谈谈需求
产品MM:
- 爱豆的新电影上架了,整体电影评价如何呢?
- 暗恋的妹子最近又失恋了,如何在她发微博的时候第一时间知道发了什么,好去呵护呢?
- 总是在看小说的时候点到广告?总是在看那啥的时候点出来,澳xx场又上线啦?
- 做个新闻类网站没有数据源咋办?
研发GG:
爬虫随时准备为您服务!
- 使用爬虫,拉取爱豆视频所有的评价,导入表格,进而分析评价
- 使用爬虫,加上定时任务,拉取妹子的微博,只要数据有变化,接入短信或邮件服务,第一时间通知
- 使用爬虫,拉取小说内容或xxx的视频,自己再设计个展示页,perfect!
- 使用爬虫,定时任务,拉取多个新闻源的新闻,存储到数据库
开篇第三问:爬虫如何实现嘞?
实现爬虫的技术有很多,如python、Node等,今天胡哥给大家分享使用Node做爬虫:爬取小说网站-首页推荐小说
爬取第一步-确定目标
目标网站:https://www.23us.so
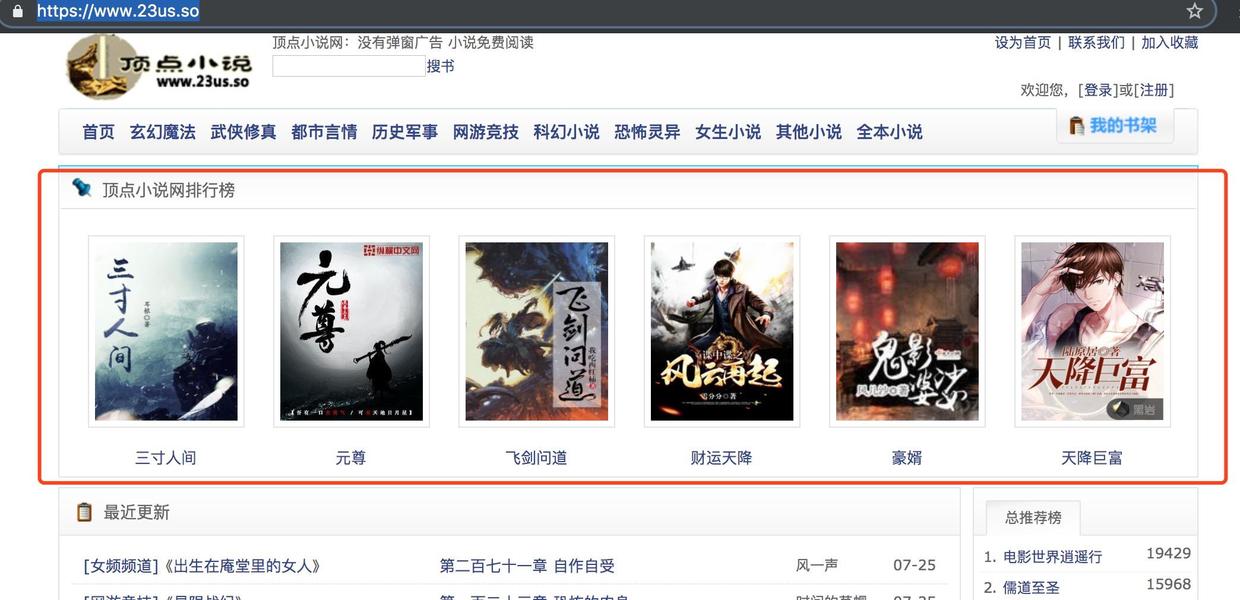
我们要获取排行榜中六部小说的:书名、封面、以及小说书籍信息对应的地址(后续获取小说完整信息)
爬取第二步-分析目标特点
网页的内容是由HTML生成的,抓取内容就相当找到特定的HTML结构,获取该元素的值。
打开网页调试控制台,查看元素HTML结构。
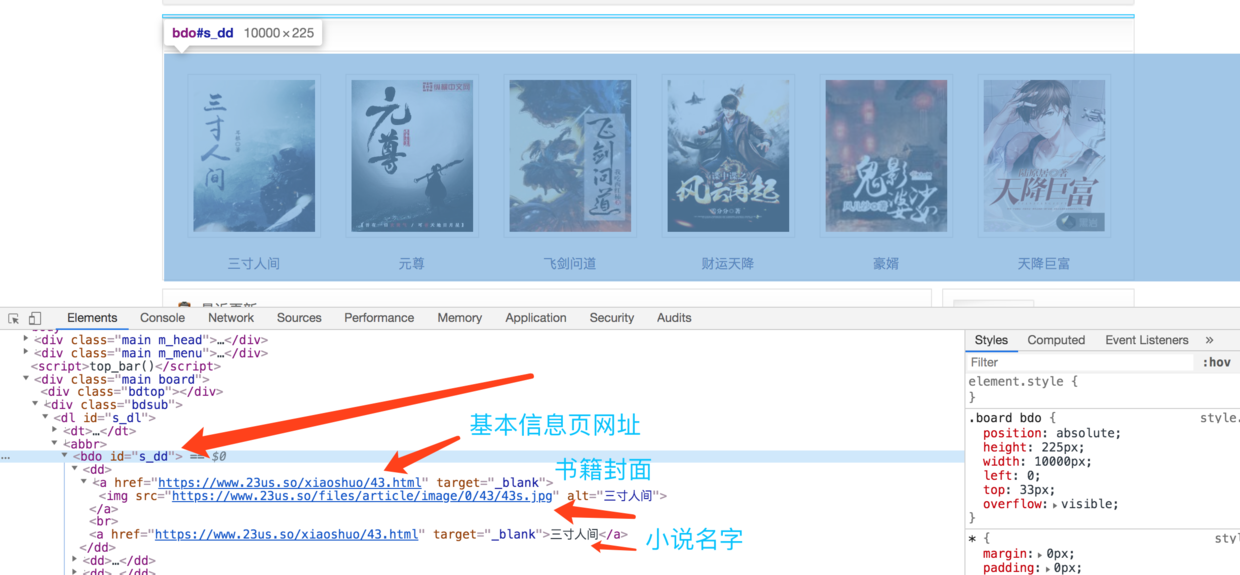
注意观察页面HTML的结构,排行榜推荐的小说的HTML结构是
bdo#s-dd 元素
dd 子元素 - 每一部小说
a 目录信息
img 封面
a 小说名称
爬取第三步-弄丫的
工具善其事必先利其器,准备好趁手的兵器!
superagent
模拟客户端发送网络请求,可设置请求参数、header头信息
npm install superagent -D
cheerio
类jQuery库,可将字符串导入,创建对象,用于快速抓取字符串中的符合条件的数据
