pandas-缺失值处理
import pandas as pd
import numpy as np
Step 1.加载数据集
# header=0以第一行作为列名
tip = pd.read_csv("lianx.csv",sep=',',header=0)
tip.head()
Step 2.删除第 1,4,7,9,11,13,14列,保存修改
a = list(tip.columns)
print(a)
b = []
c = 0
for i in a:
c= c+1
if c in [1,4,7,9,11,13,14]:
b.append(i)
# print(b)
# 删除列
tip = tip.drop(b,axis=1)
tip.head()
step 3.重命名列列索引依次为
1) alcohol
2) malic_acid
3) alcalinity_of_ash
4) magnesium
5) flavanoids
6) proanthocyanins
7) hue
c = ['alcohol','malic_acid','alcalinity_of_ash','magnesium','flavanoids','proanthocyanins','hue']
b = list(tip.columns[:7])
b2 = list(tip.columns)
print(b)
print(b2)
d = dict(zip(b,c))
print(d)
tip.rename(columns=d,inplace=True)
tip.head()

step 4.将alcohol 这一列的前三行改为NaN
#tip.iloc[:3,0]=np.nan
tip.iloc[:3,0]=np.nan
tip.head()
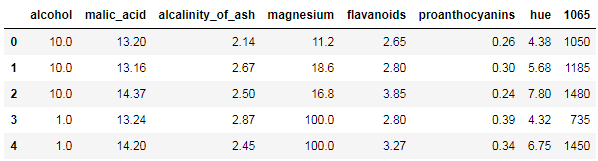
step 6. 将 alcohol 和 magnesium列的缺失值分别用10和100进行填充
tip['alcohol'] = tip['alcohol'].fillna(10)
tip['magnesium'] = tip['magnesium'].fillna(100)
tip.head()
step 7.创建10以内的10个随机整数
import random
seven = np.random.randint(0,10,10)
seven

step 8.根据上面的随机数,作为行索引,选取alcohol列,赋值为NaN
tip.iloc[seven,0]=np.nan
tip.head()
step 9.统计缺失值得个数
tip.isnull().sum()

Step 10.删除包含缺失值得行
tip.dropna()

Step 11. 让索引重新从0开始
a = list(tip.index)
b = list(range(len(a)))
c = dict(zip(a,b))
tip.rename(index=c)# 映射操作

pandas-缺失值处理的更多相关文章
- pandas缺失值处理
1.检查缺失值 为了更容易地检测缺失值(以及跨越不同的数组dtype),Pandas提供了isnull()和notnull()函数,它们也是Series和DataFrame对象的方法 - 示例1 im ...
- Python数据分析(二)pandas缺失值处理
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e' ...
- Python—关于Pandas缺失值问题(国内唯一)
获取文中的CSV文件用于代码编程以及文章首发地址,请点击下方超链接 获取CSV,用于编程调试请点这 在本文中,我们将使用Python的Pandas库逐步完成许多不同的数据清理任务.具体而言,我们将重点 ...
- Pandas系列(六)-时间序列详解
内容目录 1. 基础概述 2. 转换时间戳 3. 生成时间戳范围 4. DatetimeIndex 5. DateOffset对象 6. 与时间序列相关的方法 6.1 移动 6.2 频率转换 6.3 ...
- Pandas 时间序列
# 导入相关库 import numpy as np import pandas as pd 在做金融领域方面的分析时,经常会对时间进行一系列的处理.Pandas 内部自带了很多关于时间序列相关的工具 ...
- Python 基础(五)
pandas缺失值处理 import pandas as pd importrandom df01 = pd.DataFrame(np.random.randint(1,9),size = (4,4) ...
- Pandas系列(三)-缺失值处理
内容目录 1. 什么是缺失值 2. 丢弃缺失值 3. 填充缺失值 4. 替换缺失值 5. 使用其他对象填充 数据准备 import pandas as pd import numpy as np in ...
- 【学习】数据处理基础知识(缺失值处理)【pandas】
缺失数据(missing data)大部分数据分析应用中非常常见.pd设计目标之一就是让缺失数据的处理任务尽量轻松. pd 使用浮点值NaN(Not a Number) 表示浮点和非浮点数组中的缺失数 ...
- Python Pandas找到缺失值的位置
python pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺 ...
- pandas判断缺失值的办法
参考这篇文章: https://blog.csdn.net/u012387178/article/details/52571725 python pandas判断缺失值一般采用 isnull(),然而 ...
随机推荐
- 扩展KMP笔记
KMP能计算一个字符串的每个位置前最长公共前缀后缀 扩展KMP可以用来计算两个字符串间的最长公共前缀后缀的…… 不过为了计算这个需要绕些弯路 已知字符串$S$和$P$,$S$的长度为$n$,$P$的长 ...
- WPF 绑定属性 XAML 时间格式化
原文:WPF 绑定属性 XAML 时间格式化 XAML 时间格式化{Binding Birthday,StringFormat='yyyy-MM-dd '} public class AssetCla ...
- 图解Java常用数据结构
最近在整理数据结构方面的知识, 系统化看了下 Java 中常用数据结构, 突发奇想用动画来绘制数据流转过程. 主要基于 jdk8, 可能会有些特性与 jdk7 之前不相同, 例如 LinkedList ...
- Map拼接URL地址
import java.util.HashMap; import java.util.Iterator; import java.util.Map; /** * @Author: hoje * Des ...
- 失败zero
1127 系统玩崩溃了 分区助手调整c盘,导致自动进入快速启动然后疯狂boot网卡检测?还有测试中心? 查找错误initialization and establishing link,结论是bios ...
- 【BZOJ4823】[CQOI2017]老C的方块(网络流)
[BZOJ4823][CQOI2017]老C的方块(网络流) 题面 BZOJ 题解 首先还是给棋盘进行黑白染色,然后对于特殊边左右两侧的格子单独拎出来考虑. 为了和其他格子区分,我们把两侧的这两个格子 ...
- MongoDB系列---集合与文档操作03
MongoDB-——Collection 学习大纲: 1.集合操作 2.文档操作 知识回顾: 上一篇我们讲述了如何对MongoDB的权限和用户进行日常的基本操作,来达到我们对数据库的基本安全保障. 一 ...
- Java开发桌面程序学习(13)——Javafx多线程 下载功能
普通使用 Task<Void> task = new Task<Void>() { @Override protected void succeeded() { super.s ...
- SPA项目开发之首页导航+左侧菜单
Mock.js: 前后端分离之后,前端迫切需要一种机制,不再需要依赖后端接口开发,而mockjs就可以做到这一点 Mock.js是一个模拟数据的生成器,用来帮助前端调试开发.进行前后端的原型分离以及用 ...
- HTTP 压测工具wrk简介
前段时间项目压测,看到开发命令行下使用这个命令进行压测非常简洁.方便,萌发了学习的兴趣,这里仅做简单介绍. 安装 wrk支持大多数UNIX系统,不支持Windows.需要操作系统支持LuaJIT和Op ...