【文本处理命令】之grep搜索命令详解
一、grep搜索命令
在日常使用中grep命令也是会经常用到的一个搜索命令。grep命令用于在文本中执行关键词搜索,并显示匹配的结果。
格式:
grep [选项] [文件]
Usage: grep [OPTION]... PATTERN [FILE]...
常用选项:
-b,--byte-offset 将可执行文件binary当作文本文件来搜索
-c,--count 仅显示找到的行数
-i , --ignore-case 忽略大小写
-n,--line-number 显示行号
-v, --revert-match 取反,列出没有“关键词”的行
-w, --word-regex 按单词搜索,仅匹配这个字符串
-r 逐层便利目录查看
--color 匹配到的行高亮显示
--include 指定匹配的文件类型
--exinclude 过滤掉不需要匹配的文件类型
-A: 显示匹配行及后面多少行, 如: -A3, 则表示显示匹配行及后3行
-B: 显示匹配行及前面多少行, 如: -B3, 则表示显示匹配行及前3行
-C: 显示匹配行前后多少行, 如: -C3, 则表示显示批量行前后3行
正则匹配:
^ #行的开始 如:'^grep'匹配所有以grep开头的行。
$ #行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
‘\?‘:匹配其前面的字符0次或者1次;
‘\+’:匹配其前面的字符1次或者多次;
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
实例:
1)查询当前系统中不允许登录的用户信息
[root@VM_0_10_centos shellScript]# grep /sbin/nologin /tmp/passwd
bin:x:::bin:/bin:/sbin/nologin
daemon:x:::daemon:/sbin:/sbin/nologin
adm:x:::adm:/var/adm:/sbin/nologin
或
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | grep /sbin/nologin
2)多文件查询
# 查看多个文件匹配包含字母a的行
[root@VM_0_10_centos shellScript]# grep a test.sh test.txt
test.sh:#!/bin/bash
test.sh:echo "argument: $0";
test.txt: this is a test

3)查看既包含a又包含o的行
[root@VM_0_10_centos shellScript]# grep a test.txt | grep o
或
[root@VM_0_10_centos shellScript]# cat test.txt | grep a | grep o
Are you like awk
There are orange,apple,mongo

4)查找匹配a或者匹配o的行
[root@VM_0_10_centos shellScript]# grep -e a -e o test.txt
或
[root@VM_0_10_centos shellScript]# cat test.txt | grep -e 'a' -e 'o'
this is a test
Are you like awk
This's a test
There are orange,apple,mongo

5)匹配查询内容的前n行,后n行,前后n行
#显示匹配行前2行
grep a test.txt -A2 #显示匹配行后2行
grep a test.txt -B2 #显示匹配行前后2行
grep a test.txt -C2
PS:尝试,但是结果还是显示的全部,不知道是我命令错了还是其他原因
6)匹配字符不区分大小写
[root@VM_0_10_centos shellScript]# grep -i a test.txt
this is a test
Are you like awk
This's a test
There are orange,apple,mongo

7)匹配正则表达式(匹配小写a-z之间的5个字符,即包含5个小写字母的字符)下面加粗部分显示
[root@VM_0_10_centos shellScript]# grep -e '[a-z]\{5\}' test.txt
There are orange,apple,mongo

8)统计包含a的行数
[root@VM_0_10_centos shellScript]# grep -c a test.txt
4
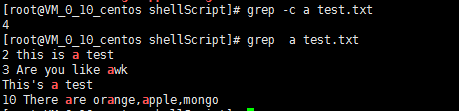
9)遍历当前目录及子目录包含a的行
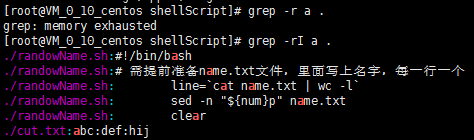
[root@VM_0_10_centos shellScript]# grep -r a .
grep: memory exhausted
[root@VM_0_10_centos shellScript]# grep -rI a .
./randowName.sh: clear
./cut.txt:abc:def:hij
PS:这里不加-I会出现上面内存问题,这是因为grep -r查找的范围会访问所有这个目录下的文件,包括二进制文件,加上-I参数不匹配查询二进制文件,可以解决这个问题。
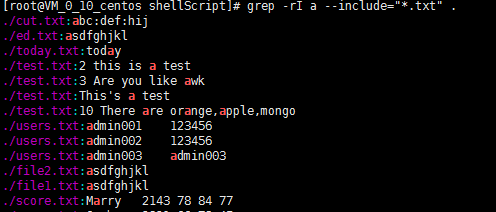
10)遍历当前目录及所有子目录,查找所有.txt类型的文件中包含a的字符
[root@VM_0_10_centos shellScript]# grep -rI a --include="*.txt" .
./cut.txt:abc:def:hij
./ed.txt:asdfghjkl
11)查找指定进程及其个数