npm install cheerio -D
项目目录:
node-pachong/
- index.js
- package.json
- node_modules/
上代码:
// node-pachong/index.js
/**
* 使用Node.js做爬虫实战
* author: justbecoder <justbecoder@aliyun.com>
*/
// 引入需要的工具包
const sp = require('superagent');
const cheerio = require('cheerio');
// 定义请求的URL地址
const BASE_URL = 'http://www.23us.so';
// 1. 发送请求,获取HTML字符串
(async () => {
let html = await sp.get(BASE_URL);
// 2. 将字符串导入,使用cheerio获取元素
let $ = cheerio.load(html.text);
// 3. 获取指定的元素
let books = []
$('#s_dd dd').each(function () {
let info = {
link: $(this).find('a').eq(0).attr('href'),
name: $(this).find('a').eq(1).text(),
image: $(this).find('img').attr('src')
}
books.push(info)
})
console.log(books)
})()
友情提醒:每个网站的HTML结构是不一样,在抓取不同网站的数据时,要分析不同的解构,才能百发百中。
效果图:
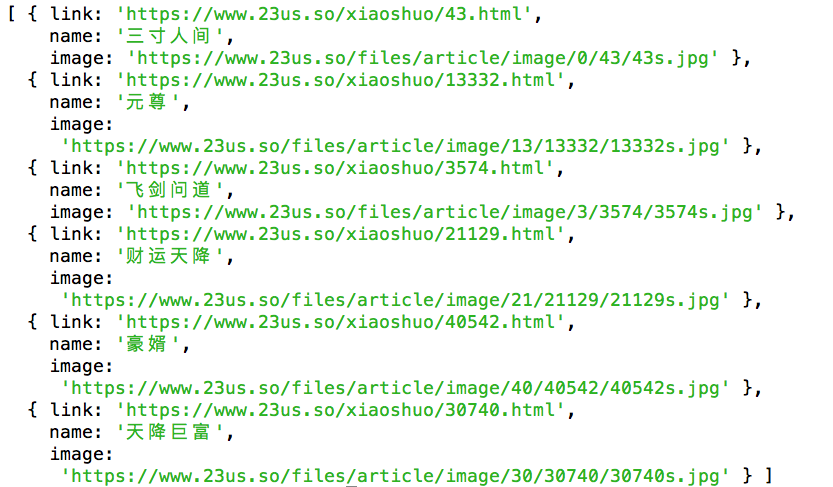
获取到信息之后,做接口数据返回、存储数据库,你想干啥都行...