PS:如果想值查询tomcat进程,使用grep -v "grep"筛选即可( ps -ef | grep -v "grep" |grep "tomcat")
12)查找包含非“a”开头的行
[root@VM_0_10_centos shellScript]# grep ^[a] test.txt
[root@VM_0_10_centos shellScript]# grep ^[^a] test.txt
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo
PS:grep可用于shell中。grep通过返回一个状态值来说明搜索的状态,结果{0:成功,1:不成功,2:搜索的文件不存在}
取出ip地址可以查看我另一篇博客:https://www.cnblogs.com/HeiDi-BoKe/p/11757961.html
【文本处理命令】之grep搜索命令详解的更多相关文章
- Linux文本处理三剑客之grep及正则表达式详解
Linux文本处理三剑客之grep及正则表达式详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux文本处理三剑客概述 grep: 全称:"Global se ...
- Linux经常使用命令002之搜索命令locate、whereis、which、find、grep
Linux经常使用命令002之搜索命令locate.whereis.which.find.grep -20150811 经常使用搜索命令 -------文件搜索命令---------- -->l ...
- Linux常用命令3 文件搜索命令
文件搜索非常占用资源,所以尽量不要使用这个命令 避免少用该命令最好的方式是设置好文件夹结构,文件不要乱放 1.文件搜索命令:find 命令名称:find 所在路径:/bin/find 执行权限:所有用 ...
- Elasticsearch java api 基本搜索部分详解
文档是结合几个博客整理出来的,内容大部分为转载内容.在使用过程中,对一些疑问点进行了整理与解析. Elasticsearch java api 基本搜索部分详解 ElasticSearch 常用的查询 ...
- Lucene系列六:Lucene搜索详解(Lucene搜索流程详解、搜索核心API详解、基本查询详解、QueryParser详解)
一.搜索流程详解 1. 先看一下Lucene的架构图 由图可知搜索的过程如下: 用户输入搜索的关键字.对关键字进行分词.根据分词结果去索引库里面找到对应的文章id.根据文章id找到对应的文章 2. L ...
- 【elasticsearch】搜索过程详解
elasticsearch 搜索过程详解 本文基于elasticsearch8.1.在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的 ...
- Linux下的grep搜索命令详解(一)
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全局正则表达 ...
- Linux中利用grep命令如何检索文件内容详解
前言 Linux系统中搜索.查找文件中的内容,一般最常用的是grep命令,另外还有egrep命令,同时vi命令也支持文件内容检索.下面来一起看看Linux利用grep命令检索文件内容的详细介绍. 方法 ...
- Shell 命令--文件创建、搜索命令--总结自《Linux Shell 脚本攻略》
(一)文件创建命令 1.touch命令 比如:touch abc命令在本地文件夹中创建了一个名为abc的空文件 2.cp命令 cp命令同意我们把一个文件的内容拷贝到同名或不同名的文件里,复制得到的文件 ...
随机推荐
- 11-《Node.js开发指南》-模块和包
什么是模块? 一个node.js文件就是一个模块,这个文件可能是js代码,json或者编译过的C/C++扩展 创建及加载模块 //a.js var name; exports.setName = fu ...
- 淘宝爬取图片和url
刚开始爬取了 百度图片和搜狗图片 但是图片不是很多,随后继续爬取淘宝图片,但是淘宝反爬比较厉害 之前的方法不能用 记录可行的 淘宝爬取 利用selenium爬取 https://cloud.tence ...
- 【第二章】Zabbix3.4监控SQLServer数据库和H3C交换机思科Cisco防火墙交换机教程笔记
监控SQLServer数据库 SSMS执行相关SQL SQL模板命名规则 Zabbix客户端导入模板 添加SQLServer监控图形 SQLServer服务器关联模板 监控思科Cisco防火墙交换机 ...
- LeetCode 219: 存在重复元素 II Contains Duplicate II
题目: 给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的绝对值最大为 k. Given an ...
- MFC图形编辑界面工具
一.背景 喔,五天的实训终于结束了,学校安排的这次实训课名称叫高级程序设计实训,但在我看来,主要是学习了Visual C++ .NET所提供的MFC(Microsoft Foundation Clas ...
- idea搜索不到任何插件
今天在idea安装插件的时候,突然发现,什么都搜索不到了?? 解决方案: 完活.
- 基于asp.net(C#)MVC+前端bootstrap+ztree+lodash+jquery技术-Angel工作室通用权限管理
一.Angel工作室简单通用权限系统简介 AngelRM(Asp.net MVC Web api)是基于asp.net(C#)MVC+前端bootstrap+ztree+lodash+jquery技术 ...
- 简单的PHP上传图片实例
分享一个简单的PHP上传图片实例,本实例主要介绍了上传图片的一些限制判断和上传图片的方法. 首先我们在form表单加上上传附件#file,上传按钮#imgbut,记得给form 表单加上multipa ...
- javaWeb核心技术第六篇之BootStrap
概述: Bootstrap 是最受欢迎的 HTML.CSS 和 JS 框架,用于开发响应式布局.移动设备优先的 WEB 项目. 作用: 开发响应式的页面 响应式:就是一个网站能够兼容多个终端 节约开发 ...
- ORA-04045: errors during recompilation/revalidation of LBACSYS.LBAC_EVENTS
使用orachk工具检查数据库实例的时候,发现报告里面有类似下面这样一些错误(最近有给Oracle 10g应用补丁PSU 10.2.0.5.180717,不清楚是这个产生的还是其他原因导致),使用脚本 ...