源码获取
关注胡哥有话说公众号,回复“爬虫”,即可获取源码地址。
后记
以上就是胡哥今天给大家分享的内容,喜欢的小伙伴记得收藏、转发、点击右下角按钮在看,推荐给更多小伙伴呦,欢迎多多留言交流...
胡哥有话说,一个有技术,有情怀的胡哥!京东开放平台首席前端攻城狮。与你一起聊聊大前端,分享前端系统架构,框架实现原理,最新最高效的技术实践!
长按扫码关注,更帅更漂亮呦!关注胡哥有话说公众号,可与胡哥继续深入交流呦!

Node.js爬虫实战 - 爬你喜欢的的更多相关文章
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- 《Node.js开发实战详解》学习笔记
<Node.js开发实战详解>学习笔记 ——持续更新中 一.NodeJS设计模式 1 . 单例模式 顾名思义,单例就是保证一个类只有一个实例,实现的方法是,先判断实例是否存在,如果存在则直 ...
- node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全. 本项目主要包含一下技术: 发送http抓取页面(http).分析页面(cheerio).中文乱码处理(bufferhelper).异步并发流程 ...
- Koa与Node.js开发实战(3)——Nunjucks模板在Koa中的应用(视频演示)
技术架构: 在Koa中应用Nunjucks,需要先把Nunjucks集成为符合Koa规格的中间件(Middleware),从本质上来讲,集成后的中间件的作用是给上下文对象绑定一个render(vi ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
随机推荐
- 基于SpringCloud的Microservices架构实战案例-配置文件属性内容加解密
使用过SpringBoot配置文件的朋友都知道,资源文件中的内容通常情况下是明文显示,安全性就比较低一些.打开application.properties或application.yml,比如mysq ...
- Java设计模式学习笔记(三) 工厂方法模式
前言 本篇是设计模式学习笔记的其中一篇文章,如对其他模式有兴趣,可从该地址查找设计模式学习笔记汇总地址 1. 简介 上一篇博客介绍了简单工厂模式,简单工厂模式存在一个很严重的问题: 就是当系统需要引入 ...
- 硬件笔记之Thinkpad T470P更换2K屏幕
0x00 前言 手上的Thinkpad T470P屏幕是1920x1080的屏幕,色域范围NTSC 45%,作为一块办公用屏是正常配置,但是考虑到色彩显示和色域范围,计划升级到2K屏幕. 2k屏幕参数 ...
- 1.Actor编写-ESGrain与ESRepGrain
ESGrain 生命周期 Ray中ESGrain继承自Grain扩展了Grain的生命周期.Grain的生命周期参见文档附录:1-Grain生命周期-译注.md ESGrain重写了Grain的OnA ...
- NET Core CSharp初级篇 1-3面向对象
.NET Core CSharp初级篇 1-3 本节内容为面向对象初级教程 类 简介 面向对象是整个C#中最核心最有特色的一个模块了,它很好的诠释了程序与现实世界的联系. 面向对象的三大特征:继承.多 ...
- MyBatis OGNL表达式用法
From<MyBatis从入门到精通> <!-- 4.7 OGNL用法 MyBatis常用的OGNL表达式: e1 or e2: e1 and e2 e1 == e2; e1 != ...
- Python 爬虫:煎蛋网妹子图
使用 Headless Chrome 替代了 PhatomJS. 图片保存到指定文件夹中. import requests from bs4 import BeautifulSoup from sel ...
- SpringBoot Jpa入门案例
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons) 我们先来了解一下是什么是springboot jpa,springboo ...
- .net持续集成cake篇之使用vs或者vscode来辅助开发cake脚本
使用Visual Studio来开发工具 前面我们都是通过手写或者复制的方法来编写Cake文件,Cake使用的是C#语言,如果仅使用简单的文本编辑器来编写显然效率是非常低下的,本节我们讲解如何使用ca ...
- 快速掌握mongoDB(五)——通过mongofiles和C#驱动操作GridFS
1 GridFS简介 当前Bson能存储的最大尺寸是16M,我们想把大于16M的文件存入mongoDB中怎么办呢?mongoDB提供的GridFS就是专门做这个的.使用GridFS存储大文件时,文件被 ...